 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARBOR: Automated Harness Optimization
Apr 22, 2026Long-horizon language-model agents are dominated, in lines of code and in operational complexity, not by their underlying model but by the harness that wraps it: context compaction, tool caching, semantic memory, trajectory reuse, speculative tool prediction, and the glue that binds the model to a sandboxed execution environment. We argue that harness design is a first-class machine-learning problem and that automated configuration search dominates manual stacking once the flag space exceeds a handful of bits. We defend this claim in two steps. First, we formalize automated harness optimization as constrained noisy Bayesian optimization over a mixed-variable, cost-heterogeneous configuration space with cold-start-corrected rewards and a posterior chance-constrained safety check, and give a reference solver, HARBOR (Harness Axis-aligned Regularized Bayesian Optimization Routine), built from a block-additive SAAS surrogate, multi-fidelity cost-aware acquisition, and TuRBO trust regions. Second, we instantiate the problem in a flag-gated harness over a production coding agent and report a controlled four-round manual-tuning case study against a fixed task suite and an end-to-end HARBOR run. The formulation itself is task-class agnostic: the configuration space, reward correction, acquisition, and safety check apply to any agent harness with a bounded flag space and a reproducible task suite.
From Translation to Superset: Benchmark-Driven Evolution of a Production AI Agent from Rust to Python
Apr 13, 2026Cross-language migration of large software systems is a persistent engineering challenge, particularly when the source codebase evolves rapidly. We present a methodology for LLM-assisted continuous code translation in which a large language model translates a production Rust codebase (648K LOC, 65 crates) into Python (41K LOC, 28 modules), with public agent benchmarks as the objective function driving iterative refinement. Our subject system is Codex CLI, a production AI coding agent. We demonstrate that: (1) the Python port resolves 59/80 SWE-bench Verified tasks (73.8%) versus Rust's 56/80 (70.0%), and achieves 42.5% on Terminal-Bench versus Rust's 47.5%, confirming near-parity on real-world agentic tasks; (2) benchmark-driven debugging, revealing API protocol mismatches, environment pollution, a silent WebSocket failure mode, and an API 400 crash, is more effective than static testing alone; (3) the architecture supports continuous upstream synchronisation via an LLM-assisted diff-translate-test loop; and (4) the Python port has evolved into a capability superset with 30 feature-flagged extensions (multi-agent orchestration, semantic memory, guardian safety, cost tracking) absent from Rust, while preserving strict parity mode for comparison. Our evaluation shows that for LLM-based agents where API latency dominates, Python's expressiveness yields a 15.9x code reduction with negligible performance cost, while the benchmark-as-objective-function methodology provides a principled framework for growing a cross-language port from parity into an extended platform.
Learning to Communicate using Contrastive Learning
Jul 03, 2023Communication is a powerful tool for coordination in multi-agent RL. But inducing an effective, common language is a difficult challenge, particularly in the decentralized setting. In this work, we introduce an alternative perspective where communicative messages sent between agents are considered as different incomplete views of the environment state. By examining the relationship between messages sent and received, we propose to learn to communicate using contrastive learning to maximize the mutual information between messages of a given trajectory. In communication-essential environments, our method outperforms previous work in both performance and learning speed. Using qualitative metrics and representation probing, we show that our method induces more symmetric communication and captures global state information from the environment. Overall, we show the power of contrastive learning and the importance of leveraging messages as encodings for effective communication.
