 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Deep Reinforcement Learning Agents Trained with Domain Randomisation
Dec 18, 2019

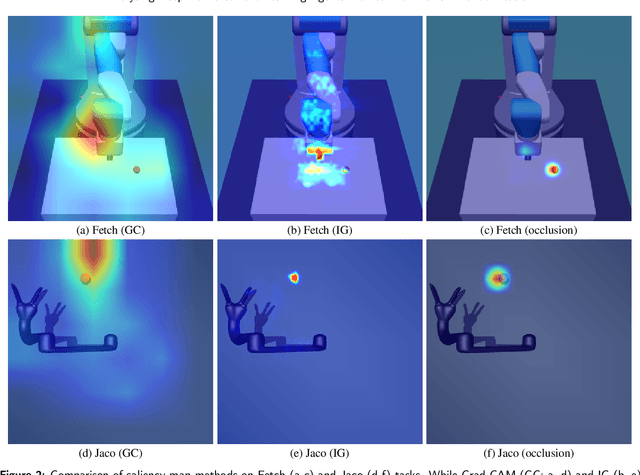
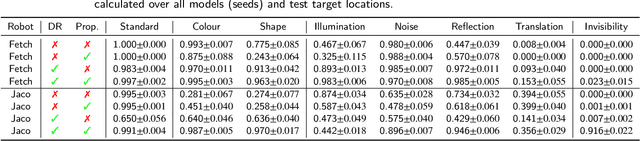
Deep reinforcement learning has the potential to train robots to perform complex tasks in the real world without requiring accurate models of the robot or its environment. A practical approach is to train agents in simulation, and then transfer them to the real world. One of the most popular methods for achieving this is to use domain randomisation, which involves randomly perturbing various aspects of a simulated environment in order to make trained agents robust to the reality gap between the simulator and the real world. However, less work has gone into understanding such agents-which are deployed in the real world-beyond task performance. In this work we examine such agents, through qualitative and quantitative comparisons between agents trained with and without visual domain randomisation, in order to provide a better understanding of how they function. In this work, we train agents for Fetch and Jaco robots on a visuomotor control task, and evaluate how well they generalise using different unit tests. We tie this with interpretability techniques, providing both quantitative and qualitative data. Finally, we investigate the internals of the trained agents by examining their weights and activations. Our results show that the primary outcome of domain randomisation is more redundant, entangled representations, accompanied with significant statistical/structural changes in the weights; moreover, the types of changes are heavily influenced by the task setup and presence of additional proprioceptive inputs. Furthermore, even with an improved saliency method introduced in this work, we show that qualitative studies may not always correspond with quantitative measures, necessitating the use of a wide suite of inspection tools in order to provide sufficient insights into the behaviour of trained agents.
Sample-Efficient Reinforcement Learning with Maximum Entropy Mellowmax Episodic Control
Nov 21, 2019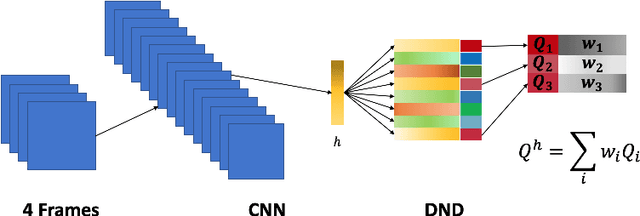
