 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Perspective for Positive-Unlabeled Learning via Noisy Labels
Mar 08, 2021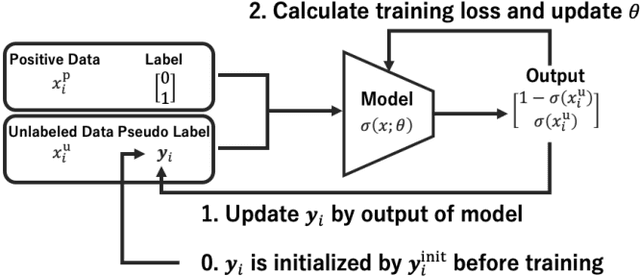
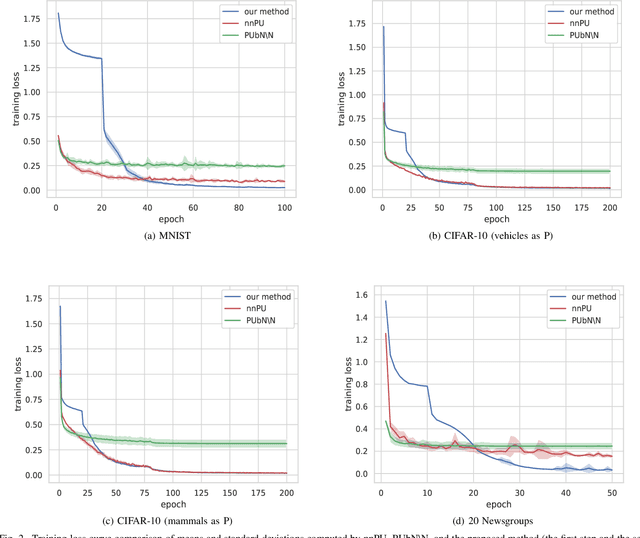
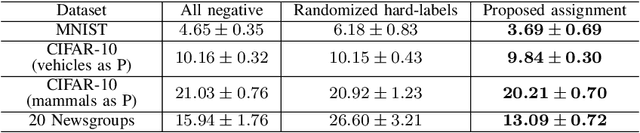
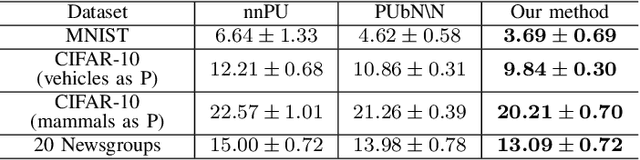
Positive-unlabeled learning refers to the process of training a binary classifier using only positive and unlabeled data. Although unlabeled data can contain positive data, all unlabeled data are regarded as negative data in existing positive-unlabeled learning methods, which resulting in diminishing performance. We provide a new perspective on this problem -- considering unlabeled data as noisy-labeled data, and introducing a new formulation of PU learning as a problem of joint optimization of noisy-labeled data. This research presents a methodology that assigns initial pseudo-labels to unlabeled data which is used as noisy-labeled data, and trains a deep neural network using the noisy-labeled data. Experimental results demonstrate that the proposed method significantly outperforms the state-of-the-art methods on several benchmark datasets.
