 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-isotropy Regularization for Proxy-based Deep Metric Learning
Mar 16, 2022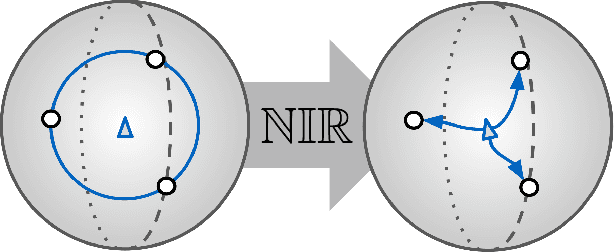
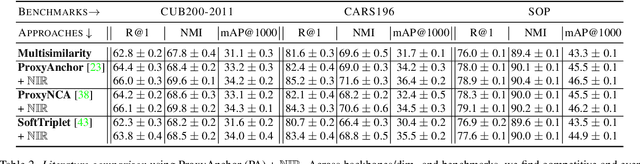
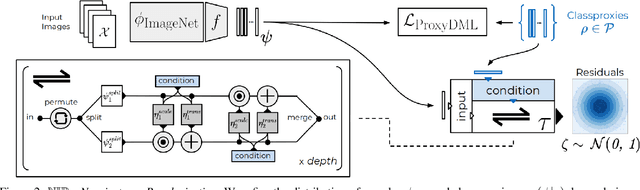
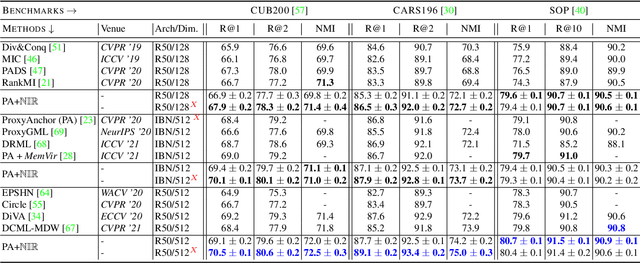
Deep Metric Learning (DML) aims to learn representation spaces on which semantic relations can simply be expressed through predefined distance metrics. Best performing approaches commonly leverage class proxies as sample stand-ins for better convergence and generalization. However, these proxy-methods solely optimize for sample-proxy distances. Given the inherent non-bijectiveness of used distance functions, this can induce locally isotropic sample distributions, leading to crucial semantic context being missed due to difficulties resolving local structures and intraclass relations between samples. To alleviate this problem, we propose non-isotropy regularization ($\mathbb{NIR}$) for proxy-based Deep Metric Learning. By leveraging Normalizing Flows, we enforce unique translatability of samples from their respective class proxies. This allows us to explicitly induce a non-isotropic distribution of samples around a proxy to optimize for. In doing so, we equip proxy-based objectives to better learn local structures. Extensive experiments highlight consistent generalization benefits of $\mathbb{NIR}$ while achieving competitive and state-of-the-art performance on the standard benchmarks CUB200-2011, Cars196 and Stanford Online Products. In addition, we find the superior convergence properties of proxy-based methods to still be retained or even improved, making $\mathbb{NIR}$ very attractive for practical usage. Code available at https://github.com/ExplainableML/NonIsotropicProxyDML.
