 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlloc-MoE: Budget-Aware Expert Activation Allocation for Efficient Mixture-of-Experts Inference
Apr 09, 2026Mixture-of-Experts (MoE) has become a dominant architecture for scaling large language models due to their sparse activation mechanism. However, the substantial number of expert activations creates a critical latency bottleneck during inference, especially in resource-constrained deployment scenarios. Existing approaches that reduce expert activations potentially lead to severe model performance degradation. In this work, we introduce the concept of \emph{activation budget} as a constraint on the number of expert activations and propose Alloc-MoE, a unified framework that optimizes budget allocation coordinately at both the layer and token levels to minimize performance degradation. At the layer level, we introduce Alloc-L, which leverages sensitivity profiling and dynamic programming to determine the optimal allocation of expert activations across layers. At the token level, we propose Alloc-T, which dynamically redistributes activations based on routing scores, optimizing budget allocation without increasing latency. Extensive experiments across multiple MoE models demonstrate that Alloc-MoE maintains model performance under a constrained activation budget. Especially, Alloc-MoE achieves $1.15\times$ prefill and $1.34\times$ decode speedups on DeepSeek-V2-Lite at half of the original budget.
GRASS: Gradient-based Adaptive Layer-wise Importance Sampling for Memory-efficient Large Language Model Fine-tuning
Apr 09, 2026Full-parameter fine-tuning of large language models is constrained by substantial GPU memory requirements. Low-rank adaptation methods mitigate this challenge by updating only a subset of parameters. However, these approaches often limit model expressiveness and yield lower performance than full-parameter fine-tuning. Layer-wise fine-tuning methods have emerged as an alternative, enabling memory-efficient training through static layer importance sampling strategies. However, these methods overlook variations in layer importance across tasks and training stages, resulting in suboptimal performance on downstream tasks. To address these limitations, we propose GRASS, a gradient-based adaptive layer-wise importance sampling framework. GRASS utilizes mean gradient norms as a task-aware and training-stage-aware metric for estimating layer importance. Furthermore, GRASS adaptively adjusts layer sampling probabilities through an adaptive training strategy. We also introduce a layer-wise optimizer state offloading mechanism that overlaps computation and communication to further reduce memory usage while maintaining comparable training throughput. Extensive experiments across multiple models and benchmarks demonstrate that GRASS consistently outperforms state-of-the-art methods, achieving an average accuracy improvement of up to 4.38 points and reducing memory usage by up to 19.97\%.
A Survey on Memory-Efficient Large-Scale Model Training in AI for Science
Jan 21, 2025



Scientific research faces high costs and inefficiencies with traditional methods, but the rise of deep learning and large language models (LLMs) offers innovative solutions. This survey reviews LLM applications across scientific fields such as biology, medicine, chemistry, and meteorology, underscoring their role in advancing research. However, the continuous expansion of model size has led to significant memory demands, hindering further development and application of LLMs for science. To address this, we review memory-efficient training techniques for LLMs based on the transformer architecture, including distributed training, mixed precision training, and gradient checkpointing. Using AlphaFold 2 as an example, we demonstrate how tailored memory optimization methods can reduce storage needs while preserving prediction accuracy. We also discuss the challenges of memory optimization in practice and potential future directions, hoping to provide valuable insights for researchers and engineers.
Scattering Environment Aware Joint Multi-user Channel Estimation and Localization with Spatially Reused Pilots
Jan 04, 2025



The increasing number of users leads to an increase in pilot overhead, and the limited pilot resources make it challenging to support all users using orthogonal pilots. By fully capturing the inherent physical characteristics of the multi-user (MU) environment, it is possible to reduce pilot costs and improve the channel estimation performance. In reality, users nearby may share the same scatterer, while users further apart tend to have orthogonal channels. This paper proposes a two-timescale approach for joint MU uplink channel estimation and localization in MIMO-OFDM systems, which fully captures the spatial characteristics of MUs. To accurately represent the structure of the MU channel, the channel is modeled in the 3-D location domain. In the long-timescale phase, the time-space-time multiple signal classification (TST-MUSIC) algorithm initially offers a rough approximation of scatterer positions for each user, which is subsequently refined through the scatterer association algorithm based on density-based spatial clustering of applications with noise (DBSCAN) algorithm. The BS then utilizes this prior information to apply a graph-coloring-based user grouping algorithm, enabling spatial division multiplexing of pilots and reducing pilot overhead. In the short timescale phase, a low-complexity scattering environment aware location-domain turbo channel estimation (SEA-LD-TurboCE) algorithm is introduced to merge the overlapping scatterer information from MUs, facilitating high-precision joint MU channel estimation and localization under spatially reused pilots. Simulation results verify the superior channel estimation and localization performance of our proposed scheme over the baselines.
Hybrid Offline-Online Design for Reconfigurable Intelligent Surface Aided UAV Communication
May 27, 2022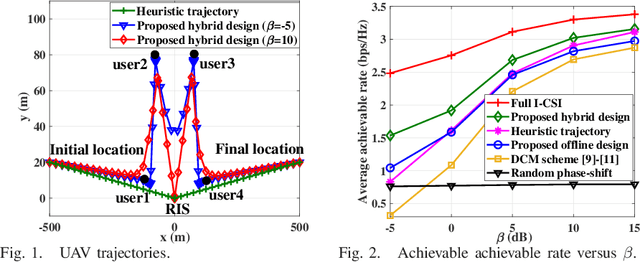
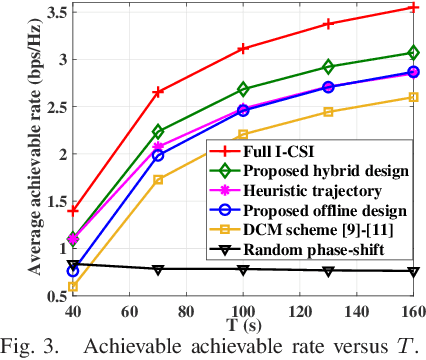
This letter considers the reconfigurable intelligent surface (RIS)-aided unmanned aerial vehicle (UAV) communication systems in urban areas under the general Rician fading channel. A hybrid offline-online design is proposed to improve the system performance by leveraging both the statistical channel state information (S-CSI) and instantaneous channel state information (I-CSI). For the offline phase, we aim to maximize the expected average achievable rate based on the S-CSI by jointly optimizing the RIS's phase-shift and UAV trajectory. The formulated stochastic optimization problem is difficult to solve due to its non-convexity. To tackle this problem, we propose an efficient algorithm by leveraging the stochastic successive convex approximation (SSCA) techniques. For the online phase, the UAV adaptively adjusts the transmit beamforming and user scheduling according to the effective I-CSI. Numerical results verify that the proposed hybrid design performs better than various bechmark schemes, and also demonstrate a favorable trade-off between system performance and CSI overhead.