 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Disentanglement by Pairwise Similarities
Jun 03, 2019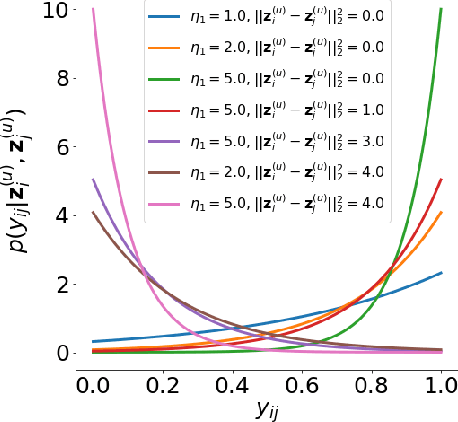
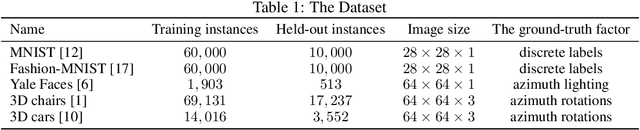
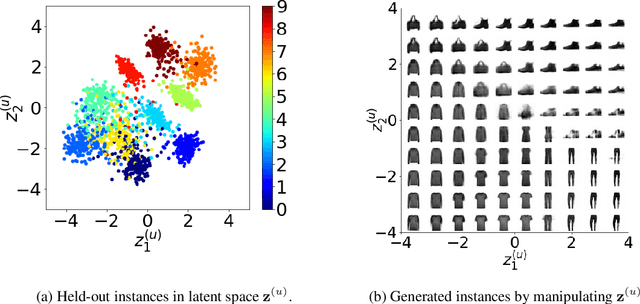
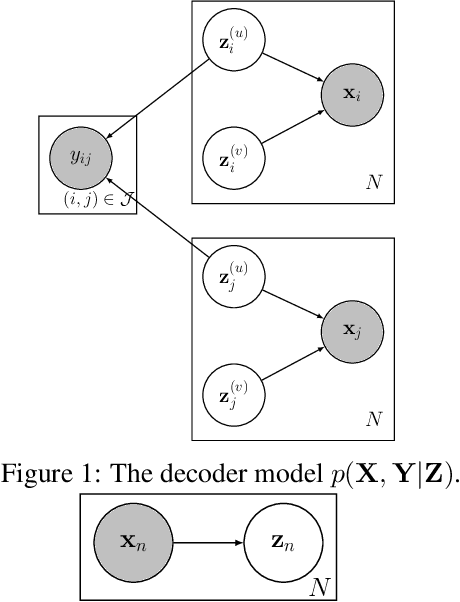
Recently, researches related to unsupervised disentanglement learning with deep generative models have gained substantial popularity. However, without introducing supervision, there is no guarantee that the factors of interest can be successfully recovered. In this paper, we propose a setting where the user introduces weak supervision by providing similarities between instances based on a factor to be disentangled. The similarity is provided as either a discrete (yes/no) or real-valued label describing whether a pair of instances are similar or not. We propose a new method for weakly supervised disentanglement of latent variables within the framework of Variational Autoencoder. Experimental results demonstrate that utilizing weak supervision improves the performance of the disentanglement method substantially.
