 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigns Beat Floats: Low-Rank Double-Binary Adaptation for On-Device Fine-Tuning
May 22, 2026On-device adaptation of large language models commonly keeps a quantized base model frozen while training and deploying a small, task-specific LoRA adapter. In the unmerged adapter-mode setting, however, the adapter is more than a compact storage module; it introduces an additional dense floating-point branch, maintains a trainable state for local updates, and acts as a unit of communication and hot-swapping.We introduce LoRDBA, a LoRA-compatible adapter that replaces both low-rank factors with binary sign carriers while representing magnitudes through lightweight, channel-wise scales, converting the dense adapter branch into two sign-accumulation matrix multiplications interleaved with channel-wise scaling. A finite-sample analysis shows that reconstruction quality is governed by the residual-to-magnitude ratio of the original LoRA factors. In adapter-mode experiments, LoRDBA outperforms low-bit baselines at matched model sizes while matching fp16 LoRA quality in selected regimes. The unmerged adapter incurs at most 8% prefill latency overhead at matched rank r=16 despite an over 10x reduction in adapter footprint, with moderate training memory overhead of approximately 1.6x that of fp16 LoRA.
OneComp: One-Line Revolution for Generative AI Model Compression
Mar 30, 2026Deploying foundation models is increasingly constrained by memory footprint, latency, and hardware costs. Post-training compression can mitigate these bottlenecks by reducing the precision of model parameters without significantly degrading performance; however, its practical implementation remains challenging as practitioners navigate a fragmented landscape of quantization algorithms, precision budgets, data-driven calibration strategies, and hardware-dependent execution regimes. We present OneComp, an open-source compression framework that transforms this expert workflow into a reproducible, resource-adaptive pipeline. Given a model identifier and available hardware, OneComp automatically inspects the model, plans mixed-precision assignments, and executes progressive quantization stages, ranging from layer-wise compression to block-wise refinement and global refinement. A key architectural choice is treating the first quantized checkpoint as a deployable pivot, ensuring that each subsequent stage improves the same model and that quality increases as more compute is invested. By converting state-of-the-art compression research into an extensible, open-source, hardware-aware pipeline, OneComp bridges the gap between algorithmic innovation and production-grade model deployment.
Sign Lock-In: Randomly Initialized Weight Signs Persist and Bottleneck Sub-Bit Model Compression
Feb 19, 2026Sub-bit model compression seeks storage below one bit per weight; as magnitudes are aggressively compressed, the sign bit becomes a fixed-cost bottleneck. Across Transformers, CNNs, and MLPs, learned sign matrices resist low-rank approximation and are spectrally indistinguishable from an i.i.d. Rademacher baseline. Despite this apparent randomness, most weights retain their initialization signs; flips primarily occur via rare near-zero boundary crossings, suggesting that sign-pattern randomness is largely inherited from initialization. We formalize this behavior with sign lock-in theory, a stopping-time analysis of sign flips under SGD noise. Under bounded updates and a rare re-entry condition into a small neighborhood around zero, the number of effective sign flips exhibits a geometric tail. Building on this mechanism, we introduce a gap-based initialization and a lightweight outward-drift regularizer, reducing the effective flip rate to approximately $10^{-3}$ with only about a one-point increase in perplexity.
More Than Bits: Multi-Envelope Double Binary Factorization for Extreme Quantization
Dec 31, 2025For extreme low-bit quantization of large language models (LLMs), Double Binary Factorization (DBF) is attractive as it enables efficient inference without sacrificing accuracy. However, the scaling parameters of DBF are too restrictive; after factoring out signs, all rank components share the same magnitude profile, resulting in performance saturation. We propose Multi-envelope DBF (MDBF), which retains a shared pair of 1-bit sign bases but replaces the single envelope with a rank-$l$ envelope. By sharing sign matrices among envelope components, MDBF effectively maintains a binary carrier and utilizes the limited memory budget for magnitude expressiveness. We also introduce a closed-form initialization and an alternating refinement method to optimize MDBF. Across the LLaMA and Qwen families, MDBF enhances perplexity and zero-shot accuracy over previous binary formats at matched bits per weight while preserving the same deployment-friendly inference primitive.
PHOTON: Hierarchical Autoregressive Modeling for Lightspeed and Memory-Efficient Language Generation
Dec 22, 2025Transformers operate as horizontal token-by-token scanners; at each generation step, the model attends to an ever-growing sequence of token-level states. This access pattern increases prefill latency and makes long-context decoding increasingly memory-bound, as KV-cache reads and writes dominate inference throughput rather than arithmetic computation. We propose Parallel Hierarchical Operation for Top-down Networks (PHOTON), a hierarchical autoregressive model that replaces flat scanning with vertical, multi-resolution context access. PHOTON maintains a hierarchy of latent streams: a bottom-up encoder progressively compresses tokens into low-rate contextual states, while lightweight top-down decoders reconstruct fine-grained token representations. Experimental results show that PHOTON is superior to competitive Transformer-based language models regarding the throughput-quality trade-off, offering significant advantages in long-context and multi-query tasks. This reduces decode-time KV-cache traffic, yielding up to $10^{3}\times$ higher throughput per unit memory.
