 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISP: Privacy-Safe Few-Shot Personalization via Lightweight Adaptation
Jan 10, 2026Large language model (LLM) personalization aims to adapt general-purpose models to individual users. Most existing methods, however, are developed under data-rich and resource-abundant settings, often incurring privacy risks. In contrast, realistic personalization typically occurs after deployment under (i) extremely limited user data, (ii) constrained computational resources, and (iii) strict privacy requirements. We propose PRISP, a lightweight and privacy-safe personalization framework tailored to these constraints. PRISP leverages a Text-to-LoRA hypernetwork to generate task-aware LoRA parameters from task descriptions, and enables efficient user personalization by optimizing a small subset of task-aware LoRA parameters together with minimal additional modules using few-shot user data. Experiments on a few-shot variant of the LaMP benchmark demonstrate that PRISP achieves strong overall performance compared to prior approaches, while reducing computational overhead and eliminating privacy risks.
Human Implicit Preference-Based Policy Fine-tuning for Multi-Agent Reinforcement Learning in USV Swarm
Mar 07, 2025Multi-Agent Reinforcement Learning (MARL) has shown promise in solving complex problems involving cooperation and competition among agents, such as an Unmanned Surface Vehicle (USV) swarm used in search and rescue, surveillance, and vessel protection. However, aligning system behavior with user preferences is challenging due to the difficulty of encoding expert intuition into reward functions. To address the issue, we propose a Reinforcement Learning with Human Feedback (RLHF) approach for MARL that resolves credit-assignment challenges through an Agent-Level Feedback system categorizing feedback into intra-agent, inter-agent, and intra-team types. To overcome the challenges of direct human feedback, we employ a Large Language Model (LLM) evaluator to validate our approach using feedback scenarios such as region constraints, collision avoidance, and task allocation. Our method effectively refines USV swarm policies, addressing key challenges in multi-agent systems while maintaining fairness and performance consistency.
AttentionHand: Text-driven Controllable Hand Image Generation for 3D Hand Reconstruction in the Wild
Jul 25, 2024



Recently, there has been a significant amount of research conducted on 3D hand reconstruction to use various forms of human-computer interaction. However, 3D hand reconstruction in the wild is challenging due to extreme lack of in-the-wild 3D hand datasets. Especially, when hands are in complex pose such as interacting hands, the problems like appearance similarity, self-handed occclusion and depth ambiguity make it more difficult. To overcome these issues, we propose AttentionHand, a novel method for text-driven controllable hand image generation. Since AttentionHand can generate various and numerous in-the-wild hand images well-aligned with 3D hand label, we can acquire a new 3D hand dataset, and can relieve the domain gap between indoor and outdoor scenes. Our method needs easy-to-use four modalities (i.e, an RGB image, a hand mesh image from 3D label, a bounding box, and a text prompt). These modalities are embedded into the latent space by the encoding phase. Then, through the text attention stage, hand-related tokens from the given text prompt are attended to highlight hand-related regions of the latent embedding. After the highlighted embedding is fed to the visual attention stage, hand-related regions in the embedding are attended by conditioning global and local hand mesh images with the diffusion-based pipeline. In the decoding phase, the final feature is decoded to new hand images, which are well-aligned with the given hand mesh image and text prompt. As a result, AttentionHand achieved state-of-the-art among text-to-hand image generation models, and the performance of 3D hand mesh reconstruction was improved by additionally training with hand images generated by AttentionHand.
Difficulty-Aware Simulator for Open Set Recognition
Jul 20, 2022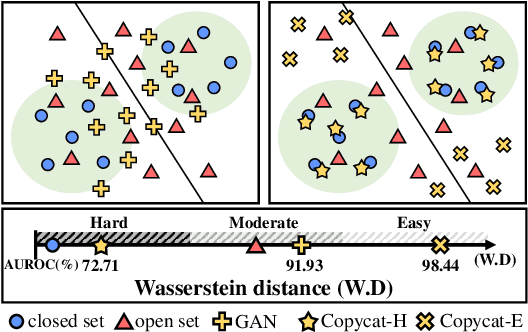
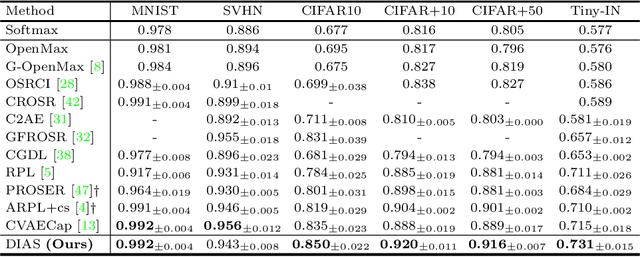
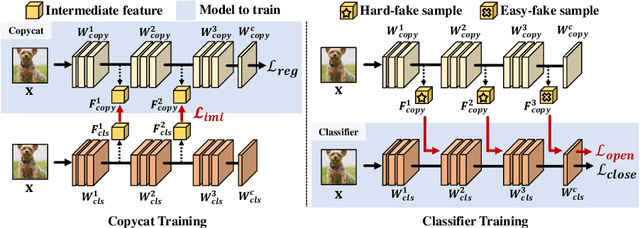

Open set recognition (OSR) assumes unknown instances appear out of the blue at the inference time. The main challenge of OSR is that the response of models for unknowns is totally unpredictable. Furthermore, the diversity of open set makes it harder since instances have different difficulty levels. Therefore, we present a novel framework, DIfficulty-Aware Simulator (DIAS), that generates fakes with diverse difficulty levels to simulate the real world. We first investigate fakes from generative adversarial network (GAN) in the classifier's viewpoint and observe that these are not severely challenging. This leads us to define the criteria for difficulty by regarding samples generated with GANs having moderate-difficulty. To produce hard-difficulty examples, we introduce Copycat, imitating the behavior of the classifier. Furthermore, moderate- and easy-difficulty samples are also yielded by our modified GAN and Copycat, respectively. As a result, DIAS outperforms state-of-the-art methods with both metrics of AUROC and F-score. Our code is available at https://github.com/wjun0830/Difficulty-Aware-Simulator.
