 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVRecap: A Dataset for Generating Stories with Character Descriptions
Sep 18, 2021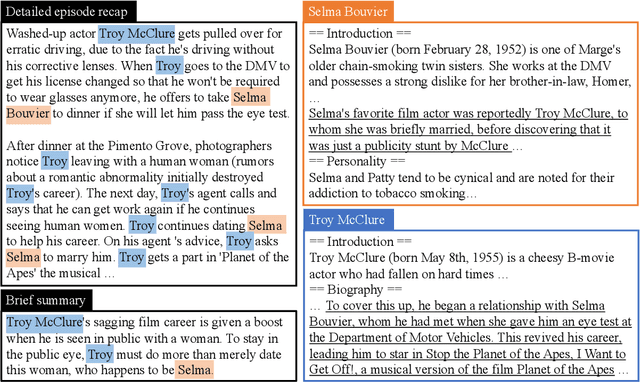
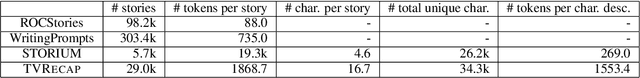

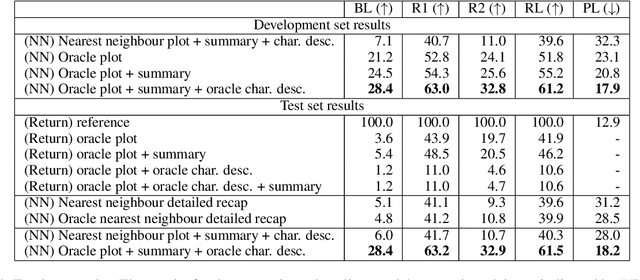
We introduce TVRecap, a story generation dataset that requires generating detailed TV show episode recaps from a brief summary and a set of documents describing the characters involved. Unlike other story generation datasets, TVRecap contains stories that are authored by professional screenwriters and that feature complex interactions among multiple characters. Generating stories in TVRecap requires drawing relevant information from the lengthy provided documents about characters based on the brief summary. In addition, by swapping the input and output, TVRecap can serve as a challenging testbed for abstractive summarization. We create TVRecap from fan-contributed websites, which allows us to collect 26k episode recaps with 1868.7 tokens on average. Empirically, we take a hierarchical story generation approach and find that the neural model that uses oracle content selectors for character descriptions demonstrates the best performance on automatic metrics, showing the potential of our dataset to inspire future research on story generation with constraints. Qualitative analysis shows that the best-performing model sometimes generates content that is unfaithful to the short summaries, suggesting promising directions for future work.
Paraphrastic Representations at Scale
Apr 30, 2021


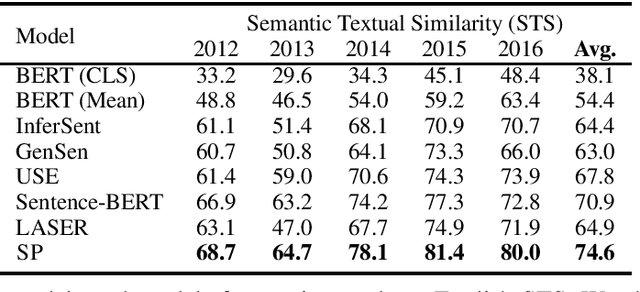
We present a system that allows users to train their own state-of-the-art paraphrastic sentence representations in a variety of languages. We also release trained models for English, Arabic, German, French, Spanish, Russian, Turkish, and Chinese. We train these models on large amounts of data, achieving significantly improved performance from the original papers proposing the methods on a suite of monolingual semantic similarity, cross-lingual semantic similarity, and bitext mining tasks. Moreover, the resulting models surpass all prior work on unsupervised semantic textual similarity, significantly outperforming even BERT-based models like Sentence-BERT (Reimers and Gurevych, 2019). Additionally, our models are orders of magnitude faster than prior work and can be used on CPU with little difference in inference speed (even improved speed over GPU when using more CPU cores), making these models an attractive choice for users without access to GPUs or for use on embedded devices. Finally, we add significantly increased functionality to the code bases for training paraphrastic sentence models, easing their use for both inference and for training them for any desired language with parallel data. We also include code to automatically download and preprocess training data.
