 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Ask Better Questions? A Large-Scale Multi-Domain Dataset for Rewriting Ill-Formed Questions
Nov 21, 2019
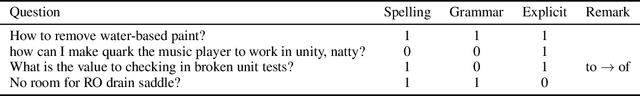


We present a large-scale dataset for the task of rewriting an ill-formed natural language question to a well-formed one. Our multi-domain question rewriting MQR dataset is constructed from human contributed Stack Exchange question edit histories. The dataset contains 427,719 question pairs which come from 303 domains. We provide human annotations for a subset of the dataset as a quality estimate. When moving from ill-formed to well-formed questions, the question quality improves by an average of 45 points across three aspects. We train sequence-to-sequence neural models on the constructed dataset and obtain an improvement of 13.2% in BLEU-4 over baseline methods built from other data resources. We release the MQR dataset to encourage research on the problem of question rewriting.
Improving Joint Training of Inference Networks and Structured Prediction Energy Networks
Nov 07, 2019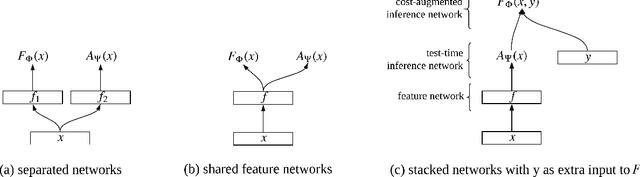
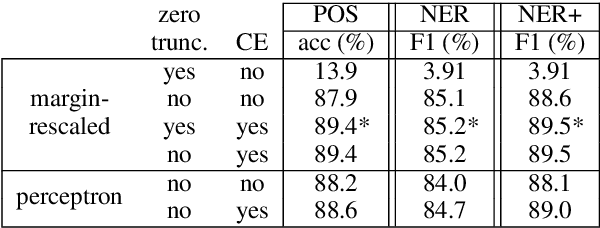
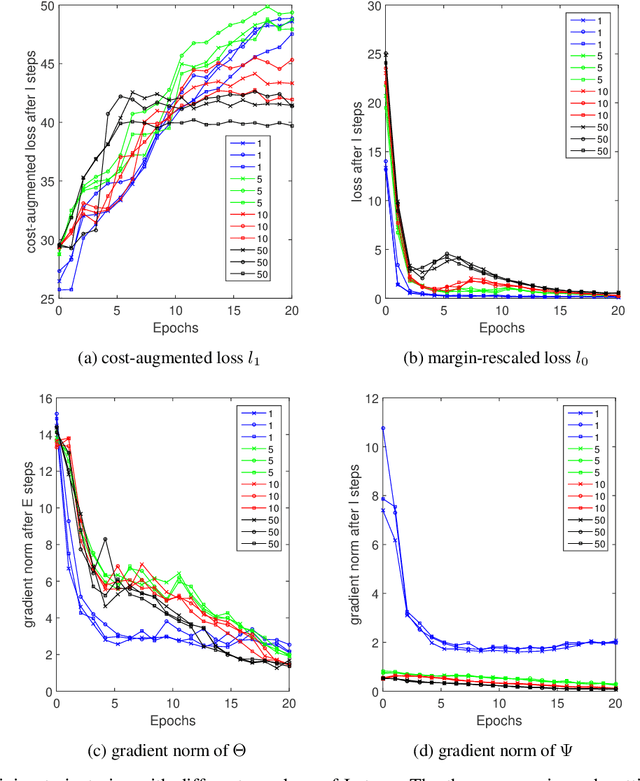
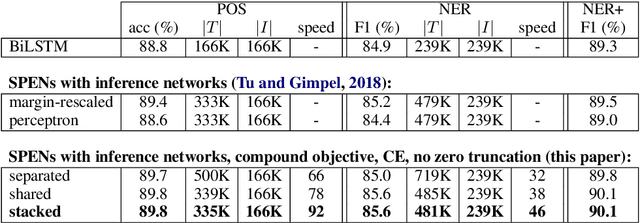
Deep energy-based models are powerful, but pose challenges for learning and inference (Belanger and McCallum, 2016). Tu and Gimpel (2018) developed an efficient framework for energy-based models by training "inference networks" to approximate structured inference instead of using gradient descent. However, their alternating optimization approach suffers from instabilities during training, requiring additional loss terms and careful hyperparameter tuning. In this paper, we contribute several strategies to stabilize and improve this joint training of energy functions and inference networks for structured prediction. We design a compound objective to jointly train both cost-augmented and test-time inference networks along with the energy function. We propose joint parameterizations for the inference networks that encourage them to capture complementary functionality during learning. We empirically validate our strategies on two sequence labeling tasks, showing easier paths to strong performance than prior work, as well as further improvements with global energy terms.