What If We Only Use Real Datasets for Scene Text Recognition? Toward Scene Text Recognition With Fewer Labels
Mar 07, 2021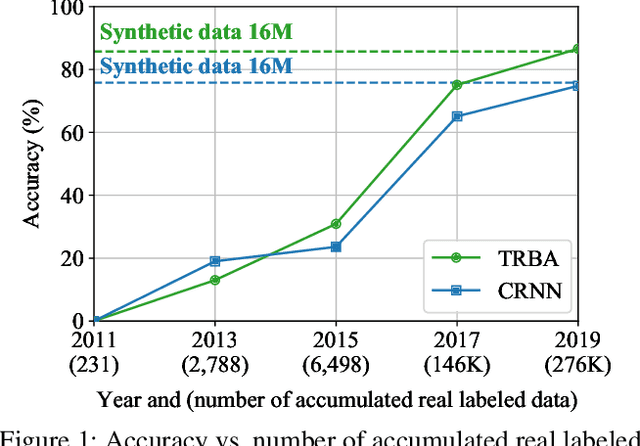
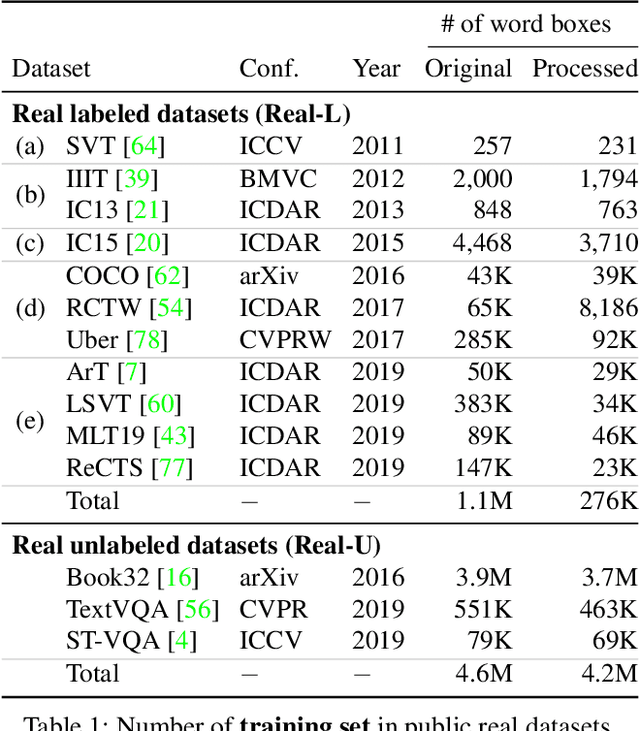

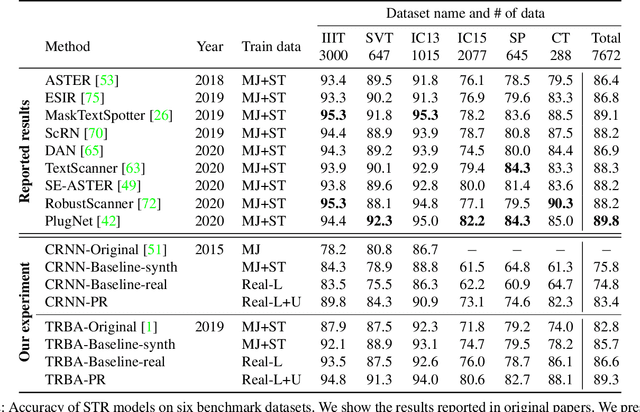
Scene text recognition (STR) task has a common practice: All state-of-the-art STR models are trained on large synthetic data. In contrast to this practice, training STR models only on fewer real labels (STR with fewer labels) is important when we have to train STR models without synthetic data: for handwritten or artistic texts that are difficult to generate synthetically and for languages other than English for which we do not always have synthetic data. However, there has been implicit common knowledge that training STR models on real data is nearly impossible because real data is insufficient. We consider that this common knowledge has obstructed the study of STR with fewer labels. In this work, we would like to reactivate STR with fewer labels by disproving the common knowledge. We consolidate recently accumulated public real data and show that we can train STR models satisfactorily only with real labeled data. Subsequently, we find simple data augmentation to fully exploit real data. Furthermore, we improve the models by collecting unlabeled data and introducing semi- and self-supervised methods. As a result, we obtain a competitive model to state-of-the-art methods. To the best of our knowledge, this is the first study that 1) shows sufficient performance by only using real labels and 2) introduces semi- and self-supervised methods into STR with fewer labels. Our code and data are available: https://github.com/ku21fan/STR-Fewer-Labels
Building Movie Map -- A Tool for Exploring Areas in a City -- and its Evaluation
Nov 17, 2020
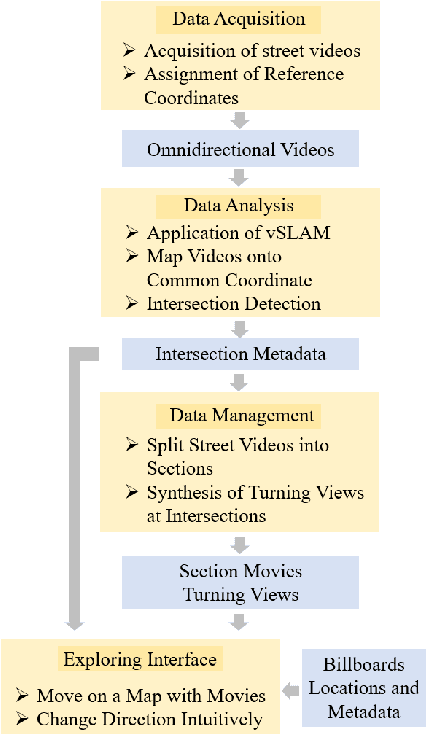
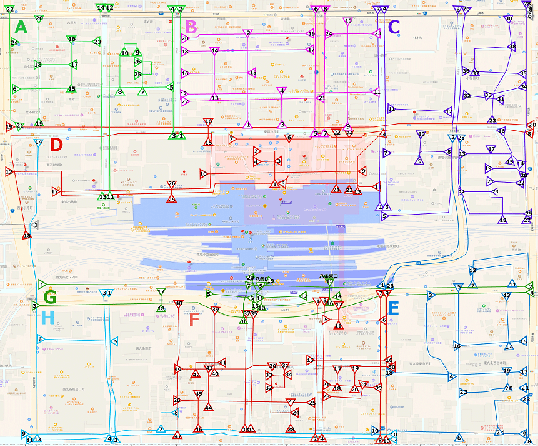
