 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute Zero-Shot Learning
Feb 23, 2022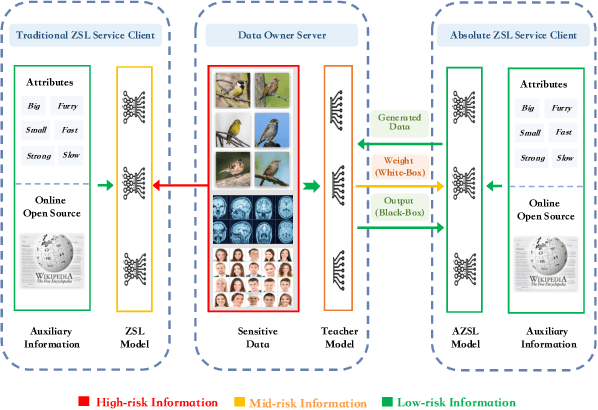
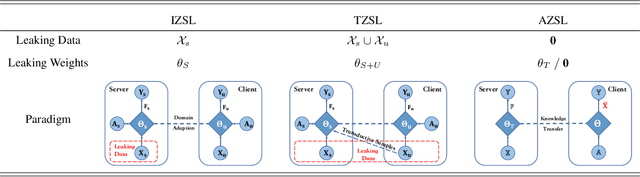
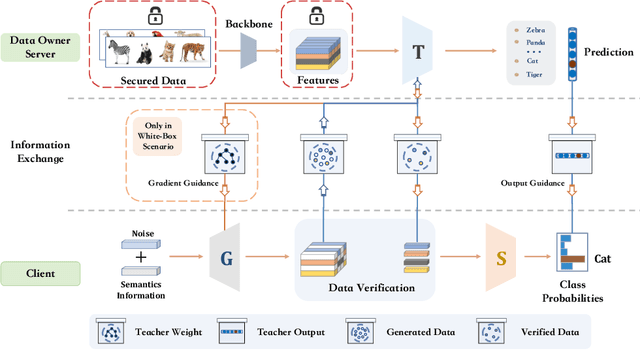
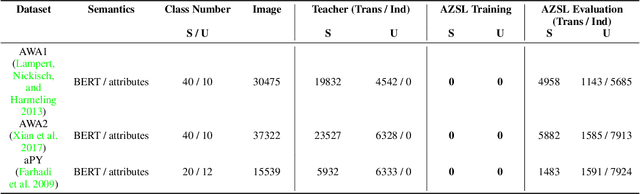
Considering the increasing concerns about data copyright and privacy issues, we present a novel Absolute Zero-Shot Learning (AZSL) paradigm, i.e., training a classifier with zero real data. The key innovation is to involve a teacher model as the data safeguard to guide the AZSL model training without data leaking. The AZSL model consists of a generator and student network, which can achieve date-free knowledge transfer while maintaining the performance of the teacher network. We investigate `black-box' and `white-box' scenarios in AZSL task as different levels of model security. Besides, we also provide discussion of teacher model in both inductive and transductive settings. Despite embarrassingly simple implementations and data-missing disadvantages, our AZSL framework can retain state-of-the-art ZSL and GZSL performance under the `white-box' scenario. Extensive qualitative and quantitative analysis also demonstrates promising results when deploying the model under `black-box' scenario.
