 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Transceiver Optimization for MmWave/THz MU-MIMO ISAC Systems
Jan 31, 2024In this paper, we consider the problem of joint transceiver design for millimeter wave (mmWave)/Terahertz (THz) multi-user MIMO integrated sensing and communication (ISAC) systems. Such a problem is formulated into a nonconvex optimization problem, with the objective of maximizing a weighted sum of communication users' rates and the passive radar's signal-to-clutter-and-noise-ratio (SCNR). By exploring a low-dimensional subspace property of the optimal precoder, a low-complexity block-coordinate-descent (BCD)-based algorithm is proposed. Our analysis reveals that the hybrid analog/digital beamforming structure can attain the same performance as that of a fully digital precoder, provided that the number of radio frequency (RF) chains is no less than the number of resolvable signal paths. Also, through expressing the precoder as a sum of a communication-precoder and a sensing-precoder, we develop an analytical solution to the joint transceiver design problem by generalizing the idea of block-diagonalization (BD) to the ISAC system. Simulation results show that with a proper tradeoff parameter, the proposed methods can achieve a decent compromise between communication and sensing, where the performance of each communication/sensing task experiences only a mild performance loss as compared with the performance attained by optimizing exclusively for a single task.
Empower Your Model with Longer and Better Context Comprehension
Jul 27, 2023Recently, with the emergence of numerous Large Language Models (LLMs), the implementation of AI has entered a new era. Irrespective of these models' own capacity and structure, there is a growing demand for LLMs to possess enhanced comprehension of longer and more complex contexts with relatively smaller sizes. Models often encounter an upper limit when processing sequences of sentences that extend beyond their comprehension capacity and result in off-topic or even chaotic responses. While several recent works attempt to address this issue in various ways, they rarely focus on "why models are unable to compensate or strengthen their capabilities on their own". In this paper, we thoroughly investigate the nature of information transfer within LLMs and propose a novel technique called Attention Transition. This technique empowers models to achieve longer and better context comprehension with minimal additional training or impact on generation fluency. Our experiments are conducted on the challenging XSum dataset using LLaMa-7b model with context token length ranging from 800 to 1900. Results demonstrate that we achieve substantial improvements compared with the original generation results evaluated by GPT4.
Calibration-Aware Margin Loss: Pushing the Accuracy-Calibration Consistency Pareto Frontier for Deep Metric Learning
Jul 08, 2023



The ability to use the same distance threshold across different test classes / distributions is highly desired for a frictionless deployment of commercial image retrieval systems. However, state-of-the-art deep metric learning losses often result in highly varied intra-class and inter-class embedding structures, making threshold calibration a non-trivial process in practice. In this paper, we propose a novel metric named Operating-Point-Incosistency-Score (OPIS) that measures the variance in the operating characteristics across different classes in a target calibration range, and demonstrate that high accuracy of a metric learning embedding model does not guarantee calibration consistency for both seen and unseen classes. We find that, in the high-accuracy regime, there exists a Pareto frontier where accuracy improvement comes at the cost of calibration consistency. To address this, we develop a novel regularization, named Calibration-Aware Margin (CAM) loss, to encourage uniformity in the representation structures across classes during training. Extensive experiments demonstrate CAM's effectiveness in improving calibration-consistency while retaining or even enhancing accuracy, outperforming state-of-the-art deep metric learning methods.
