 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam-family Methods with Decoupled Weight Decay in Deep Learning
Oct 13, 2023In this paper, we investigate the convergence properties of a wide class of Adam-family methods for minimizing quadratically regularized nonsmooth nonconvex optimization problems, especially in the context of training nonsmooth neural networks with weight decay. Motivated by the AdamW method, we propose a novel framework for Adam-family methods with decoupled weight decay. Within our framework, the estimators for the first-order and second-order moments of stochastic subgradients are updated independently of the weight decay term. Under mild assumptions and with non-diminishing stepsizes for updating the primary optimization variables, we establish the convergence properties of our proposed framework. In addition, we show that our proposed framework encompasses a wide variety of well-known Adam-family methods, hence offering convergence guarantees for these methods in the training of nonsmooth neural networks. More importantly, we show that our proposed framework asymptotically approximates the SGD method, thereby providing an explanation for the empirical observation that decoupled weight decay enhances generalization performance for Adam-family methods. As a practical application of our proposed framework, we propose a novel Adam-family method named Adam with Decoupled Weight Decay (AdamD), and establish its convergence properties under mild conditions. Numerical experiments demonstrate that AdamD outperforms Adam and is comparable to AdamW, in the aspects of both generalization performance and efficiency.
Convergence Guarantees for Stochastic Subgradient Methods in Nonsmooth Nonconvex Optimization
Jul 19, 2023



In this paper, we investigate the convergence properties of the stochastic gradient descent (SGD) method and its variants, especially in training neural networks built from nonsmooth activation functions. We develop a novel framework that assigns different timescales to stepsizes for updating the momentum terms and variables, respectively. Under mild conditions, we prove the global convergence of our proposed framework in both single-timescale and two-timescale cases. We show that our proposed framework encompasses a wide range of well-known SGD-type methods, including heavy-ball SGD, SignSGD, Lion, normalized SGD and clipped SGD. Furthermore, when the objective function adopts a finite-sum formulation, we prove the convergence properties for these SGD-type methods based on our proposed framework. In particular, we prove that these SGD-type methods find the Clarke stationary points of the objective function with randomly chosen stepsizes and initial points under mild assumptions. Preliminary numerical experiments demonstrate the high efficiency of our analyzed SGD-type methods.
Nonconvex Stochastic Bregman Proximal Gradient Method with Application to Deep Learning
Jun 29, 2023



The widely used stochastic gradient methods for minimizing nonconvex composite objective functions require the Lipschitz smoothness of the differentiable part. But the requirement does not hold true for problem classes including quadratic inverse problems and training neural networks. To address this issue, we investigate a family of stochastic Bregman proximal gradient (SBPG) methods, which only require smooth adaptivity of the differentiable part. SBPG replaces the upper quadratic approximation used in SGD with the Bregman proximity measure, resulting in a better approximation model that captures the non-Lipschitz gradients of the nonconvex objective. We formulate the vanilla SBPG and establish its convergence properties under nonconvex setting without finite-sum structure. Experimental results on quadratic inverse problems testify the robustness of SBPG. Moreover, we propose a momentum-based version of SBPG (MSBPG) and prove it has improved convergence properties. We apply MSBPG to the training of deep neural networks with a polynomial kernel function, which ensures the smooth adaptivity of the loss function. Experimental results on representative benchmarks demonstrate the effectiveness and robustness of MSBPG in training neural networks. Since the additional computation cost of MSBPG compared with SGD is negligible in large-scale optimization, MSBPG can potentially be employed as an universal open-source optimizer in the future.
Adam-family Methods for Nonsmooth Optimization with Convergence Guarantees
May 06, 2023In this paper, we present a comprehensive study on the convergence properties of Adam-family methods for nonsmooth optimization, especially in the training of nonsmooth neural networks. We introduce a novel two-timescale framework that adopts a two-timescale updating scheme, and prove its convergence properties under mild assumptions. Our proposed framework encompasses various popular Adam-family methods, providing convergence guarantees for these methods in training nonsmooth neural networks. Furthermore, we develop stochastic subgradient methods that incorporate gradient clipping techniques for training nonsmooth neural networks with heavy-tailed noise. Through our framework, we show that our proposed methods converge even when the evaluation noises are only assumed to be integrable. Extensive numerical experiments demonstrate the high efficiency and robustness of our proposed methods.
