 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectly Fine-Tuning Diffusion Models on Differentiable Rewards
Sep 29, 2023



We present Direct Reward Fine-Tuning (DRaFT), a simple and effective method for fine-tuning diffusion models to maximize differentiable reward functions, such as scores from human preference models. We first show that it is possible to backpropagate the reward function gradient through the full sampling procedure, and that doing so achieves strong performance on a variety of rewards, outperforming reinforcement learning-based approaches. We then propose more efficient variants of DRaFT: DRaFT-K, which truncates backpropagation to only the last K steps of sampling, and DRaFT-LV, which obtains lower-variance gradient estimates for the case when K=1. We show that our methods work well for a variety of reward functions and can be used to substantially improve the aesthetic quality of images generated by Stable Diffusion 1.4. Finally, we draw connections between our approach and prior work, providing a unifying perspective on the design space of gradient-based fine-tuning algorithms.
Low-Variance Gradient Estimation in Unrolled Computation Graphs with ES-Single
Apr 21, 2023



We propose an evolution strategies-based algorithm for estimating gradients in unrolled computation graphs, called ES-Single. Similarly to the recently-proposed Persistent Evolution Strategies (PES), ES-Single is unbiased, and overcomes chaos arising from recursive function applications by smoothing the meta-loss landscape. ES-Single samples a single perturbation per particle, that is kept fixed over the course of an inner problem (e.g., perturbations are not re-sampled for each partial unroll). Compared to PES, ES-Single is simpler to implement and has lower variance: the variance of ES-Single is constant with respect to the number of truncated unrolls, removing a key barrier in applying ES to long inner problems using short truncations. We show that ES-Single is unbiased for quadratic inner problems, and demonstrate empirically that its variance can be substantially lower than that of PES. ES-Single consistently outperforms PES on a variety of tasks, including a synthetic benchmark task, hyperparameter optimization, training recurrent neural networks, and training learned optimizers.
Towards Better Out-of-Distribution Generalization of Neural Algorithmic Reasoning Tasks
Nov 01, 2022



In this paper, we study the OOD generalization of neural algorithmic reasoning tasks, where the goal is to learn an algorithm (e.g., sorting, breadth-first search, and depth-first search) from input-output pairs using deep neural networks. First, we argue that OOD generalization in this setting is significantly different than common OOD settings. For example, some phenomena in OOD generalization of image classifications such as \emph{accuracy on the line} are not observed here, and techniques such as data augmentation methods do not help as assumptions underlying many augmentation techniques are often violated. Second, we analyze the main challenges (e.g., input distribution shift, non-representative data generation, and uninformative validation metrics) of the current leading benchmark, i.e., CLRS \citep{deepmind2021clrs}, which contains 30 algorithmic reasoning tasks. We propose several solutions, including a simple-yet-effective fix to the input distribution shift and improved data generation. Finally, we propose an attention-based 2WL-graph neural network (GNN) processor which complements message-passing GNNs so their combination outperforms the state-of-the-art model by a 3% margin averaged over all algorithms. Our code is available at: \url{https://github.com/smahdavi4/clrs}.
CUF: Continuous Upsampling Filters
Oct 20, 2022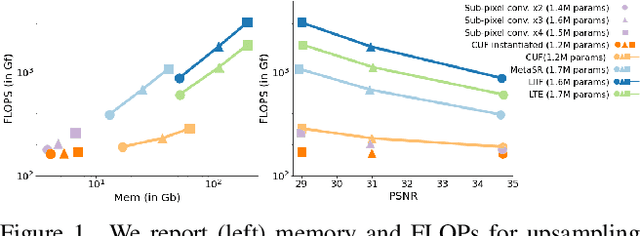


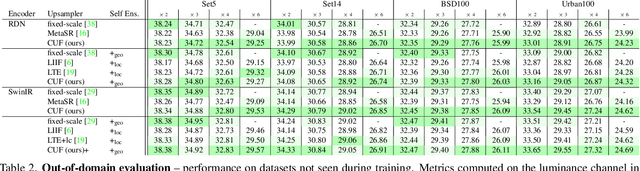
Neural fields have rapidly been adopted for representing 3D signals, but their application to more classical 2D image-processing has been relatively limited. In this paper, we consider one of the most important operations in image processing: upsampling. In deep learning, learnable upsampling layers have extensively been used for single image super-resolution. We propose to parameterize upsampling kernels as neural fields. This parameterization leads to a compact architecture that obtains a 40-fold reduction in the number of parameters when compared with competing arbitrary-scale super-resolution architectures. When upsampling images of size 256x256 we show that our architecture is 2x-10x more efficient than competing arbitrary-scale super-resolution architectures, and more efficient than sub-pixel convolutions when instantiated to a single-scale model. In the general setting, these gains grow polynomially with the square of the target scale. We validate our method on standard benchmarks showing such efficiency gains can be achieved without sacrifices in super-resolution performance.
