 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAPE: Shifted Absolute Position Embedding for Transformers
Sep 13, 2021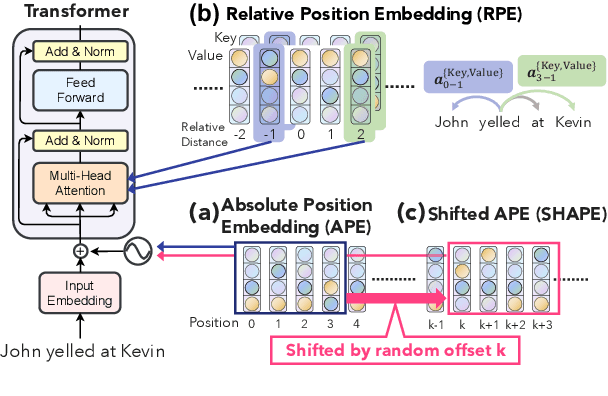
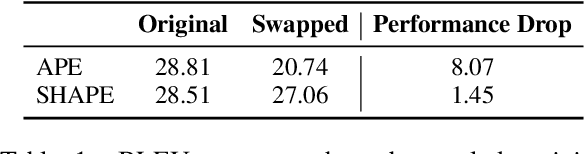
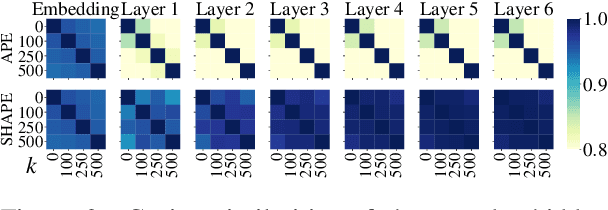
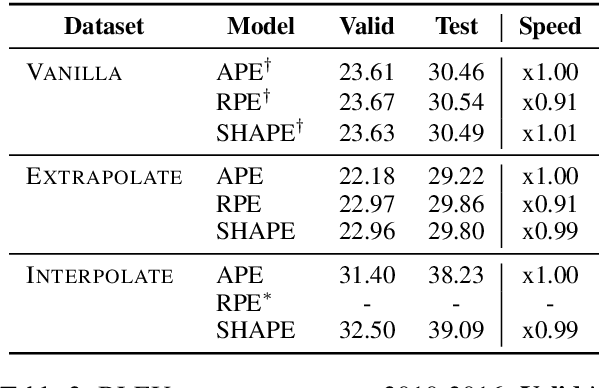
Position representation is crucial for building position-aware representations in Transformers. Existing position representations suffer from a lack of generalization to test data with unseen lengths or high computational cost. We investigate shifted absolute position embedding (SHAPE) to address both issues. The basic idea of SHAPE is to achieve shift invariance, which is a key property of recent successful position representations, by randomly shifting absolute positions during training. We demonstrate that SHAPE is empirically comparable to its counterpart while being simpler and faster.
Lower Perplexity is Not Always Human-Like
Jun 02, 2021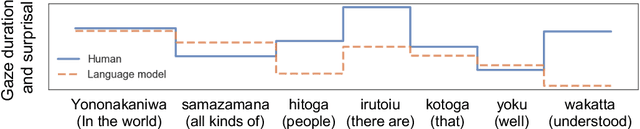

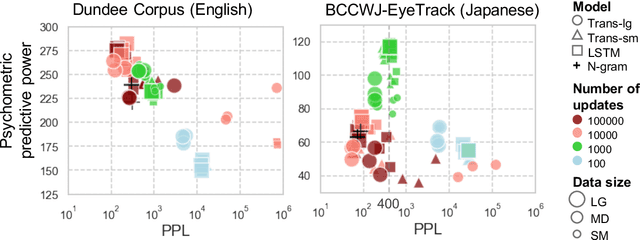
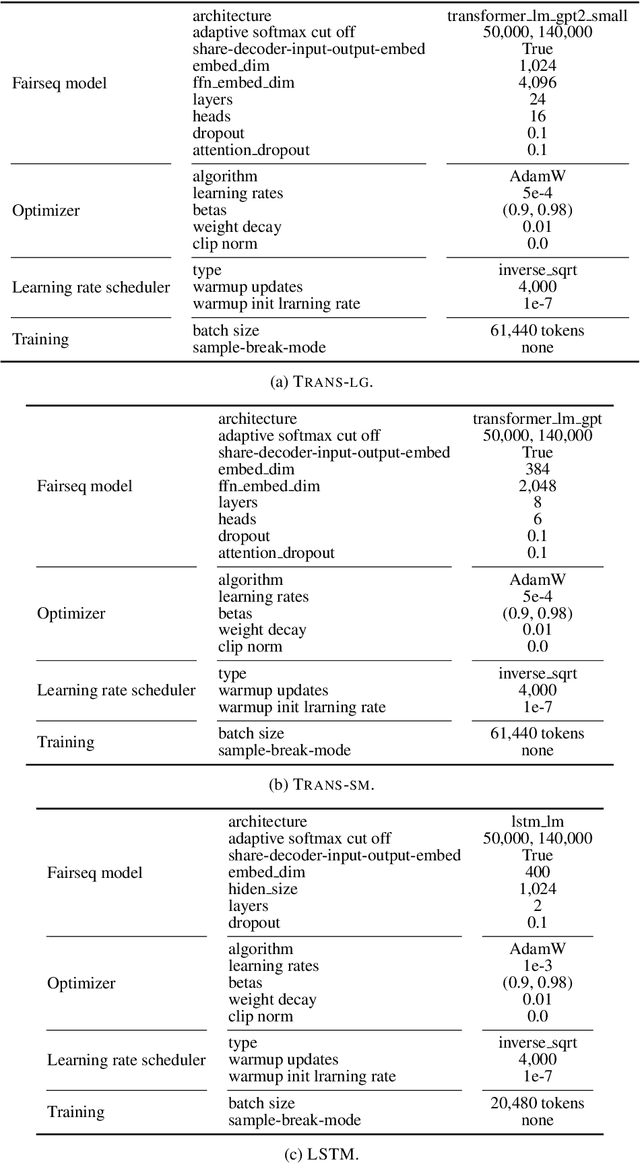
In computational psycholinguistics, various language models have been evaluated against human reading behavior (e.g., eye movement) to build human-like computational models. However, most previous efforts have focused almost exclusively on English, despite the recent trend towards linguistic universal within the general community. In order to fill the gap, this paper investigates whether the established results in computational psycholinguistics can be generalized across languages. Specifically, we re-examine an established generalization -- the