Three approaches to facilitate DNN generalization to objects in out-of-distribution orientations and illuminations: late-stopping, tuning batch normalization and invariance loss
Oct 30, 2021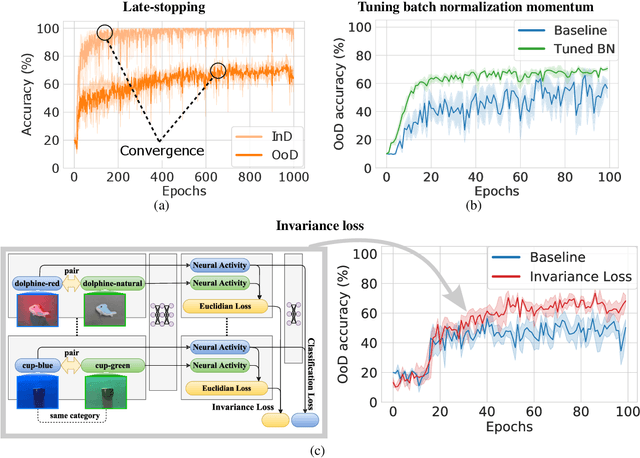



The training data distribution is often biased towards objects in certain orientations and illumination conditions. While humans have a remarkable capability of recognizing objects in out-of-distribution (OoD) orientations and illuminations, Deep Neural Networks (DNNs) severely suffer in this case, even when large amounts of training examples are available. In this paper, we investigate three different approaches to improve DNNs in recognizing objects in OoD orientations and illuminations. Namely, these are (i) training much longer after convergence of the in-distribution (InD) validation accuracy, i.e., late-stopping, (ii) tuning the momentum parameter of the batch normalization layers, and (iii) enforcing invariance of the neural activity in an intermediate layer to orientation and illumination conditions. Each of these approaches substantially improves the DNN's OoD accuracy (more than 20% in some cases). We report results in four datasets: two datasets are modified from the MNIST and iLab datasets, and the other two are novel (one of 3D rendered cars and another of objects taken from various controlled orientations and illumination conditions). These datasets allow to study the effects of different amounts of bias and are challenging as DNNs perform poorly in OoD conditions. Finally, we demonstrate that even though the three approaches focus on different aspects of DNNs, they all tend to lead to the same underlying neural mechanism to enable OoD accuracy gains -- individual neurons in the intermediate layers become more selective to a category and also invariant to OoD orientations and illuminations.
Bermuda Triangles: GNNs Fail to Detect Simple Topological Structures
May 01, 2021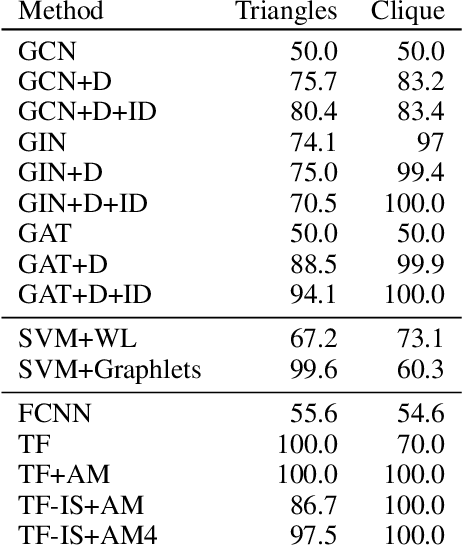
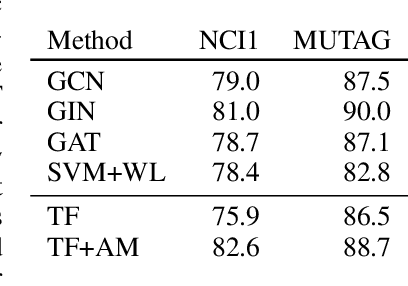
Most graph neural network architectures work by message-passing node vector embeddings over the adjacency matrix, and it is assumed that they capture graph topology by doing that. We design two synthetic tasks, focusing purely on topological problems -- triangle detection and clique distance -- on which graph neural networks perform surprisingly badly, failing to detect those "bermuda" triangles. Datasets and their generation scripts are publicly available on github.com/FujitsuLaboratories/bermudatriangles and dataset.labs.fujitsu.com.