 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Investigation of Neural Symbolic Reasoning Strategies
Feb 16, 2023Neural reasoning accuracy improves when generating intermediate reasoning steps. However, the source of this improvement is yet unclear. Here, we investigate and factorize the benefit of generating intermediate steps for symbolic reasoning. Specifically, we decompose the reasoning strategy w.r.t. step granularity and chaining strategy. With a purely symbolic numerical reasoning dataset (e.g., A=1, B=3, C=A+3, C?), we found that the choice of reasoning strategies significantly affects the performance, with the gap becoming even larger as the extrapolation length becomes longer. Surprisingly, we also found that certain configurations lead to nearly perfect performance, even in the case of length extrapolation. Our results indicate the importance of further exploring effective strategies for neural reasoning models.
Do Deep Neural Networks Capture Compositionality in Arithmetic Reasoning?
Feb 15, 2023Compositionality is a pivotal property of symbolic reasoning. However, how well recent neural models capture compositionality remains underexplored in the symbolic reasoning tasks. This study empirically addresses this question by systematically examining recently published pre-trained seq2seq models with a carefully controlled dataset of multi-hop arithmetic symbolic reasoning. We introduce a skill tree on compositionality in arithmetic symbolic reasoning that defines the hierarchical levels of complexity along with three compositionality dimensions: systematicity, productivity, and substitutivity. Our experiments revealed that among the three types of composition, the models struggled most with systematicity, performing poorly even with relatively simple compositions. That difficulty was not resolved even after training the models with intermediate reasoning steps.
Feed-Forward Blocks Control Contextualization in Masked Language Models
Feb 01, 2023



Understanding the inner workings of neural network models is a crucial step for rationalizing their output and refining their architecture. Transformer-based models are the core of recent natural language processing and have been analyzed typically with attention patterns as their epoch-making feature is contextualizing surrounding input words via attention mechanisms. In this study, we analyze their inner contextualization by considering all the components, including the feed-forward block (i.e., a feed-forward layer and its surrounding residual and normalization layers) as well as the attention. Our experiments with masked language models show that each of the previously overlooked components did modify the degree of the contextualization in case of processing special word-word pairs (e.g., consisting of named entities). Furthermore, we find that some components cancel each other's effects. Our results could update the typical view about each component's roles (e.g., attention performs contextualization, and the other components serve different roles) in the Transformer layer.
Tracing and Manipulating Intermediate Values in Neural Math Problem Solvers
Jan 17, 2023How language models process complex input that requires multiple steps of inference is not well understood. Previous research has shown that information about intermediate values of these inputs can be extracted from the activations of the models, but it is unclear where that information is encoded and whether that information is indeed used during inference. We introduce a method for analyzing how a Transformer model processes these inputs by focusing on simple arithmetic problems and their intermediate values. To trace where information about intermediate values is encoded, we measure the correlation between intermediate values and the activations of the model using principal component analysis (PCA). Then, we perform a causal intervention by manipulating model weights. This intervention shows that the weights identified via tracing are not merely correlated with intermediate values, but causally related to model predictions. Our findings show that the model has a locality to certain intermediate values, and this is useful for enhancing the interpretability of the models.
Cross-stitching Text and Knowledge Graph Encoders for Distantly Supervised Relation Extraction
Nov 02, 2022



Bi-encoder architectures for distantly-supervised relation extraction are designed to make use of the complementary information found in text and knowledge graphs (KG). However, current architectures suffer from two drawbacks. They either do not allow any sharing between the text encoder and the KG encoder at all, or, in case of models with KG-to-text attention, only share information in one direction. Here, we introduce cross-stitch bi-encoders, which allow full interaction between the text encoder and the KG encoder via a cross-stitch mechanism. The cross-stitch mechanism allows sharing and updating representations between the two encoders at any layer, with the amount of sharing being dynamically controlled via cross-attention-based gates. Experimental results on two relation extraction benchmarks from two different domains show that enabling full interaction between the two encoders yields strong improvements.