Tractable hierarchies of convex relaxations for polynomial optimization on the nonnegative orthant
Sep 13, 2022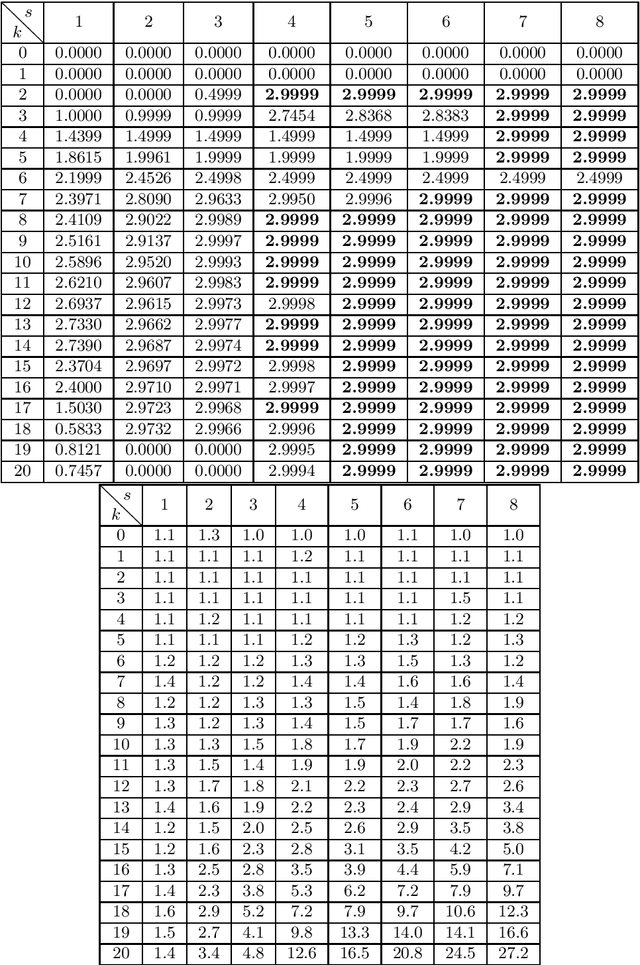
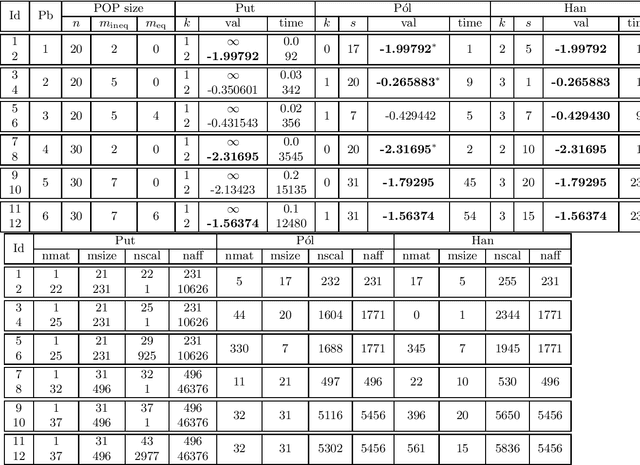
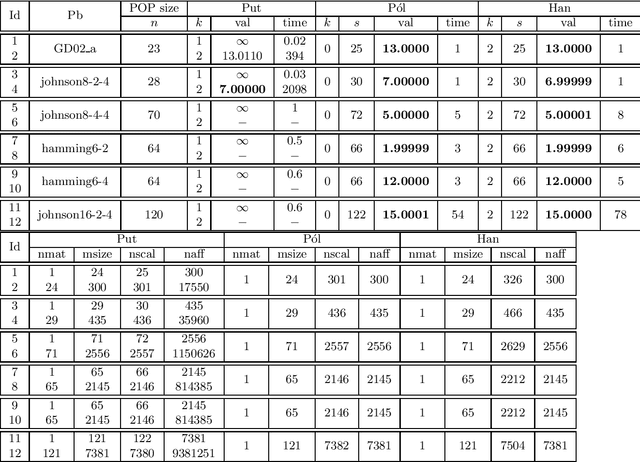
We consider polynomial optimization problems (POP) on a semialgebraic set contained in the nonnegative orthant (every POP on a compact set can be put in this format by a simple translation of the origin). Such a POP can be converted to an equivalent POP by squaring each variable. Using even symmetry and the concept of factor width, we propose a hierarchy of semidefinite relaxations based on the extension of P\'olya's Positivstellensatz by Dickinson-Povh. As its distinguishing and crucial feature, the maximal matrix size of each resulting semidefinite relaxation can be chosen arbitrarily and in addition, we prove that the sequence of values returned by the new hierarchy converges to the optimal value of the original POP at the rate $O(\varepsilon^{-c})$ if the semialgebraic set has nonempty interior. When applied to (i) robustness certification of multi-layer neural networks and (ii) computation of positive maximal singular values, our method based on P\'olya's Positivstellensatz provides better bounds and runs several hundred times faster than the standard Moment-SOS hierarchy.