End-to-end speech recognition modeling from de-identified data
Jul 12, 2022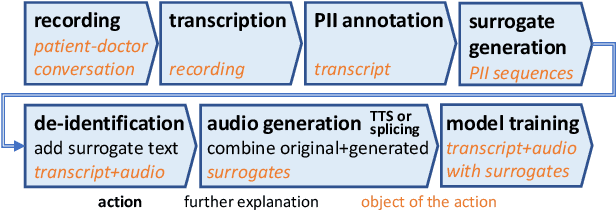
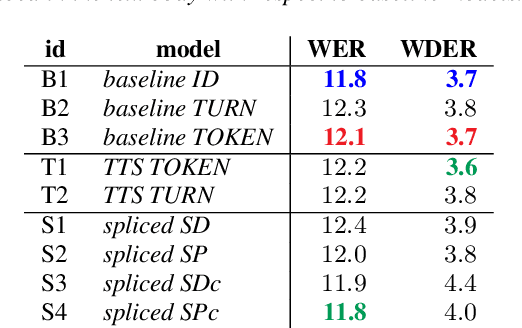
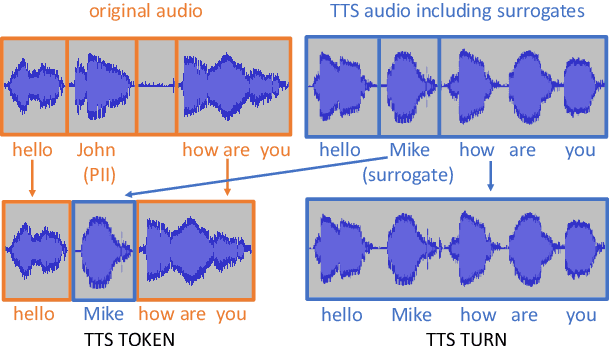
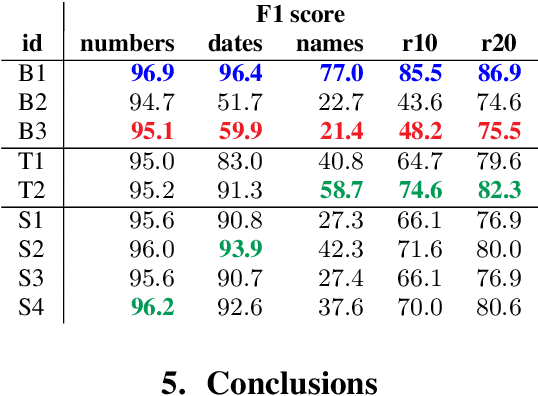
De-identification of data used for automatic speech recognition modeling is a critical component in protecting privacy, especially in the medical domain. However, simply removing all personally identifiable information (PII) from end-to-end model training data leads to a significant performance degradation in particular for the recognition of names, dates, locations, and words from similar categories. We propose and evaluate a two-step method for partially recovering this loss. First, PII is identified, and each occurrence is replaced with a random word sequence of the same category. Then, corresponding audio is produced via text-to-speech or by splicing together matching audio fragments extracted from the corpus. These artificial audio/label pairs, together with speaker turns from the original data without PII, are used to train models. We evaluate the performance of this method on in-house data of medical conversations and observe a recovery of almost the entire performance degradation in the general word error rate while still maintaining a strong diarization performance. Our main focus is the improvement of recall and precision in the recognition of PII-related words. Depending on the PII category, between $50\% - 90\%$ of the performance degradation can be recovered using our proposed method.