Target-Guided Open-Domain Conversation Planning
Sep 20, 2022
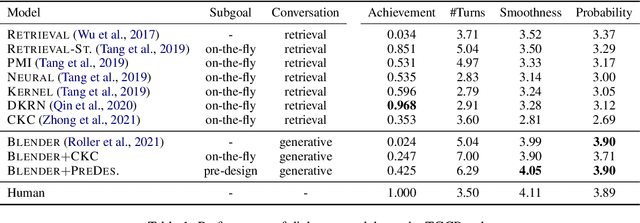


Prior studies addressing target-oriented conversational tasks lack a crucial notion that has been intensively studied in the context of goal-oriented artificial intelligence agents, namely, planning. In this study, we propose the task of Target-Guided Open-Domain Conversation Planning (TGCP) task to evaluate whether neural conversational agents have goal-oriented conversation planning abilities. Using the TGCP task, we investigate the conversation planning abilities of existing retrieval models and recent strong generative models. The experimental results reveal the challenges facing current technology.
N-best Response-based Analysis of Contradiction-awareness in Neural Response Generation Models
Aug 04, 2022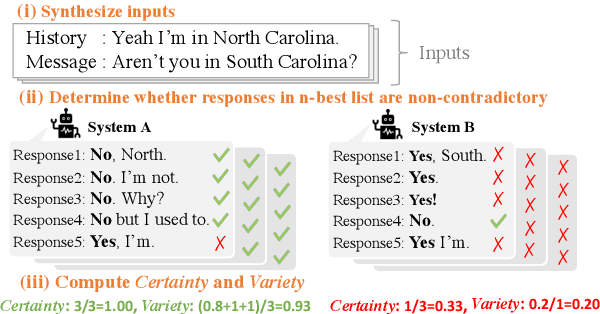

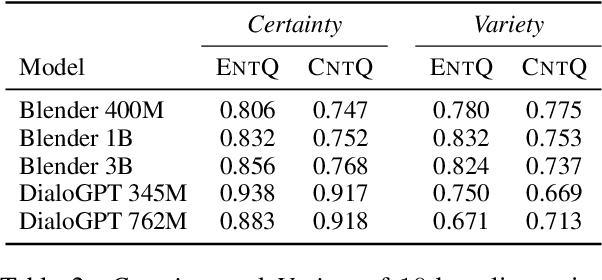
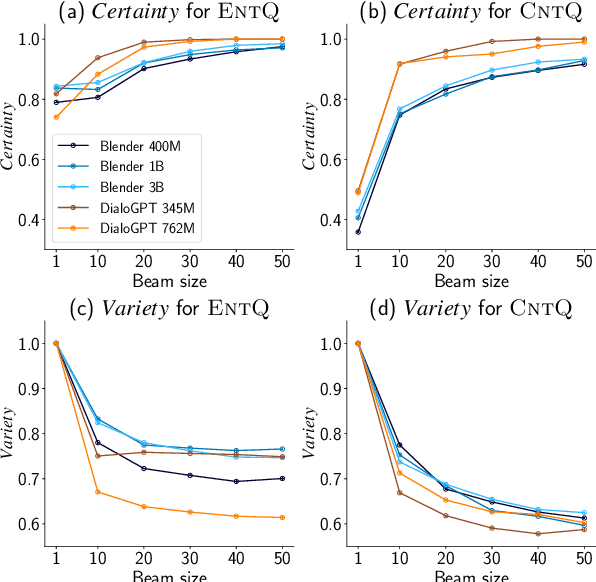
Avoiding the generation of responses that contradict the preceding context is a significant challenge in dialogue response generation. One feasible method is post-processing, such as filtering out contradicting responses from a resulting n-best response list. In this scenario, the quality of the n-best list considerably affects the occurrence of contradictions because the final response is chosen from this n-best list. This study quantitatively analyzes the contextual contradiction-awareness of neural response generation models using the consistency of the n-best lists. Particularly, we used polar questions as stimulus inputs for concise and quantitative analyses. Our tests illustrate the contradiction-awareness of recent neural response generation models and methodologies, followed by a discussion of their properties and limitations.