lower perplexity a language model has, the more human-like the language model is -- in Japanese with typologically different structures from English. Our experiments demonstrate that this established generalization exhibits a surprising lack of universality; namely, lower perplexity is not always human-like. Moreover, this discrepancy between English and Japanese is further explored from the perspective of (non-)uniform information density. Overall, our results suggest that a cross-lingual evaluation will be necessary to construct human-like computational models.
SyGNS: A Systematic Generalization Testbed Based on Natural Language Semantics
Jun 02, 2021
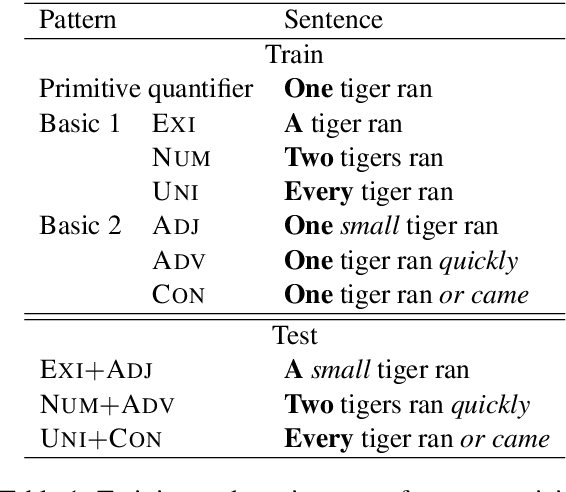
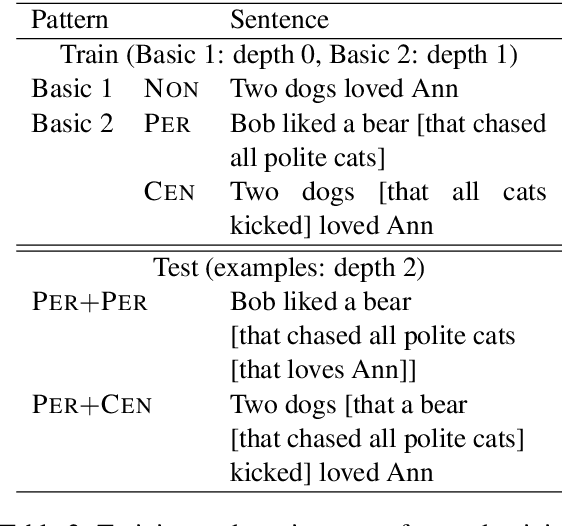
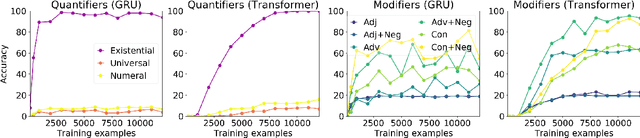
Recently, deep neural networks (DNNs) have achieved great success in semantically challenging NLP tasks, yet it remains unclear whether DNN models can capture compositional meanings, those aspects of meaning that have been long studied in formal semantics. To investigate this issue, we propose a Systematic Generalization testbed based on Natural language Semantics (SyGNS), whose challenge is to map natural language sentences to multiple forms of scoped meaning representations, designed to account for various semantic phenomena. Using SyGNS, we test whether neural networks can systematically parse sentences involving novel combinations of logical expressions such as quantifiers and negation. Experiments show that Transformer and GRU models can generalize to unseen combinations of quantifiers, negations, and modifiers