Generative-Discriminative Complementary Learning
Apr 16, 2019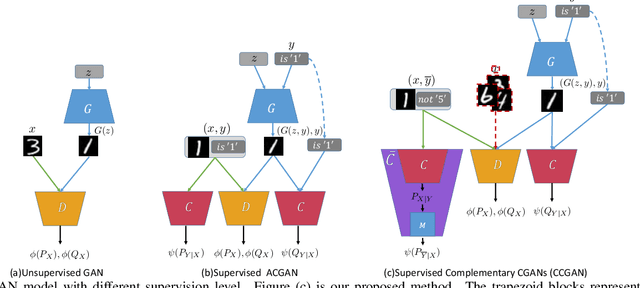
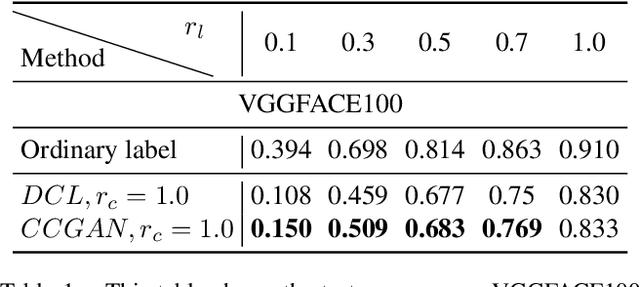
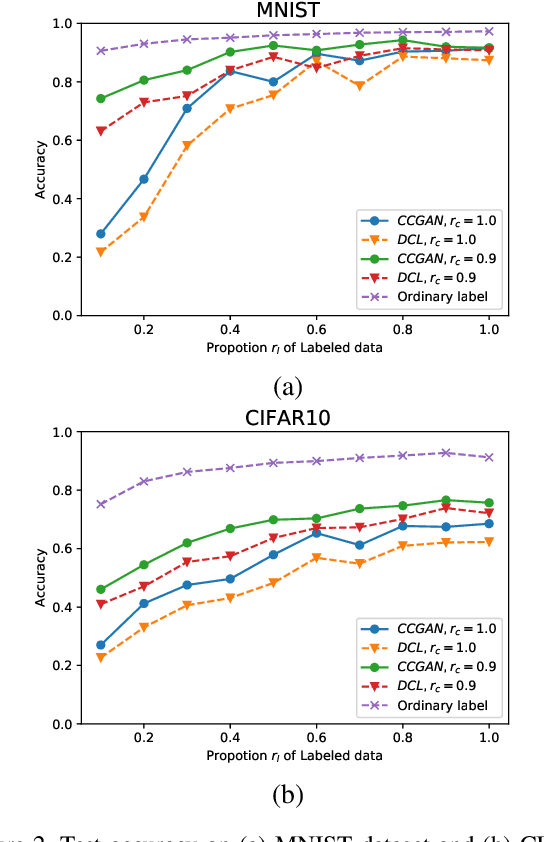

Majority of state-of-the-art deep learning methods for vision applications are discriminative approaches, which model the conditional distribution. The success of such approaches heavily depends on high-quality labeled instances, which are not easy to obtain, especially as the number of candidate classes increases. In this paper, we study the complementary learning problem. Unlike ordinary labels, complementary labels are easy to obtain because an annotator only needs to provide a yes/no answer to a randomly chosen candidate class for each instance. We propose a generative-discriminative complementary learning method that estimates the ordinary labels by modeling both the conditional (discriminative) and instance (generative) distributions. Our method, we call Complementary Conditional GAN (CCGAN), improves the accuracy of predicting ordinary labels and is able to generate high quality instances in spite of weak supervision. In addition to the extensive empirical studies, we also theoretically show that our model can retrieve the true conditional distribution from the complementarily-labeled data.
Robust Angular Local Descriptor Learning
Jan 26, 2019
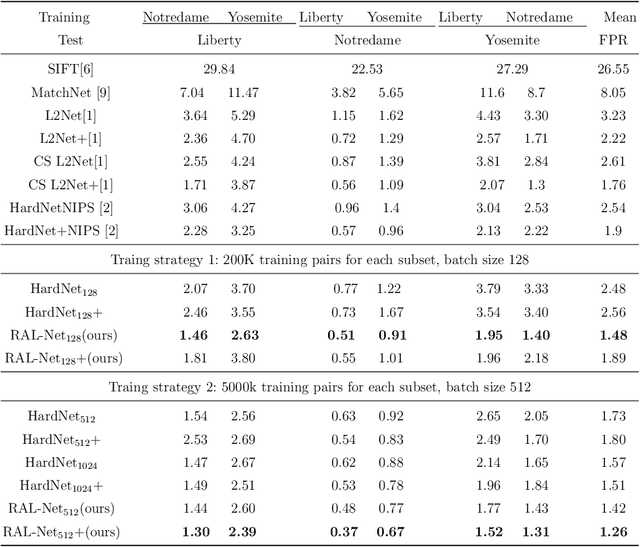
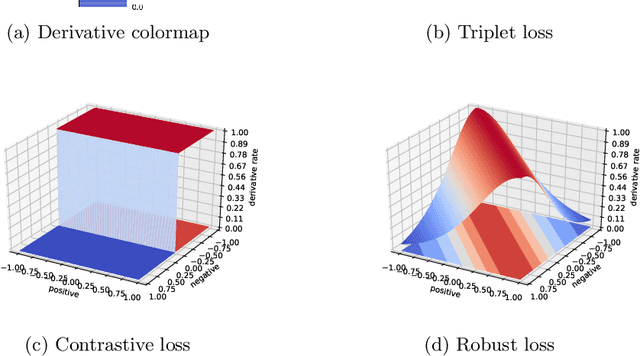
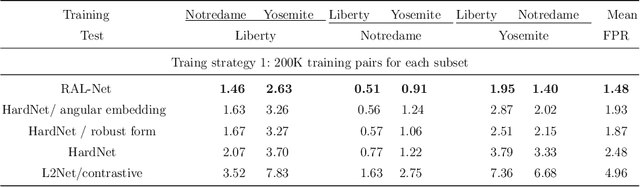
In recent years, the learned local descriptors have outperformed handcrafted ones by a large margin, due to the powerful deep convolutional neural network architectures such as L2-Net [1] and triplet based metric learning [2]. However, there are two problems in the current methods, which hinders the overall performance. Firstly, the widely-used margin loss is sensitive to incorrect correspondences, which are prevalent in the existing local descriptor learning datasets. Second, the