RealTime QA: What's the Answer Right Now?
Jul 27, 2022
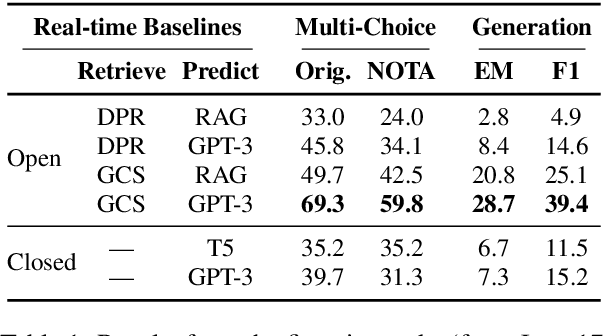
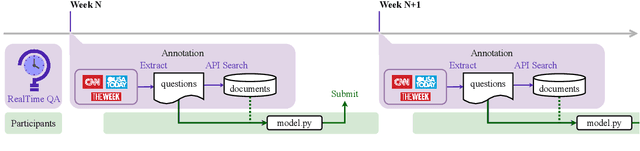
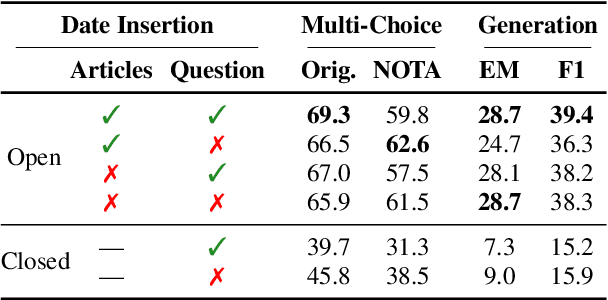
We introduce RealTime QA, a dynamic question answering (QA) platform that announces questions and evaluates systems on a regular basis (weekly in this version). RealTime QA inquires about the current world, and QA systems need to answer questions about novel events or information. It therefore challenges static, conventional assumptions in open domain QA datasets and pursues, instantaneous applications. We build strong baseline models upon large pretrained language models, including GPT-3 and T5. Our benchmark is an ongoing effort, and this preliminary report presents real-time evaluation results over the past month. Our experimental results show that GPT-3 can often properly update its generation results, based on newly-retrieved documents, highlighting the importance of up-to-date information retrieval. Nonetheless, we find that GPT-3 tends to return outdated answers when retrieved documents do not provide sufficient information to find an answer. This suggests an important avenue for future research: can an open domain QA system identify such unanswerable cases and communicate with the user or even the retrieval module to modify the retrieval results? We hope that RealTime QA will spur progress in instantaneous applications of question answering and beyond.
Balancing Cost and Quality: An Exploration of Human-in-the-loop Frameworks for Automated Short Answer Scoring
Jun 16, 2022

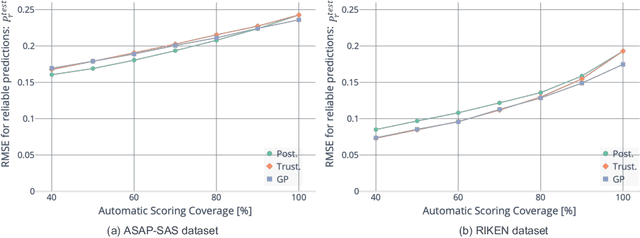
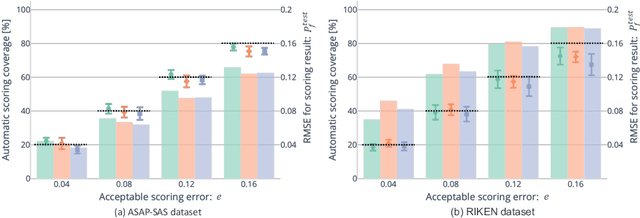
Short answer scoring (SAS) is the task of grading short text written by a learner. In recent years, deep-learning-based approaches have substantially improved the performance of SAS models, but how to guarantee high-quality predictions still remains a critical issue when applying such models to the education field. Towards guaranteeing high-quality predictions, we present the first study of exploring the use of human-in-the-loop framework for minimizing the grading cost while guaranteeing the grading quality by allowing a SAS model to share the grading task with a human grader. Specifically, by introducing a confidence estimation method for indicating the reliability of the model predictions, one can guarantee the scoring quality by utilizing only predictions with high reliability for the scoring results and casting predictions with low reliability to human graders. In our experiments, we investigate the feasibility of the proposed framework using multiple confidence estimation methods and multiple SAS datasets. We find that our human-in-the-loop framework allows automatic scoring models and human graders to achieve the target scoring quality.