that are similar to given training instances in form, but not to the others. We also find that the generalization performance to unseen combinations is better when the form of meaning representations is simpler. The data and code for SyGNS are publicly available at https://github.com/verypluming/SyGNS.
Learning to Learn to be Right for the Right Reasons
Apr 23, 2021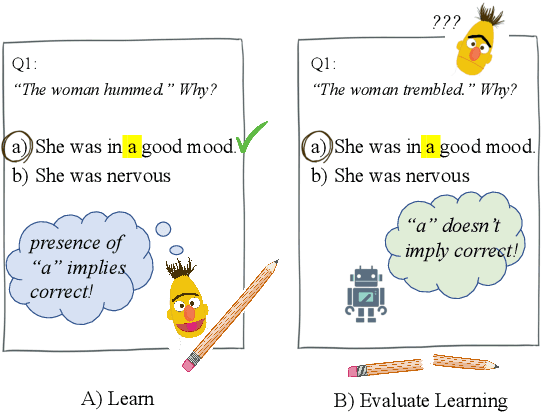
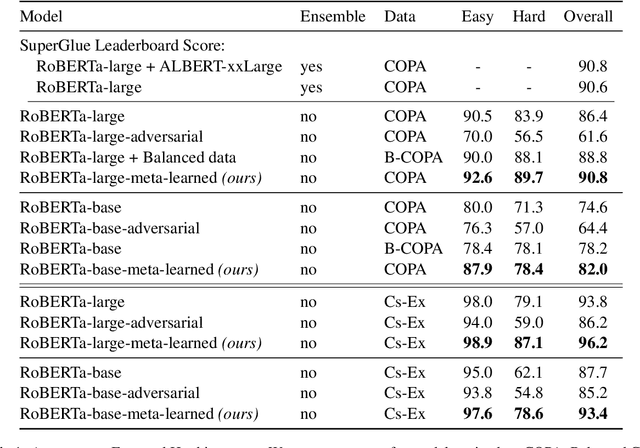
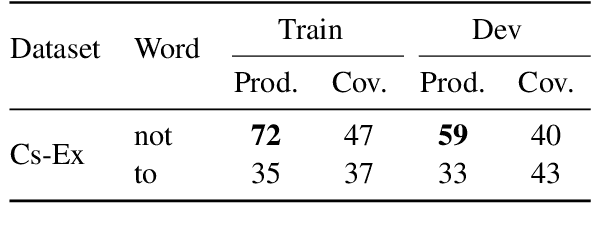
Improving model generalization on held-out data is one of the core objectives in commonsense reasoning. Recent work has shown that models trained on the dataset with superficial cues tend to perform well on the easy test set with superficial cues but perform poorly on the hard test set without superficial cues. Previous approaches have resorted to manual methods of encouraging models not to overfit to superficial cues. While some of the methods have improved performance on hard instances, they also lead to degraded performance on easy instances. Here, we propose to explicitly learn a model that does well on both the easy test set with superficial cues and hard test set without superficial cues. Using a meta-learning objective, we learn such a model that improves performance on both the easy test set and the hard test set. By evaluating our models on Choice of Plausible Alternatives (COPA) and Commonsense Explanation, we show that our proposed method leads to improved performance on both the easy test set and the hard test set upon which we observe up to 16.5 percentage points improvement over the baseline.