We propose a new Movie Map system, with an interface for exploring cities. The system consists of four stages; acquisition, analysis, management, and interaction. In the acquisition stage, omnidirectional videos are taken along streets in target areas. Frames of the video are localized on the map, intersections are detected, and videos are segmented. Turning views at intersections are subsequently generated. By connecting the video segments following the specified movement in an area, we can view the streets better. The interface allows for easy exploration of a target area, and it can show virtual billboards of stores in the view. We conducted user studies to compare our system to the GSV in a scenario where users could freely move and explore to find a landmark. The experiment showed that our system had a better user experience than GSV.
Few-Shot Font Generation with Deep Metric Learning
Nov 04, 2020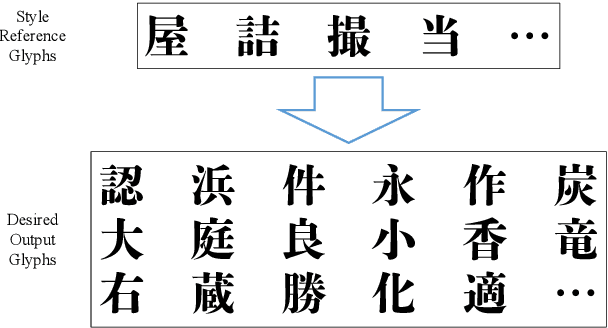
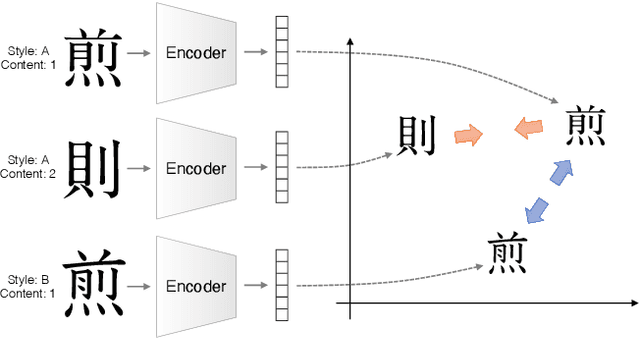
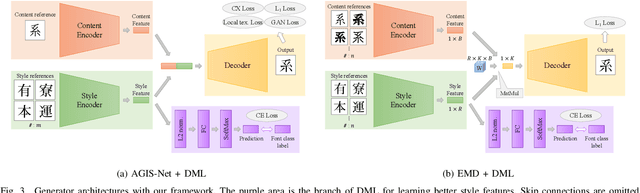

Designing fonts for languages with a large number of characters, such as Japanese and Chinese, is an extremely labor-intensive and time-consuming task. In this study, we addressed the problem of automatically generating Japanese typographic fonts from only a few font samples, where the synthesized glyphs are expected to have coherent characteristics, such as skeletons, contours, and serifs. Existing methods often fail to generate fine glyph images when the number of style reference glyphs is extremely limited. Herein, we proposed a simple but powerful framework for extracting better style features. This framework introduces deep metric learning to style encoders. We performed experiments using black-and-white and shape-distinctive font datasets and demonstrated the effectiveness of the proposed framework.