Learning to Improve Code Efficiency
Aug 09, 2022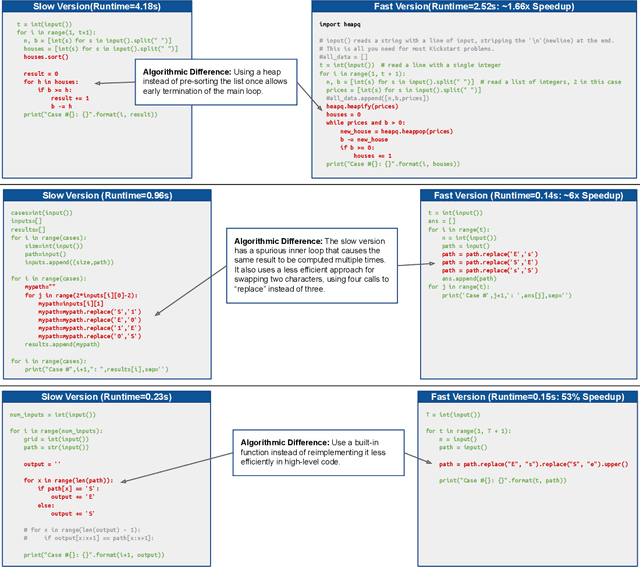
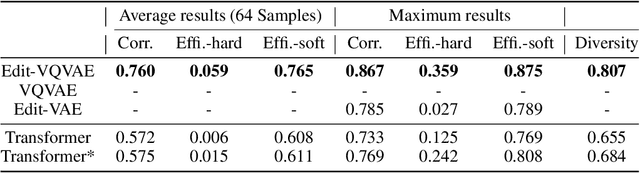
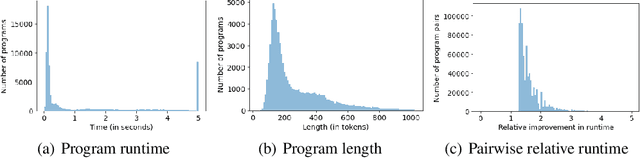

Improvements in the performance of computing systems, driven by Moore's Law, have transformed society. As such hardware-driven gains slow down, it becomes even more important for software developers to focus on performance and efficiency during development. While several studies have demonstrated the potential from such improved code efficiency (e.g., 2x better generational improvements compared to hardware), unlocking these gains in practice has been challenging. Reasoning about algorithmic complexity and the interaction of coding patterns on hardware can be challenging for the average programmer, especially when combined with pragmatic constraints around development velocity and multi-person development. This paper seeks to address this problem. We analyze a large competitive programming dataset from the Google Code Jam competition and find that efficient code is indeed rare, with a 2x runtime difference between the median and the 90th percentile of solutions. We propose using machine learning to automatically provide prescriptive feedback in the form of hints, to guide programmers towards writing high-performance code. To automatically learn these hints from the dataset, we propose a novel discrete variational auto-encoder, where each discrete latent variable represents a different learned category of code-edit that increases performance. We show that this method represents the multi-modal space of code efficiency edits better than a sequence-to-sequence baseline and generates a distribution of more efficient solutions.