A Comparative Study on Collecting High-Quality Implicit Reasonings at a Large-scale
Apr 16, 2021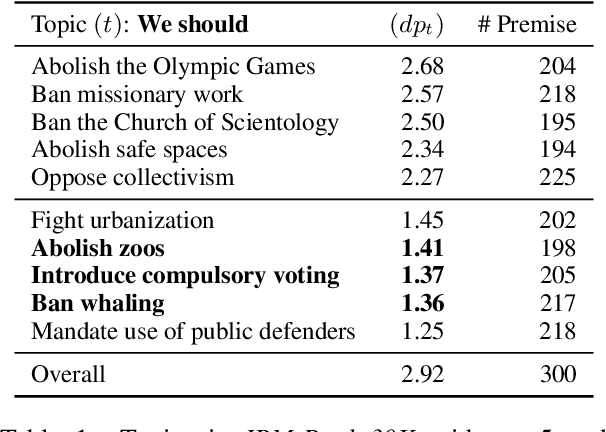

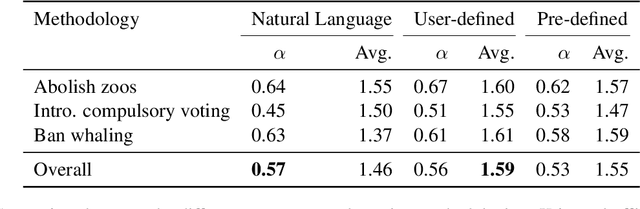

Explicating implicit reasoning (i.e. warrants) in arguments is a long-standing challenge for natural language understanding systems. While recent approaches have focused on explicating warrants via crowdsourcing or expert annotations, the quality of warrants has been questionable due to the extreme complexity and subjectivity of the task. In this paper, we tackle the complex task of warrant explication and devise various methodologies for collecting warrants. We conduct an extensive study with trained experts to evaluate the resulting warrants of each methodology and find that our methodologies allow for high-quality warrants to be collected. We construct a preliminary dataset of 6,000 warrants annotated over 600 arguments for 3 debatable topics. To facilitate research in related downstream tasks, we release our guidelines and preliminary dataset.
Pseudo Zero Pronoun Resolution Improves Zero Anaphora Resolution
Apr 15, 2021
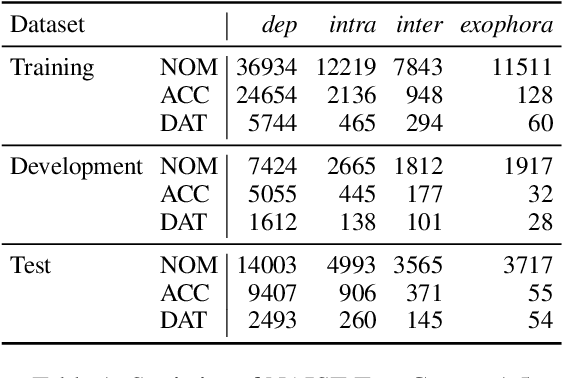

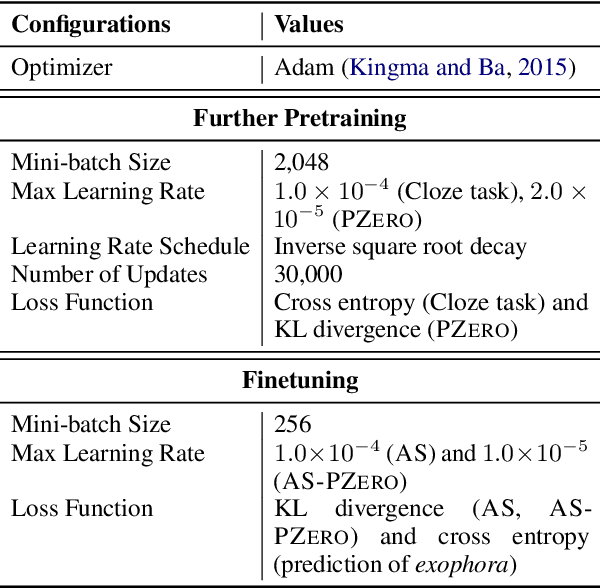
The use of pretrained masked language models (MLMs) has drastically improved the performance of zero anaphora resolution (ZAR). We further expand this approach with a novel pretraining task and finetuning method for Japanese ZAR. Our pretraining task aims to acquire anaphoric relational knowledge necessary for ZAR from a large-scale raw corpus. The ZAR model is finetuned in the same manner as pretraining. Our experiments show that combining the proposed methods surpasses previous state-of-the-art performance with large margins, providing insight on the remaining challenges.