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Oct 30, 2019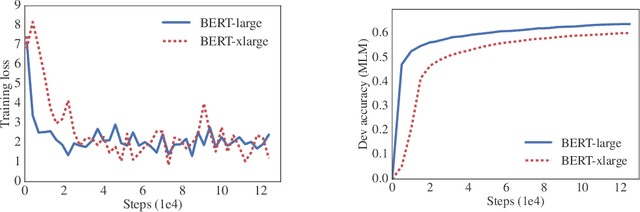

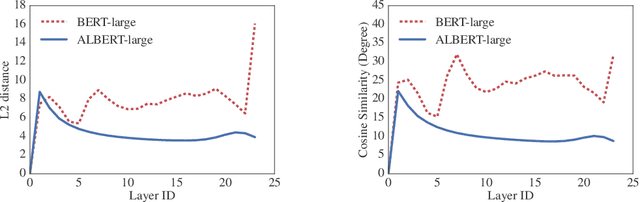

Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations, longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows that our proposed methods lead to models that scale much better compared to the original BERT. We also use a self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and SQuAD benchmarks while having fewer parameters compared to BERT-large.The code and the pretrained models are available at https://github.com/google-research/google-research/tree/master/albert.
Latent-Variable Generative Models for Data-Efficient Text Classification
Oct 01, 2019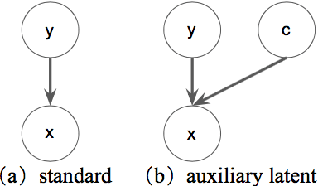
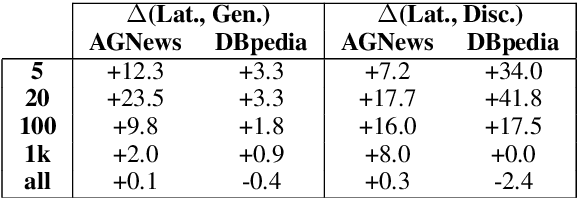
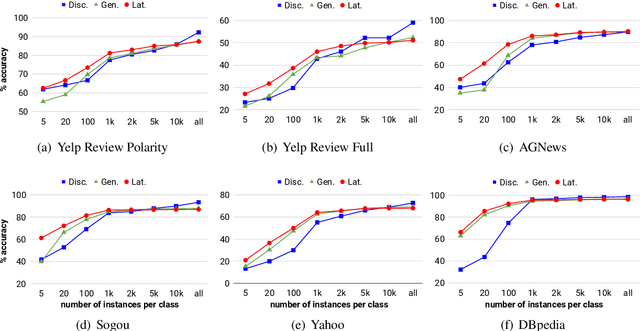
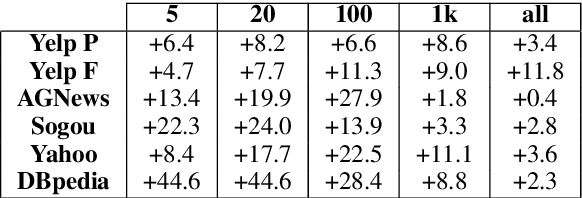
Generative classifiers offer potential advantages over their discriminative counterparts, namely in the areas of data efficiency, robustness to data shift and adversarial examples, and zero-shot learning (Ng and Jordan,2002; Yogatama et al., 2017; Lewis and Fan,2019). In this paper, we improve generative text classifiers by introducing discrete latent variables into the generative story, and explore several graphical model configurations. We parameterize the distributions using standard neural architectures used in conditional language modeling and perform learning by directly maximizing the log marginal likelihood via gradient-based optimization, which avoids the need to do expectation-maximization. We empirically characterize the performance of our models on six text classification datasets. The choice of where to include the latent variable has a significant impact on performance, with the strongest results obtained when using the latent variable as an auxiliary conditioning variable in the generation of the textual input. This model consistently outperforms both the generative and discriminative classifiers in small-data settings. We analyze our model by using it for controlled generation, finding that the latent variable captures interpretable properties of the data, even with very small training sets.