GiraffeDet: A Heavy-Neck Paradigm for Object Detection
Feb 09, 2022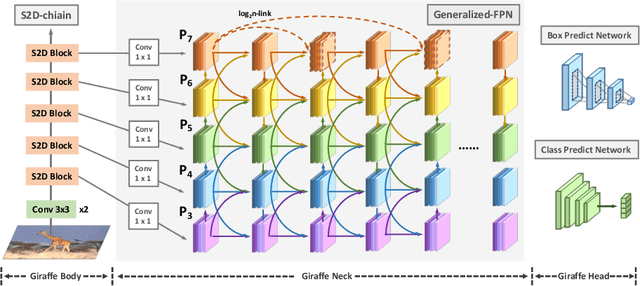
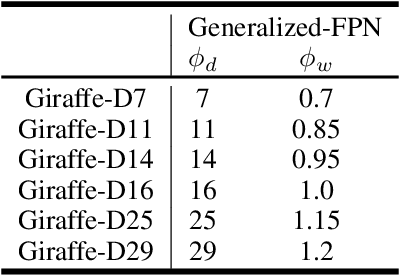
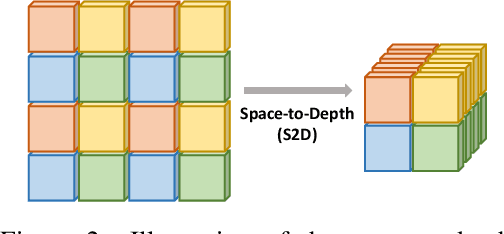
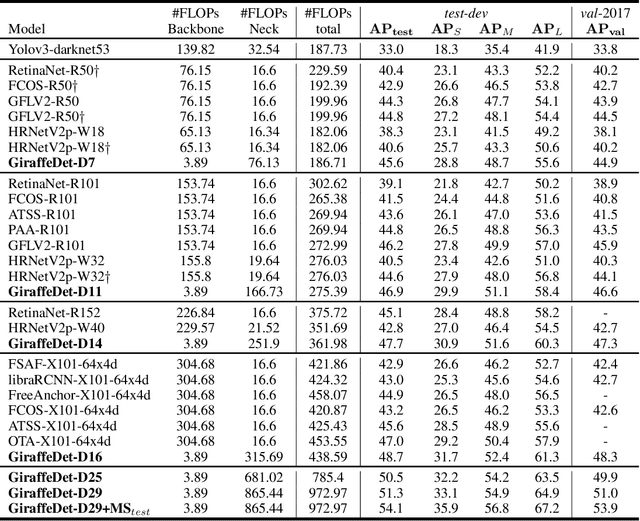
In conventional object detection frameworks, a backbone body inherited from image recognition models extracts deep latent features and then a neck module fuses these latent features to capture information at different scales. As the resolution in object detection is much larger than in image recognition, the computational cost of the backbone often dominates the total inference cost. This heavy-backbone design paradigm is mostly due to the historical legacy when transferring image recognition models to object detection rather than an end-to-end optimized design for object detection. In this work, we show that such paradigm indeed leads to sub-optimal object detection models. To this end, we propose a novel heavy-neck paradigm, GiraffeDet, a giraffe-like network for efficient object detection. The GiraffeDet uses an extremely lightweight backbone and a very deep and large neck module which encourages dense information exchange among different spatial scales as well as different levels of latent semantics simultaneously. This design paradigm allows detectors to process the high-level semantic information and low-level spatial information at the same priority even in the early stage of the network, making it more effective in detection tasks. Numerical evaluations on multiple popular object detection benchmarks show that GiraffeDet consistently outperforms previous SOTA models across a wide spectrum of resource constraints.
AnANet: Modeling Association and Alignment for Cross-modal Correlation Classification
Sep 02, 2021
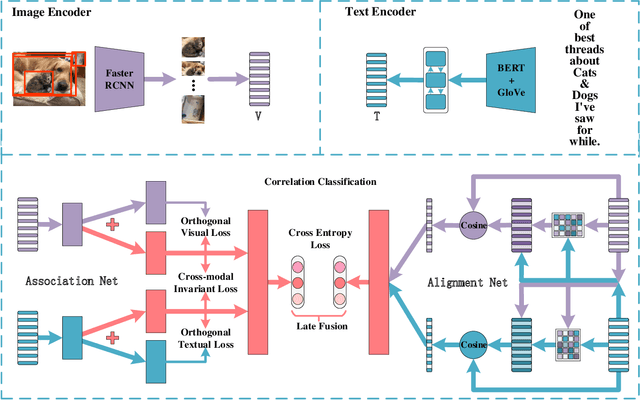

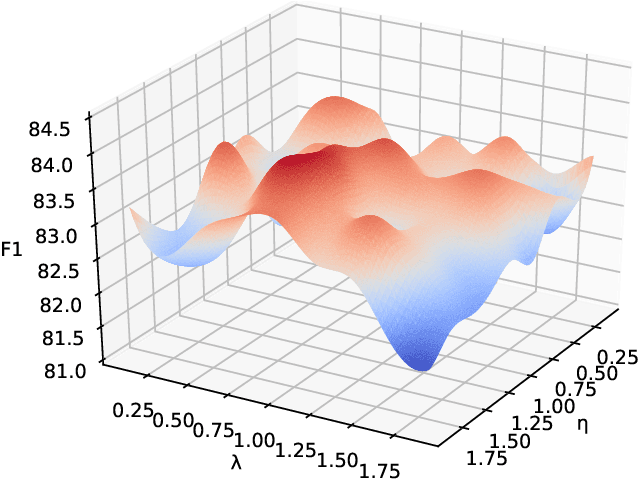
The explosive increase of multimodal data makes a great demand in many cross-modal applications that follow the strict prior related assumption. Thus researchers study the definition of cross-modal correlation category and construct various classification systems and predictive models. However, those systems pay more attention to the fine-grained relevant types of