Escaping Spurious Local Minima of Low-Rank Matrix Factorization Through Convex Lifting
Apr 29, 2022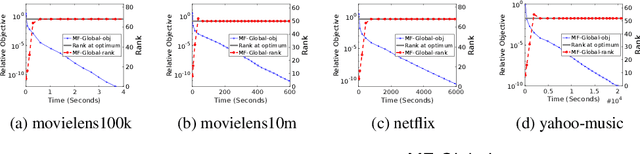
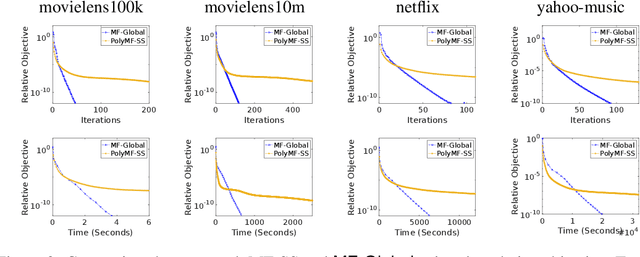
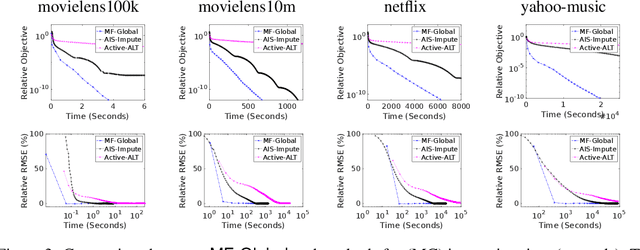
This work proposes a rapid global solver for nonconvex low-rank matrix factorization (MF) problems that we name MF-Global. Through convex lifting steps, our method efficiently escapes saddle points and spurious local minima ubiquitous in noisy real-world data, and is guaranteed to always converge to the global optima. Moreover, the proposed approach adaptively adjusts the rank for the factorization and provably identifies the optimal rank for MF automatically in the course of optimization through tools of manifold identification, and thus it also spends significantly less time on parameter tuning than existing MF methods, which require an exhaustive search for this optimal rank. On the other hand, when compared to methods for solving the lifted convex form only, MF-Global leads to significantly faster convergence and much shorter running time. Experiments on real-world large-scale recommendation system problems confirm that MF-Global can indeed effectively escapes spurious local solutions at which existing MF approaches stuck, and is magnitudes faster than state-of-the-art algorithms for the lifted convex form.