L2 distance ignores the fact that the feature vectors have been normalized to unit norm. To tackle these two problems and further boost the performance, we propose a robust angular loss which 1) uses cosine similarity instead of L2 distance to compare descriptors and 2) relies on a robust loss function that gives smaller penalty to triplets with negative relative similarity. The resulting descriptor shows robustness on different datasets, reaching the state-of-the-art result on Brown dataset , as well as demonstrating excellent generalization ability on the Hpatches dataset and a Wide Baseline Stereo dataset.
Deep Diffeomorphic Normalizing Flows
Oct 08, 2018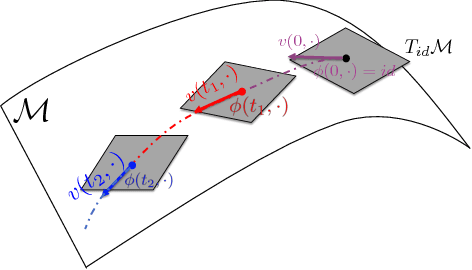
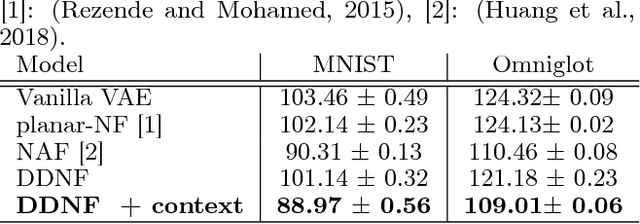
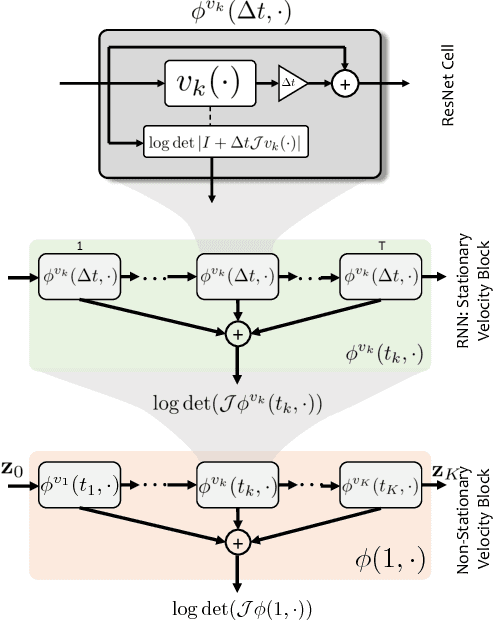
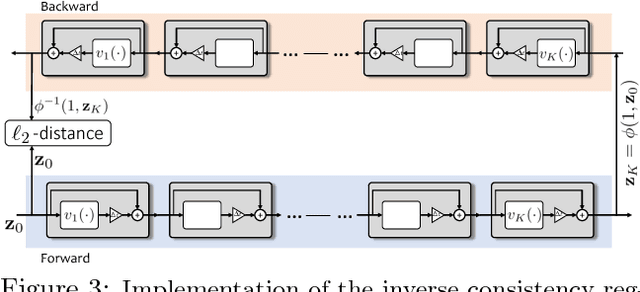
The Normalizing Flow (NF) models a general probability density by estimating an invertible transformation applied on samples drawn from a known distribution. We introduce a new type of NF, called Deep Diffeomorphic Normalizing Flow (DDNF). A diffeomorphic flow is an invertible function where both the function and its inverse are smooth. We construct the flow using an ordinary differential equation (ODE) governed by a time-varying smooth vector field. We use a neural network to parametrize the smooth vector field and a recursive neural network (RNN) for approximating the solution of the ODE. Each cell in the RNN is a residual network implementing one Euler integration step. The architecture of our flow enables efficient likelihood evaluation, straightforward flow inversion, and results in highly flexible density estimation. An end-to-end trained DDNF achieves competitive results with state-of-the-art methods on a suite of density estimation and variational inference tasks. Finally, our method brings concepts from Riemannian geometry that, we believe, can open a new research direction for neural density estimation.
