 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas
Jan 29, 2026Large language models (LLMs) are increasingly used as tool-augmented agents for multi-step decision making, yet training robust tool-using agents remains challenging. Existing methods still require manual intervention, depend on non-verifiable simulated environments, rely exclusively on either supervised fine-tuning (SFT) or reinforcement learning (RL), and struggle with stable long-horizon, multi-turn learning. To address these challenges, we introduce ASTRA, a fully automated end-to-end framework for training tool-augmented language model agents via scalable data synthesis and verifiable reinforcement learning. ASTRA integrates two complementary components. First, a pipeline that leverages the static topology of tool-call graphs synthesizes diverse, structurally grounded trajectories, instilling broad and transferable tool-use competence. Second, an environment synthesis framework that captures the rich, compositional topology of human semantic reasoning converts decomposed question-answer traces into independent, code-executable, and rule-verifiable environments, enabling deterministic multi-turn RL. Based on this method, we develop a unified training methodology that integrates SFT with online RL using trajectory-level rewards to balance task completion and interaction efficiency. Experiments on multiple agentic tool-use benchmarks demonstrate that ASTRA-trained models achieve state-of-the-art performance at comparable scales, approaching closed-source systems while preserving core reasoning ability. We release the full pipelines, environments, and trained models at https://github.com/LianjiaTech/astra.
Rényi Divergence Deep Mutual Learning
Sep 15, 2022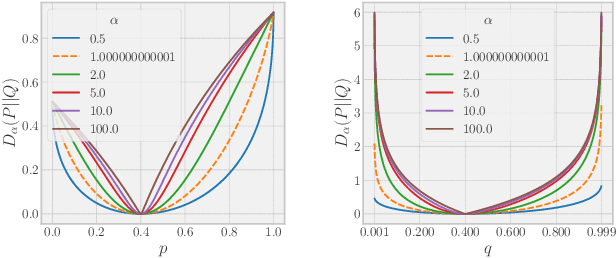


This paper revisits an incredibly simple yet exceedingly effective computing paradigm, Deep Mutual Learning (DML). We observe that the effectiveness correlates highly to its excellent generalization quality. In the paper, we interpret the performance improvement with DML from a novel perspective that it is roughly an approximate Bayesian posterior sampling procedure. This also establishes the foundation for applying the R\'{e}nyi divergence to improve the original DML, as it brings in the variance control of the prior (in the context of DML). Therefore, we propose R\'{e}nyi Divergence Deep Mutual Learning (RDML). Our empirical results represent the advantage of the marriage of DML and the R\'{e}nyi divergence. The flexible control imposed by the R\'{e}nyi divergence is able to further improve DML to learn better generalized models.