SummScreen: A Dataset for Abstractive Screenplay Summarization
Apr 14, 2021
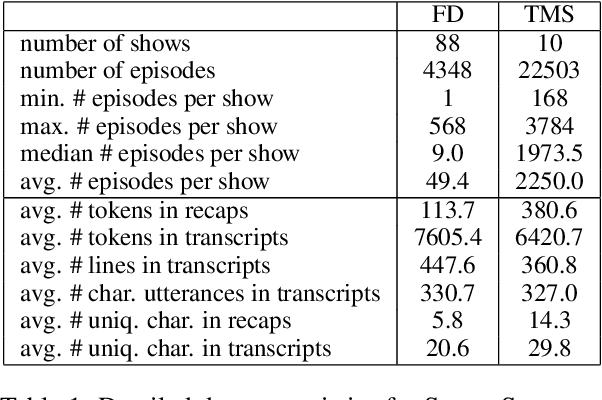
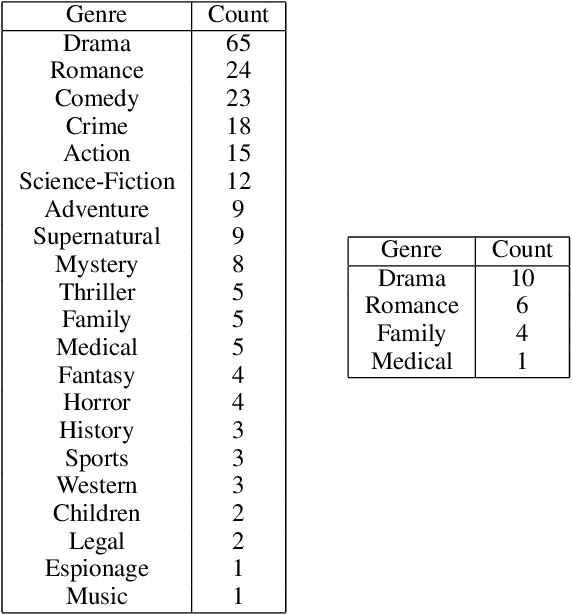
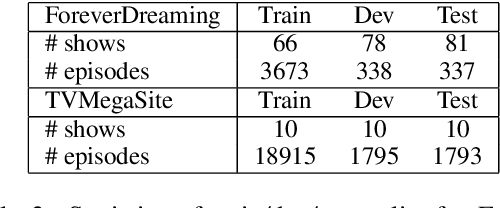
We introduce SummScreen, a summarization dataset comprised of pairs of TV series transcripts and human written recaps. The dataset provides a challenging testbed for abstractive summarization for several reasons. Plot details are often expressed indirectly in character dialogues and may be scattered across the entirety of the transcript. These details must be found and integrated to form the succinct plot descriptions in the recaps. Also, TV scripts contain content that does not directly pertain to the central plot but rather serves to develop characters or provide comic relief. This information is rarely contained in recaps. Since characters are fundamental to TV series, we also propose two entity-centric evaluation metrics. Empirically, we characterize the dataset by evaluating several methods, including neural models and those based on nearest neighbors. An oracle extractive approach outperforms all benchmarked models according to automatic metrics, showing that the neural models are unable to fully exploit the input transcripts. Human evaluation and qualitative analysis reveal that our non-oracle models are competitive with their oracle counterparts in terms of generating faithful plot events and can benefit from better content selectors. Both oracle and non-oracle models generate unfaithful facts, suggesting future research directions.