Pre-training helps Bayesian optimization too
Jul 07, 2022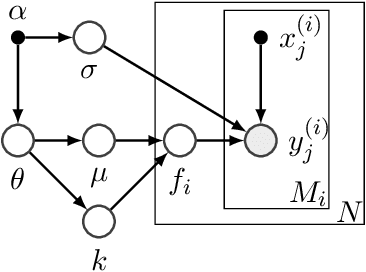
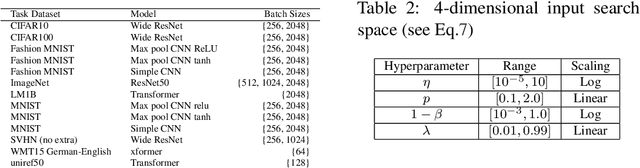
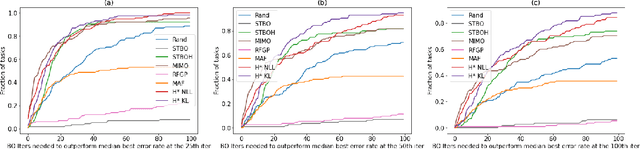
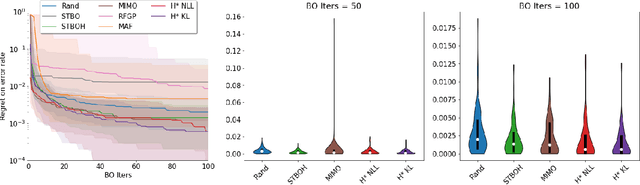
Bayesian optimization (BO) has become a popular strategy for global optimization of many expensive real-world functions. Contrary to a common belief that BO is suited to optimizing black-box functions, it actually requires domain knowledge on characteristics of those functions to deploy BO successfully. Such domain knowledge often manifests in Gaussian process priors that specify initial beliefs on functions. However, even with expert knowledge, it is not an easy task to select a prior. This is especially true for hyperparameter tuning problems on complex machine learning models, where landscapes of tuning objectives are often difficult to comprehend. We seek an alternative practice for setting these functional priors. In particular, we consider the scenario where we have data from similar functions that allow us to pre-train a tighter distribution a priori. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
Data-Driven Offline Optimization For Architecting Hardware Accelerators
Oct 20, 2021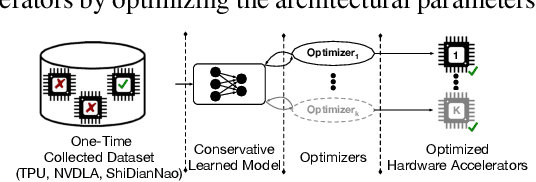
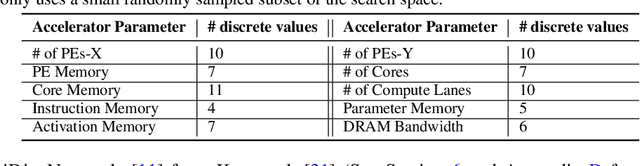
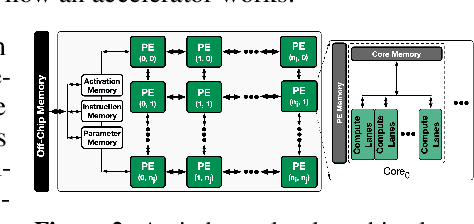
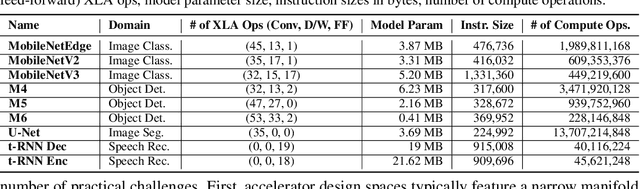
Industry has gradually moved towards application-specific hardware accelerators in order to attain higher efficiency. While such a paradigm shift is already starting to show promising results, designers need to spend considerable manual effort and perform a large number of time-consuming simulations to find accelerators that can accelerate multiple target applications while obeying design constraints. Moreover, such a "simulation-driven" approach must be re-run from scratch every time the set of target applications or design constraints change. An alternative paradigm is to use a "data-driven", offline approach that utilizes logged simulation data, to architect hardware accelerators, without needing any form of simulations. Such an approach not only alleviates the need to run time-consuming simulation, but also enables data reuse and applies even when set of target applications changes. In this paper, we develop such a data-driven offline optimization method for designing hardware accelerators, dubbed PRIME, that enjoys all of these properties. Our approach learns a conservative, robust estimate of the desired cost function, utilizes infeasible points, and optimizes the design against this estimate without any additional simulator queries during optimization. PRIME architects accelerators -- tailored towards both single and multiple applications -- improving performance upon state-of-the-art simulation-driven methods by about 1.54x and 1.20x, while considerably reducing the required total simulation time by 93% and 99%, respectively. In addition, PRIME also architects effective accelerators for unseen applications in a zero-shot setting, outperforming simulation-based methods by 1.26x.