Learning to Infer Belief Embedded Communication
Mar 15, 2022
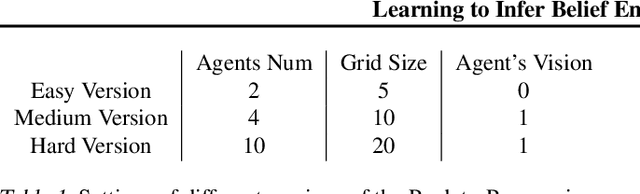
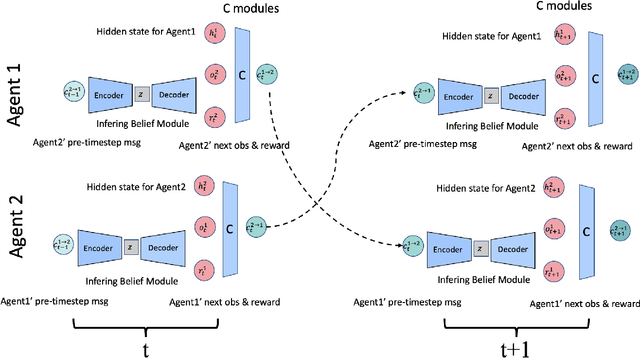
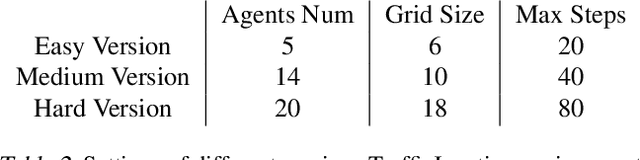
In multi-agent collaboration problems with communication, an agent's ability to encode their intention and interpret other agents' strategies is critical for planning their future actions. This paper introduces a novel algorithm called Intention Embedded Communication (IEC) to mimic an agent's language learning ability. IEC contains a perception module for decoding other agents' intentions in response to their past actions. It also includes a language generation module for learning implicit grammar during communication with two or more agents. Such grammar, by construction, should be compact for efficient communication. Both modules undergo conjoint evolution - similar to an infant's babbling that enables it to learn a language of choice by trial and error. We utilised three multi-agent environments, namely predator/prey, traffic junction and level-based foraging and illustrate that such a co-evolution enables us to learn much quicker (50%) than state-of-the-art algorithms like MADDPG. Ablation studies further show that disabling the inferring belief module, communication module, and the hidden states reduces the model performance by 38%, 60% and 30%, respectively. Hence, we suggest that modelling other agents' behaviour accelerates another agent to learn grammar and develop a language to communicate efficiently. We evaluate our method on a set of cooperative scenarios and show its superior performance to other multi-agent baselines. We also demonstrate that it is essential for agents to reason about others' states and learn this ability by continuous communication.
Switch Trajectory Transformer with Distributional Value Approximation for Multi-Task Reinforcement Learning
Mar 14, 2022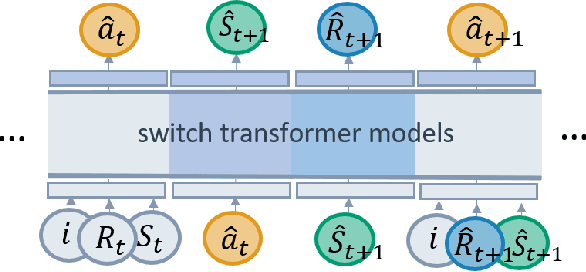
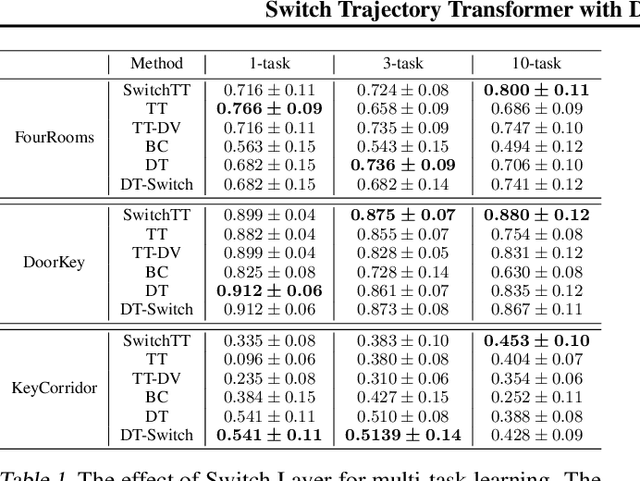
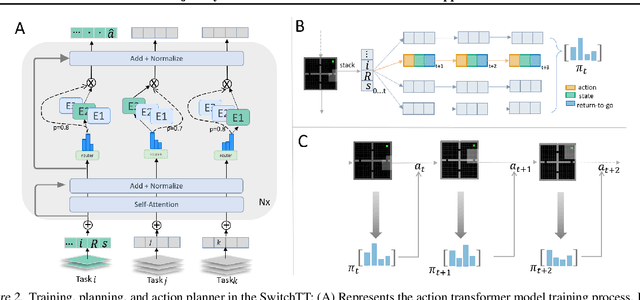
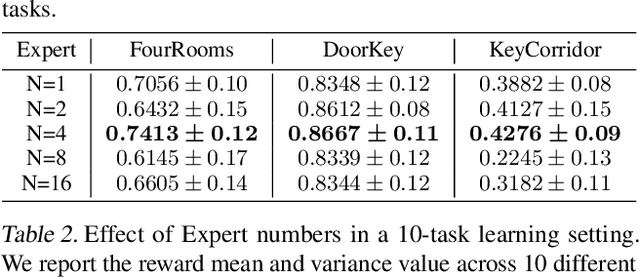
