 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Cyclical Learning Rate to Neural Machine Translation
Apr 06, 2020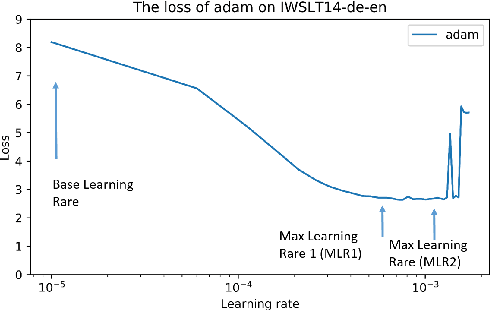

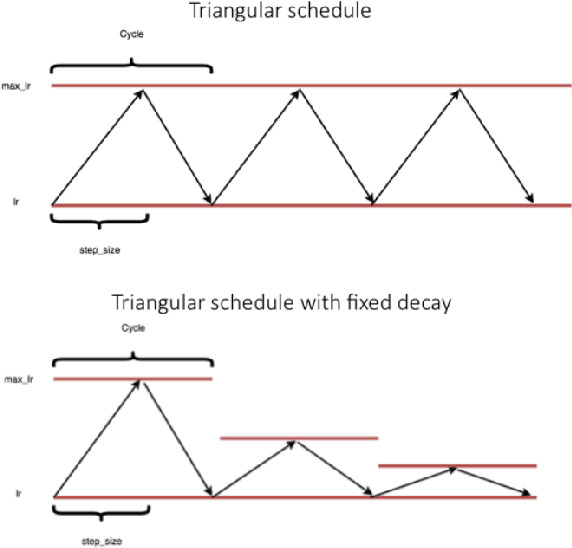

In training deep learning networks, the optimizer and related learning rate are often used without much thought or with minimal tuning, even though it is crucial in ensuring a fast convergence to a good quality minimum of the loss function that can also generalize well on the test dataset. Drawing inspiration from the successful application of cyclical learning rate policy for computer vision related convolutional networks and datasets, we explore how cyclical learning rate can be applied to train transformer-based neural networks for neural machine translation. From our carefully designed experiments, we show that the choice of optimizers and the associated cyclical learning rate policy can have a significant impact on the performance. In addition, we establish guidelines when applying cyclical learning rates to neural machine translation tasks. Thus with our work, we hope to raise awareness of the importance of selecting the right optimizers and the accompanying learning rate policy, at the same time, encourage further research into easy-to-use learning rate policies.
Practical Matrix Completion and Corruption Recovery using Proximal Alternating Robust Subspace Minimization
Oct 28, 2014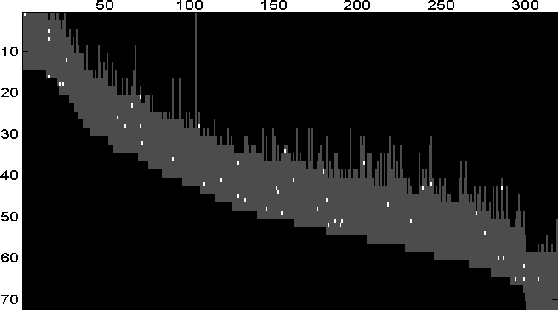
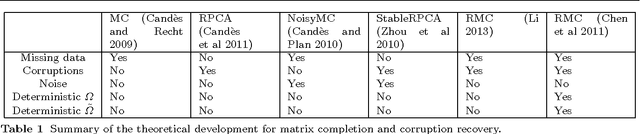
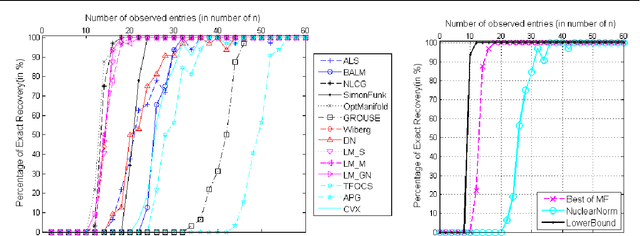
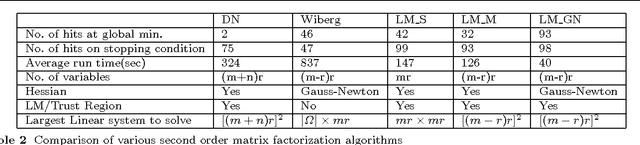
Low-rank matrix completion is a problem of immense practical importance. Recent works on the subject often use nuclear norm as a convex surrogate of the rank function. Despite its solid theoretical foundation, the convex version of the problem often fails to work satisfactorily in real-life applications. Real data often suffer from very few observations, with support not meeting the random requirements, ubiquitous presence of noise and potentially gross corruptions, sometimes with these simultaneously occurring. This paper proposes a Proximal Alternating Robust Subspace Minimization (PARSuMi) method to tackle the three problems. The proximal alternating scheme explicitly exploits the rank constraint on the completed matrix and uses the $\ell_0$ pseudo-norm directly in the corruption recovery step. We show that the proposed method for the non-convex and non-smooth model converges to a stationary point. Although it is not guaranteed to find the global optimal solution, in practice we find that our algorithm can typically arrive at a good local minimizer when it is supplied with a reasonably good starting point based on convex optimization. Extensive experiments with challenging synthetic and real data demonstrate that our algorithm succeeds in a much larger range of practical problems where convex optimization fails, and it also outperforms various state-of-the-art algorithms.