Learning Chess Blindfolded: Evaluating Language Models on State Tracking
Feb 26, 2021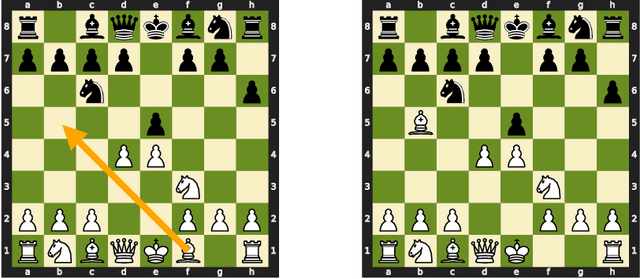


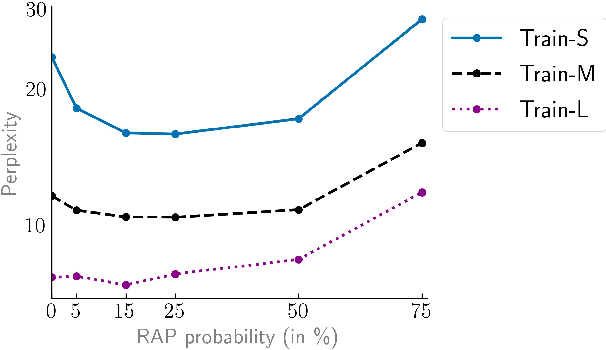
Transformer language models have made tremendous strides in natural language understanding tasks. However, the complexity of natural language makes it challenging to ascertain how accurately these models are tracking the world state underlying the text. Motivated by this issue, we consider the task of language modeling for the game of chess. Unlike natural language, chess notations describe a simple, constrained, and deterministic domain. Moreover, we observe that the appropriate choice of chess notation allows for directly probing the world state, without requiring any additional probing-related machinery. We find that: (a) With enough training data, transformer language models can learn to track pieces and predict legal moves with high accuracy when trained solely on move sequences. (b) For small training sets providing access to board state information during training can yield significant improvements. (c) The success of transformer language models