 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Design Framework for operationalizing Trustworthy Artificial Intelligence in Healthcare: Requirements, Tradeoffs and Challenges for its Clinical Adoption
Apr 27, 2025



Artificial Intelligence (AI) holds great promise for transforming healthcare, particularly in disease diagnosis, prognosis, and patient care. The increasing availability of digital medical data, such as images, omics, biosignals, and electronic health records, combined with advances in computing, has enabled AI models to approach expert-level performance. However, widespread clinical adoption remains limited, primarily due to challenges beyond technical performance, including ethical concerns, regulatory barriers, and lack of trust. To address these issues, AI systems must align with the principles of Trustworthy AI (TAI), which emphasize human agency and oversight, algorithmic robustness, privacy and data governance, transparency, bias and discrimination avoidance, and accountability. Yet, the complexity of healthcare processes (e.g., screening, diagnosis, prognosis, and treatment) and the diversity of stakeholders (clinicians, patients, providers, regulators) complicate the integration of TAI principles. To bridge the gap between TAI theory and practical implementation, this paper proposes a design framework to support developers in embedding TAI principles into medical AI systems. Thus, for each stakeholder identified across various healthcare processes, we propose a disease-agnostic collection of requirements that medical AI systems should incorporate to adhere to the principles of TAI. Additionally, we examine the challenges and tradeoffs that may arise when applying these principles in practice. To ground the discussion, we focus on cardiovascular diseases, a field marked by both high prevalence and active AI innovation, and demonstrate how TAI principles have been applied and where key obstacles persist.
Evaluation of machine learning algorithms for Health and Wellness applications: a tutorial
Aug 31, 2020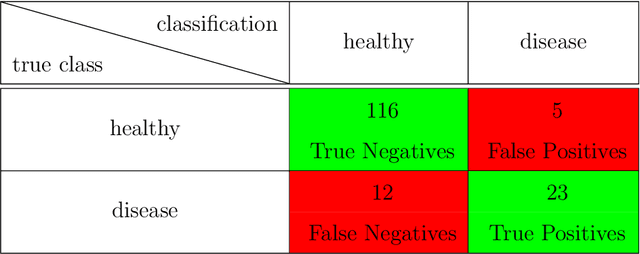
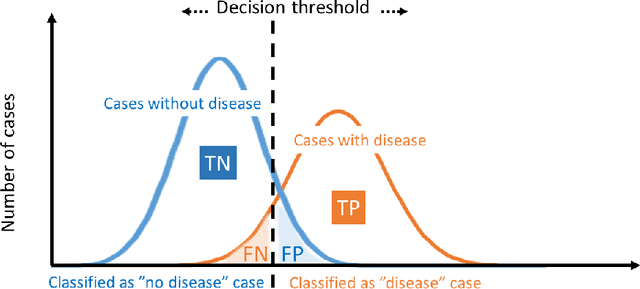
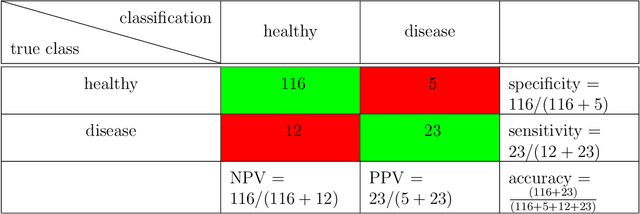
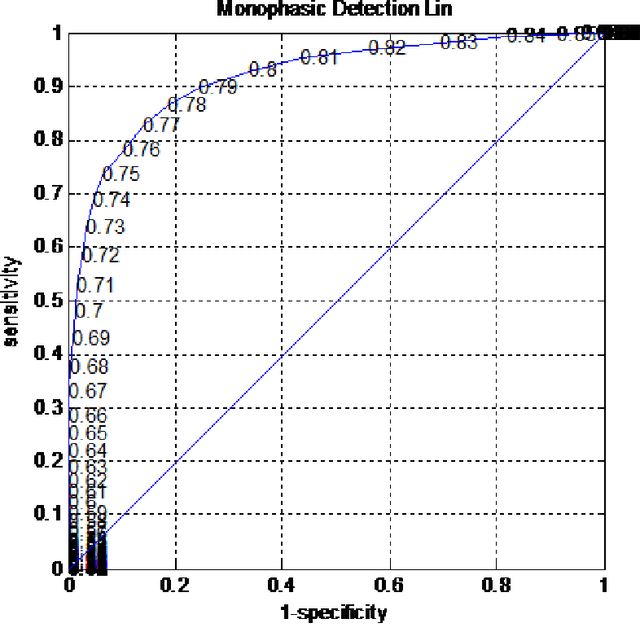
Research on decision support applications in healthcare, such as those related to diagnosis, prediction, treatment planning, etc., have seen enormously increased interest recently. This development is thanks to the increase in data availability as well as advances in artificial intelligence and machine learning research. Highly promising research examples are published daily. However, at the same time, there are some unrealistic expectations with regards to the requirements for reliable development and objective validation that is needed in healthcare settings. These expectations may lead to unmet schedules and disappointments (or non-uptake) at the end-user side. It is the aim of this tutorial to provide practical guidance on how to assess performance reliably and efficiently and avoid common traps. Instead of giving a list of do's and don't s, this tutorial tries to build a better understanding behind these do's and don't s and presents both the most relevant performance evaluation criteria as well as how to compute them. Along the way, we will indicate common mistakes and provide references discussing various topics more in-depth.
HARK Side of Deep Learning -- From Grad Student Descent to Automated Machine Learning
Apr 16, 2019Recent advancements in machine learning research, i.e., deep learning, introduced methods that excel conventional algorithms as well as humans in several complex tasks, ranging from detection of objects in images and speech recognition to playing difficult strategic games. However, the current methodology of machine learning research and consequently, implementations of the real-world applications of such algorithms, seems to have a recurring HARKing (Hypothesizing After the Results are Known) issue. In this work, we elaborate on the algorithmic, economic and social reasons and consequences of this phenomenon. We present examples from current common practices of conducting machine learning research (e.g. avoidance of reporting negative results) and failure of generalization ability of the proposed algorithms and datasets in actual real-life usage. Furthermore, a potential future trajectory of machine learning research and development from the perspective of accountable, unbiased, ethical and privacy-aware algorithmic decision making is discussed. We would like to emphasize that with this discussion we neither claim to provide an exhaustive argumentation nor blame any specific institution or individual on the raised issues. This is simply a discussion put forth by us, insiders of the machine learning field, reflecting on us.