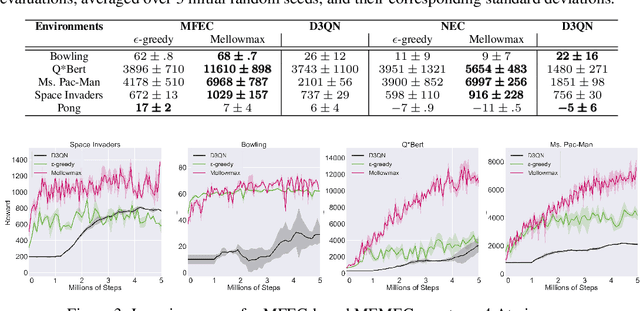
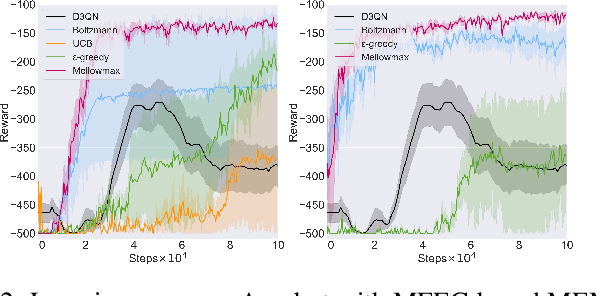
Deep networks have enabled reinforcement learning to scale to more complex and challenging domains, but these methods typically require large quantities of training data. An alternative is to use sample-efficient episodic control methods: neuro-inspired algorithms which use non-/semi-parametric models that predict values based on storing and retrieving previously experienced transitions. One way to further improve the sample efficiency of these approaches is to use more principled exploration strategies. In this work, we therefore propose maximum entropy mellowmax episodic control (MEMEC), which samples actions according to a Boltzmann policy with a state-dependent temperature. We demonstrate that MEMEC outperforms other uncertainty- and softmax-based exploration methods on classic reinforcement learning environments and Atari games, achieving both more rapid learning and higher final rewards.
Memory-Efficient Episodic Control Reinforcement Learning with Dynamic Online k-means
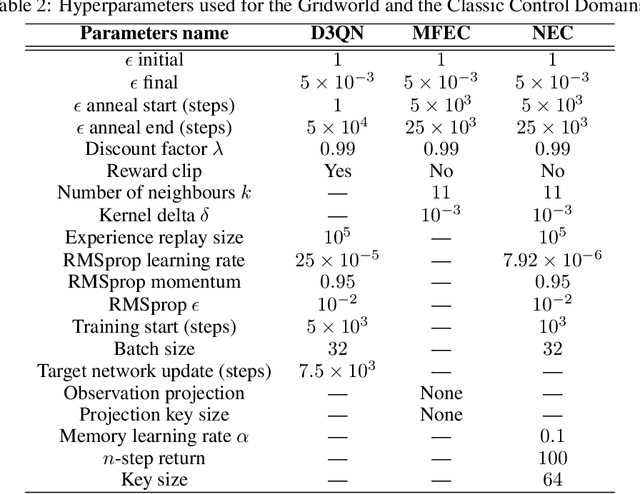
Nov 21, 2019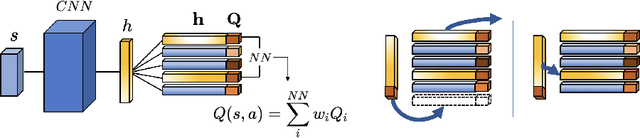
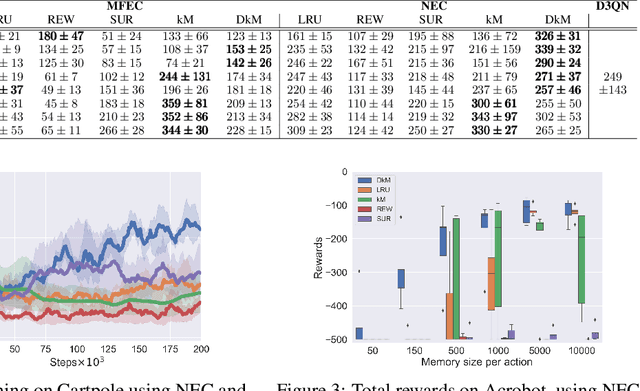


Recently, neuro-inspired episodic control (EC) methods have been developed to overcome the data-inefficiency of standard deep reinforcement learning approaches. Using non-/semi-parametric models to estimate the value function, they learn rapidly, retrieving cached values from similar past states. In realistic scenarios, with limited resources and noisy data, maintaining meaningful representations in memory is essential to speed up the learning and avoid catastrophic forgetting. Unfortunately, EC methods have a large space and time complexity. We investigate different solutions to these problems based on prioritising and ranking stored states, as well as online clustering techniques. We also propose a new dynamic online k-means algorithm that is both computationally-efficient and yields significantly better performance at smaller memory sizes; we validate this approach on classic reinforcement learning environments and Atari games.
