 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgGym: An agricultural biotic stress simulation environment for ultra-precision management planning
Sep 01, 2024



Agricultural production requires careful management of inputs such as fungicides, insecticides, and herbicides to ensure a successful crop that is high-yielding, profitable, and of superior seed quality. Current state-of-the-art field crop management relies on coarse-scale crop management strategies, where entire fields are sprayed with pest and disease-controlling chemicals, leading to increased cost and sub-optimal soil and crop management. To overcome these challenges and optimize crop production, we utilize machine learning tools within a virtual field environment to generate localized management plans for farmers to manage biotic threats while maximizing profits. Specifically, we present AgGym, a modular, crop and stress agnostic simulation framework to model the spread of biotic stresses in a field and estimate yield losses with and without chemical treatments. Our validation with real data shows that AgGym can be customized with limited data to simulate yield outcomes under various biotic stress conditions. We further demonstrate that deep reinforcement learning (RL) policies can be trained using AgGym for designing ultra-precise biotic stress mitigation strategies with potential to increase yield recovery with less chemicals and lower cost. Our proposed framework enables personalized decision support that can transform biotic stress management from being schedule based and reactive to opportunistic and prescriptive. We also release the AgGym software implementation as a community resource and invite experts to contribute to this open-sourced publicly available modular environment framework. The source code can be accessed at: https://github.com/SCSLabISU/AgGym.
MDPGT: Momentum-based Decentralized Policy Gradient Tracking
Dec 06, 2021
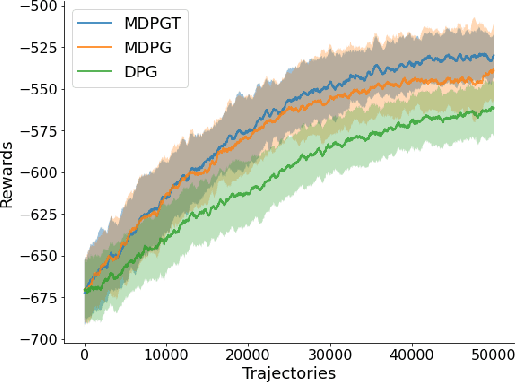
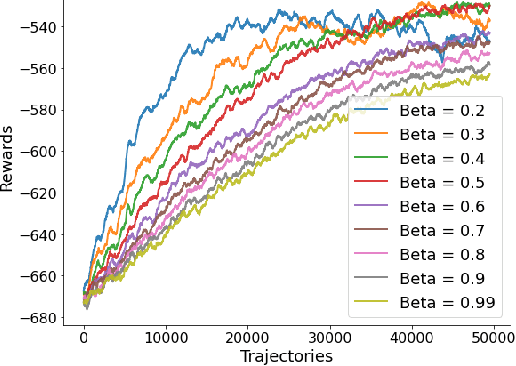
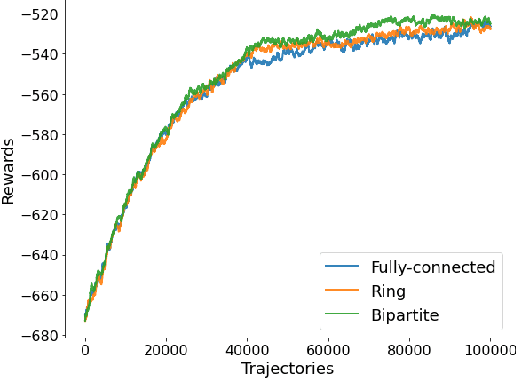
We propose a novel policy gradient method for multi-agent reinforcement learning, which leverages two different variance-reduction techniques and does not require large batches over iterations. Specifically, we propose a momentum-based decentralized policy gradient tracking (MDPGT) where a new momentum-based variance reduction technique is used to approximate the local policy gradient surrogate with importance sampling, and an intermediate parameter is adopted to track two consecutive policy gradient surrogates. Moreover, MDPGT provably achieves the best available sample complexity of $\mathcal{O}(N^{-1}\epsilon^{-3})$ for converging to an $\epsilon$-stationary point of the global average of $N$ local performance functions (possibly nonconcave). This outperforms the state-of-the-art sample complexity in decentralized model-free reinforcement learning, and when initialized with a single trajectory, the sample complexity matches those obtained by the existing decentralized policy gradient methods. We further validate the theoretical claim for the Gaussian policy function. When the required error tolerance $\epsilon$ is small enough, MDPGT leads to a linear speed up, which has been previously established in decentralized stochastic optimization, but not for reinforcement learning. Lastly, we provide empirical results on a multi-agent reinforcement learning benchmark environment to support our theoretical findings.