Integrating Language Guidance into Vision-based Deep Metric Learning
Mar 16, 2022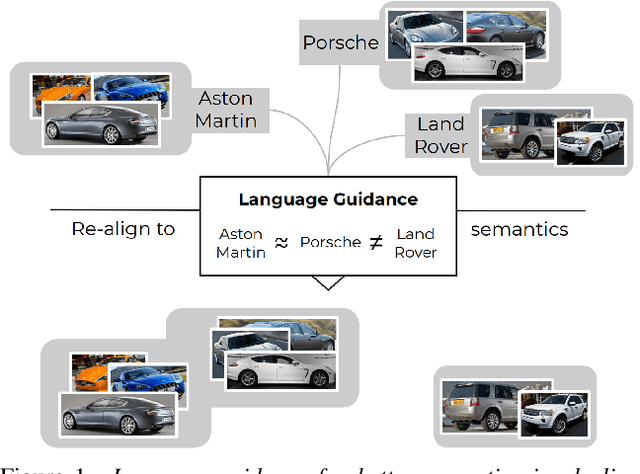
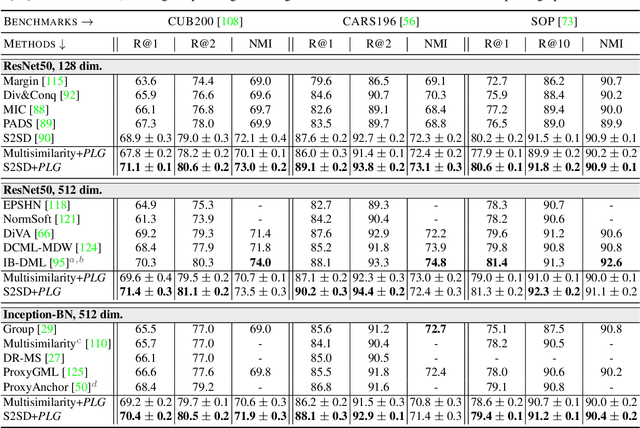
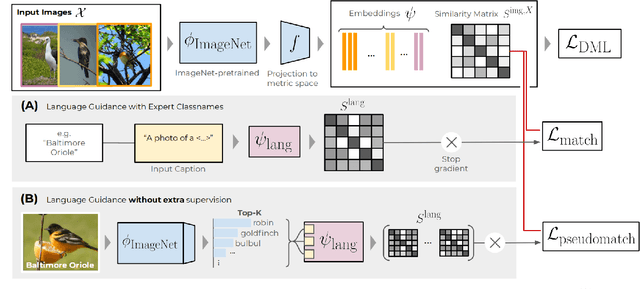
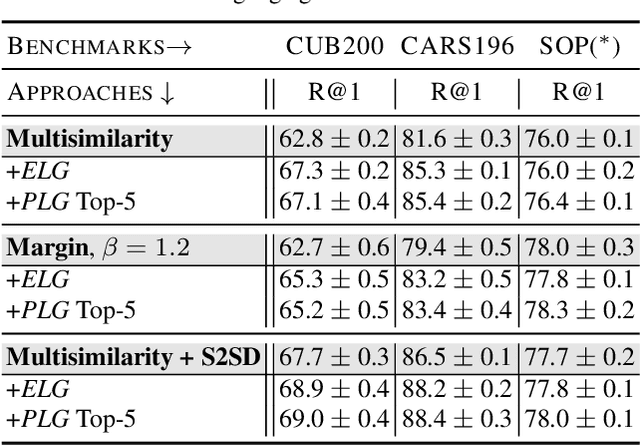
Deep Metric Learning (DML) proposes to learn metric spaces which encode semantic similarities as embedding space distances. These spaces should be transferable to classes beyond those seen during training. Commonly, DML methods task networks to solve contrastive ranking tasks defined over binary class assignments. However, such approaches ignore higher-level semantic relations between the actual classes. This causes learned embedding spaces to encode incomplete semantic context and misrepresent the semantic relation between classes, impacting the generalizability of the learned metric space. To tackle this issue, we propose a language guidance objective for visual similarity learning. Leveraging language embeddings of expert- and pseudo-classnames, we contextualize and realign visual representation spaces corresponding to meaningful language semantics for better semantic consistency. Extensive experiments and ablations provide a strong motivation for our proposed approach and show language guidance offering significant, model-agnostic improvements for DML, achieving competitive and state-of-the-art results on all benchmarks. Code available at https://github.com/ExplainableML/LanguageGuidance_for_DML.