Generalized NOMP for Line Spectrum Estimation and Detection from Coarsely Quantized Samples
Jul 02, 2023



As radar systems accompanied by large numbers of antennas and scale up in bandwidth, the cost and power consumption of high-precision (e.g., 10-12 bits) analog-to-digital converter (ADC) become the limiting factor. As a remedy, line spectral estimation and detection (LSE\&D) from low resolution (e.g., 1-4 bits) quantization has been gradually drawn attention in recent years. As low resolution quantization reduces the dynamic range (DR) of the receiver, the theoretical detection probabilities for the multiple targets (especially for the weakest target) are analyzed, which reveals the effects of low resolution on weak signal detection and provides the guidelines for system design. The computation complexities of current methods solve the line spectral estimation from coarsely quantized samples are often high. In this paper, we propose a fast generalized Newtonized orthogonal matching pursuit (GNOMP) which has superior estimation accuracy and maintains a constant false alarm rate (CFAR) behaviour. Besides, such an approach are easily extended to handle the other measurement scenarios such as sign measurements from time-varying thresholds, compressive setting, multisnapshot setting, multidimensional setting and unknown noise variance. Substantial numerical simulations are conducted to demonstrate the effectiveness of GNOMP in terms of estimating accuracy, detection probability and running time. Besides, real data are also provided to demonstrate the effectiveness of the GNOMP.
Musketeer (All for One, and One for All): A Generalist Vision-Language Model with Task Explanation Prompts
May 11, 2023We present a sequence-to-sequence vision-language model whose parameters are jointly trained on all tasks (all for one) and fully shared among multiple tasks (one for all), resulting in a single model which we named Musketeer. The integration of knowledge across heterogeneous tasks is enabled by a novel feature called Task Explanation Prompt (TEP). TEP reduces interference among tasks, allowing the model to focus on their shared structure. With a single model, Musketeer achieves results comparable to or better than strong baselines trained on single tasks, almost uniformly across multiple tasks.
Channel Estimation for RIS-aided mmWave Massive MIMO System Using Few-bit ADCs
Jan 26, 2023Millimeter wave (mmWave) massive multiple-input multiple-output (massive MIMO) is one of the most promising technologies for the fifth generation and beyond wireless communication system. However, a large number of antennas incur high power consumption and hardware costs, and high-frequency communications place a heavy burden on the analog-to-digital converters (ADCs) at the base station (BS). Furthermore, it is too costly to equipping each antenna with a high-precision ADC in a large antenna array system. It is promising to adopt low-resolution ADCs to address this problem. In this paper, we investigate the cascaded channel estimation for a mmWave massive MIMO system aided by a reconfigurable intelligent surface (RIS) with the BS equipped with few-bit ADCs. Due to the low-rank property of the cascaded channel, the estimation of the cascaded channel can be formulated as a low-rank matrix completion problem. We introduce a Bayesian optimal estimation framework for estimating the user-RIS-BS cascaded channel to tackle with the information loss caused by quantization. To implement the estimator and achieve the matrix completion, we use efficient bilinear generalized approximate message passing (BiG-AMP) algorithm. Extensive simulation results verify that our proposed method can accurately estimate the cascaded channel for the RIS-aided mmWave massive MIMO system with low-resolution ADCs.
Target-Mounted Intelligent Reflecting Surface for Joint Location and Orientation Estimation
Jan 23, 2023Intelligent reflecting surface (IRS) has been widely recognized as an efficient technique to reconfigure the electromagnetic environment in favor of wireless communication performance. In this paper, we propose a new application of IRS for device-free target sensing via joint location and orientation estimation. In particular, different from the existing works that use IRS as an additional anchor node for localization/sensing, we consider mounting IRS on the sensing target, whereby estimating the IRS's location and orientation as that of the target by leveraging IRS's controllable signal reflection. To this end, we first propose a tensor-based method to acquire essential angle information between the IRS and the sensing transmitter as well as a set of distributed sensing receivers. Next, based on the estimated angle information, we formulate two optimization problems to estimate the location and orientation of the IRS/target, respectively, and obtain the locally optimal solutions to them by invoking two iterative algorithms, namely, gradient descent method and manifold optimization. In particular, we show that the orientation estimation problem admits a closed-form solution in a special case that usually holds in practice. Furthermore, theoretical analysis is conducted to draw essential insights into the proposed sensing system design and performance. Simulation results verify our theoretical analysis and demonstrate that the proposed methods can achieve high estimation accuracy which is close to the theoretical bound.