Simple and Effective Paraphrastic Similarity from Parallel Translations
Sep 30, 2019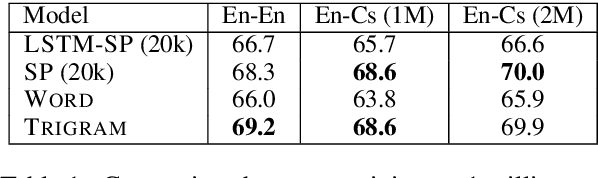
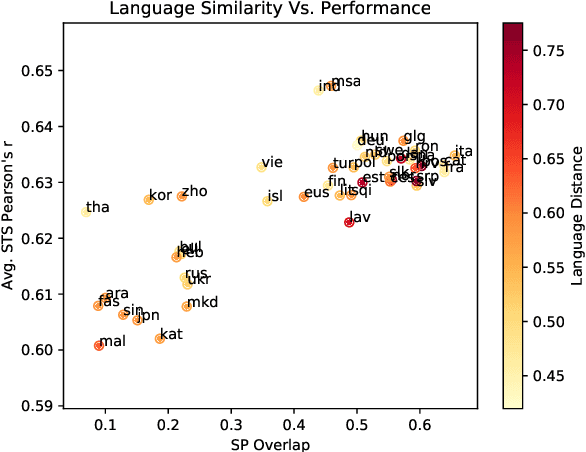
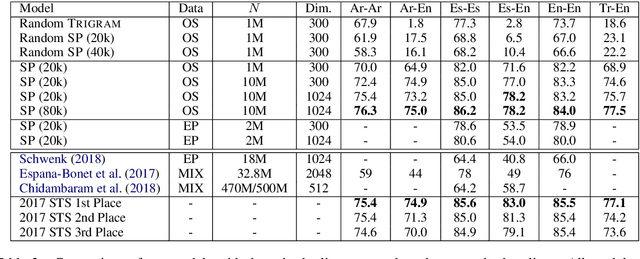
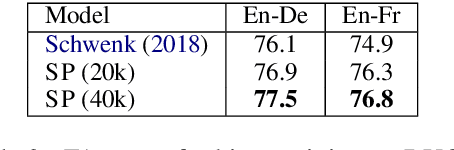
We present a model and methodology for learning paraphrastic sentence embeddings directly from bitext, removing the time-consuming intermediate step of creating paraphrase corpora. Further, we show that the resulting model can be applied to cross-lingual tasks where it both outperforms and is orders of magnitude faster than more complex state-of-the-art baselines.
Generating Diverse Story Continuations with Controllable Semantics
Sep 30, 2019
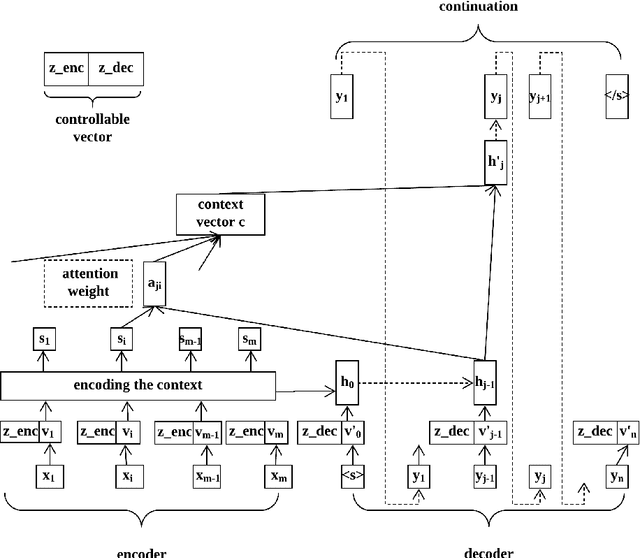
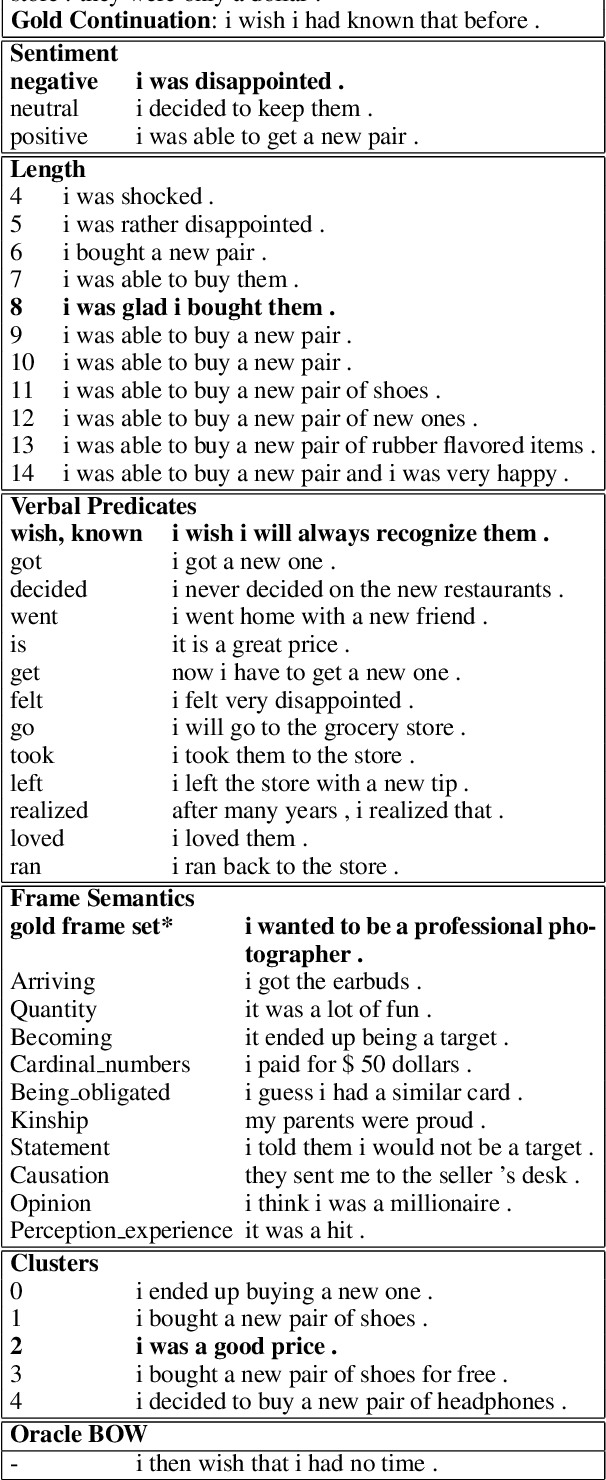
We propose a simple and effective modeling framework for controlled generation of multiple, diverse outputs. We focus on the setting of generating the next sentence of a story given its context. As controllable dimensions, we consider several sentence attributes, including sentiment, length, predicates, frames, and automatically-induced clusters. Our empirical results demonstrate: (1) our framework is accurate in terms of generating outputs that match the target control values; (2) our model yields increased maximum metric scores compared to standard n-best list generation via beam search; (3) controlling generation with semantic frames leads to a stronger combination of diversity and quality than other control variables as measured by automatic metrics. We also conduct a human evaluation to assess the utility of providing multiple suggestions for creative writing, demonstrating promising results for the potential of controllable, diverse generation in a collaborative writing system.
Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
Sep 14, 2019