Geometry-Consistent Adversarial Networks for One-Sided Unsupervised Domain Mapping
Sep 16, 2018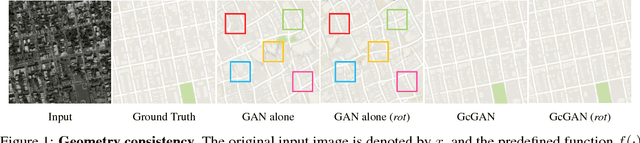
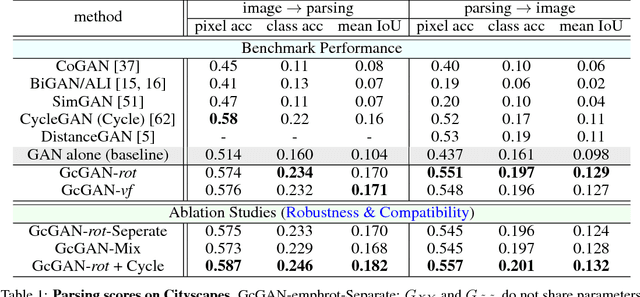
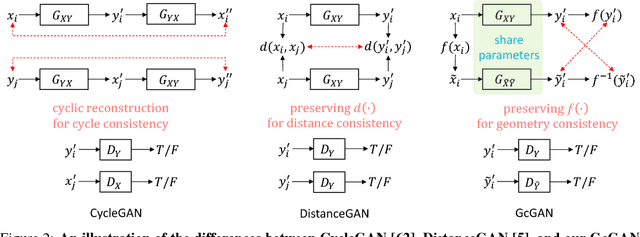
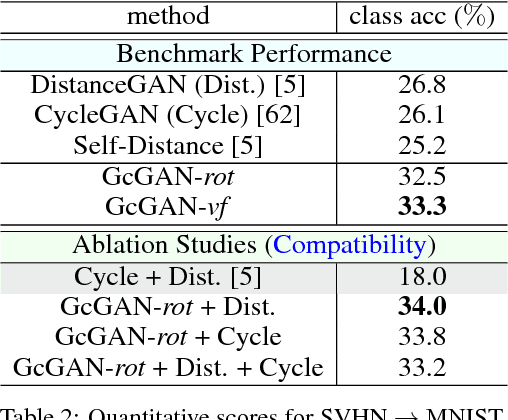
Unsupervised domain mapping aims at learning a function to translate domain X to Y (GXY : X to Y) in the absence of paired (X,Y) samples. Finding the optimal GXY without paired data is an ill-posed problem and hence appropriate constraints are required to obtain reasonable solutions. One of the most prominent constraint is cycle-consistency, which enforces the translated image by GXY to be translated back to the input image by an inverse mapping GYX. While cycle-consistency requires simultaneous training of GXY and GYX, recent methods have demonstrated one-sided domain mapping (only learn GXY) can be achieved by preserving pairwise distance between images before and after translation. Although cycle-consistency and distance preserving successfully constrain the solution space, they overlook the special properties of images that simple geometric transformations do not change the semantics of an image. Based on this special property, we develop a geometry-consistent adversarial network (GcGAN) which enables one-sided unsupervised domain mapping. Our GcGAN takes the original image and its counterpart image transformed by a predefined geometric transformation as inputs and generates two images in the new domain with the corresponding geometry-consistency constraint. The geometry-consistency constraint eliminates unreasonable solutions and produce more reliable solutions. Quantitative comparisons against baseline (GAN alone) and the state-of-the-art methods, including DistanceGAN and CycleGAN, demonstrate the superiority of our method in generating realistic images.