The Aleatoric Uncertainty Estimation Using a Separate Formulation with Virtual Residuals
Nov 03, 2020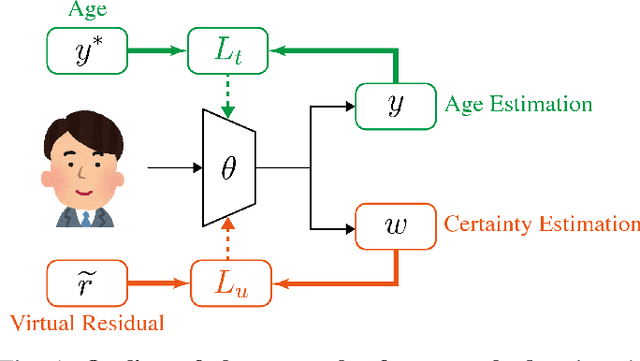
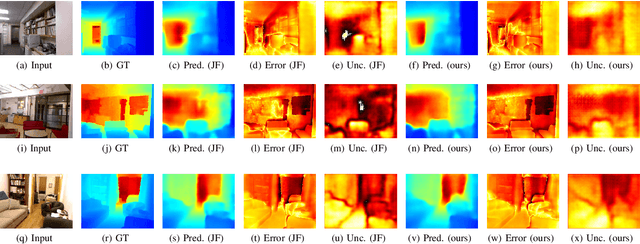
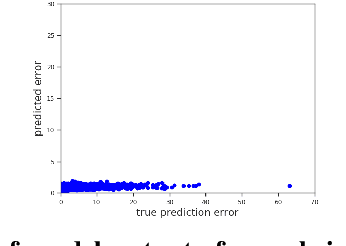
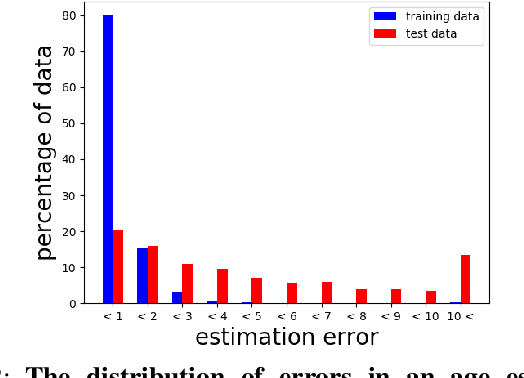
We propose a new optimization framework for aleatoric uncertainty estimation in regression problems. Existing methods can quantify the error in the target estimation, but they tend to underestimate it. To obtain the predictive uncertainty inherent in an observation, we propose a new separable formulation for the estimation of a signal and of its uncertainty, avoiding the effect of overfitting. By decoupling target estimation and uncertainty estimation, we also control the balance between signal estimation and uncertainty estimation. We conduct three types of experiments: regression with simulation data, age estimation, and depth estimation. We demonstrate that the proposed method outperforms a state-of-the-art technique for signal and uncertainty estimation.