is dependent on access to the entire game history i.e. "full attention". Approximating this full attention results in a significant performance drop. We propose this testbed as a benchmark for future work on the development and analysis of transformer language models.
Substructure Substitution: Structured Data Augmentation for NLP
Jan 02, 2021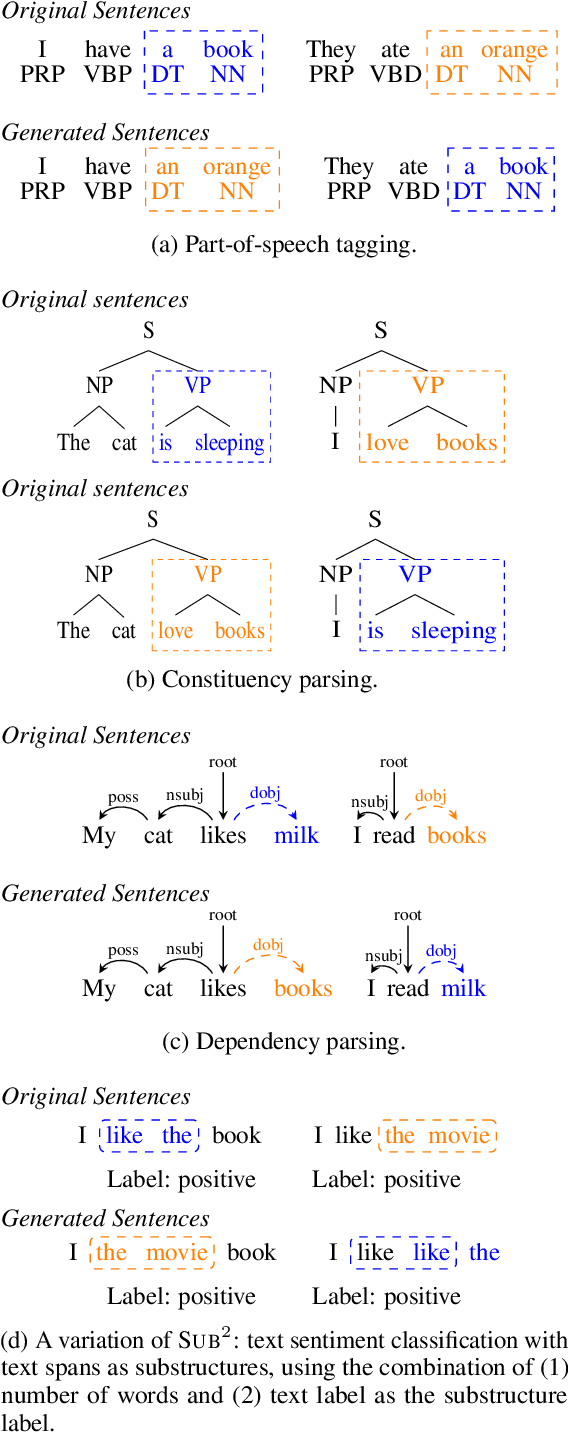
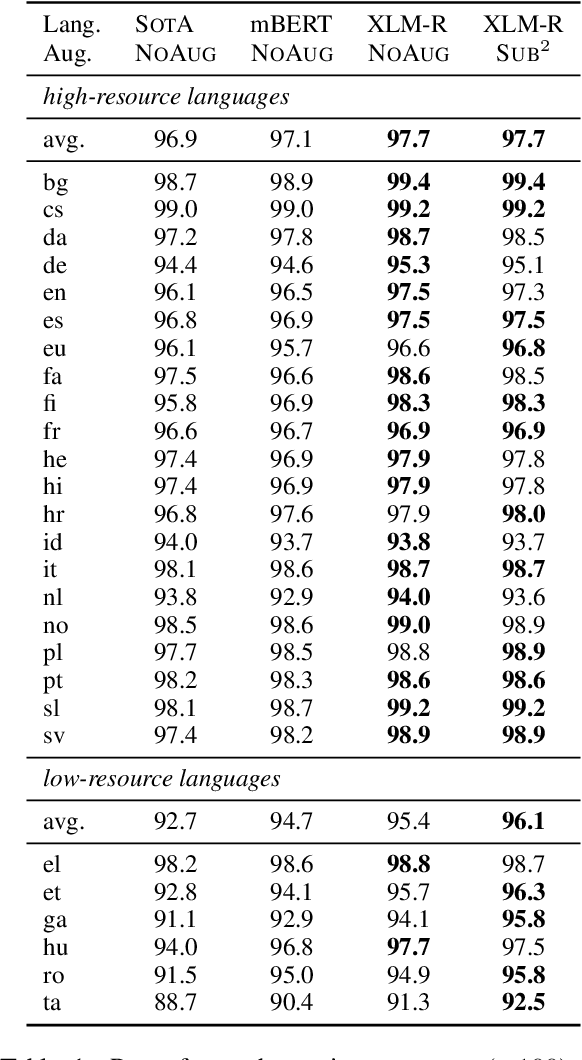
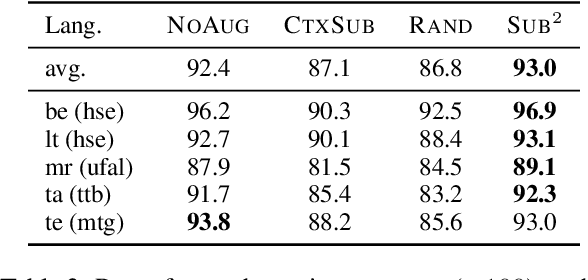
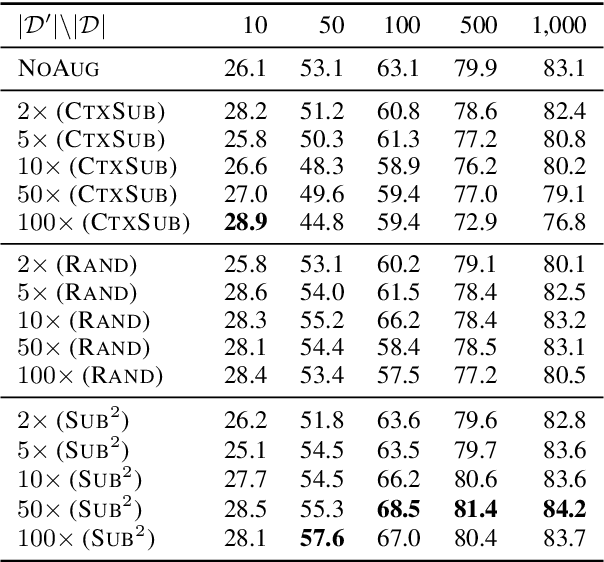
We study a family of data augmentation methods, substructure substitution (SUB2), for natural language processing (NLP) tasks. SUB2 generates new examples by substituting substructures (e.g., subtrees or subsequences) with ones with the same label, which can be applied to many structured NLP tasks such as part-of-speech tagging and parsing. For more general tasks (e.g., text classification) which do not have explicitly annotated substructures, we present variations of SUB2 based on constituency parse trees, introducing structure-aware data augmentation methods to general NLP tasks. For most cases, training with the augmented