Characterizing Generalization under Out-Of-Distribution Shifts in Deep Metric Learning
Jul 20, 2021
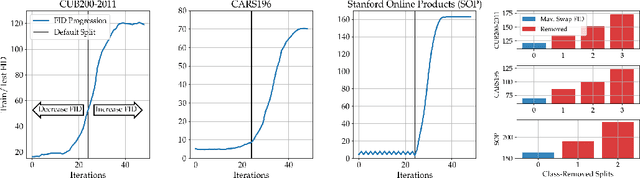
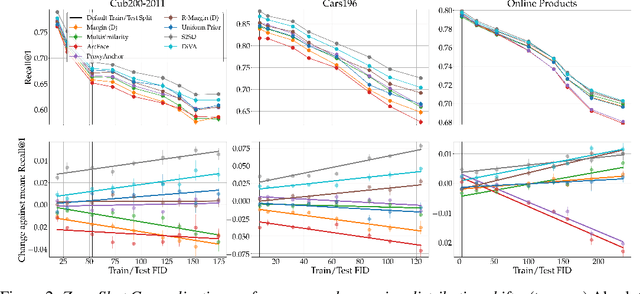
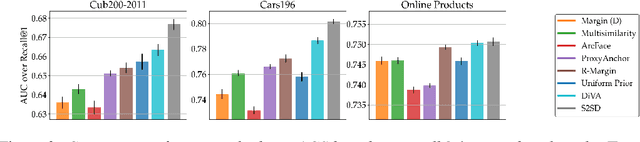
Deep Metric Learning (DML) aims to find representations suitable for zero-shot transfer to a priori unknown test distributions. However, common evaluation protocols only test a single, fixed data split in which train and test classes are assigned randomly. More realistic evaluations should consider a broad spectrum of distribution shifts with potentially varying degree and difficulty. In this work, we systematically construct train-test splits of increasing difficulty and present the ooDML benchmark to characterize generalization under out-of-distribution shifts in DML. ooDML is designed to probe the generalization performance on much more challenging, diverse train-to-test distribution shifts. Based on our new benchmark, we conduct a thorough empirical analysis of state-of-the-art DML methods. We find that while generalization tends to consistently degrade with difficulty, some methods are better at retaining performance as the distribution shift increases. Finally, we propose few-shot DML as an efficient way to consistently improve generalization in response to unknown test shifts presented in ooDML. Code available here: https://github.com/Confusezius/Characterizing_Generalization_in_DeepMetricLearning.
Towards Total Recall in Industrial Anomaly Detection
Jun 15, 2021

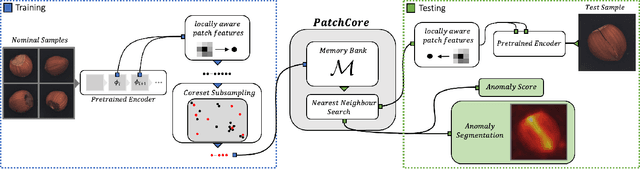
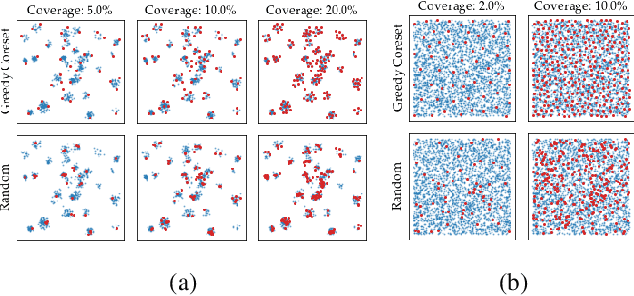
Being able to spot defective parts is a critical component in large-scale industrial manufacturing. A particular challenge that we address in this work is the cold-start problem: fit a model using nominal (non-defective) example images only. While handcrafted solutions per class are possible, the goal is to build systems that work well simultaneously on many different tasks automatically. The best peforming approaches combine embeddings from ImageNet models with an outlier detection model. In this paper, we extend on this line of work and propose PatchCore, which uses a maximally representative memory bank of nominal patch-features. PatchCore offers competitive inference times while achieving state-of-the-art performance for both detection and localization. On the standard dataset MVTec AD, PatchCore achieves an image-level anomaly detection AUROC score of $99.1\%$, more than halving the error compared to the next best competitor. We further report competitive results on two additional datasets and also find competitive results in the few samples regime.