SLGAN: Style- and Latent-guided Generative Adversarial Network for Desirable Makeup Transfer and Removal
Sep 24, 2020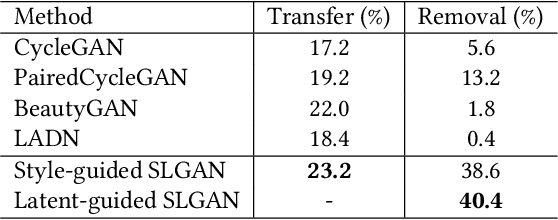
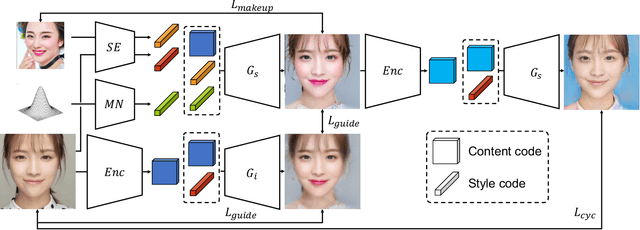


There are five features to consider when using generative adversarial networks to apply makeup to photos of the human face. These features include (1) facial components, (2) interactive color adjustments, (3) makeup variations, (4) robustness to poses and expressions, and the (5) use of multiple reference images. Several related works have been proposed, mainly using generative adversarial networks (GAN). Unfortunately, none of them have addressed all five features simultaneously. This paper closes the gap with an innovative style- and latent-guided GAN (SLGAN). We provide a novel, perceptual makeup loss and a style-invariant decoder that can transfer makeup styles based on histogram matching to avoid the identity-shift problem. In our experiments, we show that our SLGAN is better than or comparable to state-of-the-art methods. Furthermore, we show that our proposal can interpolate facial makeup images to determine the unique features, compare existing methods, and help users find desirable makeup configurations.
Multi-Task Curriculum Framework for Open-Set Semi-Supervised Learning
Jul 22, 2020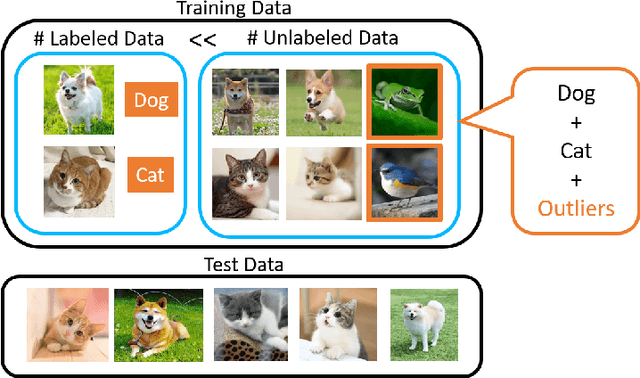

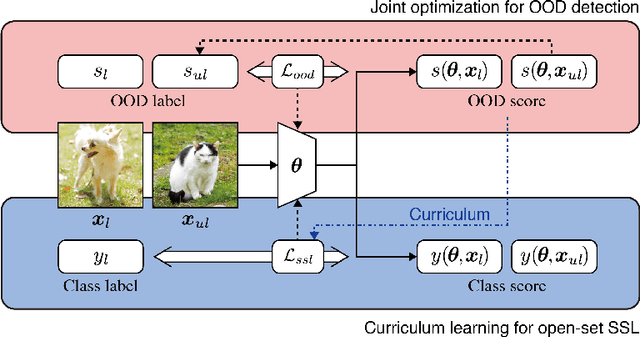
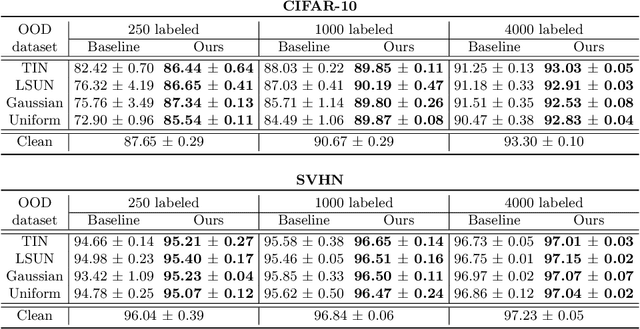
Semi-supervised learning (SSL) has been proposed to leverage unlabeled data for training powerful models when only limited labeled data is available. While existing SSL methods assume that samples in the labeled and unlabeled data share the classes of their samples, we address a more complex novel scenario named open-set SSL, where out-of-distribution (OOD) samples are contained in unlabeled data. Instead of training an OOD detector and SSL separately, we propose a multi-task curriculum learning framework. First, to detect the OOD samples in unlabeled data, we estimate the probability of the sample belonging to OOD. We use a joint optimization framework, which updates the network parameters and the OOD score alternately. Simultaneously, to achieve high performance on the classification of in-distribution (ID) data, we select ID samples in unlabeled data having small OOD scores, and use these data with labeled data for training the deep neural networks to classify ID samples in a semi-supervised manner. We conduct several experiments, and our method achieves state-of-the-art results by successfully eliminating the effect of OOD samples.