dataset by SUB2 achieves better performance than training with the original training set. Further experiments show that SUB2 has more consistent performance than other investigated augmentation methods, across different tasks and sizes of the seed dataset.
Generating Wikipedia Article Sections from Diverse Data Sources
Dec 29, 2020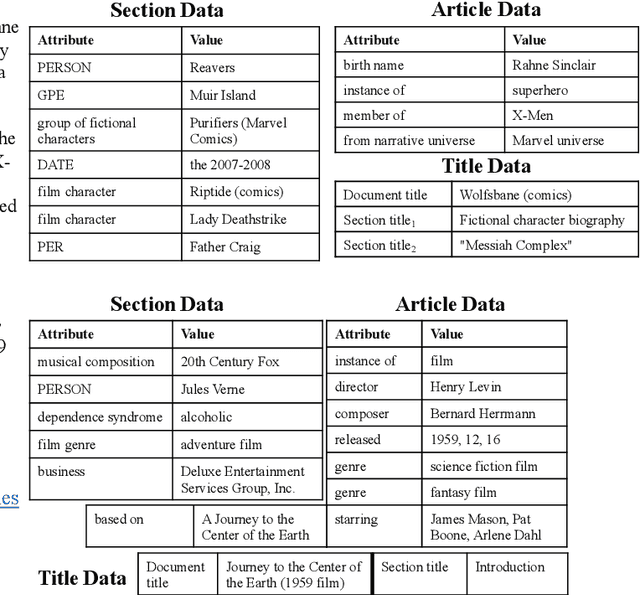
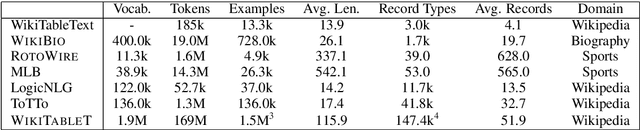

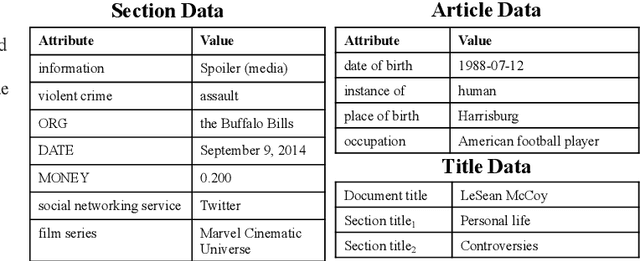
Datasets for data-to-text generation typically focus either on multi-domain, single-sentence generation or on single-domain, long-form generation. In this work, we create a large-scale dataset, WikiTableT, that pairs Wikipedia sections with their corresponding tabular data and various metadata. WikiTableT contains millions of instances, covering a broad range of topics, as well as a variety of flavors of generation tasks with different levels of flexibility. We benchmark several training and decoding strategies on WikiTableT. Our qualitative analysis shows that the best approaches can generate fluent and high quality texts but they sometimes struggle with coherence.