cross-modal correlation, ignoring lots of implicit relevant data which are often divided into irrelevant types. What's worse is that none of previous predictive models manifest the essence of cross-modal correlation according to their definition at the modeling stage. In this paper, we present a comprehensive analysis of the image-text correlation and redefine a new classification system based on implicit association and explicit alignment. To predict the type of image-text correlation, we propose the Association and Alignment Network according to our proposed definition (namely AnANet) which implicitly represents the global discrepancy and commonality between image and text and explicitly captures the cross-modal local relevance. The experimental results on our constructed new image-text correlation dataset show the effectiveness of our model.
Discriminative Latent Semantic Graph for Video Captioning
Aug 10, 2021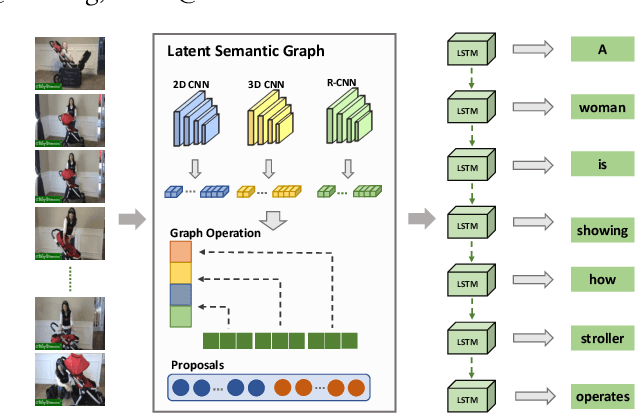
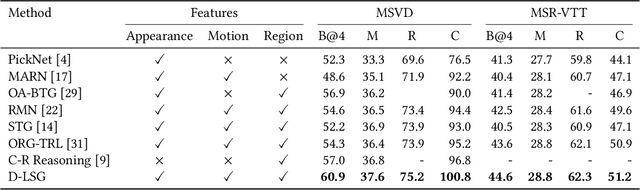
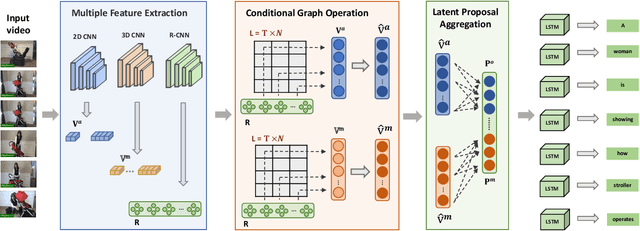
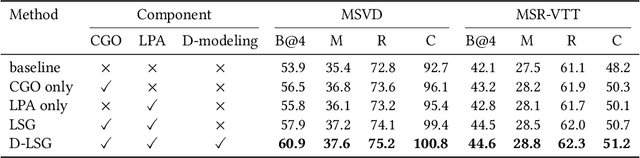
Video captioning aims to automatically generate natural language sentences that can describe the visual contents of a given video. Existing generative models like encoder-decoder frameworks cannot explicitly explore the object-level interactions and frame-level information from complex spatio-temporal data to generate semantic-rich captions. Our main contribution is to identify three key problems in a joint framework for future video summarization tasks. 1) Enhanced Object Proposal: we propose a novel Conditional Graph that can fuse spatio-temporal information into latent object proposal. 2) Visual Knowledge: Latent Proposal Aggregation is proposed to dynamically extract visual words with higher semantic levels. 3) Sentence Validation: A novel Discriminative Language Validator is proposed to verify generated captions so that key semantic concepts can be effectively preserved. Our experiments on two public datasets (MVSD and MSR-VTT) manifest significant improvements over state-of-the-art approaches on all metrics, especially for BLEU-4 and CIDEr. Our code is available at https://github.com/baiyang4/D-LSG-Video-Caption.