AlphaStar: An Evolutionary Computation Perspective
Feb 08, 2019In January 2019, DeepMind revealed AlphaStar to the world-the first artificial intelligence (AI) system to beat a professional player at the game of StarCraft II-representing a milestone in the progress of AI. AlphaStar draws on many areas of AI research, including deep learning, reinforcement learning, game theory, and evolutionary computation (EC). In this paper we analyze AlphaStar primarily through the lens of EC, presenting a new look at the system and relating it to many concepts in the field. We highlight some of its most interesting aspects-the use of Lamarckian evolution, competitive co-evolution, and quality diversity. In doing so, we hope to provide a bridge between the wider EC community and one of the most significant AI systems developed in recent times.
Adaptive Neural Trees
Oct 07, 2018
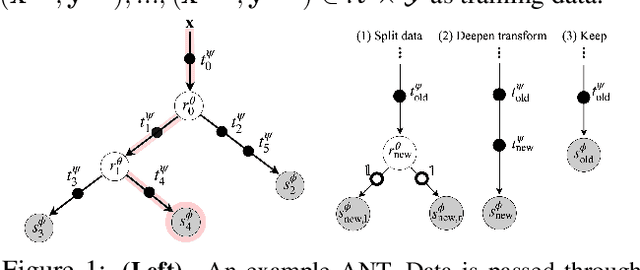

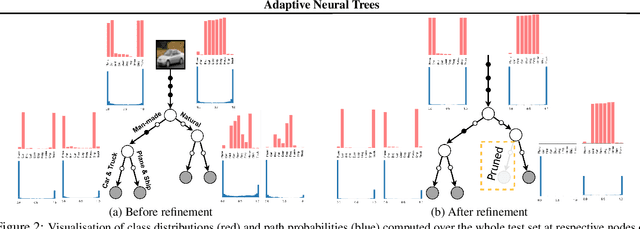
Deep neural networks and decision trees operate on largely separate paradigms; typically, the former performs representation learning with pre-specified architectures, while the latter is characterised by learning hierarchies over pre-specified features with data-driven architectures. We unite the two via adaptive neural trees (ANTs), a model that incorporates representation learning into edges, routing functions and leaf nodes of a decision tree, along with a backpropagation-based training algorithm that adaptively grows the architecture from primitive modules (e.g., convolutional layers). ANTs allow increased interpretability via hierarchical clustering, e.g., learning meaningful class associations, such as separating natural vs. man-made objects. We demonstrate this whilst achieving over 99% and 90% accuracy on the MNIST and CIFAR-10 datasets. Furthermore, ANT optimisation naturally adapts the architecture to the size and complexity of the training data.