While most neural machine translation (NMT) systems are still trained using maximum likelihood estimation, recent work has demonstrated that optimizing systems to directly improve evaluation metrics such as BLEU can substantially improve final translation accuracy. However, training with BLEU has some limitations: it doesn't assign partial credit, it has a limited range of output values, and it can penalize semantically correct hypotheses if they differ lexically from the reference. In this paper, we introduce an alternative reward function for optimizing NMT systems that is based on recent work in semantic similarity. We evaluate on four disparate languages translated to English, and find that training with our proposed metric results in better translations as evaluated by BLEU, semantic similarity, and human evaluation, and also that the optimization procedure converges faster. Analysis suggests that this is because the proposed metric is more conducive to optimization, assigning partial credit and providing more diversity in scores than BLEU.
Evaluation Benchmarks and Learning Criteriafor Discourse-Aware Sentence Representations
Aug 31, 2019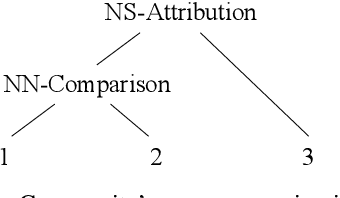
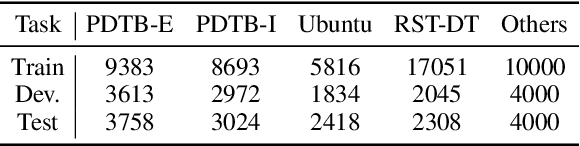

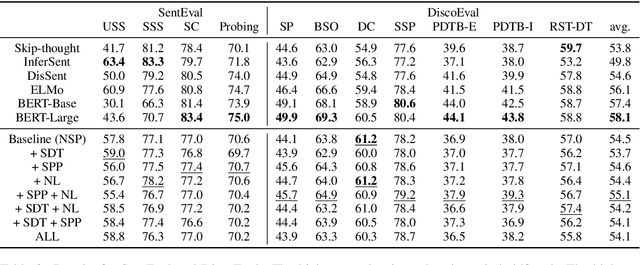
Prior work on pretrained sentence embeddings and benchmarks focus on the capabilities of stand-alone sentences. We propose DiscoEval, a test suite of tasks to evaluate whether sentence representations include broader context information. We also propose a variety of training objectives that makes use of natural annotations from Wikipedia to build sentence encoders capable of modeling discourse. We benchmark sentence encoders pretrained with our proposed training objectives, as well as other popular pretrained sentence encoders on DiscoEval and other sentence evaluation tasks. Empirically, we show that these training objectives help to encode different aspects of information in document structures. Moreover, BERT and ELMo demonstrate strong performances over DiscoEval with individual hidden layers showing different characteristics.
