 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying economic narratives in large text corpora -- An integrated approach using Large Language Models
Jun 18, 2025As interest in economic narratives has grown in recent years, so has the number of pipelines dedicated to extracting such narratives from texts. Pipelines often employ a mix of state-of-the-art natural language processing techniques, such as BERT, to tackle this task. While effective on foundational linguistic operations essential for narrative extraction, such models lack the deeper semantic understanding required to distinguish extracting economic narratives from merely conducting classic tasks like Semantic Role Labeling. Instead of relying on complex model pipelines, we evaluate the benefits of Large Language Models (LLMs) by analyzing a corpus of Wall Street Journal and New York Times newspaper articles about inflation. We apply a rigorous narrative definition and compare GPT-4o outputs to gold-standard narratives produced by expert annotators. Our results suggests that GPT-4o is capable of extracting valid economic narratives in a structured format, but still falls short of expert-level performance when handling complex documents and narratives. Given the novelty of LLMs in economic research, we also provide guidance for future work in economics and the social sciences that employs LLMs to pursue similar objectives.
Improving the Effectiveness of Potential-Based Reward Shaping in Reinforcement Learning
Feb 03, 2025



Potential-based reward shaping is commonly used to incorporate prior knowledge of how to solve the task into reinforcement learning because it can formally guarantee policy invariance. As such, the optimal policy and the ordering of policies by their returns are not altered by potential-based reward shaping. In this work, we highlight the dependence of effective potential-based reward shaping on the initial Q-values and external rewards, which determine the agent's ability to exploit the shaping rewards to guide its exploration and achieve increased sample efficiency. We formally derive how a simple linear shift of the potential function can be used to improve the effectiveness of reward shaping without changing the encoded preferences in the potential function, and without having to adjust the initial Q-values, which can be challenging and undesirable in deep reinforcement learning. We show the theoretical limitations of continuous potential functions for correctly assigning positive and negative reward shaping values. We verify our theoretical findings empirically on Gridworld domains with sparse and uninformative reward functions, as well as on the Cart Pole and Mountain Car environments, where we demonstrate the application of our results in deep reinforcement learning.
Efficient Neural Ranking using Forward Indexes and Lightweight Encoders
Nov 02, 2023Dual-encoder-based dense retrieval models have become the standard in IR. They employ large Transformer-based language models, which are notoriously inefficient in terms of resources and latency. We propose Fast-Forward indexes -- vector forward indexes which exploit the semantic matching capabilities of dual-encoder models for efficient and effective re-ranking. Our framework enables re-ranking at very high retrieval depths and combines the merits of both lexical and semantic matching via score interpolation. Furthermore, in order to mitigate the limitations of dual-encoders, we tackle two main challenges: Firstly, we improve computational efficiency by either pre-computing representations, avoiding unnecessary computations altogether, or reducing the complexity of encoders. This allows us to considerably improve ranking efficiency and latency. Secondly, we optimize the memory footprint and maintenance cost of indexes; we propose two complementary techniques to reduce the index size and show that, by dynamically dropping irrelevant document tokens, the index maintenance efficiency can be improved substantially. We perform evaluation to show the effectiveness and efficiency of Fast-Forward indexes -- our method has low latency and achieves competitive results without the need for hardware acceleration, such as GPUs.
Machine Learning meets Data-Driven Journalism: Boosting International Understanding and Transparency in News Coverage
Jun 16, 2016
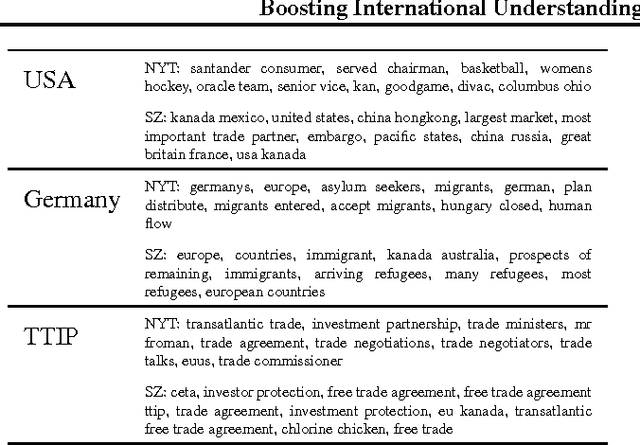

Migration crisis, climate change or tax havens: Global challenges need global solutions. But agreeing on a joint approach is difficult without a common ground for discussion. Public spheres are highly segmented because news are mainly produced and received on a national level. Gain- ing a global view on international debates about important issues is hindered by the enormous quantity of news and by language barriers. Media analysis usually focuses only on qualitative re- search. In this position statement, we argue that it is imperative to pool methods from machine learning, journalism studies and statistics to help bridging the segmented data of the international public sphere, using the Transatlantic Trade and Investment Partnership (TTIP) as a case study.