Variational Inference for Data-Efficient Model Learning in POMDPs
May 23, 2018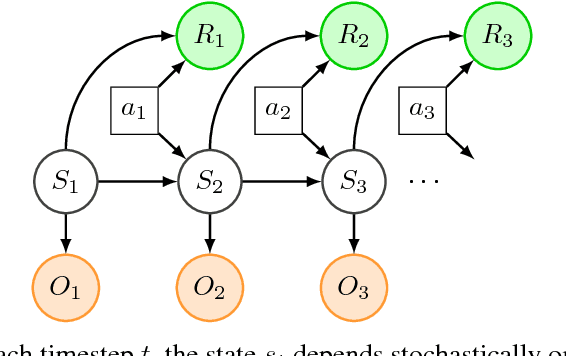
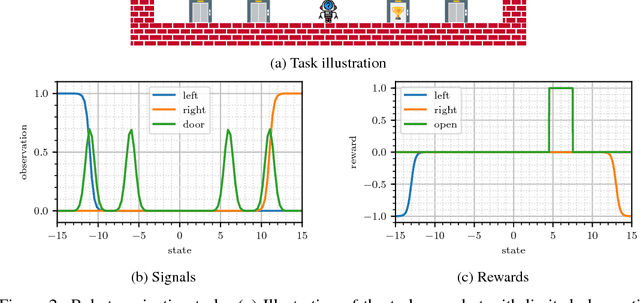
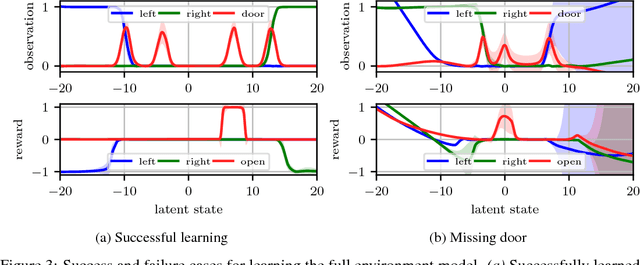
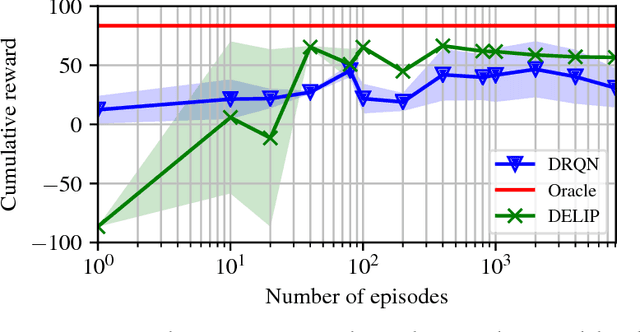
Partially observable Markov decision processes (POMDPs) are a powerful abstraction for tasks that require decision making under uncertainty, and capture a wide range of real world tasks. Today, effective planning approaches exist that generate effective strategies given black-box models of a POMDP task. Yet, an open question is how to acquire accurate models for complex domains. In this paper we propose DELIP, an approach to model learning for POMDPs that utilizes amortized structured variational inference. We empirically show that our model leads to effective control strategies when coupled with state-of-the-art planners. Intuitively, model-based approaches should be particularly beneficial in environments with changing reward structures, or where rewards are initially unknown. Our experiments confirm that DELIP is particularly effective in this setting.
Generative Adversarial Networks: An Overview
Oct 19, 2017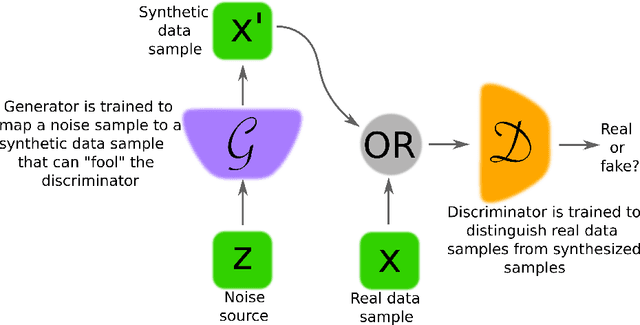
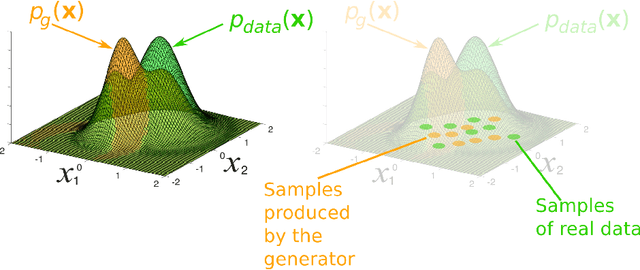
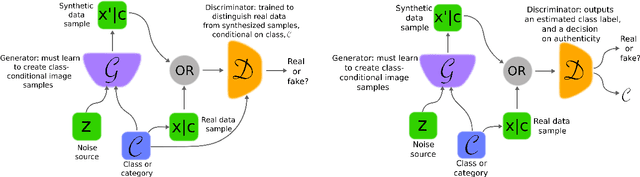
Generative adversarial networks (GANs) provide a way to learn deep representations without extensively annotated training data. They achieve this through deriving backpropagation signals through a competitive process involving a pair of networks. The representations that can be learned by GANs may be used in a variety of applications, including image synthesis, semantic image editing, style transfer, image super-resolution and classification. The aim of this review paper is to provide an overview of GANs for the signal processing community, drawing on familiar analogies and concepts where possible. In addition to identifying different methods for training and constructing GANs, we also point to remaining challenges in their theory and application.