STRIDE along Spectrahedral Vertices for Solving Large-Scale Rank-One Semidefinite Relaxations
May 28, 2021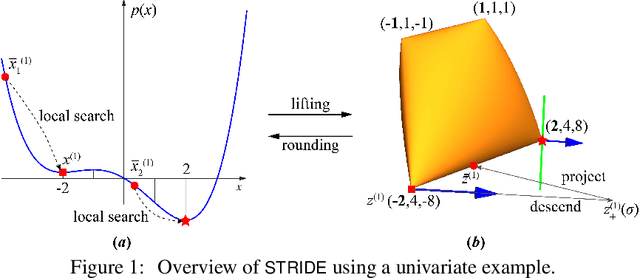
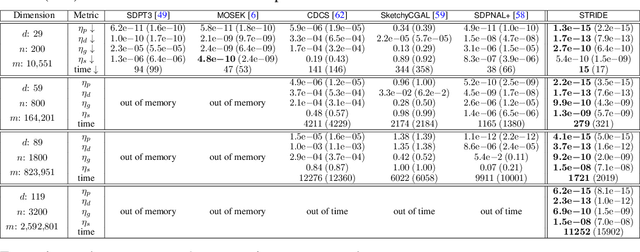
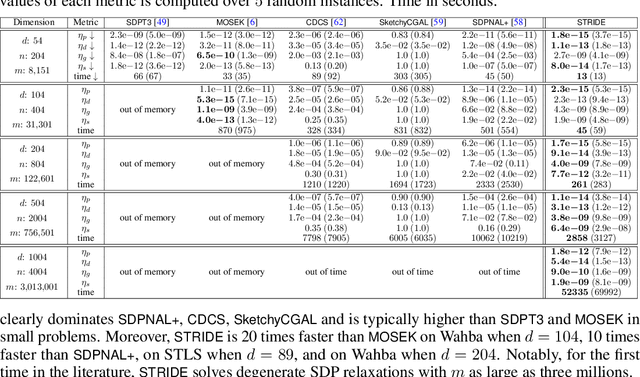
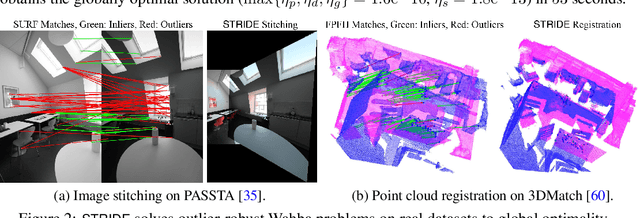
We consider solving high-order semidefinite programming (SDP) relaxations of nonconvex polynomial optimization problems (POPs) that admit rank-one optimal solutions. Existing approaches, which solve the SDP independently from the POP, either cannot scale to large problems or suffer from slow convergence due to the typical degeneracy of such SDPs. We propose a new algorithmic framework, called SpecTrahedral pRoximal gradIent Descent along vErtices (STRIDE), that blends fast local search on the nonconvex POP with global descent on the convex SDP. Specifically, STRIDE follows a globally convergent trajectory driven by a proximal gradient method (PGM) for solving the SDP, while simultaneously probing long, but safeguarded, rank-one "strides", generated by fast nonlinear programming algorithms on the POP, to seek rapid descent. We prove STRIDE has global convergence. To solve the subproblem of projecting a given point onto the feasible set of the SDP, we reformulate the projection step as a continuously differentiable unconstrained optimization and apply a limited-memory BFGS method to achieve both scalability and accuracy. We conduct numerical experiments on solving second-order SDP relaxations arising from two important applications in machine learning and computer vision. STRIDE dominates a diverse set of five existing SDP solvers and is the only solver that can solve degenerate rank-one SDPs to high accuracy (e.g., KKT residuals below 1e-9), even in the presence of millions of equality constraints.