We propose SwitchTT, a multi-task extension to Trajectory Transformer but enhanced with two striking features: (i) exploiting a sparsely activated model to reduce computation cost in multi-task offline model learning and (ii) adopting a distributional trajectory value estimator that improves policy performance, especially in sparse reward settings. These two enhancements make SwitchTT suitable for solving multi-task offline reinforcement learning problems, where model capacity is critical for absorbing the vast quantities of knowledge available in the multi-task dataset. More specifically, SwitchTT exploits switch transformer model architecture for multi-task policy learning, allowing us to improve model capacity without proportional computation cost. Also, SwitchTT approximates the distribution rather than the expectation of trajectory value, mitigating the effects of the Monte-Carlo Value estimator suffering from poor sample complexity, especially in the sparse-reward setting. We evaluate our method using the suite of ten sparse-reward tasks from the gym-mini-grid environment.We show an improvement of 10% over Trajectory Transformer across 10-task learning and obtain up to 90% increase in offline model training speed. Our results also demonstrate the advantage of the switch transformer model for absorbing expert knowledge and the importance of value distribution in evaluating the trajectory.
The Multi-Agent Pickup and Delivery Problem: MAPF, MARL and Its Warehouse Applications
Mar 14, 2022
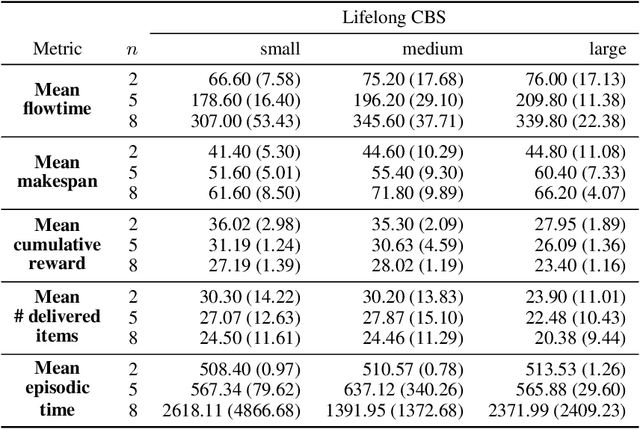
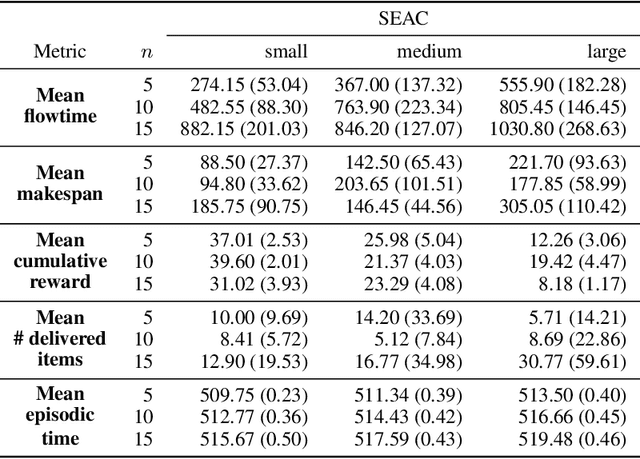
We study two state-of-the-art solutions to the multi-agent pickup and delivery (MAPD) problem based on different principles -- multi-agent path-finding (MAPF) and multi-agent reinforcement learning (MARL). Specifically, a recent MAPF algorithm called conflict-based search (CBS) and a current MARL algorithm called shared experience actor-critic (SEAC) are studied. While the performance of these algorithms is measured using quite different metrics in their separate lines of work, we aim to benchmark these two methods comprehensively in a simulated warehouse automation environment.