Query-based Targeted Action-Space Adversarial Policies on Deep Reinforcement Learning Agents
Nov 13, 2020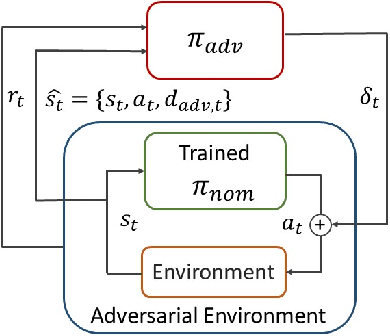
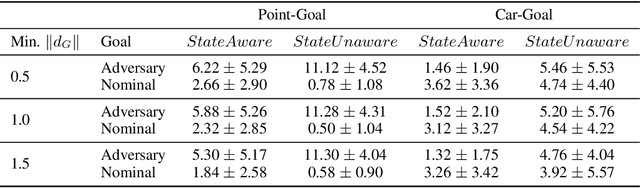
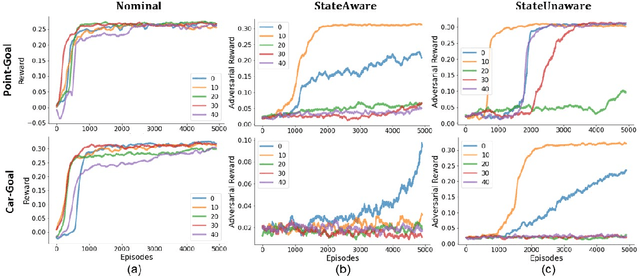
Advances in computing resources have resulted in the increasing complexity of cyber-physical systems (CPS). As the complexity of CPS evolved, the focus has shifted from traditional control methods to deep reinforcement learning-based (DRL) methods for control of these systems. This is due to the difficulty of obtaining accurate models of complex CPS for traditional control. However, to securely deploy DRL in production, it is essential to examine the weaknesses of DRL-based controllers (policies) towards malicious attacks from all angles. In this work, we investigate targeted attacks in the action-space domain, also commonly known as actuation attacks in CPS literature, which perturbs the outputs of a controller. We show that a query-based black-box attack model that generates optimal perturbations with respect to an adversarial goal can be formulated as another reinforcement learning problem. Thus, such an adversarial policy can be trained using conventional DRL methods. Experimental results showed that adversarial policies that only observe the nominal policy's output generate stronger attacks than adversarial policies that observe the nominal policy's input and output. Further analysis reveals that nominal policies whose outputs are frequently at the boundaries of the action space are naturally more robust towards adversarial policies. Lastly, we propose the use of adversarial training with transfer learning to induce robust behaviors into the nominal policy, which decreases the rate of successful targeted attacks by half.
Robustifying Reinforcement Learning Agents via Action Space Adversarial Training
Jul 14, 2020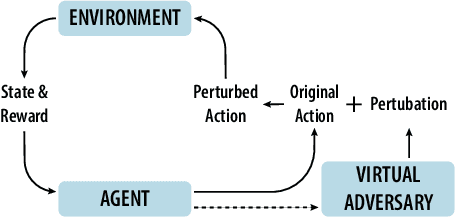
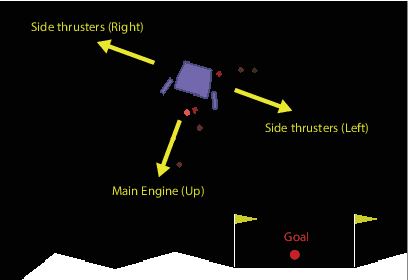
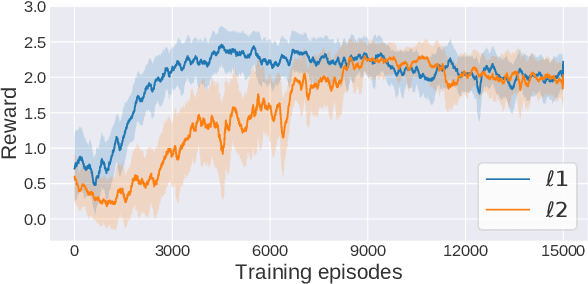
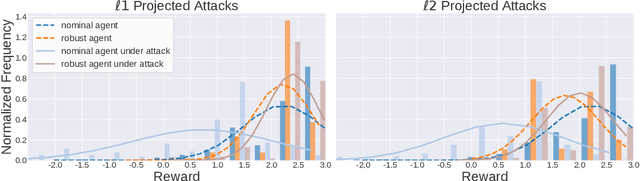
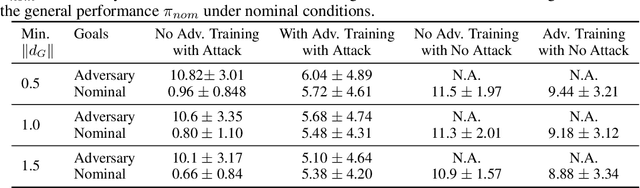