Unsupervised Label Refinement Improves Dataless Text Classification
Dec 08, 2020
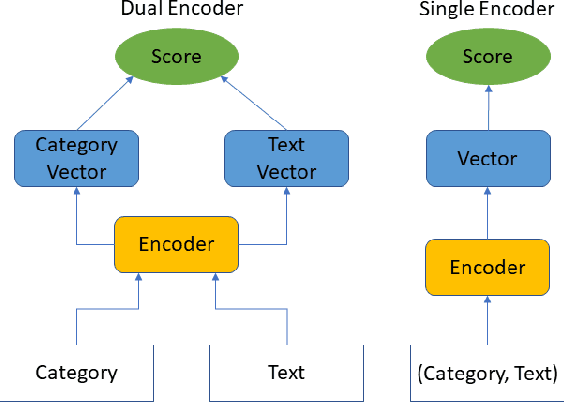
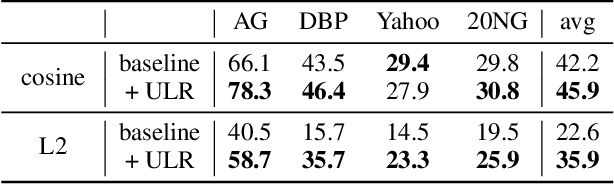
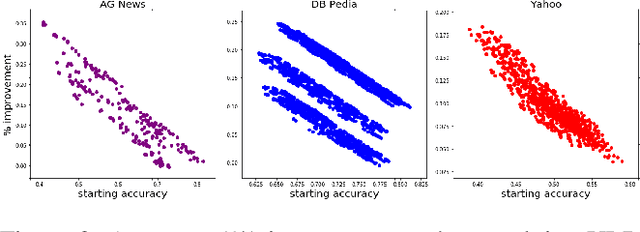
Dataless text classification is capable of classifying documents into previously unseen labels by assigning a score to any document paired with a label description. While promising, it crucially relies on accurate descriptions of the label set for each downstream task. This reliance causes dataless classifiers to be highly sensitive to the choice of label descriptions and hinders the broader application of dataless classification in practice. In this paper, we ask the following question: how can we improve dataless text classification using the inputs of the downstream task dataset? Our primary solution is a clustering based approach. Given a dataless classifier, our approach refines its set of predictions using k-means clustering. We demonstrate the broad applicability of our approach by improving the performance of two widely used classifier architectures, one that encodes text-category pairs with two independent encoders and one with a single joint encoder. Experiments show that our approach consistently improves dataless classification across different datasets and makes the classifier more robust to the choice of label descriptions.
Clustering Contextualized Representations of Text for Unsupervised Syntax Induction
Oct 24, 2020
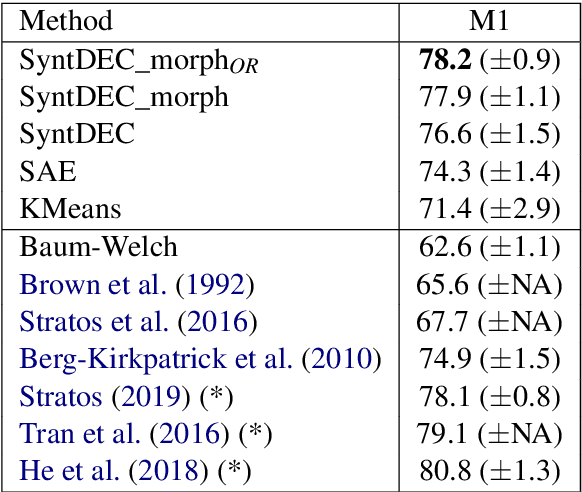
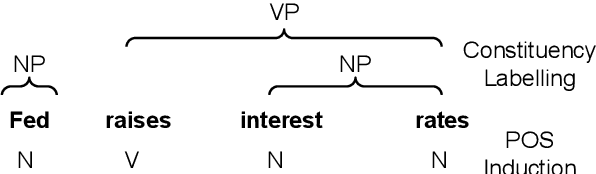
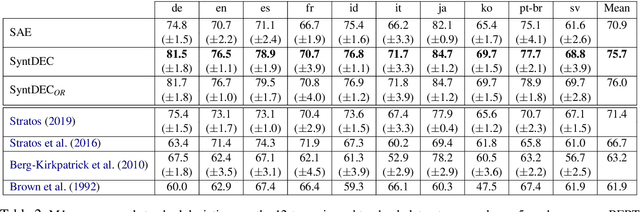
We explore clustering of contextualized text representations for two unsupervised syntax induction tasks: part of speech induction (POSI) and constituency labelling (CoLab). We propose a deep embedded clustering approach which jointly transforms these representations into a lower dimension cluster friendly space and clusters them. We further enhance these representations by augmenting them with task-specific representations. We also explore the effectiveness of multilingual representations for different tasks and languages. With this work, we establish the first strong baselines for unsupervised syntax induction using contextualized text representations. We report competitive performance on 45-tag POSI, state-of-the-art performance on 12-tag POSI across 10 languages, and competitive results on CoLab.