Query Twice: Dual Mixture Attention Meta Learning for Video Summarization
Aug 19, 2020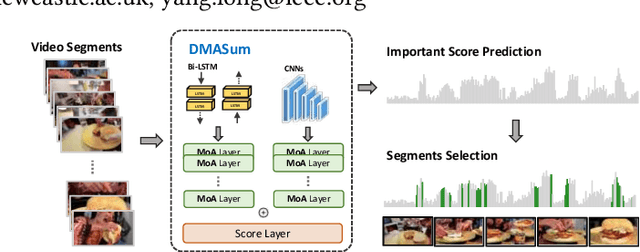
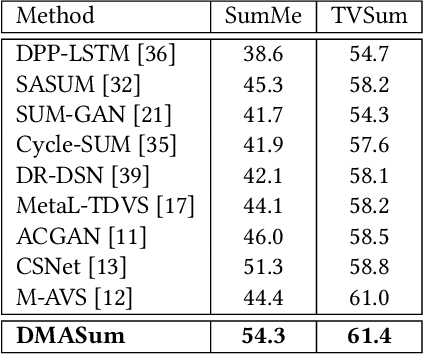
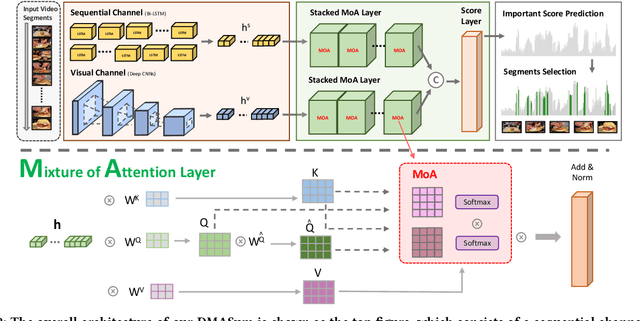
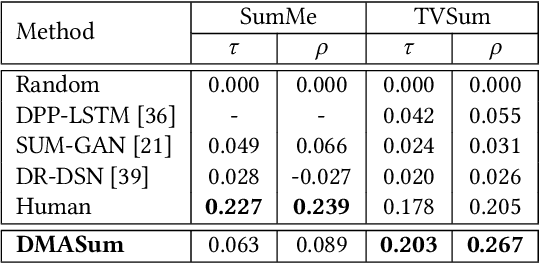
Video summarization aims to select representative frames to retain high-level information, which is usually solved by predicting the segment-wise importance score via a softmax function. However, softmax function suffers in retaining high-rank representations for complex visual or sequential information, which is known as the Softmax Bottleneck problem. In this paper, we propose a novel framework named Dual Mixture Attention (DMASum) model with Meta Learning for video summarization that tackles the softmax bottleneck problem, where the Mixture of Attention layer (MoA) effectively increases the model capacity by employing twice self-query attention that can capture the second-order changes in addition to the initial query-key attention, and a novel Single Frame Meta Learning rule is then introduced to achieve more generalization to small datasets with limited training sources. Furthermore, the DMASum significantly exploits both visual and sequential attention that connects local key-frame and global attention in an accumulative way. We adopt the new evaluation protocol on two public datasets, SumMe, and TVSum. Both qualitative and quantitative experiments manifest significant improvements over the state-of-the-art methods.