Transfer Learning with Label Noise
Aug 08, 2018
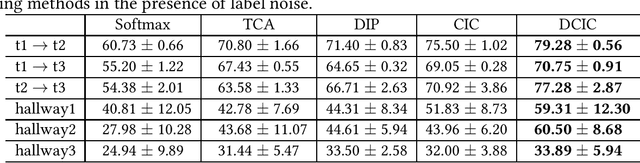
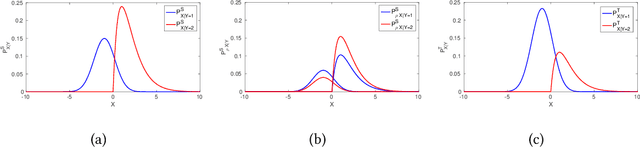
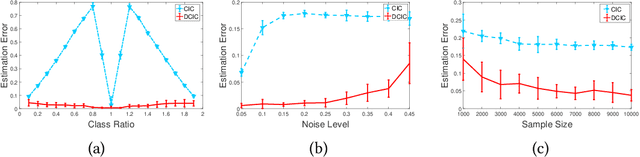
Transfer learning aims to improve learning in target domain by borrowing knowledge from a related but different source domain. To reduce the distribution shift between source and target domains, recent methods have focused on exploring invariant representations that have similar distributions across domains. However, when learning this invariant knowledge, existing methods assume that the labels in source domain are uncontaminated, while in reality, we often have access to source data with noisy labels. In this paper, we first show how label noise adversely affect the learning of invariant representations and the correcting of label shift in various transfer learning scenarios. To reduce the adverse effects, we propose a novel Denoising Conditional Invariant Component (DCIC) framework, which provably ensures (1) extracting invariant representations given examples with noisy labels in source domain and unlabeled examples in target domain; (2) estimating the label distribution in target domain with no bias. Experimental results on both synthetic and real-world data verify the effectiveness of the proposed method.
Causal Generative Domain Adaptation Networks
Jun 28, 2018
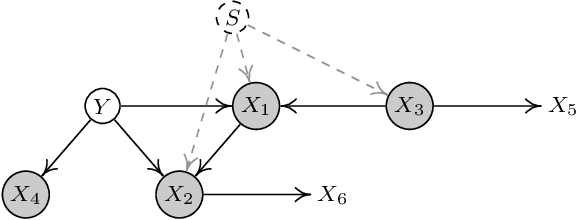
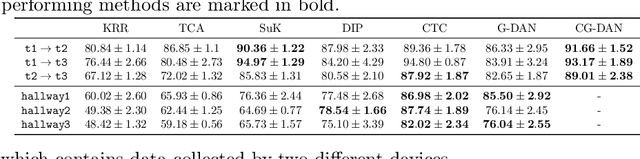
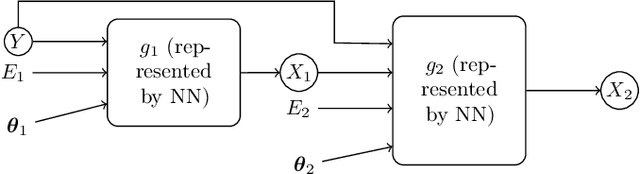
An essential problem in domain adaptation is to understand and make use of distribution changes across domains. For this purpose, we first propose a flexible Generative Domain Adaptation Network (G-DAN) with specific latent variables to capture changes in the generating process of features across domains. By explicitly modeling the changes, one can even generate data in new domains using the generating process with new values for the latent variables in G-DAN. In practice, the process to generate all features together may involve high-dimensional latent variables, requiring dealing with distributions in high dimensions and making it difficult to learn domain changes from few source domains. Interestingly, by further making use of the causal representation of joint distributions, we then decompose the joint distribution into separate modules, each of which involves different low-dimensional latent variables and can be learned separately, leading to a Causal G-DAN (CG-DAN). This improves both statistical and computational efficiency of the learning procedure. Finally, by matching the feature distribution in the target domain, we can recover the target-domain joint distribution and derive the learning machine for the target domain. We demonstrate the efficacy of both G-DAN and CG-DAN in domain generation and cross-domain prediction on both synthetic and real data experiments.
