 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Sea of LLM Evaluation: Investigating Bias in Toxicity Benchmarks
May 11, 2026The rapid adoption of LLMs in both research and industry highlights the challenges of deploying them safely and reveals a gap in the systematic evaluation of toxicity benchmarks. As organizations increasingly rely on these benchmarks to certify models for customer-facing applications and automated moderation, unrecognized evaluation biases could lead to the deployment of vulnerable or unsafe systems. This work investigates the robustness of established benchmarking setups and examines how to measure currently neglected intrinsic biases, such as those related to model choice, metrics, and task types. Our experiments uncover significant discrepancies in benchmark behaviors when evaluation setups are altered. Specifically, shifting the task from text completion to summarization increases the tendency of benchmarks to flag content as harmful. Additionally, certain benchmarks fail to maintain consistent behavior when the input data domain is changed. Furthermore, we observe model-specific instabilities, demonstrating a clear need for more robust and comprehensive safety evaluation frameworks.
Linear-Time and Constant-Memory Text Embeddings Based on Recurrent Language Models
Apr 20, 2026Transformer-based embedding models suffer from quadratic computational and linear memory complexity, limiting their utility for long sequences. We propose recurrent architectures as an efficient alternative, introducing a vertically chunked inference strategy that enables fast embedding generation with memory usage that becomes constant in the input length once it exceeds the vertical chunk size. By fine-tuning Mamba2 models, we demonstrate their viability as general-purpose text embedders, achieving competitive performance across a range of benchmarks while maintaining a substantially smaller memory footprint compared to transformer-based counterparts. We empirically validate the applicability of our inference strategy to Mamba2, RWKV, and xLSTM models, confirming consistent runtime-memory trade-offs across architectures and establishing recurrent models as a compelling alternative to transformers for efficient embedding generation.
End-to-end speech recognition modeling from de-identified data
Jul 12, 2022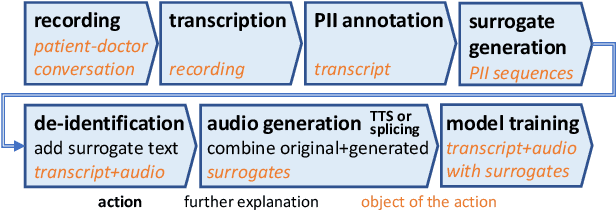
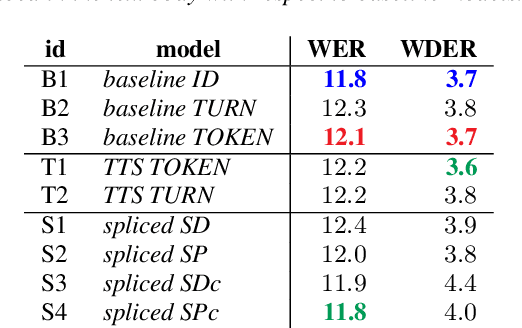
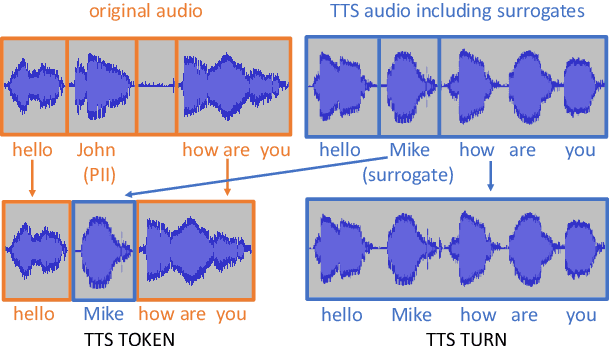
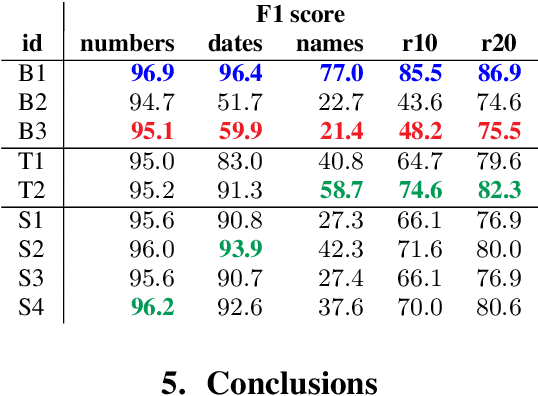
De-identification of data used for automatic speech recognition modeling is a critical component in protecting privacy, especially in the medical domain. However, simply removing all personally identifiable information (PII) from end-to-end model training data leads to a significant performance degradation in particular for the recognition of names, dates, locations, and words from similar categories. We propose and evaluate a two-step method for partially recovering this loss. First, PII is identified, and each occurrence is replaced with a random word sequence of the same category. Then, corresponding audio is produced via text-to-speech or by splicing together matching audio fragments extracted from the corpus. These artificial audio/label pairs, together with speaker turns from the original data without PII, are used to train models. We evaluate the performance of this method on in-house data of medical conversations and observe a recovery of almost the entire performance degradation in the general word error rate while still maintaining a strong diarization performance. Our main focus is the improvement of recall and precision in the recognition of PII-related words. Depending on the PII category, between $50\% - 90\%$ of the performance degradation can be recovered using our proposed method.