 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Example Generation with Syntactically Controlled Paraphrase Networks
Apr 17, 2018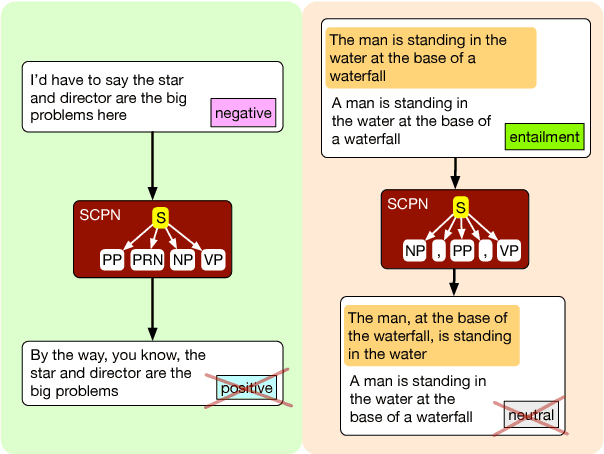
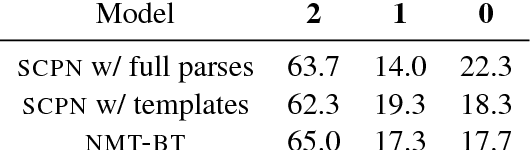
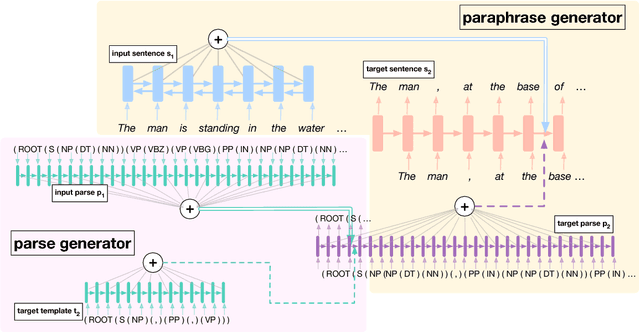

We propose syntactically controlled paraphrase networks (SCPNs) and use them to generate adversarial examples. Given a sentence and a target syntactic form (e.g., a constituency parse), SCPNs are trained to produce a paraphrase of the sentence with the desired syntax. We show it is possible to create training data for this task by first doing backtranslation at a very large scale, and then using a parser to label the syntactic transformations that naturally occur during this process. Such data allows us to train a neural encoder-decoder model with extra inputs to specify the target syntax. A combination of automated and human evaluations show that SCPNs generate paraphrases that follow their target specifications without decreasing paraphrase quality when compared to baseline (uncontrolled) paraphrase systems. Furthermore, they are more capable of generating syntactically adversarial examples that both (1) "fool" pretrained models and (2) improve the robustness of these models to syntactic variation when used to augment their training data.
Parsing Speech: A Neural Approach to Integrating Lexical and Acoustic-Prosodic Information
Apr 15, 2018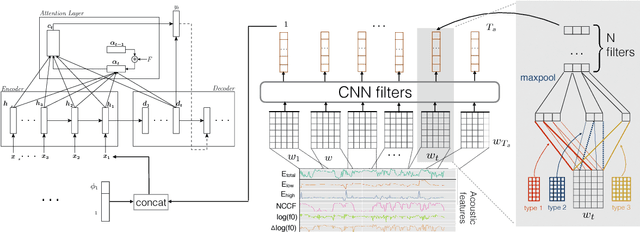
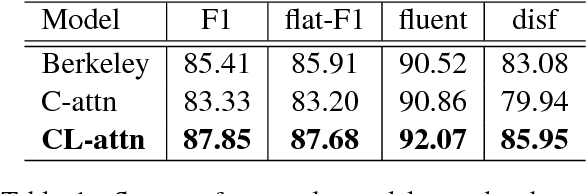
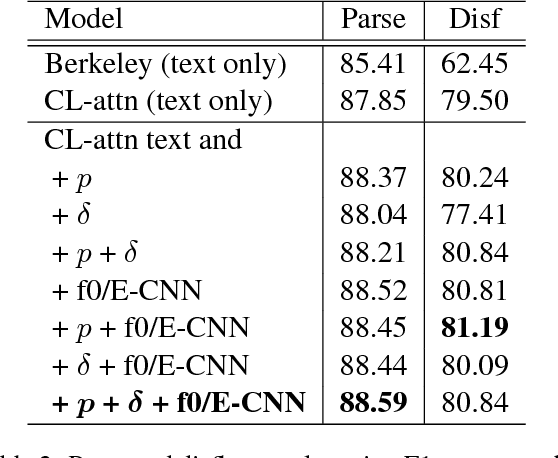
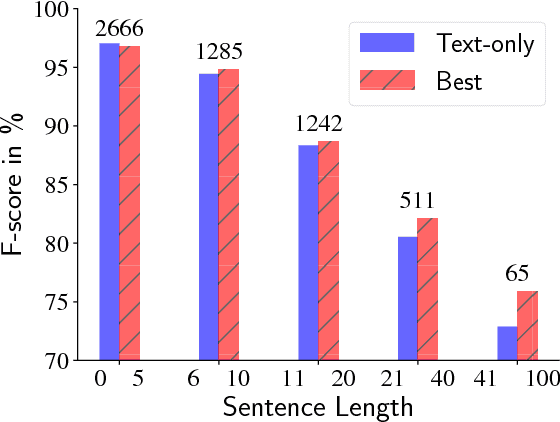
In conversational speech, the acoustic signal provides cues that help listeners disambiguate difficult parses. For automatically parsing spoken utterances, we introduce a model that integrates transcribed text and acoustic-prosodic features using a convolutional neural network over energy and pitch trajectories coupled with an attention-based recurrent neural network that accepts text and prosodic