Two Training Strategies for Improving Relation Extraction over Universal Graph
Feb 12, 2021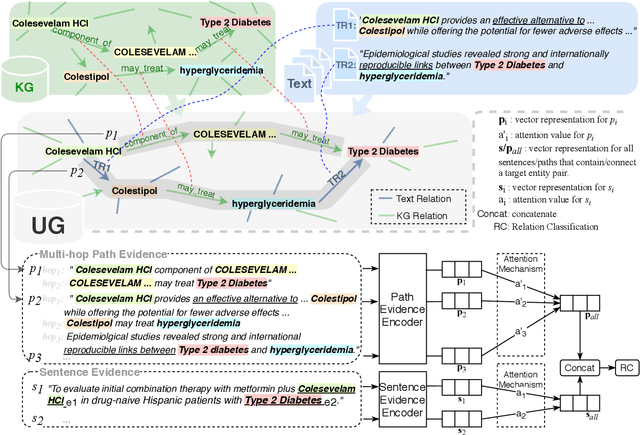

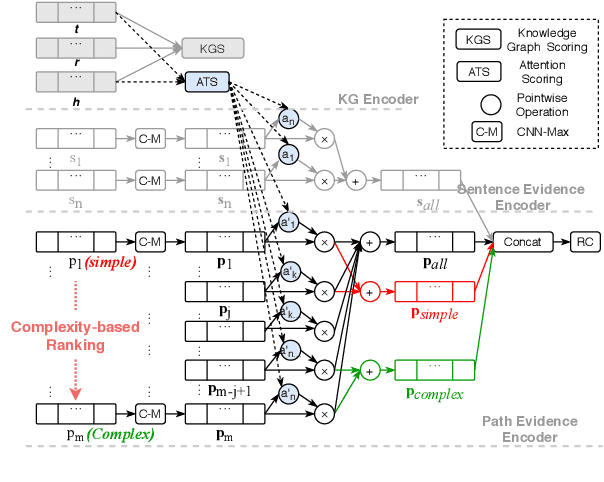

This paper explores how the Distantly Supervised Relation Extraction (DS-RE) can benefit from the use of a Universal Graph (UG), the combination of a Knowledge Graph (KG) and a large-scale text collection. A straightforward extension of a current state-of-the-art neural model for DS-RE with a UG may lead to degradation in performance. We first report that this degradation is associated with the difficulty in learning a UG and then propose two training strategies: (1) Path Type Adaptive Pretraining, which sequentially trains the model with different types of UG paths so as to prevent the reliance on a single type of UG path; and (2) Complexity Ranking Guided Attention mechanism, which restricts the attention span according to the complexity of a UG path so as to force the model to extract features not only from simple UG paths but also from complex ones. Experimental results on both biomedical and NYT10 datasets prove the robustness of our methods and achieve a new state-of-the-art result on the NYT10 dataset. The code and datasets used in this paper are available at https://github.com/baodaiqin/UGDSRE.
Exploring Transitivity in Neural NLI Models through Veridicality
Jan 26, 2021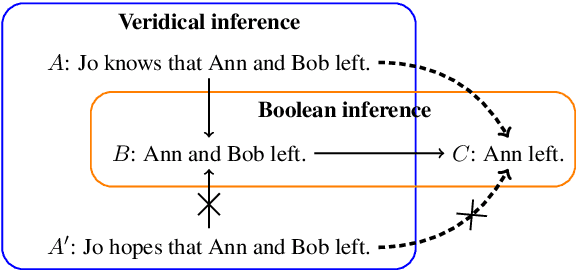


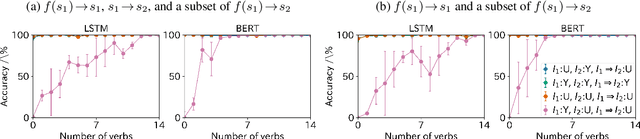
Despite the recent success of deep neural networks in natural language processing, the extent to which they can demonstrate human-like generalization capacities for natural language understanding remains unclear. We explore this issue in the domain of natural language inference (NLI), focusing on the transitivity of inference relations, a fundamental property for systematically drawing inferences. A model capturing transitivity can compose basic inference patterns and draw new inferences. We introduce an analysis method using synthetic and naturalistic NLI datasets involving clause-embedding verbs to evaluate whether models can perform transitivity inferences composed of veridical inferences and arbitrary inference types. We find that current NLI models do not perform consistently well on transitivity inference tasks, suggesting that they lack the generalization capacity for drawing composite inferences from provided training examples. The data and code for our analysis are publicly available at https://github.com/verypluming/transitivity.