Channel-Level Variable Quantization Network for Deep Image Compression
Jul 15, 2020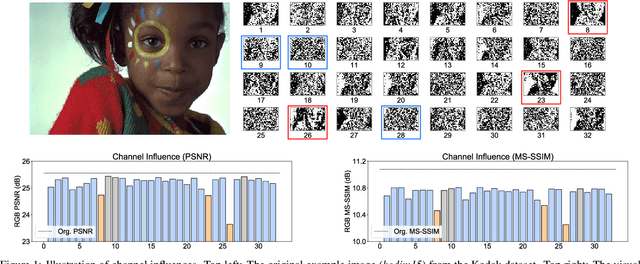
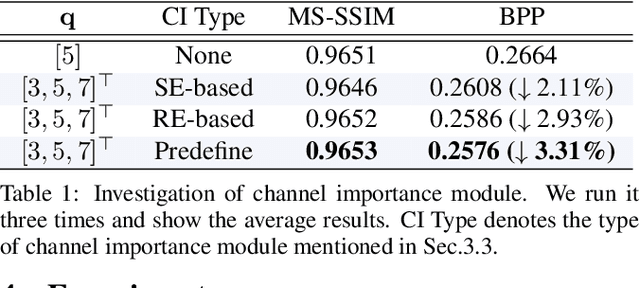
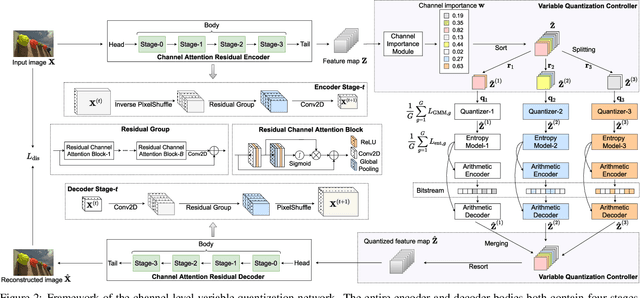
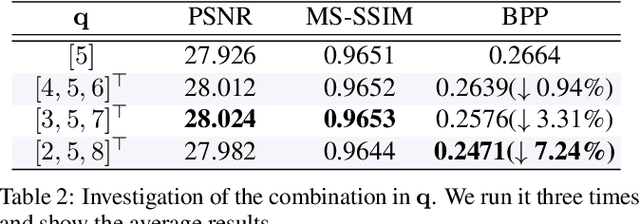
Deep image compression systems mainly contain four components: encoder, quantizer, entropy model, and decoder. To optimize these four components, a joint rate-distortion framework was proposed, and many deep neural network-based methods achieved great success in image compression. However, almost all convolutional neural network-based methods treat channel-wise feature maps equally, reducing the flexibility in handling different types of information. In this paper, we propose a channel-level variable quantization network to dynamically allocate more bitrates for significant channels and withdraw bitrates for negligible channels. Specifically, we propose a variable quantization controller. It consists of two key components: the channel importance module, which can dynamically learn the importance of channels during training, and the splitting-merging module, which can allocate different bitrates for different channels. We also formulate the quantizer into a Gaussian mixture model manner. Quantitative and qualitative experiments verify the effectiveness of the proposed model and demonstrate that our method achieves superior performance and can produce much better visual reconstructions.
