 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models
Nov 12, 2025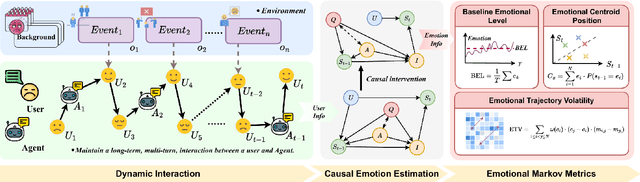
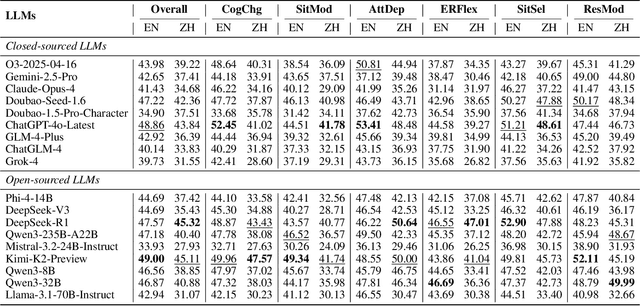
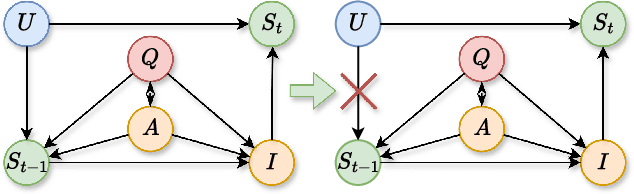
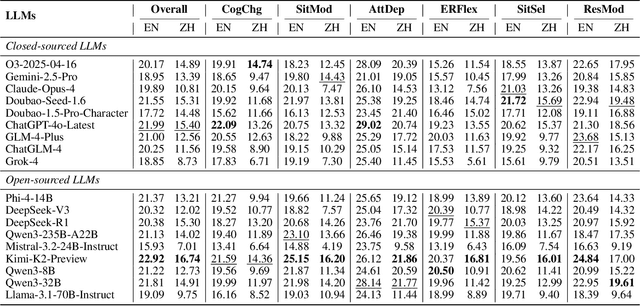
Emotional support is a core capability in human-AI interaction, with applications including psychological counseling, role play, and companionship. However, existing evaluations of large language models (LLMs) often rely on short, static dialogues and fail to capture the dynamic and long-term nature of emotional support. To overcome this limitation, we shift from snapshot-based evaluation to trajectory-based assessment, adopting a user-centered perspective that evaluates models based on their ability to improve and stabilize user emotional states over time. Our framework constructs a large-scale benchmark consisting of 328 emotional contexts and 1,152 disturbance events, simulating realistic emotional shifts under evolving dialogue scenarios. To encourage psychologically grounded responses, we constrain model outputs using validated emotion regulation strategies such as situation selection and cognitive reappraisal. User emotional trajectories are modeled as a first-order Markov process, and we apply causally-adjusted emotion estimation to obtain unbiased emotional state tracking. Based on this framework, we introduce three trajectory-level metrics: Baseline Emotional Level (BEL), Emotional Trajectory Volatility (ETV), and Emotional Centroid Position (ECP). These metrics collectively capture user emotional dynamics over time and support comprehensive evaluation of long-term emotional support performance of LLMs. Extensive evaluations across a diverse set of LLMs reveal significant disparities in emotional support capabilities and provide actionable insights for model development.
CPTuning: Contrastive Prompt Tuning for Generative Relation Extraction
Jan 04, 2025



Generative relation extraction (RE) commonly involves first reformulating RE as a linguistic modeling problem easily tackled with pre-trained language models (PLM) and then fine-tuning a PLM with supervised cross-entropy loss. Although having achieved promising performance, existing approaches assume only one deterministic relation between each pair of entities without considering real scenarios where multiple relations may be valid, i.e., entity pair overlap, causing their limited applications. To address this problem, we introduce a novel contrastive prompt tuning method for RE, CPTuning, which learns to associate a candidate relation between two in-context entities with a probability mass above or below a threshold, corresponding to whether the relation exists. Beyond learning schema, CPTuning also organizes RE as a verbalized relation generation task and uses Trie-constrained decoding to ensure a model generates valid relations. It adaptively picks out the generated candidate relations with a high estimated likelihood in inference, thereby achieving multi-relation extraction. We conduct extensive experiments on four widely used datasets to validate our method. Results show that T5-large fine-tuned with CPTuning significantly outperforms previous methods, regardless of single or multiple relations extraction.
Multilingual Dialogue Generation with Shared-Private Memory
Oct 06, 2019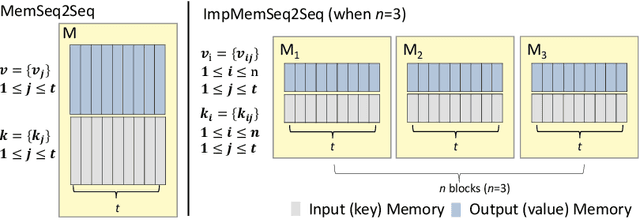
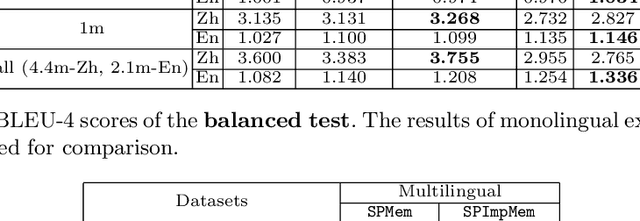
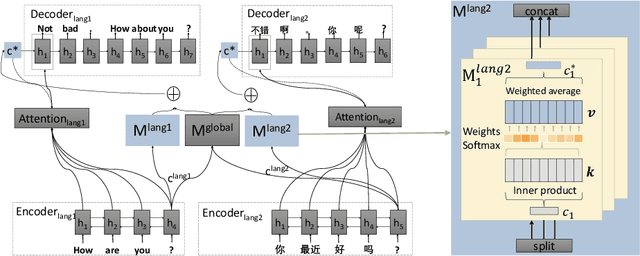
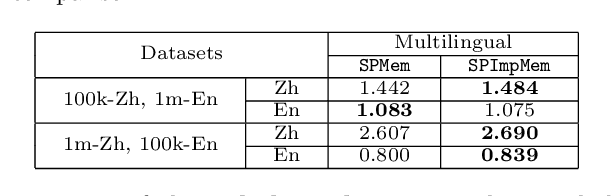
Existing dialog systems are all monolingual, where features shared among different languages are rarely explored. In this paper, we introduce a novel multilingual dialogue system. Specifically, we augment the sequence to sequence framework with improved shared-private memory. The shared memory learns common features among different languages and facilitates a cross-lingual transfer to boost dialogue systems, while the private memory is owned by each separate language to capture its unique feature. Experiments conducted on Chinese and English conversation corpora of different scales show that our proposed architecture outperforms the individually learned model with the help of the other language, where the improvement is particularly distinct when the training data is limited.