Reinforcement Learning for Location-Aware Scheduling
Mar 07, 2022
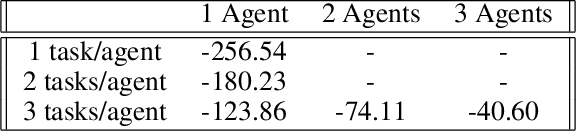
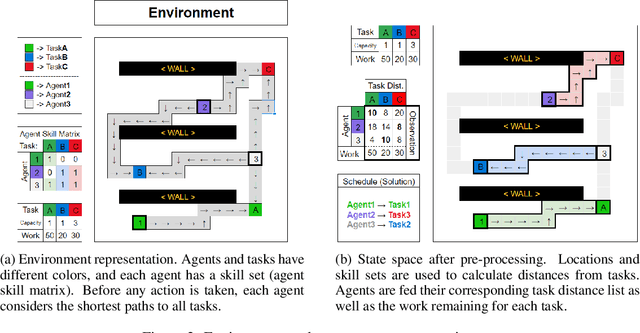
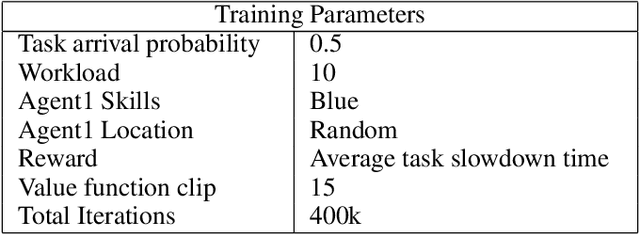
Recent techniques in dynamical scheduling and resource management have found applications in warehouse environments due to their ability to organize and prioritize tasks in a higher temporal resolution. The rise of deep reinforcement learning, as a learning paradigm, has enabled decentralized agent populations to discover complex coordination strategies. However, training multiple agents simultaneously introduce many obstacles in training as observation and action spaces become exponentially large. In our work, we experimentally quantify how various aspects of the warehouse environment (e.g., floor plan complexity, information about agents' live location, level of task parallelizability) affect performance and execution priority. To achieve efficiency, we propose a compact representation of the state and action space for location-aware multi-agent systems, wherein each agent has knowledge of only self and task coordinates, hence only partial observability of the underlying Markov Decision Process. Finally, we show how agents trained in certain environments maintain performance in completely unseen settings and also correlate performance degradation with floor plan geometry.