Building a Manga Dataset "Manga109" with Annotations for Multimedia Applications
May 12, 2020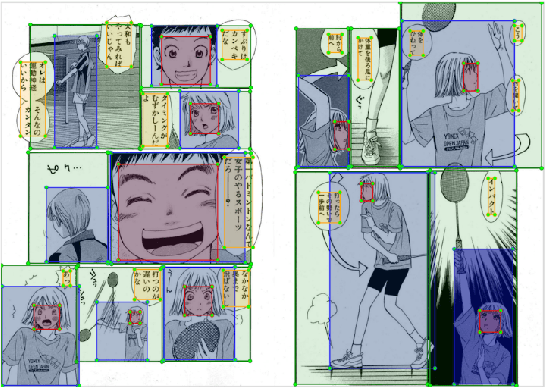
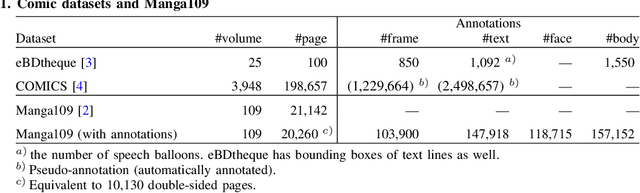
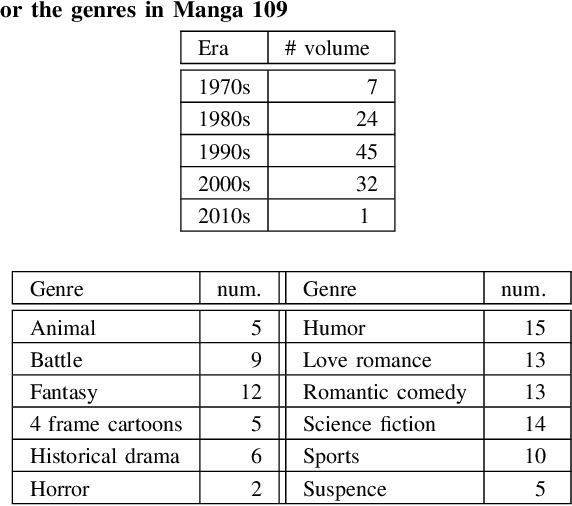
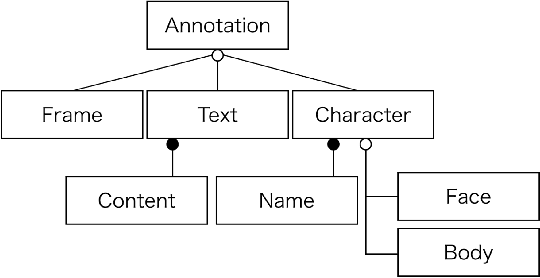
Manga, or comics, which are a type of multimodal artwork, have been left behind in the recent trend of deep learning applications because of the lack of a proper dataset. Hence, we built Manga109, a dataset consisting of a variety of 109 Japanese comic books (94 authors and 21,142 pages) and made it publicly available by obtaining author permissions for academic use. We carefully annotated the frames, speech texts, character faces, and character bodies; the total number of annotations exceeds 500k. This dataset provides numerous manga images and annotations, which will be beneficial for use in machine learning algorithms and their evaluation. In addition to academic use, we obtained further permission for a subset of the dataset for industrial use. In this article, we describe the details of the dataset and present a few examples of multimedia processing applications (detection, retrieval, and generation) that apply existing deep learning methods and are made possible by the dataset.