Controllable Paraphrasing and Translation with a Syntactic Exemplar
Oct 12, 2020
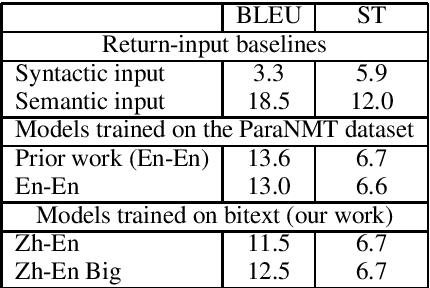

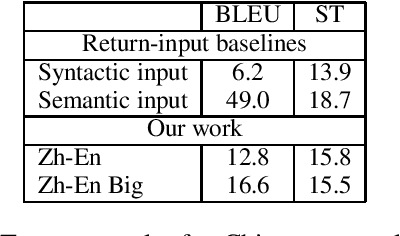
Most prior work on exemplar-based syntactically controlled paraphrase generation relies on automatically-constructed large-scale paraphrase datasets. We sidestep this prerequisite by adapting models from prior work to be able to learn solely from bilingual text (bitext). Despite only using bitext for training, and in near zero-shot conditions, our single proposed model can perform four tasks: controlled paraphrase generation in both languages and controlled machine translation in both language directions. To evaluate these tasks quantitatively, we create three novel evaluation datasets. Our experimental results show that our models achieve competitive results on controlled paraphrase generation and strong performance on controlled machine translation. Analysis shows that our models learn to disentangle semantics and syntax in their latent representations.
Discriminatively-Tuned Generative Classifiers for Robust Natural Language Inference