On denoising autoencoders trained to minimise binary cross-entropy
Oct 09, 2017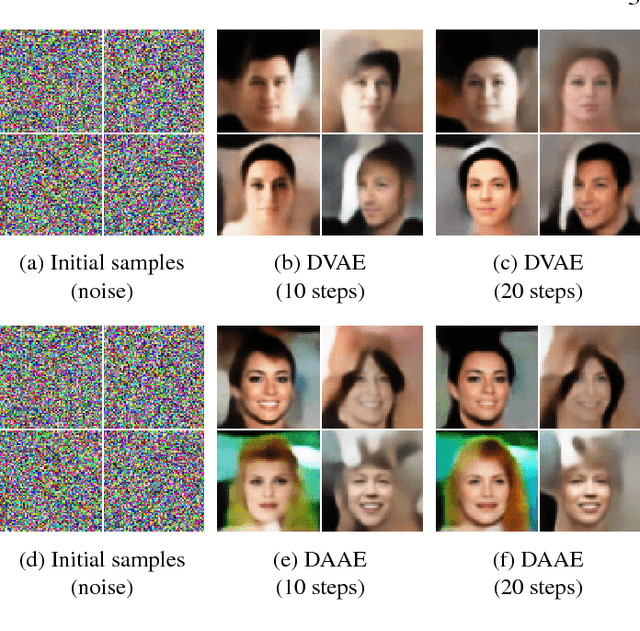


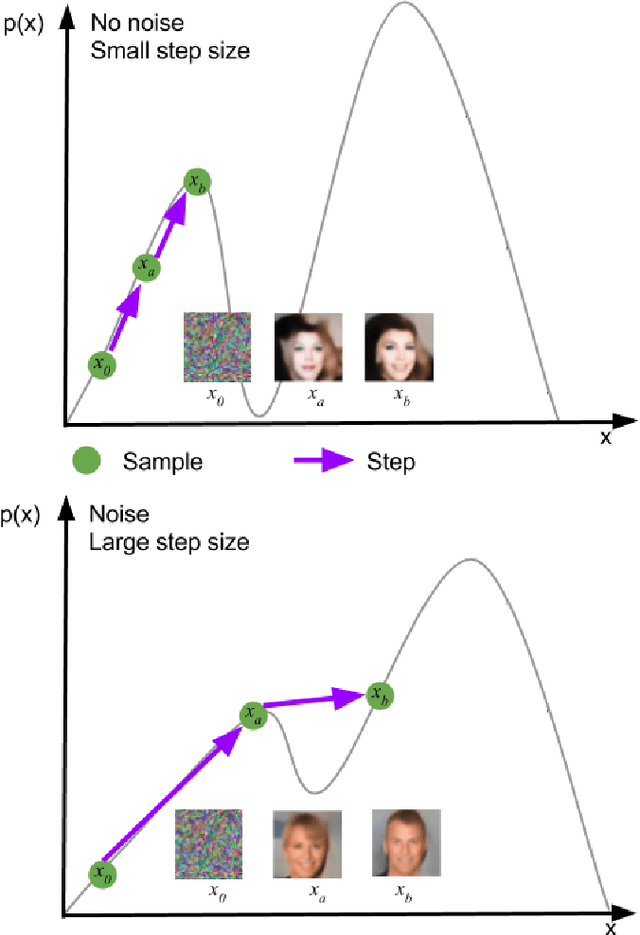
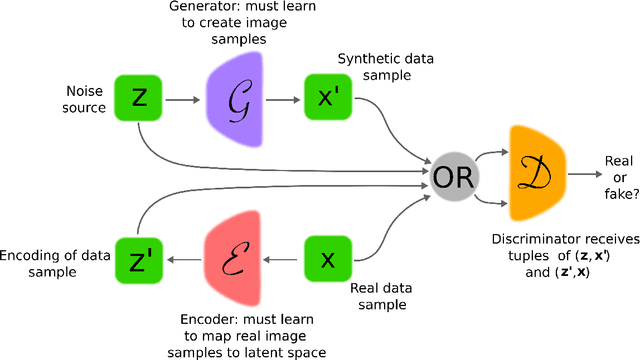
Denoising autoencoders (DAEs) are powerful deep learning models used for feature extraction, data generation and network pre-training. DAEs consist of an encoder and decoder which may be trained simultaneously to minimise a loss (function) between an input and the reconstruction of a corrupted version of the input. There are two common loss functions used for training autoencoders, these include the mean-squared error (MSE) and the binary cross-entropy (BCE). When training autoencoders on image data a natural choice of loss function is BCE, since pixel values may be normalised to take values in [0,1] and the decoder model may be designed to generate samples that take values in (0,1). We show theoretically that DAEs trained to minimise BCE may be used to take gradient steps in the data space towards regions of high probability under the data-generating distribution. Previously this had only been shown for DAEs trained using MSE. As a consequence of the theory, iterative application of a trained DAE moves a data sample from regions