Order Matters: Shuffling Sequence Generation for Video Prediction
Jul 20, 2019
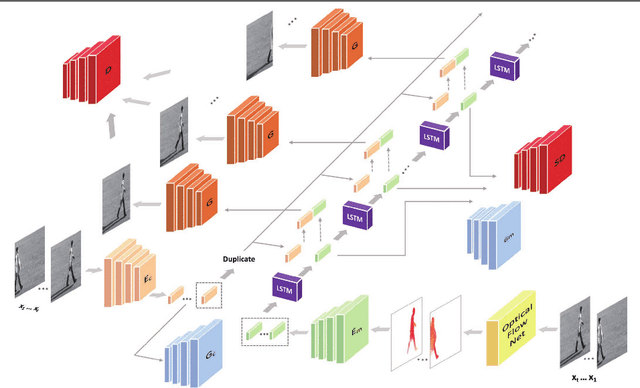
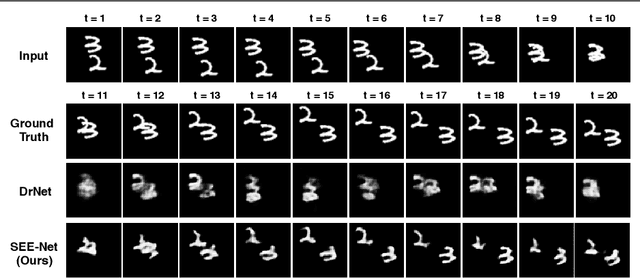

Predicting future frames in natural video sequences is a new challenge that is receiving increasing attention in the computer vision community. However, existing models suffer from severe loss of temporal information when the predicted sequence is long. Compared to previous methods focusing on generating more realistic contents, this paper extensively studies the importance of sequential order information for video generation. A novel Shuffling sEquence gEneration network (SEE-Net) is proposed that can learn to discriminate unnatural sequential orders by shuffling the video frames and comparing them to the real video sequence. Systematic experiments on three datasets with both synthetic and real-world videos manifest the effectiveness of shuffling sequence generation for video prediction in our proposed model and demonstrate state-of-the-art performance by both qualitative and quantitative evaluations. The source code is available at https://github.com/andrewjywang/SEENet.
Segmentation Rectification for Video Cutout via One-Class Structured Learning
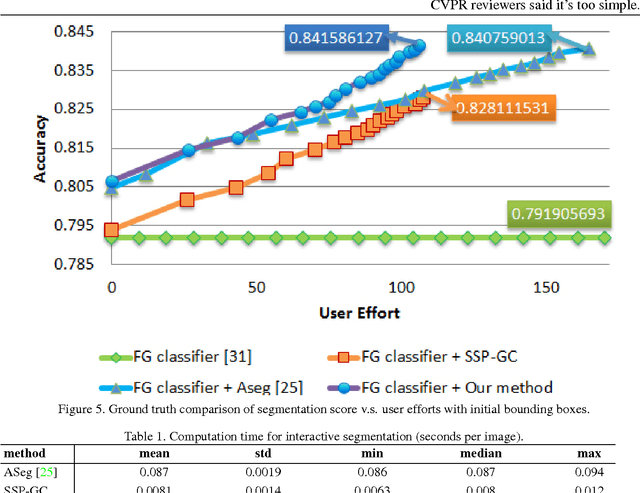
Feb 16, 2016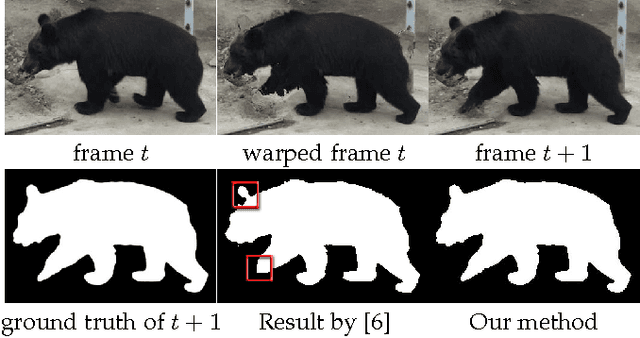

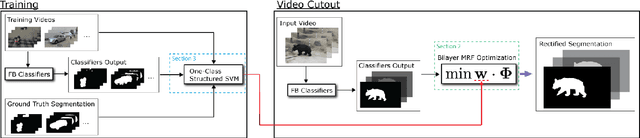

Recent works on interactive video object cutout mainly focus on designing dynamic foreground-background (FB) classifiers for segmentation propagation. However, the research on optimally removing errors from the FB classification is sparse, and the errors often accumulate rapidly, causing significant errors in the propagated frames. In this work, we take the initial steps to addressing this problem, and we call this new task \emph{segmentation rectification}. Our key observation is that the possibly asymmetrically distributed false positive and false negative errors were handled equally in the conventional methods. We, alternatively, propose to optimally remove these two types of errors. To this effect, we propose a novel bilayer Markov Random Field (MRF) model for this new task. We also adopt the well-established structured learning framework to learn the optimal model from data. Additionally, we propose a novel one-class structured SVM (OSSVM) which greatly speeds up the structured learning process. Our method naturally extends to RGB-D videos as well. Comprehensive experiments on both RGB and RGB-D data demonstrate that our simple and effective method significantly outperforms the segmentation propagation methods adopted in the state-of-the-art video cutout systems, and the results also suggest the potential usefulness of our method in image cutout system.