Adoption of machine learning (ML)-enabled cyber-physical systems (CPS) are becoming prevalent in various sectors of modern society such as transportation, industrial, and power grids. Recent studies in deep reinforcement learning (DRL) have demonstrated its benefits in a large variety of data-driven decisions and control applications. As reliance on ML-enabled systems grows, it is imperative to study the performance of these systems under malicious state and actuator attacks. Traditional control systems employ resilient/fault-tolerant controllers that counter these attacks by correcting the system via error observations. However, in some applications, a resilient controller may not be sufficient to avoid a catastrophic failure. Ideally, a robust approach is more useful in these scenarios where a system is inherently robust (by design) to adversarial attacks. While robust control has a long history of development, robust ML is an emerging research area that has already demonstrated its relevance and urgency. However, the majority of robust ML research has focused on perception tasks and not on decision and control tasks, although the ML (specifically RL) models used for control applications are equally vulnerable to adversarial attacks. In this paper, we show that a well-performing DRL agent that is initially susceptible to action space perturbations (e.g. actuator attacks) can be robustified against similar perturbations through adversarial training.
Deep Reinforcement Learning for Adaptive Traffic Signal Control
Nov 14, 2019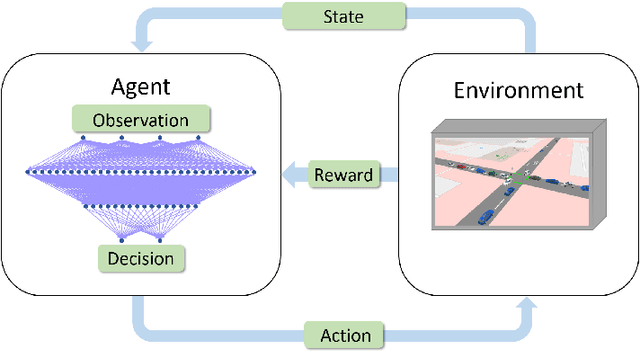
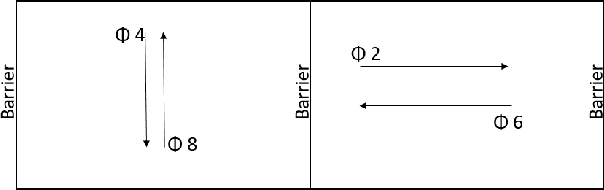

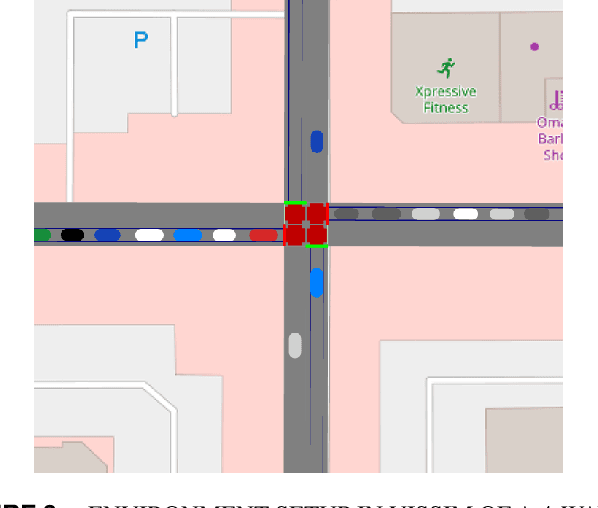
Many existing traffic signal controllers are either simple adaptive controllers based on sensors placed around traffic intersections, or optimized by traffic engineers on a fixed schedule. Optimizing traffic controllers is time consuming and usually require experienced traffic engineers. Recent research has demonstrated the potential of using deep reinforcement learning (DRL) in this context. However, most of the studies do not consider realistic settings that could seamlessly transition into deployment. In this paper, we propose a DRL-based adaptive traffic signal control framework that explicitly considers realistic traffic scenarios, sensors, and physical constraints. In this framework, we also propose a novel reward function that shows significantly improved traffic performance compared to the typical baseline pre-timed and fully-actuated traffic signals controllers. The framework is implemented and validated on a simulation platform emulating real-life traffic scenarios and sensor data streams.