of low probability to regions of higher probability under the data-generating distribution. Firstly, we validate the theory by showing that novel data samples, consistent with the training data, may be synthesised when the initial data samples are random noise. Secondly, we motivate the theory by showing that initial data samples synthesised via other methods may be improved via iterative application of a trained DAE to those initial samples.
A Brief Survey of Deep Reinforcement Learning
Sep 28, 2017
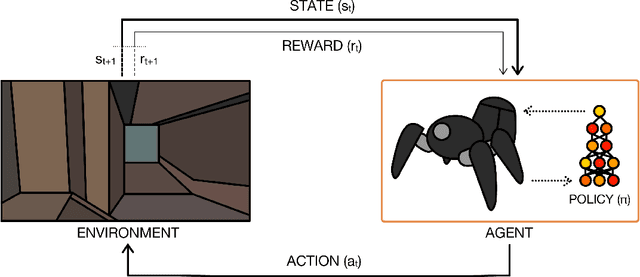
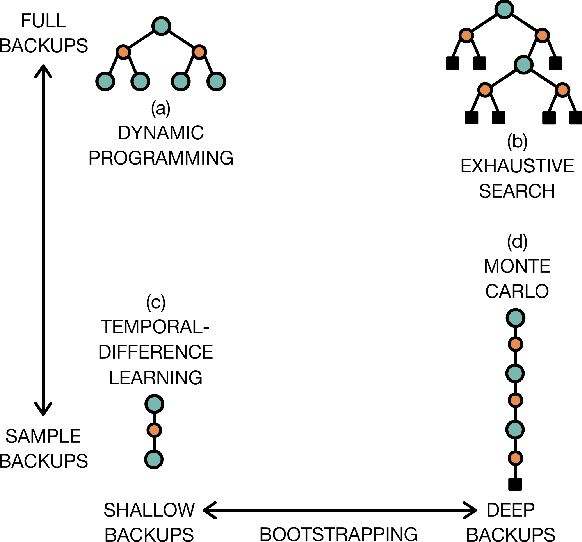
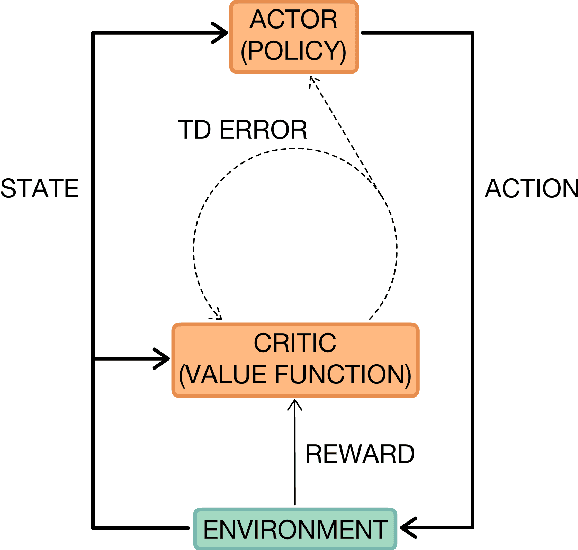
Deep reinforcement learning is poised to revolutionise the field of AI and represents a step towards building autonomous systems with a higher level understanding of the visual world. Currently, deep learning is enabling reinforcement learning to scale to problems that were previously intractable, such as learning to play video games directly from pixels. Deep reinforcement learning algorithms are also applied to robotics, allowing control policies for robots to be learned directly from camera inputs in the real world. In this survey, we begin with an introduction to the general field of reinforcement learning, then