Learning to Ground Decentralized Multi-Agent Communication with Contrastive Learning
Mar 07, 2022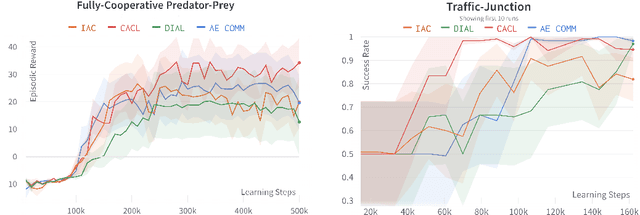
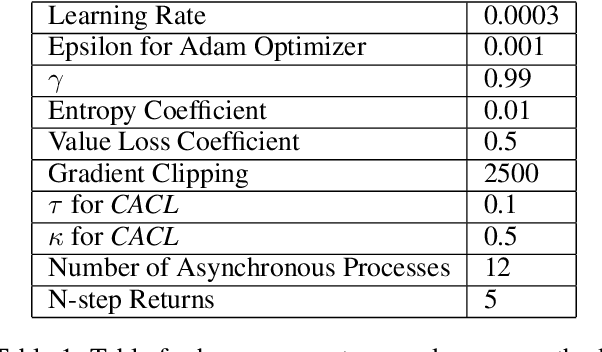
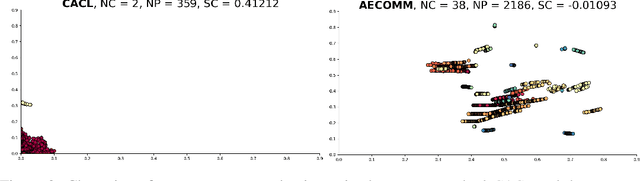
For communication to happen successfully, a common language is required between agents to understand information communicated by one another. Inducing the emergence of a common language has been a difficult challenge to multi-agent learning systems. In this work, we introduce an alternative perspective to the communicative messages sent between agents, considering them as different incomplete views of the environment state. Based on this perspective, we propose a simple approach to induce the emergence of a common language by maximizing the mutual information between messages of a given trajectory in a self-supervised manner. By evaluating our method in communication-essential environments, we empirically show how our method leads to better learning performance and speed, and learns a more consistent common language than existing methods, without introducing additional learning parameters.
Hierarchically Structured Scheduling and Execution of Tasks in a Multi-Agent Environment
Mar 06, 2022
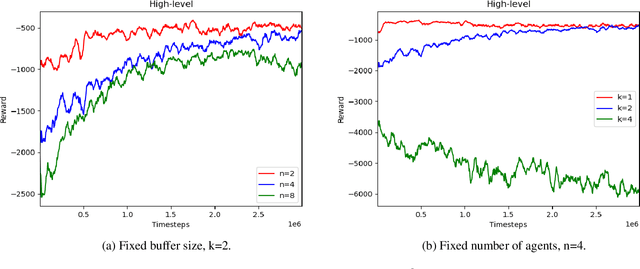
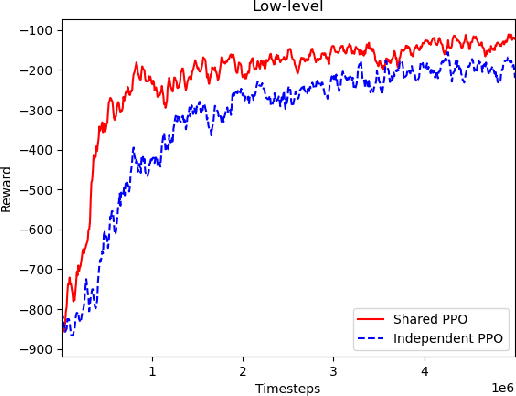
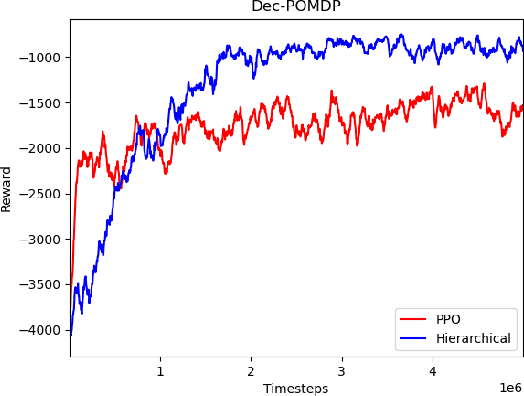
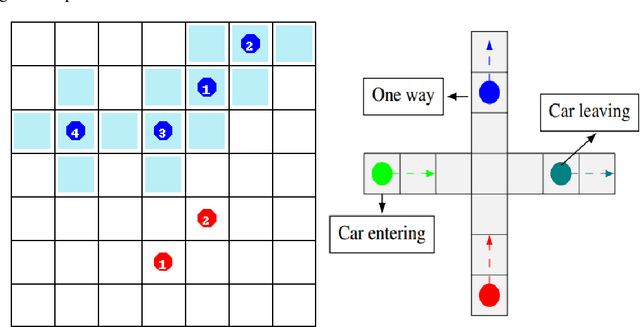
In a warehouse environment, tasks appear dynamically. Consequently, a task management system that matches them with the workforce too early (e.g., weeks in advance) is necessarily sub-optimal. Also, the rapidly increasing size of the action space of such a system consists of a significant problem for traditional schedulers. Reinforcement learning, however, is suited to deal with issues requiring making sequential decisions towards a long-term, often remote, goal. In this work, we set ourselves on a problem that presents itself with a hierarchical structure: the task-scheduling, by a centralised agent, in a dynamic warehouse multi-agent environment and the execution of one such schedule, by decentralised agents with only partial observability thereof. We propose to use deep reinforcement learning to solve both the high-level scheduling problem and the low-level multi-agent problem of schedule execution. Finally, we also conceive the case where centralisation is impossible at test time and workers must learn how to cooperate in executing the tasks in an environment with no schedule and only partial observability.