features. We find that different types of acoustic-prosodic features are individually helpful, and together give statistically significant improvements in parse and disfluency detection F1 scores over a strong text-only baseline. For this study with known sentence boundaries, error analyses show that the main benefit of acoustic-prosodic features is in sentences with disfluencies, attachment decisions are most improved, and transcription errors obscure gains from prosody.
Learning Approximate Inference Networks for Structured Prediction
Mar 09, 2018

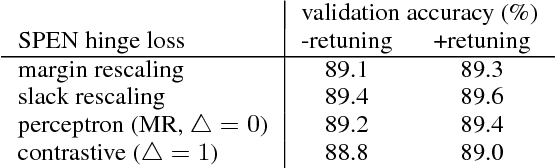

Structured prediction energy networks (SPENs; Belanger & McCallum 2016) use neural network architectures to define energy functions that can capture arbitrary dependencies among parts of structured outputs. Prior work used gradient descent for inference, relaxing the structured output to a set of continuous variables and then optimizing the energy with respect to them. We replace this use of gradient descent with a neural network trained to approximate structured argmax inference. This "inference network" outputs continuous values that we treat as the output structure. We develop large-margin training criteria for joint training of the structured energy function and inference network. On multi-label classification we report speed-ups of 10-60x compared to (Belanger et al, 2017) while also improving accuracy. For sequence labeling with simple structured energies, our approach performs comparably to exact inference while being much faster at test time. We then demonstrate improved accuracy by augmenting the energy with a "label language model" that scores entire output label sequences, showing it can improve handling of long-distance dependencies in part-of-speech tagging. Finally, we show how inference networks can replace dynamic programming for test-time inference in conditional random fields, suggestive for their general use for fast inference in structured settings.