EntEval: A Holistic Evaluation Benchmark for Entity Representations
Aug 31, 2019

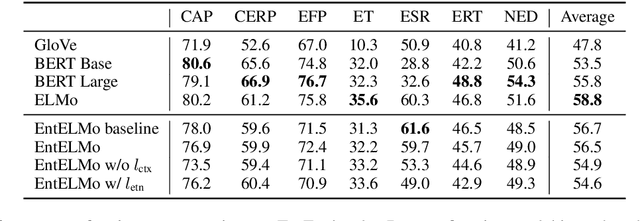
Rich entity representations are useful for a wide class of problems involving entities. Despite their importance, there is no standardized benchmark that evaluates the overall quality of entity representations. In this work, we propose EntEval: a test suite of diverse tasks that require nontrivial understanding of entities including entity typing, entity similarity, entity relation prediction, and entity disambiguation. In addition, we develop training techniques for learning better entity representations by using natural hyperlink annotations in Wikipedia. We identify effective objectives for incorporating the contextual information in hyperlinks into state-of-the-art pretrained language models and show that they improve strong baselines on multiple EntEval tasks.
Variational Sequential Labelers for Semi-Supervised Learning
Jun 23, 2019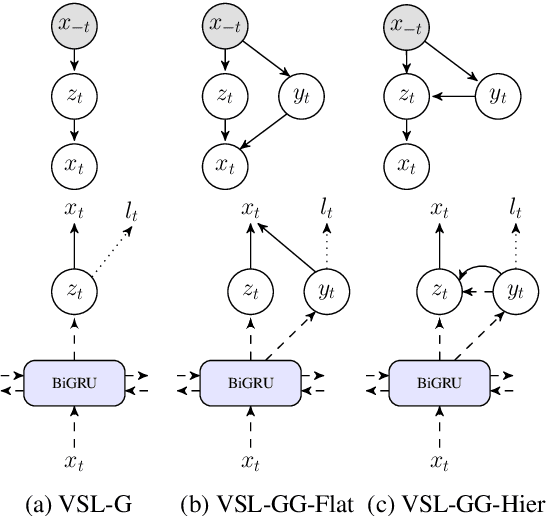

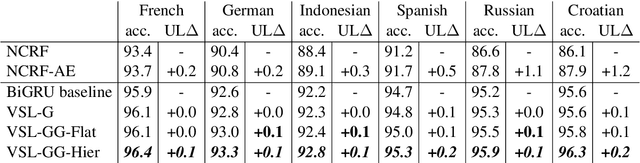
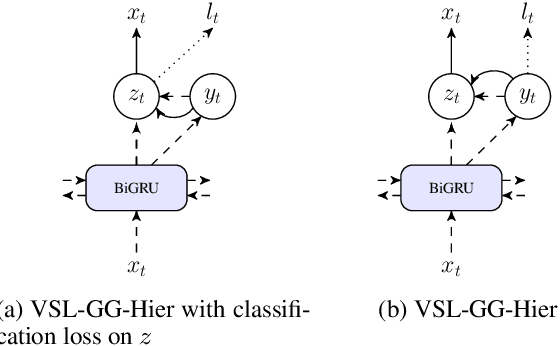
We introduce a family of multitask variational methods for semi-supervised sequence labeling. Our model family consists of a latent-variable generative model and a discriminative labeler. The generative models use latent variables to define the conditional probability of a word given its context, drawing inspiration from word prediction objectives commonly used in learning word embeddings. The labeler helps inject discriminative information into the latent space. We explore several latent variable configurations, including ones with hierarchical structure, which enables the model to account for both label-specific and word-specific information. Our models consistently outperform standard sequential baselines on 8 sequence labeling datasets, and improve further with unlabeled data.