On the Dark Side of Calibration for Modern Neural Networks
Jun 17, 2021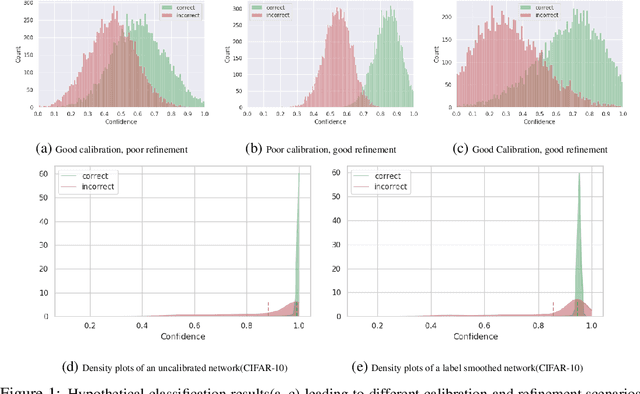
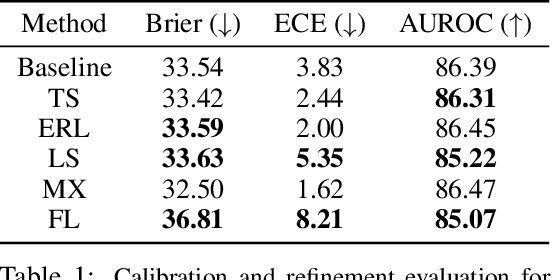
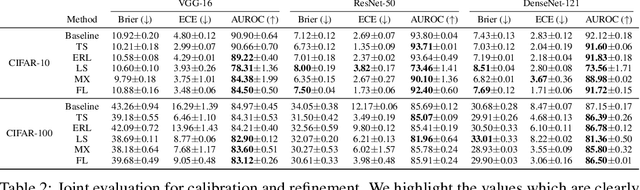
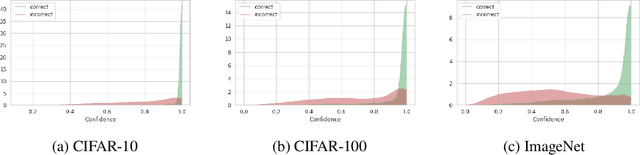
Modern neural networks are highly uncalibrated. It poses a significant challenge for safety-critical systems to utilise deep neural networks (DNNs), reliably. Many recently proposed approaches have demonstrated substantial progress in improving DNN calibration. However, they hardly touch upon refinement, which historically has been an essential aspect of calibration. Refinement indicates separability of a network's correct and incorrect predictions. This paper presents a theoretically and empirically supported exposition for reviewing a model's calibration and refinement. Firstly, we show the breakdown of expected calibration error (ECE), into predicted confidence and refinement. Connecting with this result, we highlight that regularisation based calibration only focuses on naively reducing a model's confidence. This logically has a severe downside to a model's refinement. We support our claims through rigorous empirical evaluations of many state of the art calibration approaches on standard datasets. We find that many calibration approaches with the likes of label smoothing, mixup etc. lower the utility of a DNN by degrading its refinement. Even under natural data shift, this calibration-refinement trade-off holds for the majority of calibration methods. These findings call for an urgent retrospective into some popular pathways taken for modern DNN calibration.