Automatic prior selection for meta Bayesian optimization with a case study on tuning deep neural network optimizers
Sep 16, 2021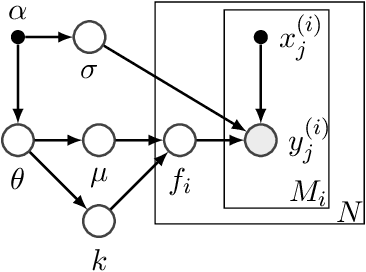
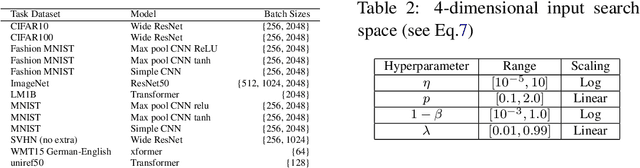
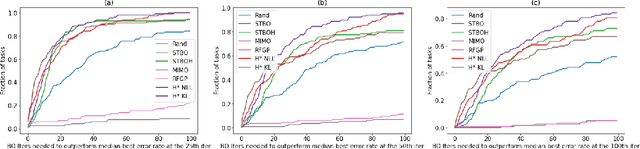
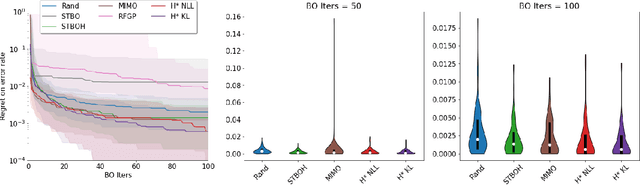
The performance of deep neural networks can be highly sensitive to the choice of a variety of meta-parameters, such as optimizer parameters and model hyperparameters. Tuning these well, however, often requires extensive and costly experimentation. Bayesian optimization (BO) is a principled approach to solve such expensive hyperparameter tuning problems efficiently. Key to the performance of BO is specifying and refining a distribution over functions, which is used to reason about the optima of the underlying function being optimized. In this work, we consider the scenario where we have data from similar functions that allows us to specify a tighter distribution a priori. Specifically, we focus on the common but potentially costly task of tuning optimizer parameters for training neural networks. Building on the meta BO method from Wang et al. (2018), we develop practical improvements that (a) boost its performance by leveraging tuning results on multiple tasks without requiring observations for the same meta-parameter points across all tasks, and (b) retain its regret bound for a special case of our method. As a result, we provide a coherent BO solution for iterative optimization of continuous optimizer parameters. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
Two Sides of the Same Coin: Heterophily and Oversmoothing in Graph Convolutional Neural Networks
Feb 24, 2021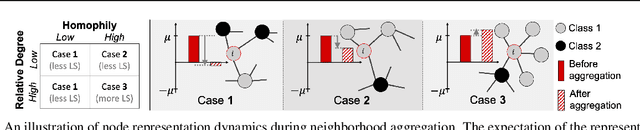
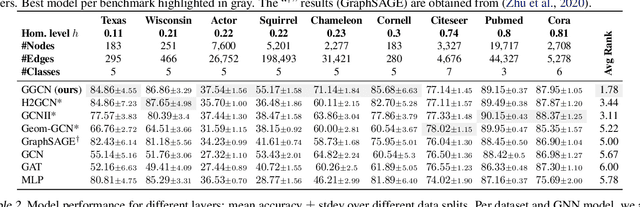
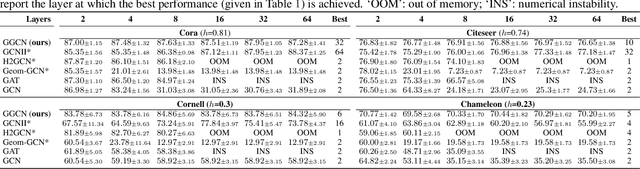
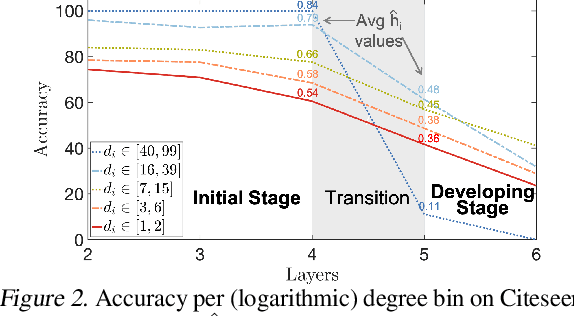
Most graph neural networks (GNN) perform poorly in graphs where neighbors typically have different features/classes (heterophily) and when stacking multiple layers (oversmoothing). These two seemingly unrelated problems have been studied independently, but there is recent empirical evidence that solving one problem may benefit the