S2SD: Simultaneous Similarity-based Self-Distillation for Deep Metric Learning
Oct 01, 2020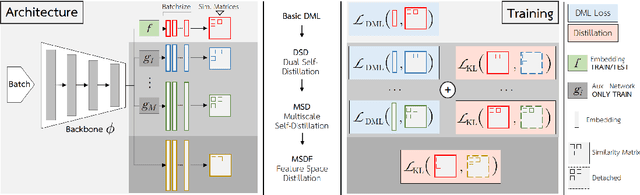
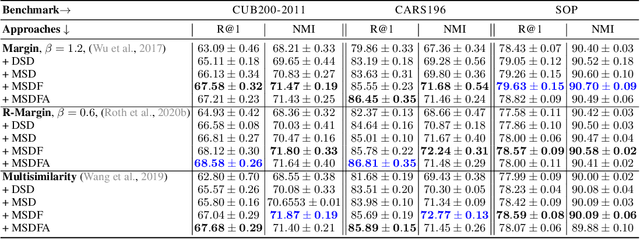
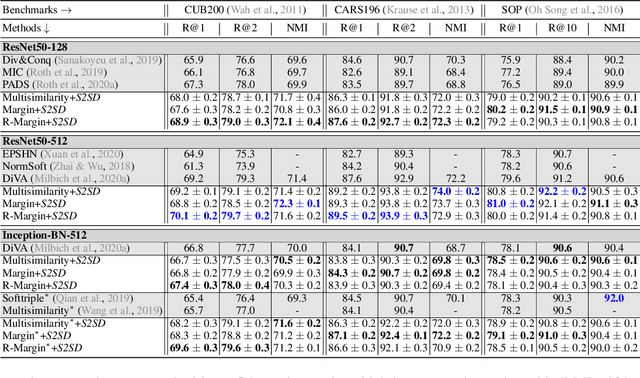
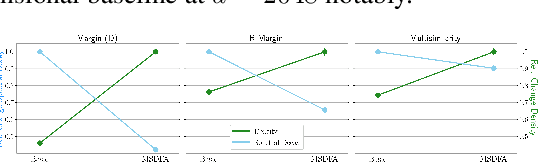
Deep Metric Learning (DML) provides a crucial tool for visual similarity and zero-shot retrieval applications by learning generalizing embedding spaces, although recent work in DML has shown strong performance saturation across training objectives. However, generalization capacity is known to scale with the embedding space dimensionality. Unfortunately, high dimensional embeddings also create higher retrieval cost for downstream applications. To remedy this, we propose S2SD - Simultaneous Similarity-based Self-distillation. S2SD extends DML with knowledge distillation from auxiliary, high-dimensional embedding and feature spaces to leverage complementary context during training while retaining test-time cost and with negligible changes to the training time. Experiments and ablations across different objectives and standard benchmarks show S2SD offering notable improvements of up to 7% in Recall@1, while also setting a new state-of-the-art. Code available at https://github.com/MLforHealth/S2SD.
COVID-19 Image Data Collection: Prospective Predictions Are the Future
Jun 22, 2020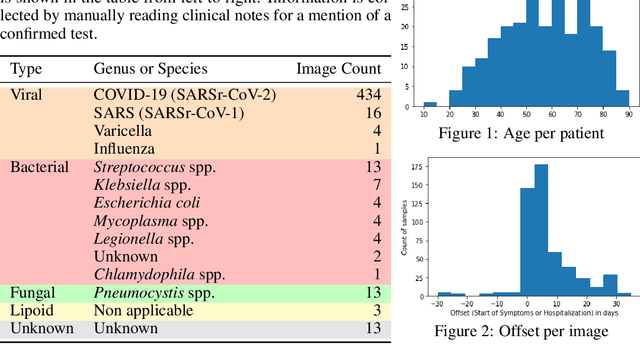
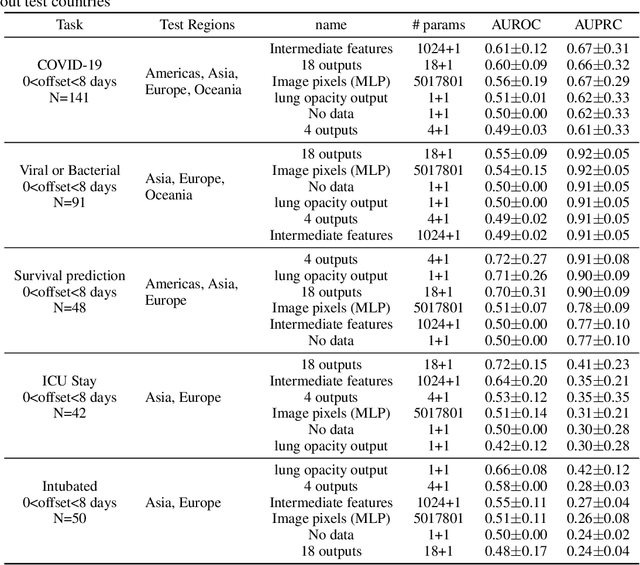
Across the world's coronavirus disease 2019 (COVID-19) hot spots, the need to streamline patient diagnosis and management has become more pressing than ever. As one of the main imaging tools, chest X-rays (CXRs) are common, fast, non-invasive, relatively cheap, and potentially bedside to monitor the progression of the disease. This paper describes the first public COVID-19 image data collection as well as a preliminary exploration of possible use cases for the data. This dataset currently contains hundreds of frontal view X-rays and is the largest public resource for COVID-19 image and prognostic data, making it a necessary resource to develop and evaluate tools to aid in the treatment of COVID-19. It was manually aggregated from publication figures as well as various web based repositories into a machine learning (ML) friendly format with