A Study of All-Convolutional Encoders for Connectionist Temporal Classification
Feb 15, 2018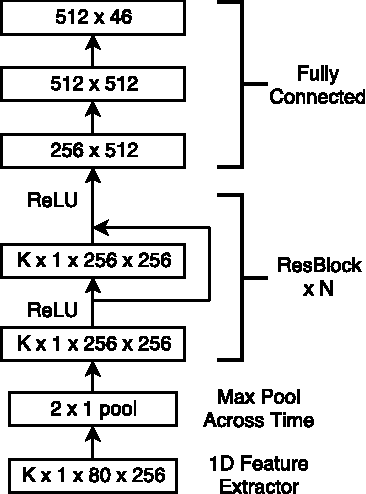
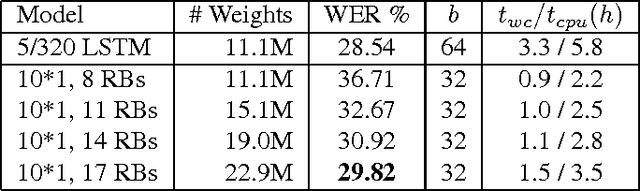
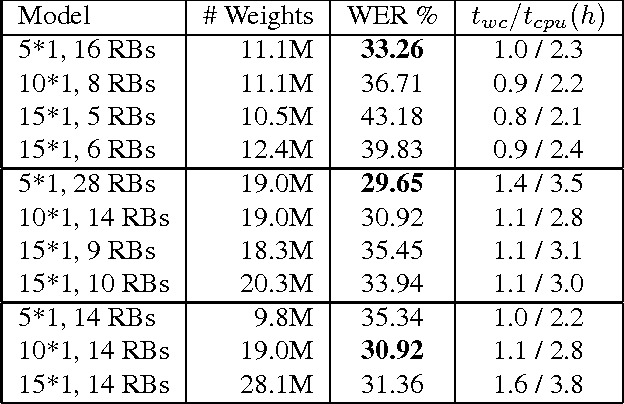
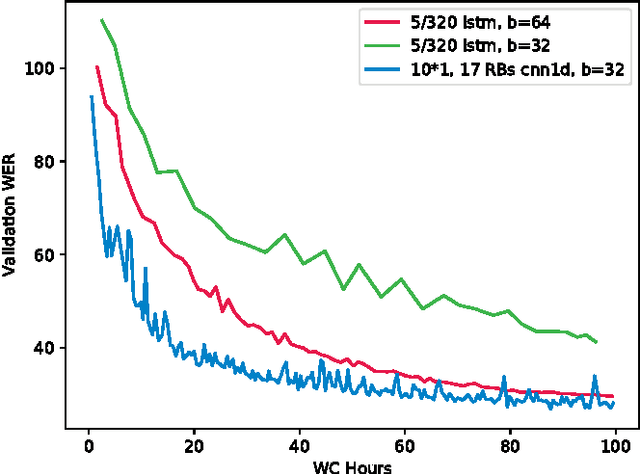
Connectionist temporal classification (CTC) is a popular sequence prediction approach for automatic speech recognition that is typically used with models based on recurrent neural networks (RNNs). We explore whether deep convolutional neural networks (CNNs) can be used effectively instead of RNNs as the "encoder" in CTC. CNNs lack an explicit representation of the entire sequence, but have the advantage that they are much faster to train. We present an exploration of CNNs as encoders for CTC models, in the context of character-based (lexicon-free) automatic speech recognition. In particular, we explore a range of one-dimensional convolutional layers, which are particularly efficient. We compare the performance of our CNN-based models against typical RNNbased models in terms of training time, decoding time, model size and word error rate (WER) on the Switchboard Eval2000 corpus. We find that our CNN-based models are close in performance to LSTMs, while not matching them, and are much faster to train and decode.
End-to-End Neural Segmental Models for Speech Recognition
Aug 15, 2017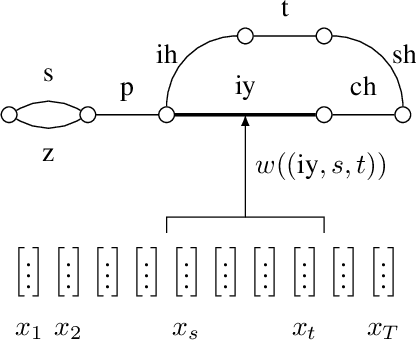
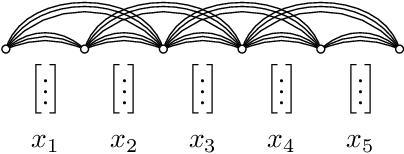
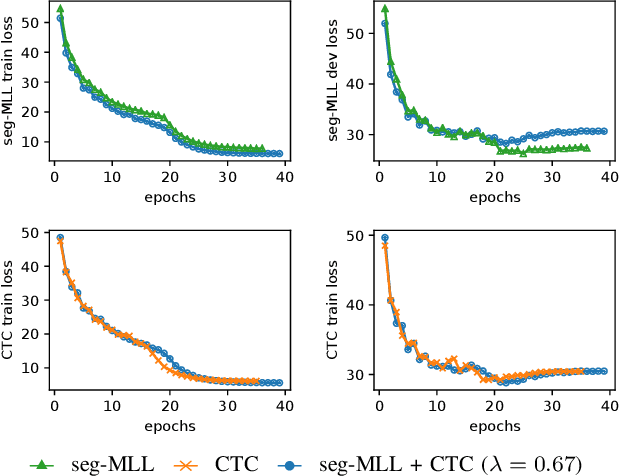
Segmental models are an alternative to frame-based models for sequence prediction, where hypothesized path weights are based on entire segment scores rather than a single frame at a time. Neural segmental models are segmental models that use neural network-based weight functions. Neural segmental models have achieved competitive results for speech recognition, and their end-to-end training has been explored in several studies. In this work, we review neural segmental models, which can be viewed as consisting of a neural network-based acoustic encoder and a finite-state transducer decoder. We study end-to-end segmental models with different weight functions, including ones based on frame-level neural classifiers and on segmental recurrent neural networks. We study how reducing the search space size impacts performance under different weight functions. We also compare several loss functions for end-to-end training. Finally, we explore training approaches, including multi-stage vs. end-to-end training and multitask training that combines segmental and frame-level losses.