Learning Graph Laplacian with MCP
Oct 22, 2020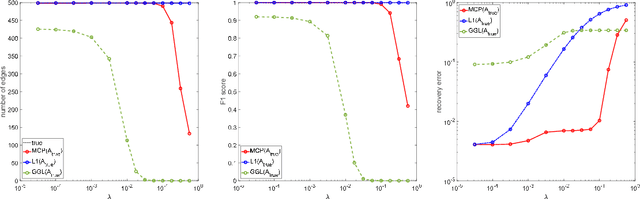

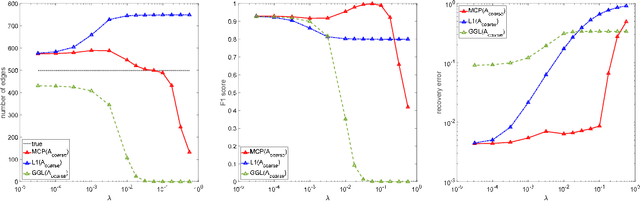
Motivated by the observation that the ability of the $\ell_1$ norm in promoting sparsity in graphical models with Laplacian constraints is much weakened, this paper proposes to learn graph Laplacian with a non-convex penalty: minimax concave penalty (MCP). For solving the MCP penalized graphical model, we design an inexact proximal difference-of-convex algorithm (DCA) and prove its convergence to critical points. We note that each subproblem of the proximal DCA enjoys the nice property that the objective function in its dual problem is continuously differentiable with a semismooth gradient. Therefore, we apply an efficient semismooth Newton method to subproblems of the proximal DCA. Numerical experiments on various synthetic and real data sets demonstrate the effectiveness of the non-convex penalty MCP in promoting sparsity. Compared with the state-of-the-art method \cite[Algorithm~1]{ying2020does}, our method is demonstrated to be more efficient and reliable for learning graph Laplacian with MCP.
Estimation of sparse Gaussian graphical models with hidden clustering structure
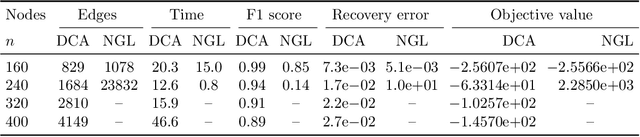
Apr 17, 2020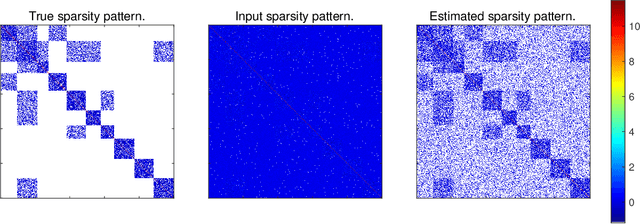
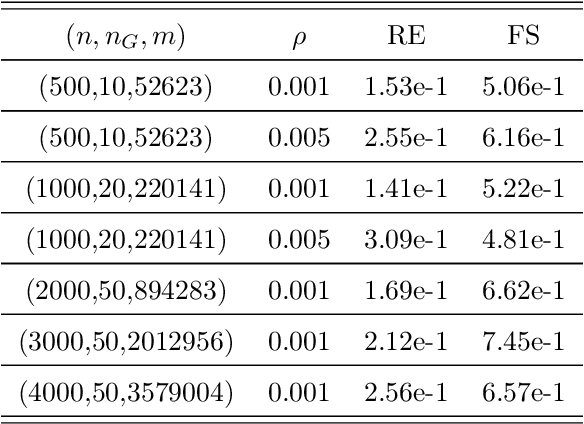
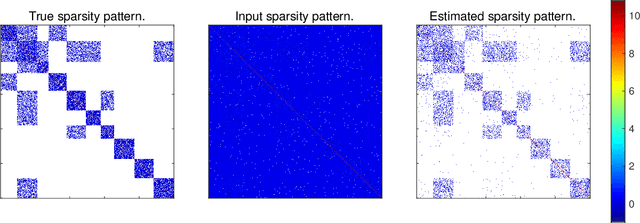
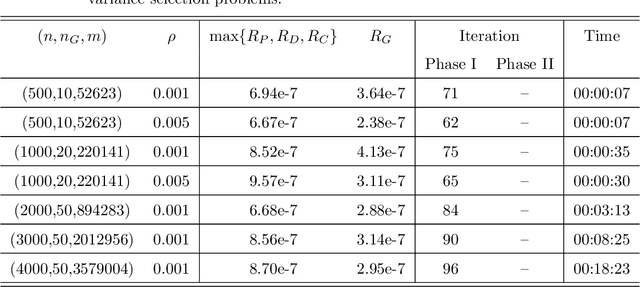
Estimation of Gaussian graphical models is important in natural science when modeling the statistical relationships between variables in the form of a graph. The sparsity and clustering structure of the concentration matrix is enforced to reduce model complexity and describe inherent regularities. We propose a model to estimate the sparse Gaussian graphical models with hidden clustering structure, which also allows additional linear constraints to be imposed on the concentration matrix. We design an efficient two-phase