accompanying dataloader code. We collected frontal and lateral view imagery and metadata such as the time since first symptoms, intensive care unit (ICU) status, survival status, intubation status, or hospital location. We present multiple possible use cases for the data such as predicting the need for the ICU, predicting patient survival, and understanding a patient's trajectory during treatment. Data can be accessed here: https://github.com/ieee8023/covid-chestxray-dataset
Predicting COVID-19 Pneumonia Severity on Chest X-ray with Deep Learning
Jun 06, 2020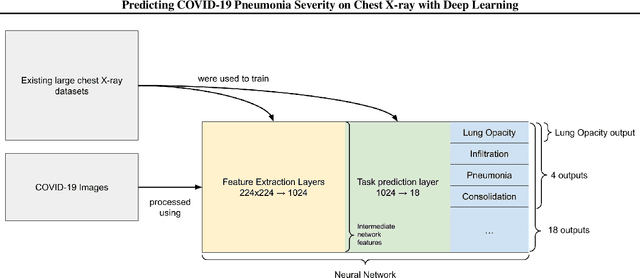


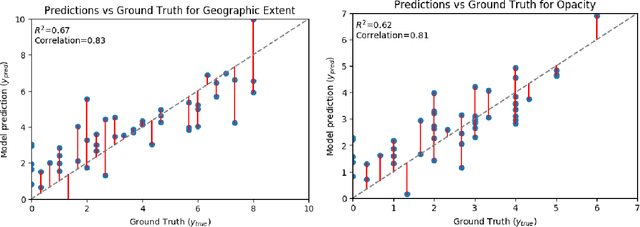
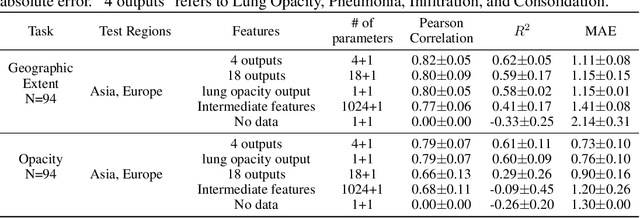
The need to streamline patient management for COVID-19 has become more pressing than ever. Chest X-rays provide a non-invasive (potentially bedside) tool to monitor the progression of the disease. In this study, we present a severity score prediction model for COVID-19 pneumonia for frontal chest X-ray images. Such a tool can gauge severity of COVID-19 lung infections (and pneumonia in general) that can be used for escalation or de-escalation of care as well as monitoring treatment efficacy, especially in the ICU. Images from a public COVID-19 database were scored retrospectively by three blinded experts in terms of the extent of lung involvement as well as the degree of opacity. A neural network model that was pre-trained on large (non-COVID-19) chest X-ray datasets is used to construct features for COVID-19 images which are predictive for our task. This study finds that training a regression model on a subset of the outputs from an this pre-trained chest X-ray model predicts our geographic extent score (range 0-8) with 1.14 mean absolute error (MAE) and our lung opacity score (range 0-6) with 0.78 MAE. All code, labels, and data are made available at https://github.com/mlmed/torchxrayvision and https://github.com/ieee8023/covid-chestxray-dataset
DiVA: Diverse Visual Feature Aggregation for Deep Metric Learning
Apr 29, 2020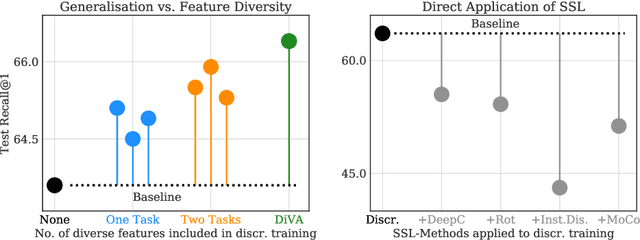
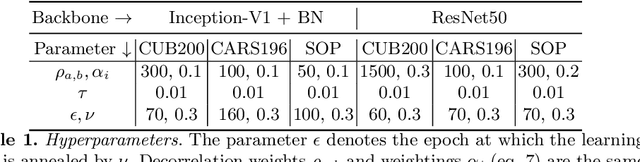
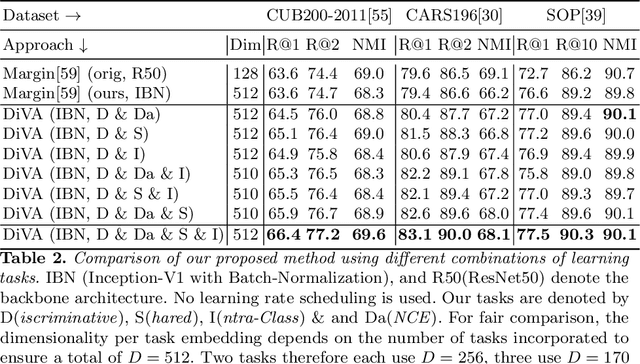
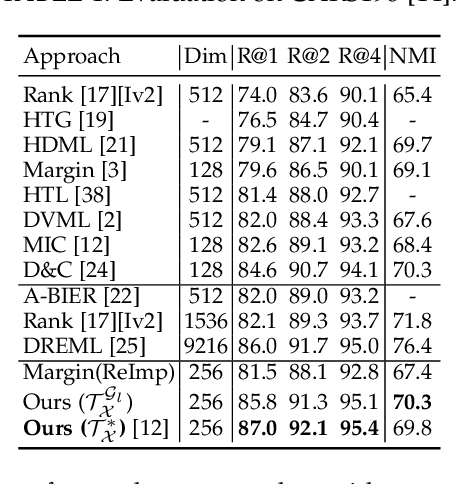