Deep Ordinal Regression Network for Monocular Depth Estimation
Jun 06, 2018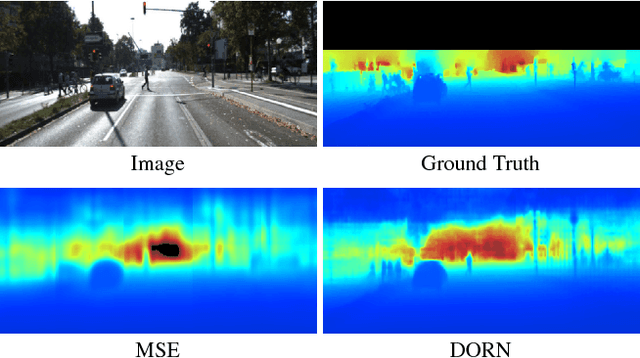
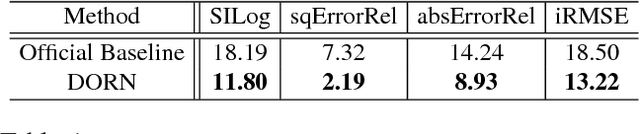
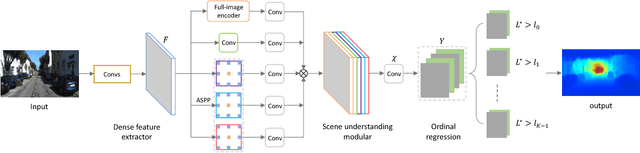
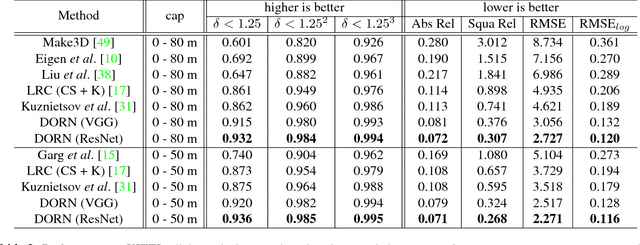
Monocular depth estimation, which plays a crucial role in understanding 3D scene geometry, is an ill-posed problem. Recent methods have gained significant improvement by exploring image-level information and hierarchical features from deep convolutional neural networks (DCNNs). These methods model depth estimation as a regression problem and train the regression networks by minimizing mean squared error, which suffers from slow convergence and unsatisfactory local solutions. Besides, existing depth estimation networks employ repeated spatial pooling operations, resulting in undesirable low-resolution feature maps. To obtain high-resolution depth maps, skip-connections or multi-layer deconvolution networks are required, which complicates network training and consumes much more computations. To eliminate or at least largely reduce these problems, we introduce a spacing-increasing discretization (SID) strategy to discretize depth and recast depth network learning as an ordinal regression problem. By training the network using an ordinary regression loss, our method achieves much higher accuracy and \dd{faster convergence in synch}. Furthermore, we adopt a multi-scale network structure which avoids unnecessary spatial pooling and captures multi-scale information in parallel. The method described in this paper achieves state-of-the-art results on four challenging benchmarks, i.e., KITTI [17], ScanNet [9], Make3D [50], and NYU Depth v2 [42], and win the 1st prize in Robust Vision Challenge 2018. Code has been made available at: https://github.com/hufu6371/DORN.