Learning to Embed Words in Context for Syntactic Tasks
Jun 12, 2017


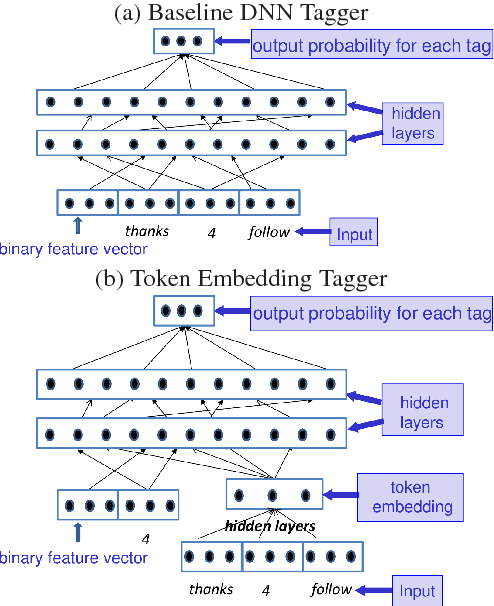
We present models for embedding words in the context of surrounding words. Such models, which we refer to as token embeddings, represent the characteristics of a word that are specific to a given context, such as word sense, syntactic category, and semantic role. We explore simple, efficient token embedding models based on standard neural network architectures. We learn token embeddings on a large amount of unannotated text and evaluate them as features for part-of-speech taggers and dependency parsers trained on much smaller amounts of annotated data. We find that predictors endowed with token embeddings consistently outperform baseline predictors across a range of context window and training set sizes.
Learning Paraphrastic Sentence Embeddings from Back-Translated Bitext
Jun 06, 2017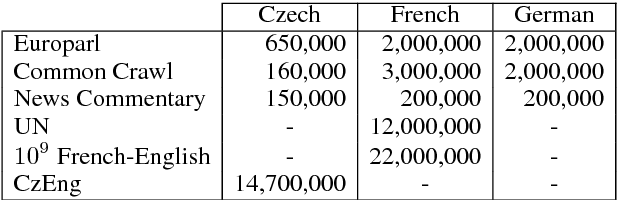

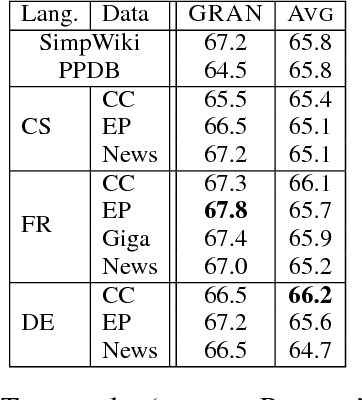
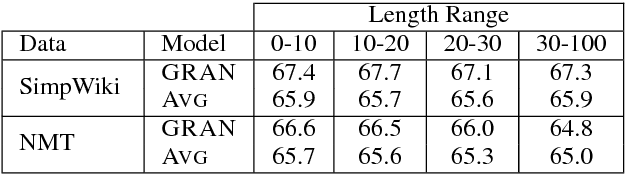
We consider the problem of learning general-purpose, paraphrastic sentence embeddings in the setting of Wieting et al. (2016b). We use neural machine translation to generate sentential paraphrases via back-translation of bilingual sentence pairs. We evaluate the paraphrase pairs by their ability to serve as training data for learning paraphrastic sentence embeddings. We find that the data quality is stronger than prior work based on bitext and on par with manually-written English paraphrase pairs, with the advantage that our approach can scale up to generate large training sets for many languages and domains. We experiment with several language pairs and data sources, and develop a variety of data filtering techniques. In the process, we explore how neural machine translation output differs from human-written sentences, finding clear differences in length, the amount of repetition, and the use of rare words.