Visual Similarity plays an important role in many computer vision applications. Deep metric learning (DML) is a powerful framework for learning such similarities which not only generalize from training data to identically distributed test distributions, but in particular also translate to unknown test classes. However, its prevailing learning paradigm is class-discriminative supervised training, which typically results in representations specialized in separating training classes. For effective generalization, however, such an image representation needs to capture a diverse range of data characteristics. To this end, we propose and study multiple complementary learning tasks, targeting conceptually different data relationships by only resorting to the available training samples and labels of a standard DML setting. Through simultaneous optimization of our tasks we learn a single model to aggregate their training signals, resulting in strong generalization and state-of-the-art performance on multiple established DML benchmark datasets.
Sharing Matters for Generalization in Deep Metric Learning
Apr 12, 2020
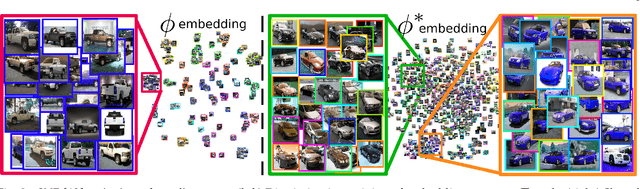
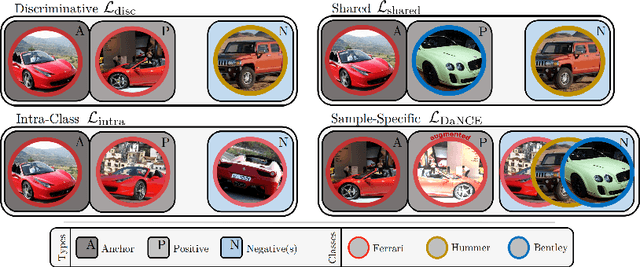
Learning the similarity between images constitutes the foundation for numerous vision tasks. The common paradigm is discriminative metric learning, which seeks an embedding that separates different training classes. However, the main challenge is to learn a metric that not only generalizes from training to novel, but related, test samples. It should also transfer to different object classes. So what complementary information is missed by the discriminative paradigm? Besides finding characteristics that separate between classes, we also need them to likely occur in novel categories, which is indicated if they are shared across training classes. This work investigates how to learn such characteristics without the need for extra annotations or training data. By formulating our approach as a novel triplet sampling strategy, it can be easily applied on top of recent ranking loss frameworks. Experiments show that, independent of the underlying network architecture and the specific ranking loss, our approach significantly improves performance in deep metric learning, leading to new the state-of-the-art results on various standard benchmark datasets.