progress to the main streams of value-based and policy-based methods. Our survey will cover central algorithms in deep reinforcement learning, including the deep $Q$-network, trust region policy optimisation, and asynchronous advantage actor-critic. In parallel, we highlight the unique advantages of deep neural networks, focusing on visual understanding via reinforcement learning. To conclude, we describe several current areas of research within the field.
Classifying Options for Deep Reinforcement Learning
Jun 19, 2017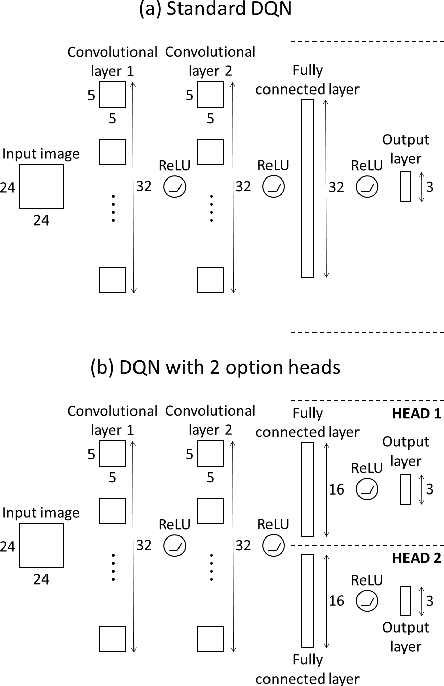

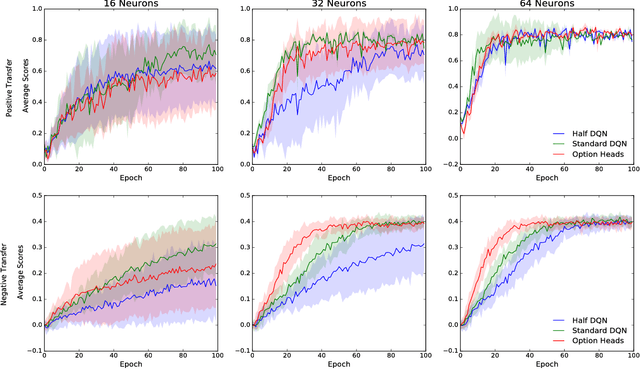
In this paper we combine one method for hierarchical reinforcement learning - the options framework - with deep Q-networks (DQNs) through the use of different "option heads" on the policy network, and a supervisory network for choosing between the different options. We utilise our setup to investigate the effects of architectural constraints in subtasks with positive and negative transfer, across a range of network capacities. We empirically show that our augmented DQN has lower sample complexity when simultaneously learning subtasks with negative transfer, without degrading performance when learning subtasks with positive transfer.