* 10 pages, 8 figures
Unsupervised Out-of-Distribution Detection by Maximum Classifier Discrepancy
Aug 14, 2019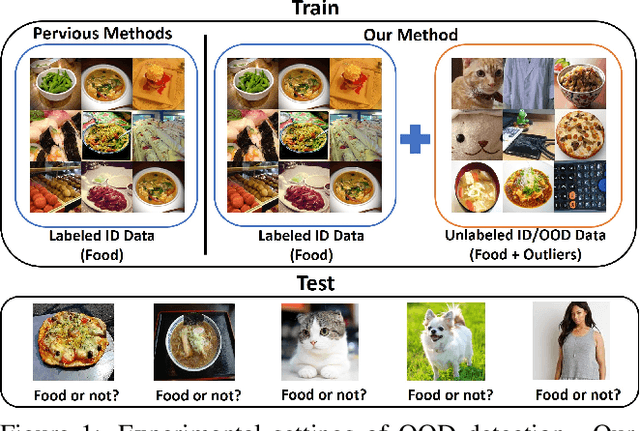

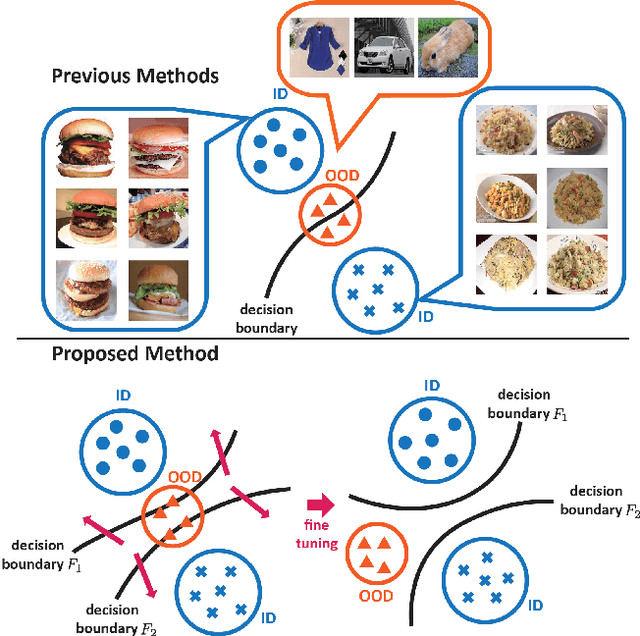
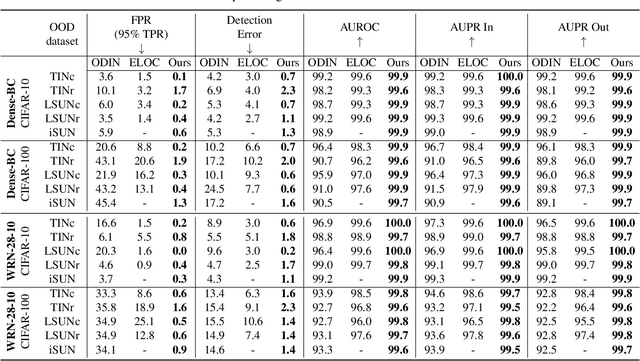
Since deep learning models have been implemented in many commercial applications, it is important to detect out-of-distribution (OOD) inputs correctly to maintain the performance of the models, ensure the quality of the collected data, and prevent the applications from being used for other-than-intended purposes. In this work, we propose a two-head deep convolutional neural network (CNN) and maximize the discrepancy between the two classifiers to detect OOD inputs. We train a two-head CNN consisting of one common feature extractor and two classifiers which have different decision boundaries but can classify in-distribution (ID) samples correctly. Unlike previous methods, we also utilize unlabeled data for unsupervised training and we use these unlabeled data to maximize the discrepancy between the decision boundaries of two classifiers to push OOD samples outside the manifold of the in-distribution (ID) samples, which enables us to detect OOD samples that are far from the support of the ID samples. Overall, our approach significantly outperforms other state-of-the-art methods on several OOD detection benchmarks and two cases of real-world simulation.