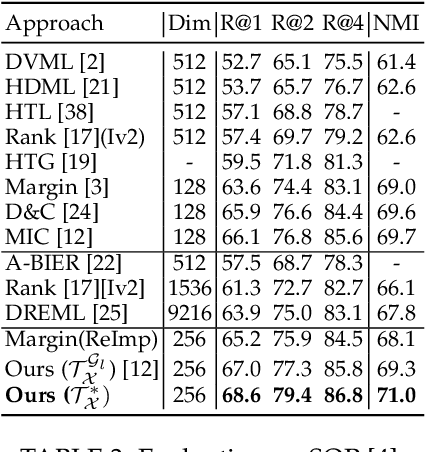
PADS: Policy-Adapted Sampling for Visual Similarity Learning
Mar 28, 2020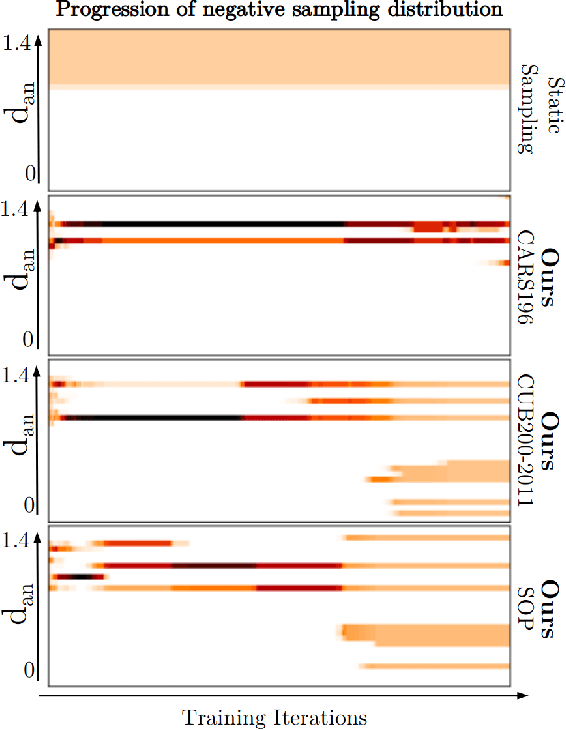
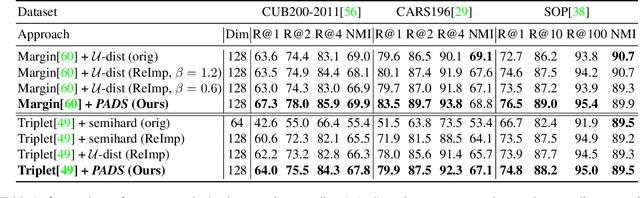
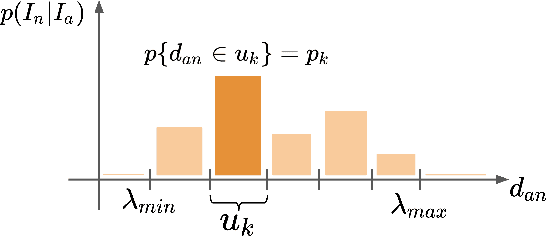
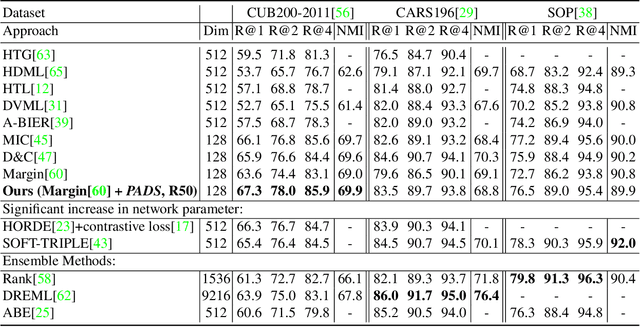
Learning visual similarity requires to learn relations, typically between triplets of images. Albeit triplet approaches being powerful, their computational complexity mostly limits training to only a subset of all possible training triplets. Thus, sampling strategies that decide when to use which training sample during learning are crucial. Currently, the prominent paradigm are fixed or curriculum sampling strategies that are predefined before training starts. However, the problem truly calls for a sampling process that adjusts based on the actual state of the similarity representation during training. We, therefore, employ reinforcement learning and have a teacher network adjust the sampling distribution based on the current state of the learner network, which represents visual similarity. Experiments on benchmark datasets using standard triplet-based losses show that our adaptive sampling strategy significantly outperforms fixed sampling strategies. Moreover, although our adaptive sampling is only applied on top of basic triplet-learning frameworks, we reach competitive results to state-of-the-art approaches that employ diverse additional learning signals or strong ensemble architectures. Code can be found under https://github.com/Confusezius/CVPR2020_PADS.