Diverse Lottery Tickets Boost Ensemble from a Single Pretrained Model
May 24, 2022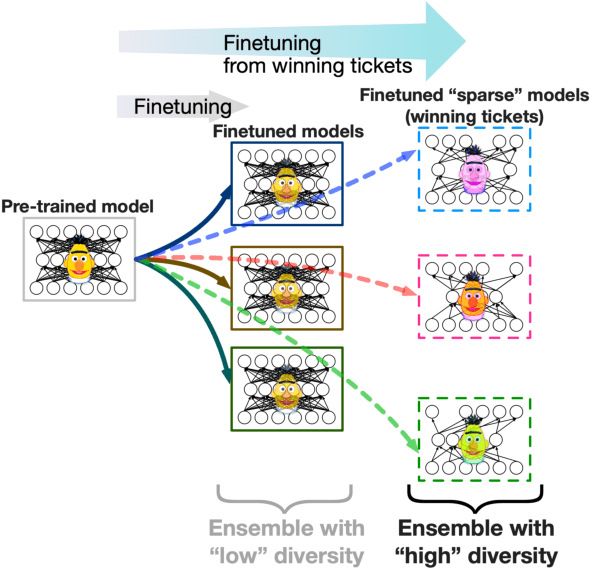
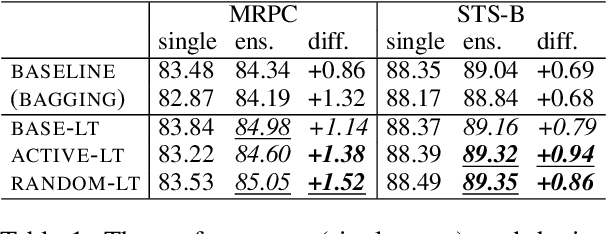
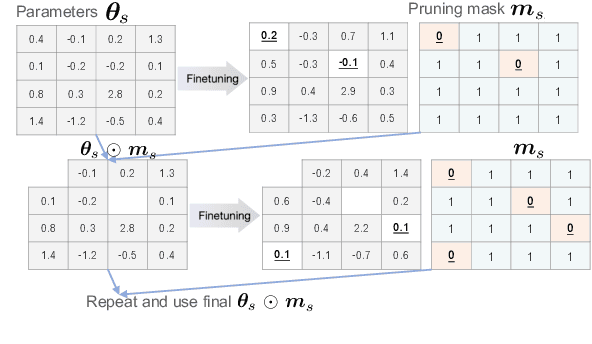
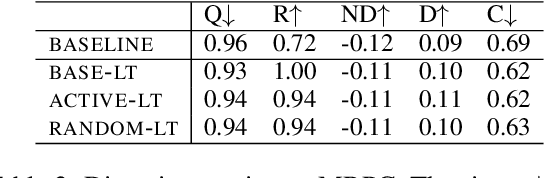
Ensembling is a popular method used to improve performance as a last resort. However, ensembling multiple models finetuned from a single pretrained model has been not very effective; this could be due to the lack of diversity among ensemble members. This paper proposes Multi-Ticket Ensemble, which finetunes different subnetworks of a single pretrained model and ensembles them. We empirically demonstrated that winning-ticket subnetworks produced more diverse predictions than dense networks, and their ensemble outperformed the standard ensemble on some tasks.