Emergent Predication Structure in Hidden State Vectors of Neural Readers
May 31, 2017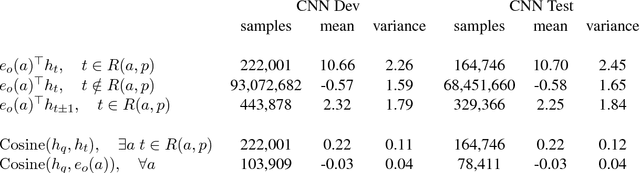
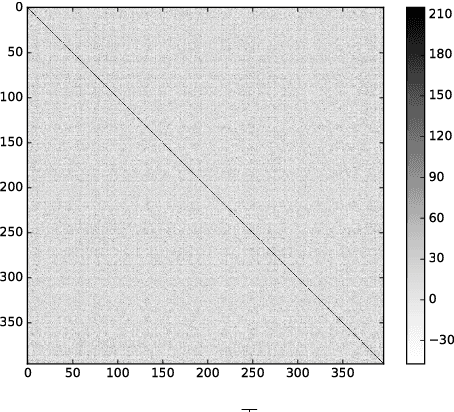


A significant number of neural architectures for reading comprehension have recently been developed and evaluated on large cloze-style datasets. We present experiments supporting the emergence of "predication structure" in the hidden state vectors of these readers. More specifically, we provide evidence that the hidden state vectors represent atomic formulas $\Phi[c]$ where $\Phi$ is a semantic property (predicate) and $c$ is a constant symbol entity identifier.
Revisiting Recurrent Networks for Paraphrastic Sentence Embeddings
Apr 30, 2017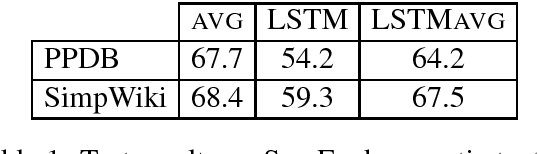
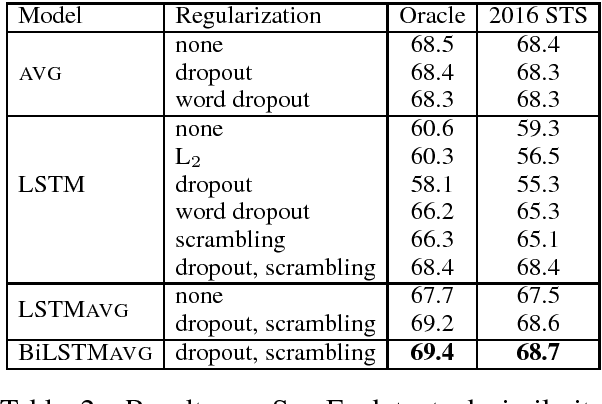

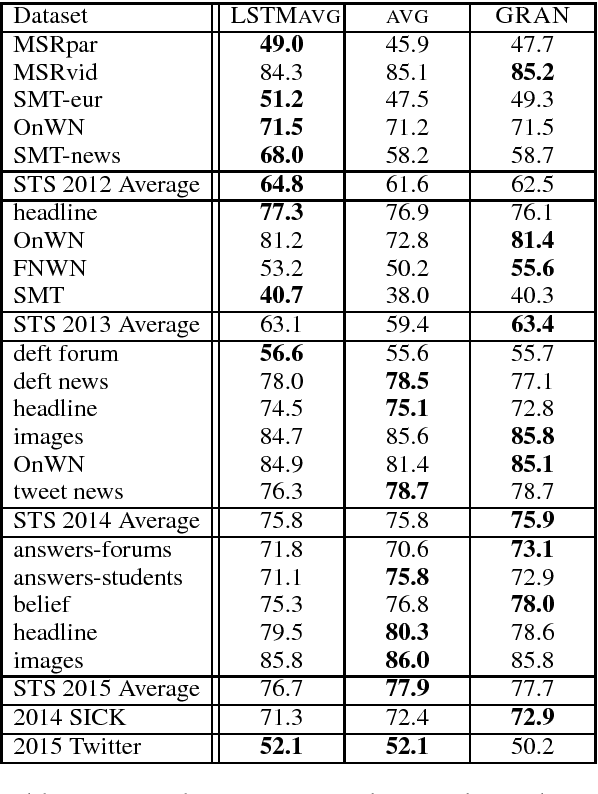
We consider the problem of learning general-purpose, paraphrastic sentence embeddings, revisiting the setting of Wieting et al. (2016b). While they found LSTM recurrent networks to underperform word averaging, we present several developments that together produce the opposite conclusion. These include training on sentence pairs rather than phrase pairs, averaging states to represent sequences, and regularizing aggressively. These improve LSTMs in both transfer learning and supervised settings. We also introduce a new recurrent architecture, the Gated Recurrent Averaging Network, that is inspired by averaging and LSTMs while outperforming them both. We analyze our learned models, finding evidence of preferences for particular parts of speech and dependency relations.