Causal Discovery in the Presence of Measurement Error: Identifiability Conditions
Jun 10, 2017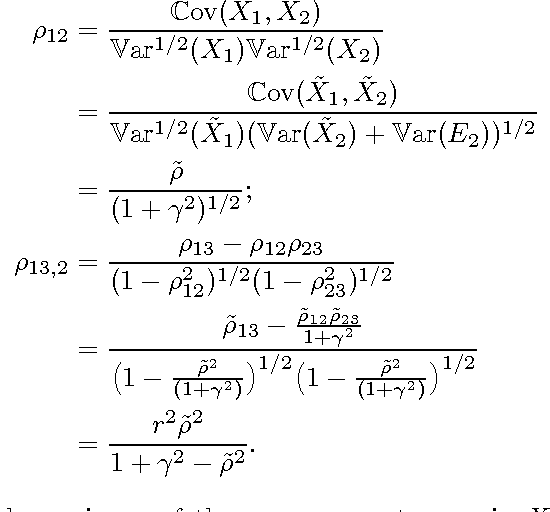
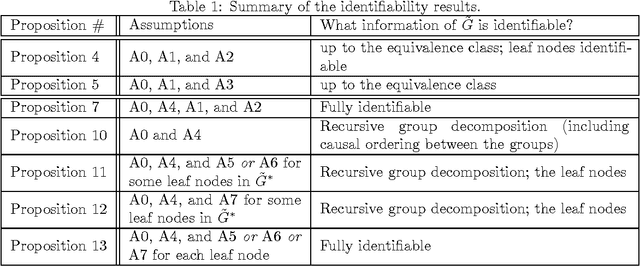
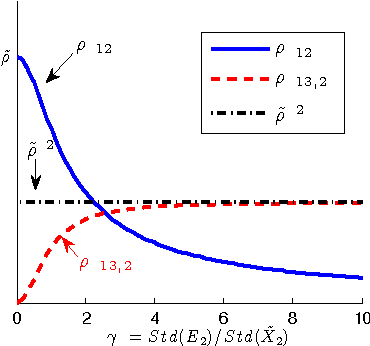
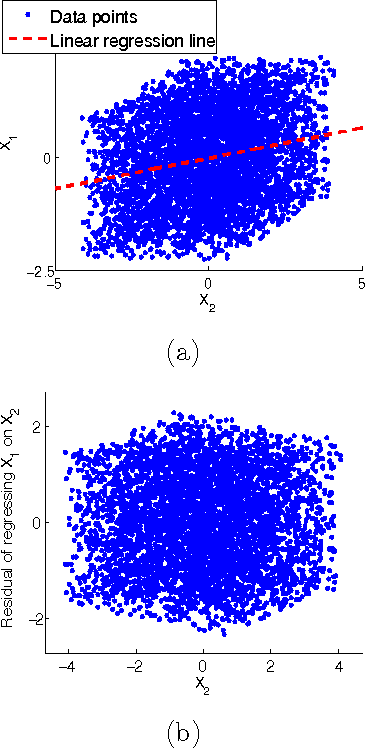
Measurement error in the observed values of the variables can greatly change the output of various causal discovery methods. This problem has received much attention in multiple fields, but it is not clear to what extent the causal model for the measurement-error-free variables can be identified in the presence of measurement error with unknown variance. In this paper, we study precise sufficient identifiability conditions for the measurement-error-free causal model and show what information of the causal model can be recovered from observed data. In particular, we present two different sets of identifiability conditions, based on the second-order statistics and higher-order statistics of the data, respectively. The former was inspired by the relationship between the generating model of the measurement-error-contaminated data and the factor analysis model, and the latter makes use of the identifiability result of the over-complete independent component analysis problem.
Nonparametric Spherical Topic Modeling with Word Embeddings
Apr 01, 2016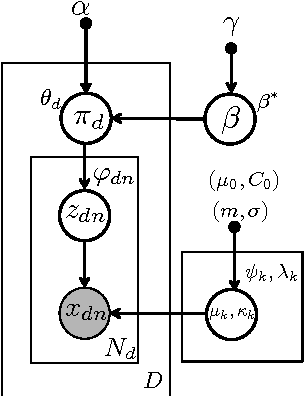


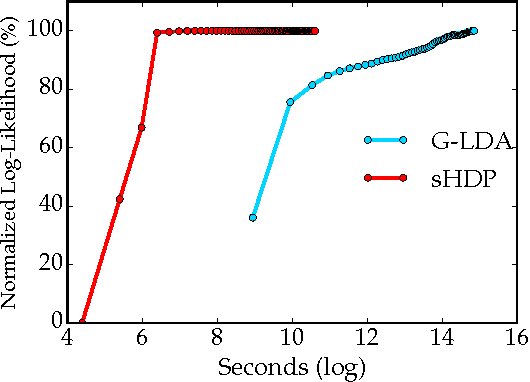
Traditional topic models do not account for semantic regularities in language. Recent distributional representations of words exhibit semantic consistency over directional metrics such as cosine similarity. However, neither categorical nor Gaussian observational distributions used in existing topic models are appropriate to leverage such correlations. In this paper, we propose to use the von Mises-Fisher distribution to model the density of words over a unit sphere. Such a representation is well-suited for directional data. We use a Hierarchical Dirichlet Process for our base topic model and propose an efficient inference algorithm based on Stochastic Variational Inference. This model enables us to naturally exploit the semantic structures of word embeddings while flexibly discovering the number of topics. Experiments demonstrate that our method outperforms competitive approaches in terms of topic coherence on two different text corpora while offering efficient inference.