algorithm for solving the proposed model. We develop a symmetric Gauss-Seidel based alternating direction method of the multipliers (sGS-ADMM) to generate an initial point to warm-start the second phase algorithm, which is a proximal augmented Lagrangian method (pALM), to get a solution with high accuracy. Numerical experiments on both synthetic data and real data demonstrate the good performance of our model, as well as the efficiency and robustness of our proposed algorithm.
Efficient algorithms for multivariate shape-constrained convex regression problems
Feb 26, 2020
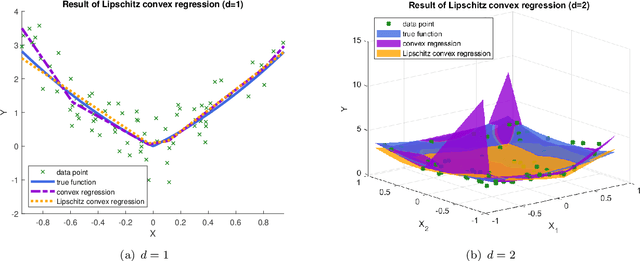

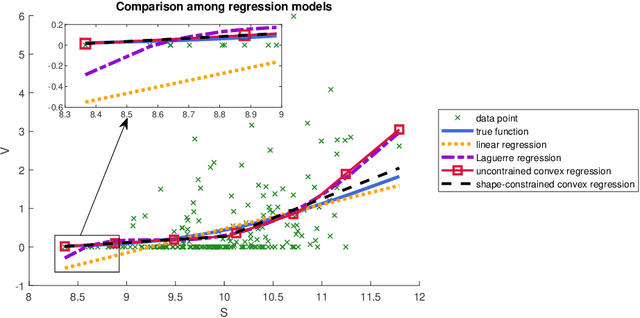
Shape-constrained convex regression problem deals with fitting a convex function to the observed data, where additional constraints are imposed, such as component-wise monotonicity and uniform Lipschitz continuity. This paper provides a comprehensive mechanism for computing the least squares estimator of a multivariate shape-constrained convex regression function in $\mathbb{R}^d$. We prove that the least squares estimator is computable via solving a constrained convex quadratic programming (QP) problem with $(n+1)d$ variables and at least $n(n-1)$ linear inequality constraints, where $n$ is the number of data points. For solving the generally very large-scale convex QP, we design two efficient algorithms, one is the symmetric Gauss-Seidel based alternating direction method of multipliers ({\tt sGS-ADMM}), and the other is the proximal augmented Lagrangian method ({\tt pALM}) with the subproblems solved by the semismooth Newton method ({\tt SSN}). Comprehensive numerical experiments, including those in the pricing of basket options and estimation of production functions in economics, demonstrate that both of our proposed algorithms outperform the state-of-the-art algorithm. The {\tt pALM} is more efficient than the {\tt sGS-ADMM} but the latter has the advantage of being simpler to implement.