Superpixelizing Binary MRF for Image Labeling Problems
Mar 23, 2015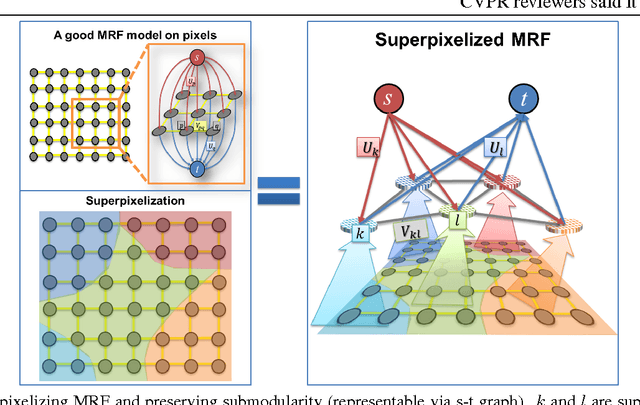
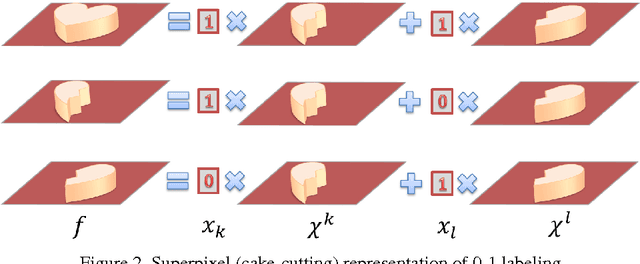
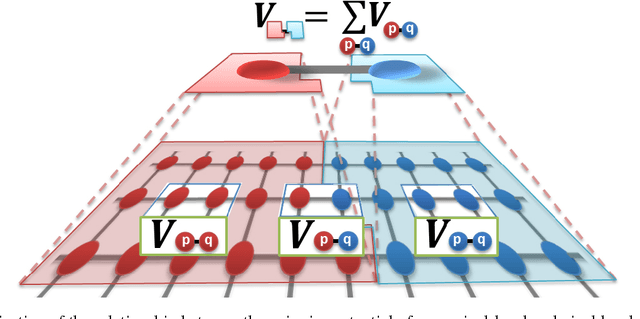
Superpixels have become prevalent in computer vision. They have been used to achieve satisfactory performance at a significantly smaller computational cost for various tasks. People have also combined superpixels with Markov random field (MRF) models. However, it often takes additional effort to formulate MRF on superpixel-level, and to the best of our knowledge there exists no principled approach to obtain this formulation. In this paper, we show how generic pixel-level binary MRF model can be solved in the superpixel space. As the main contribution of this paper, we show that a superpixel-level MRF can be derived from the pixel-level MRF by substituting the superpixel representation of the pixelwise label into the original pixel-level MRF energy. The resultant superpixel-level MRF energy also remains submodular for a submodular pixel-level MRF. The derived formula hence gives us a handy way to formulate MRF energy in superpixel-level. In the experiments, we demonstrate the efficacy of our approach on several computer vision problems.