Efficient Estimation of Influence of a Training Instance
Dec 08, 2020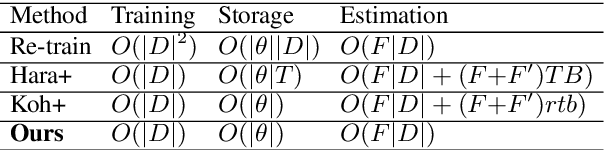
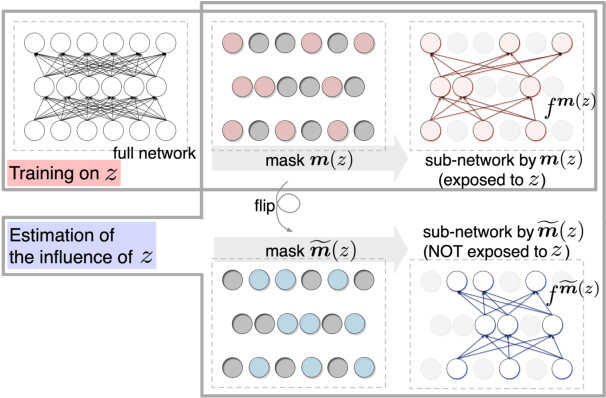
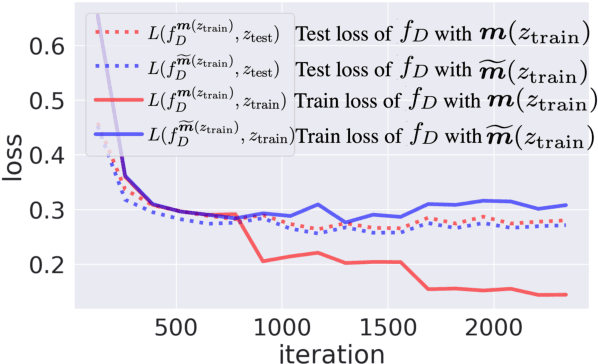

Understanding the influence of a training instance on a neural network model leads to improving interpretability. However, it is difficult and inefficient to evaluate the influence, which shows how a model's prediction would be changed if a training instance were not used. In this paper, we propose an efficient method for estimating the influence. Our method is inspired by dropout, which zero-masks a sub-network and prevents the sub-network from learning each training instance. By switching between dropout masks, we can use sub-networks that learned or did not learn each training instance and estimate its influence. Through experiments with BERT and VGGNet on classification datasets, we demonstrate that the proposed method can capture training influences, enhance the interpretability of error predictions, and cleanse the training dataset for improving generalization.
An Empirical Study of Contextual Data Augmentation for Japanese Zero Anaphora Resolution
Nov 04, 2020



One critical issue of zero anaphora resolution (ZAR) is the scarcity of labeled data. This study explores how effectively this problem can be alleviated by data augmentation. We adopt a state-of-the-art data augmentation method, called the contextual data augmentation (CDA), that generates labeled training instances using a pretrained language model. The CDA has been reported to work well for several other natural language processing tasks, including text classification and machine translation. This study addresses two underexplored issues on CDA, that is, how to reduce the computational cost of data augmentation and how to ensure the quality of the generated data. We also propose two methods to adapt CDA to ZAR: [MASK]-based augmentation and linguistically-controlled masking. Consequently, the experimental results on Japanese ZAR show that our methods contribute to both the accuracy gain and the computation cost reduction. Our closer analysis reveals that the proposed method can improve the quality of the augmented training data when compared to the conventional CDA.