other. In this work, going beyond empirical observations, we theoretically characterize the connections between heterophily and oversmoothing, both of which lead to indistinguishable node representations. By modeling the change in node representations during message propagation, we theoretically analyze the factors (e.g., degree, heterophily level) that make the representations of nodes from different classes indistinguishable. Our analysis highlights that (1) nodes with high heterophily and nodes with low heterophily and low degrees relative to their neighbors (degree discrepancy) trigger the oversmoothing problem, and (2) allowing "negative" messages between neighbors can decouple the heterophily and oversmoothing problems. Based on our insights, we design a model that addresses the discrepancy in features and degrees between neighbors by incorporating signed messages and learned degree corrections. Our experiments on 9 real networks show that our model achieves state-of-the-art performance under heterophily, and performs comparably to existing GNNs under low heterophily(homophily). It also effectively addresses oversmoothing and even benefits from multiple layers.
Oops I Took A Gradient: Scalable Sampling for Discrete Distributions
Feb 08, 2021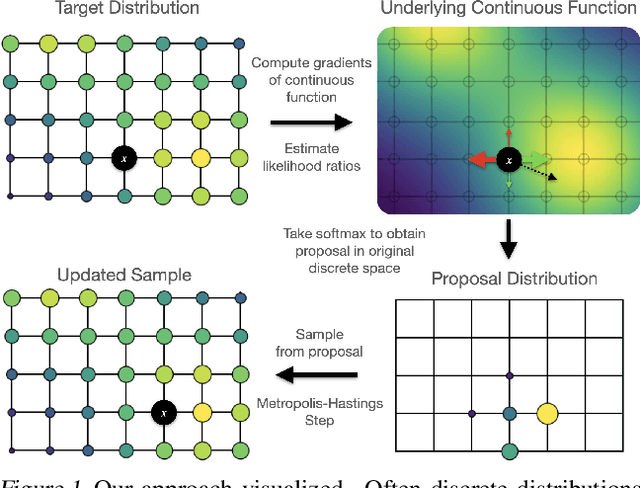

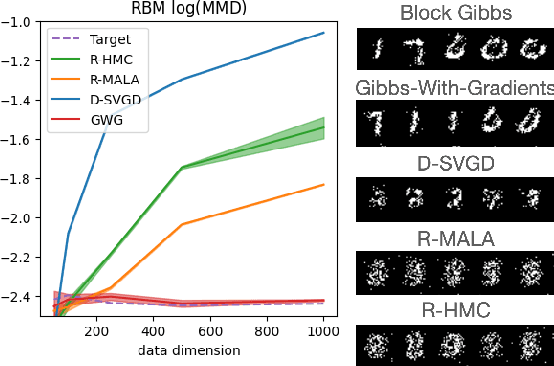
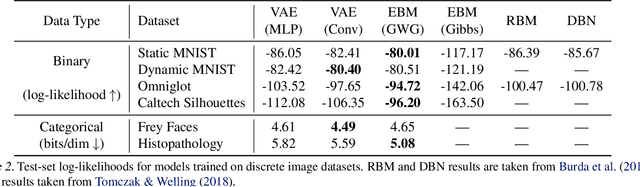
We propose a general and scalable approximate sampling strategy for probabilistic models with discrete variables. Our approach uses gradients of the likelihood function with respect to its discrete inputs to propose updates in a Metropolis-Hastings sampler. We show empirically that this approach outperforms generic samplers in a number of difficult settings including Ising models, Potts models, restricted Boltzmann machines, and factorial hidden Markov models. We also demonstrate the use of our improved sampler for training deep energy-based models on high dimensional discrete data. This approach outperforms variational auto-encoders and existing energy-based models. Finally, we give bounds showing that our approach is near-optimal in the class of samplers which propose local updates.