Rigid and Non-rigid Shape Evolutions for Shape Alignment and Recovery in Images
Dec 29, 2014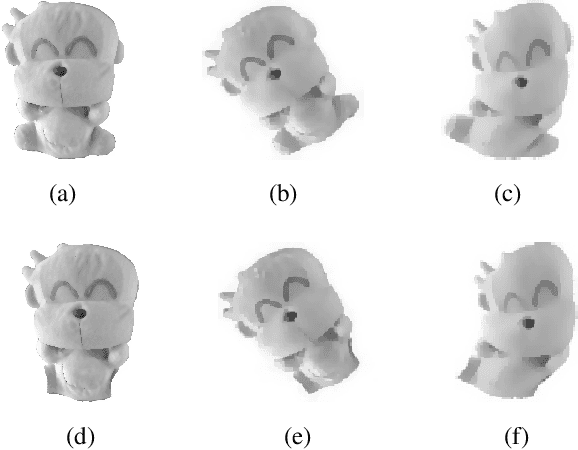
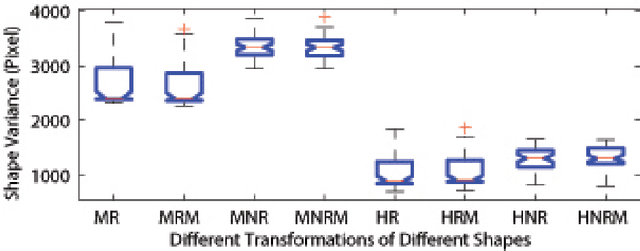
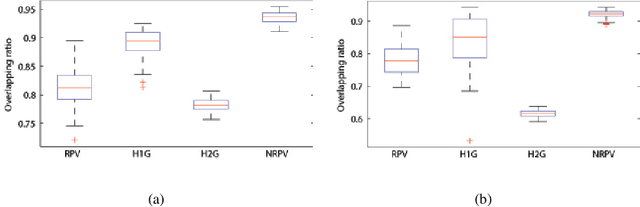

The same type of objects in different images may vary in their shapes because of rigid and non-rigid shape deformations, occluding foreground as well as cluttered background. The problem concerned in this work is the shape extraction in such challenging situations. We approach the shape extraction through shape alignment and recovery. This paper presents a novel and general method for shape alignment and recovery by using one example shapes based on deterministic energy minimization. Our idea is to use general model of shape deformation in minimizing active contour energies. Given \emph{a priori} form of the shape deformation, we show how the curve evolution equation corresponding to the shape deformation can be derived. The curve evolution is called the prior variation shape evolution (PVSE). We also derive the energy-minimizing PVSE for minimizing active contour energies. For shape recovery, we propose to use the PVSE that deforms the shape while preserving its shape characteristics. For choosing such shape-preserving PVSE, a theory of shape preservability of the PVSE is established. Experimental results validate the theory and the formulations, and they demonstrate the effectiveness of our method.
A Compact Linear Programming Relaxation for Binary Sub-modular MRF
Apr 09, 2014

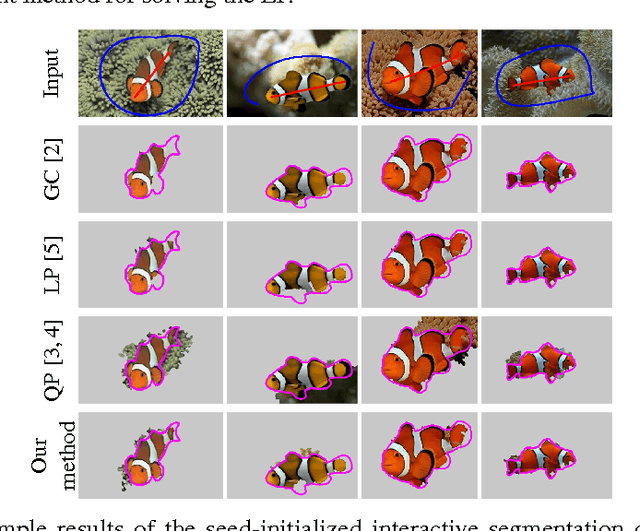

We propose a novel compact linear programming (LP) relaxation for binary sub-modular MRF in the context of object segmentation. Our model is obtained by linearizing an $l_1^+$-norm derived from the quadratic programming (QP) form of the MRF energy. The resultant LP model contains significantly fewer variables and constraints compared to the conventional LP relaxation of the MRF energy. In addition, unlike QP which can produce ambiguous labels, our model can be viewed as a quasi-total-variation minimization problem, and it can therefore preserve the discontinuities in the labels. We further establish a relaxation bound between our LP model and the conventional LP model. In the experiments, we demonstrate our method for the task of interactive object segmentation. Our LP model outperforms QP when converting the continuous labels to binary labels using different threshold values on the entire Oxford interactive segmentation dataset. The computational complexity of our LP is of the same order as that of the QP, and it is significantly lower than the conventional LP relaxation.