Oct 08, 2020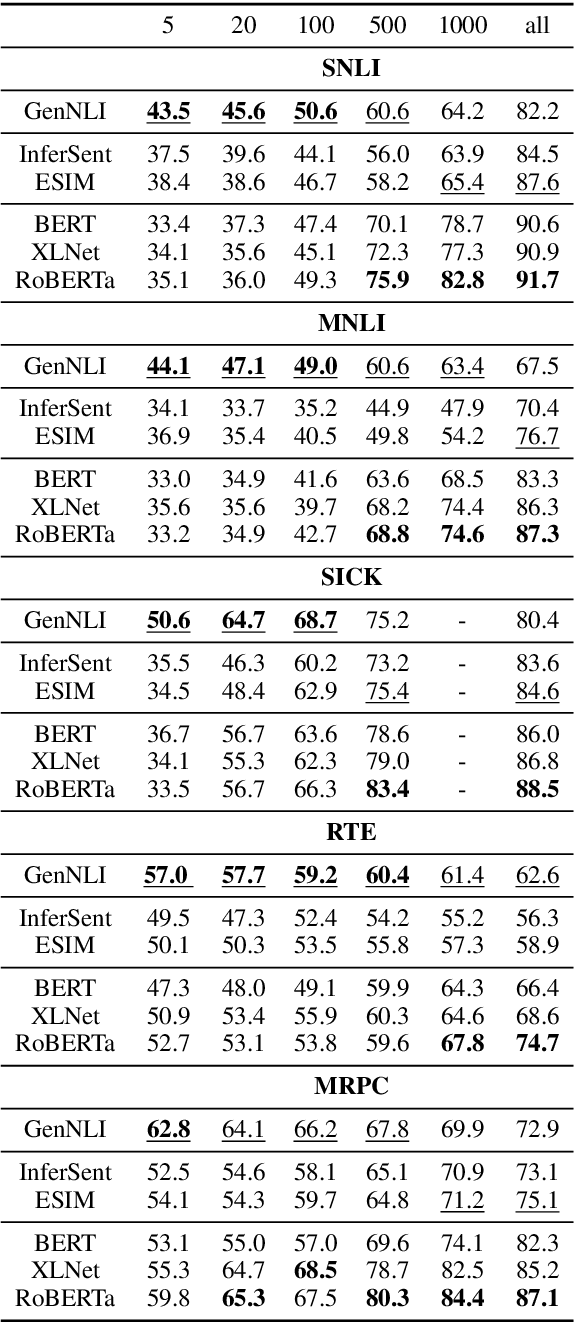
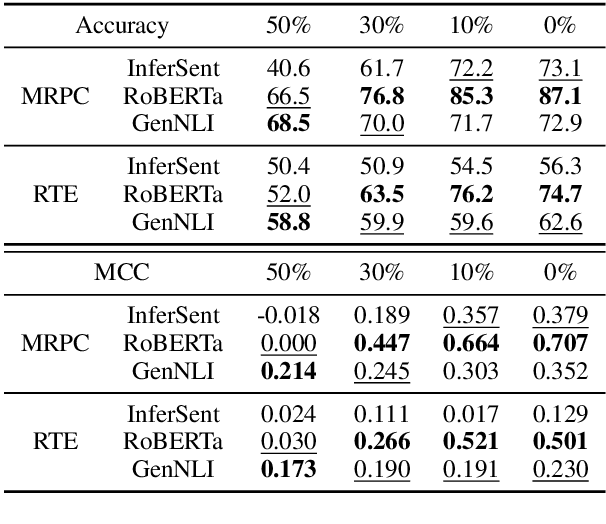
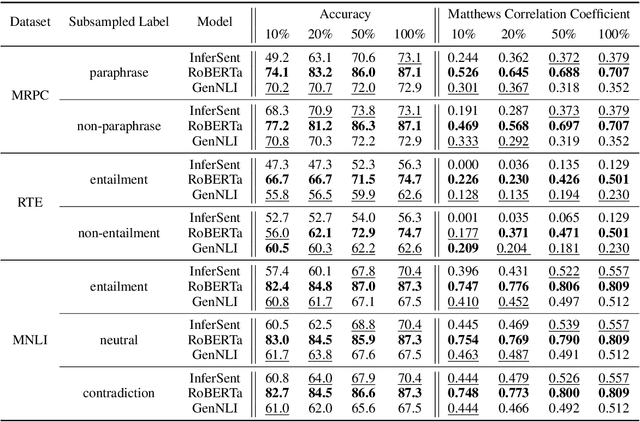

While discriminative neural network classifiers are generally preferred, recent work has shown advantages of generative classifiers in term of data efficiency and robustness. In this paper, we focus on natural language inference (NLI). We propose GenNLI, a generative classifier for NLI tasks, and empirically characterize its performance by comparing it to five baselines, including discriminative models and large-scale pretrained language representation models like BERT. We explore training objectives for discriminative fine-tuning of our generative classifiers, showing improvements over log loss fine-tuning from prior work . In particular, we find strong results with a simple unbounded modification to log loss, which we call the "infinilog loss". Our experiments show that GenNLI outperforms both discriminative and pretrained baselines across several challenging NLI experimental settings, including small training sets, imbalanced label distributions, and label noise.