 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasi-Fractal UCA Based OAM for Highly Efficient Orthogonal Transmission
Aug 10, 2024



The development of orbital angular momentum (OAM)-based radio vortex transmission presents a promising opportunity for increasing the capacity of wireless communication in correlated channels due to its inherent orthogonality among different OAM modes. One of the most popular schemes for high-efficient OAM transmission is the digital baseband associated with uniform circular array (UCA) based transceiver. However, the periodicity of complex-exponential feed makes the maximum number of orthogonal signals carried by multiple OAM modes generally restricted to the array-element number of UCA antenna, which poses an open question of how to employ more OAM modes given a fixed number of array elements. Furthermore, signals modulated with high-order OAM modes are difficult to be captured by the receiver due to their serious divergence as propagating in free space, thus severely limiting the capacity of radio vortex communications. To overcome the above challenges, in this paper based on the partly element-overlapped fractal geometry layout and effectively using low-order OAM modes, we propose the quasi-fractal UCA (QF-UCA) antenna based OAM multiplexing transmission. We perform the two-dimension OAM modulation (TOM) and demodulation (TOD) schemes with the orthogonal OAM mode number exceeding the array-element number, which is beyond the traditional concept of multiple antennas based wireless communications. Simulation results show that our proposed scheme can achieve more number of orthogonal multiplexing streams than the maximum number of orthogonal multiplexing corresponding to traditional multiple antenna systems.
Singing Voice Data Scaling-up: An Introduction to ACE-Opencpop and KiSing-v2
Jan 31, 2024



In singing voice synthesis (SVS), generating singing voices from musical scores faces challenges due to limited data availability, a constraint less common in text-to-speech (TTS). This study proposes a new approach to address this data scarcity. We utilize an existing singing voice synthesizer for data augmentation and apply precise manual tuning to reduce unnatural voice synthesis. Our development of two extensive singing voice corpora, ACE-Opencpop and KiSing-v2, facilitates large-scale, multi-singer voice synthesis. Utilizing pre-trained models derived from these corpora, we achieve notable improvements in voice quality, evident in both in-domain and out-of-domain scenarios. The corpora, pre-trained models, and their related training recipes are publicly available at Muskits-ESPnet (https://github.com/espnet/espnet).
Online Model Distillation for Efficient Video Inference
Dec 06, 2018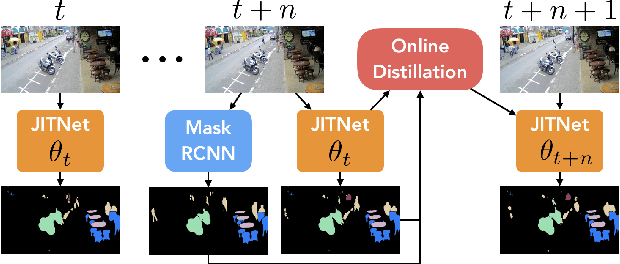
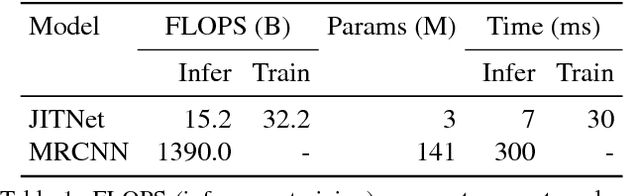
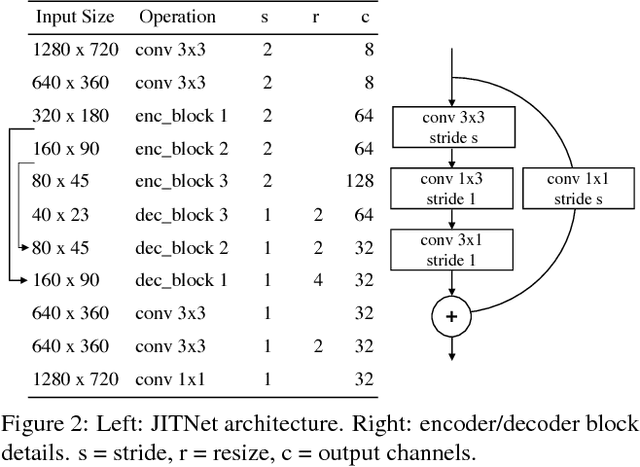
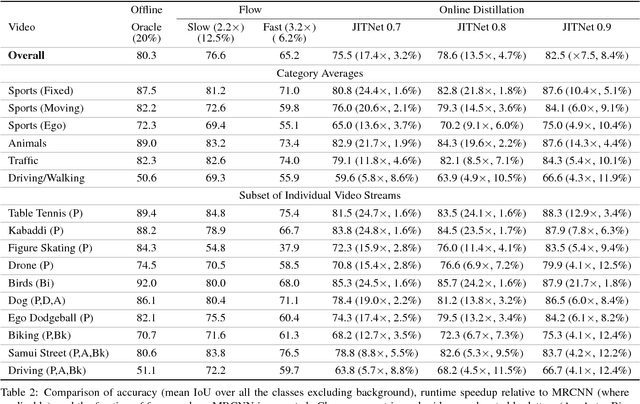
High-quality computer vision models typically address the problem of understanding the general distribution of real-world images. However, most cameras observe only a very small fraction of this distribution. This offers the possibility of achieving more efficient inference by specializing compact, low-cost models to the specific distribution of frames observed by a single camera. In this paper, we employ the technique of model distillation (supervising a low-cost student model using the output of a high-cost teacher) to specialize accurate, low-cost semantic segmentation models to a target video stream. Rather than learn a specialized student model on offline data from the video stream, we train the student in an online fashion on the live video, intermittently running the teacher to provide a target for learning. Online model distillation yields semantic segmentation models that closely approximate their Mask R-CNN teacher with 7 to 17x lower inference runtime cost (11 to 26x in FLOPs), even when the target video's distribution is non-stationary. Our method requires no offline pretraining on the target video stream, and achieves higher accuracy and lower cost than solutions based on flow or video object segmentation. We also provide a new video dataset for evaluating the efficiency of inference over long running video streams.