Adjusting for Dropout Variance in Batch Normalization and Weight Initialization
Mar 23, 2017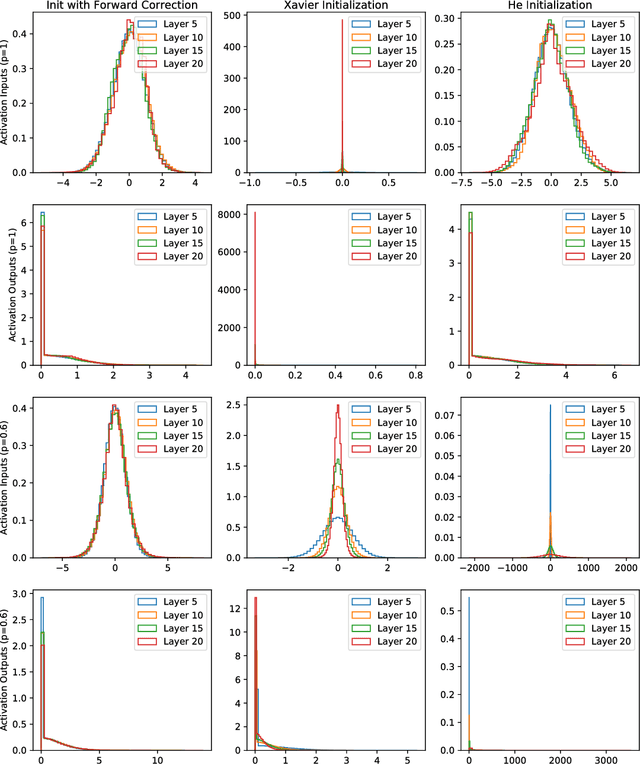
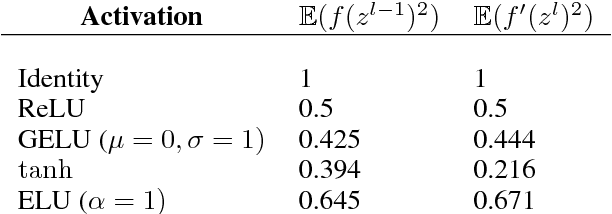
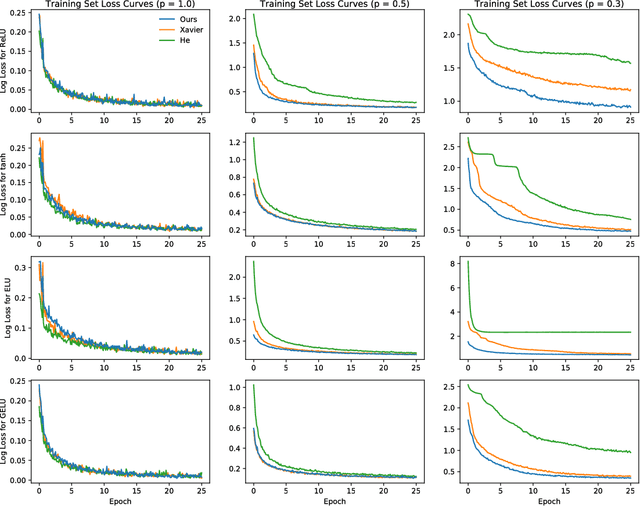

We show how to adjust for the variance introduced by dropout with corrections to weight initialization and Batch Normalization, yielding higher accuracy. Though dropout can preserve the expected input to a neuron between train and test, the variance of the input differs. We thus propose a new weight initialization by correcting for the influence of dropout rates and an arbitrary nonlinearity's influence on variance through simple corrective scalars. Since Batch Normalization trained with dropout estimates the variance of a layer's incoming distribution with some inputs dropped, the variance also differs between train and test. After training a network with Batch Normalization and dropout, we simply update Batch Normalization's variance moving averages with dropout off and obtain state of the art on CIFAR-10 and CIFAR-100 without data augmentation.