Spatiotemporally Constrained Action Space Attacks on Deep Reinforcement Learning Agents
Sep 05, 2019
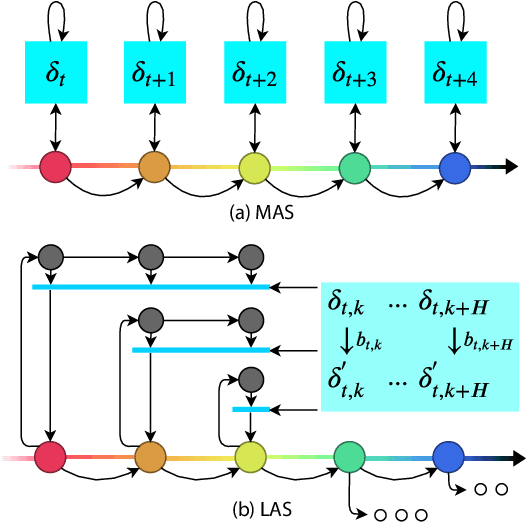
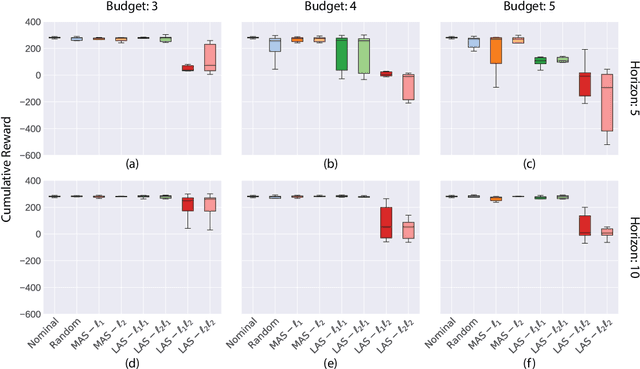
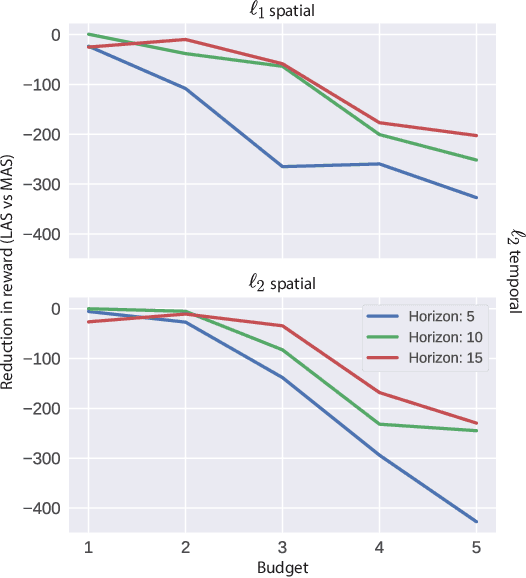
Robustness of Deep Reinforcement Learning (DRL) algorithms towards adversarial attacks in real world applications such as those deployed in cyber-physical systems (CPS) are of increasing concern. Numerous studies have investigated the mechanisms of attacks on the RL agent's state space. Nonetheless, attacks on the RL agent's action space (AS) (corresponding to actuators in engineering systems) are equally perverse; such attacks are relatively less studied in the ML literature. In this work, we first frame the problem as an optimization problem of minimizing the cumulative reward of an RL agent with decoupled constraints as the budget of attack. We propose a white-box Myopic Action Space (MAS) attack algorithm that distributes the attacks across the action space dimensions. Next, we reformulate the optimization problem above with the same objective function, but with a temporally coupled constraint on the attack budget to take into account the approximated dynamics of the agent. This leads to the white-box Look-ahead Action Space (LAS) attack algorithm that distributes the attacks across the action and temporal dimensions. Our results shows that using the same amount of resources, the LAS attack deteriorates the agent's performance significantly more than the MAS attack. This reveals the possibility that with limited resource, an adversary can utilize the agent's dynamics to malevolently craft attacks that causes the agent to fail. Additionally, we leverage these attack strategies as a possible tool to gain insights on the potential vulnerabilities of DRL agents.