 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021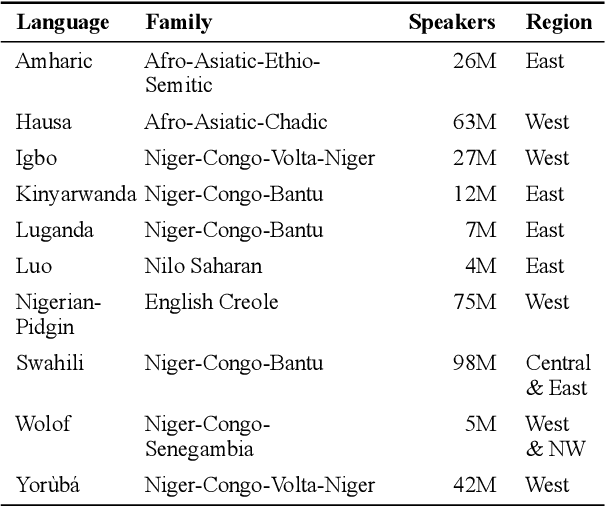

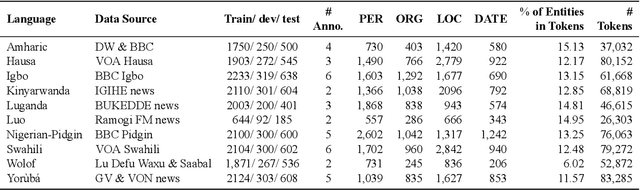
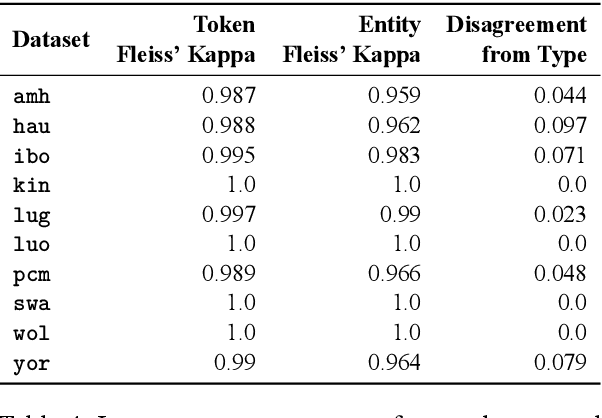
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Counterfactual Detection meets Transfer Learning
May 27, 2020



We can consider Counterfactuals as belonging in the domain of Discourse structure and semantics, A core area in Natural Language Understanding and in this paper, we introduce an approach to resolving counterfactual detection as well as the indexing of the antecedents and consequents of Counterfactual statements. While Transfer learning is already being applied to several NLP tasks, It has the characteristics to excel in a novel number of tasks. We show that detecting Counterfactuals is a straightforward Binary Classification Task that can be implemented with minimal adaptation on already existing model Architectures, thanks to a well annotated training data set,and we introduce a new end to end pipeline to process antecedents and consequents as an entity recognition task, thus adapting them into Token Classification.