CFAR based NOMP for Line Spectral Estimation and Detection
Oct 19, 2022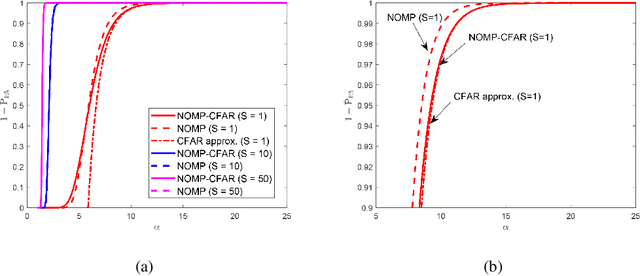
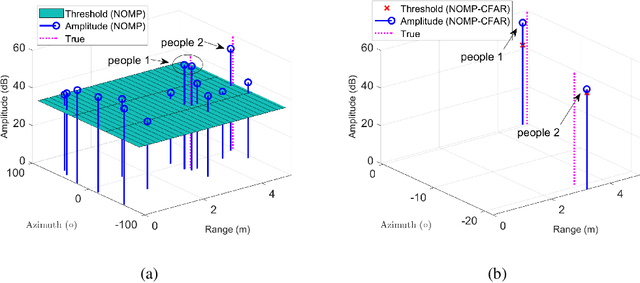

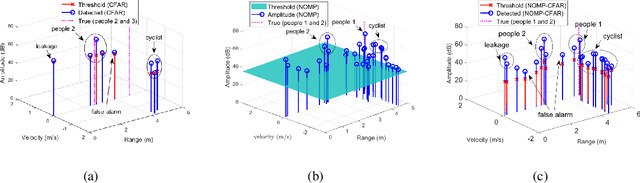
The line spectrum estimation problem is considered in this paper. We propose a CFAR-based Newtonized OMP (NOMP-CFAR) method which can maintain a desired false alarm rate without the knowledge of the noise variance. The NOMP-CFAR consists of two steps, namely, an initialization step and a detection step. In the initialization step, NOMP is employed to obtain candidate sinusoidal components. In the detection step, CFAR detector is applied to detect each candidate frequency, and remove the most unlikely frequency component. Then, the Newton refinements are used to refine the remaining parameters. The relationship between the false alarm rate and the required threshold is established. By comparing with the NOMP, NOMP-CFAR has only $1$ dB performance loss in additive white Gaussian noise scenario with false alarm probability $10^{-2}$ and detection probability $0.8$ without knowledge of noise variance. For varied noise variance scenario, NOMP-CFAR still preserves its CFAR property, while NOMP violates the CFAR. Besides, real experiments are also conducted to demonstrate the detection performance of NOMP-CFAR, compared to CFAR and NOMP.
Compressed CPD-Based Channel Estimation and Joint Beamforming for RIS-Assisted Millimeter Wave Communications
Oct 04, 2022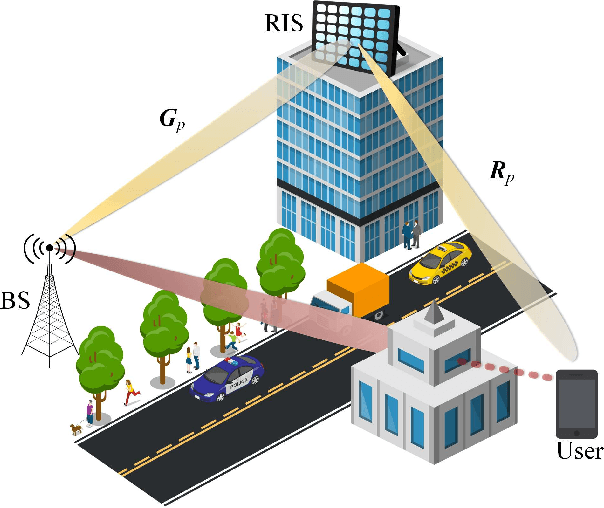
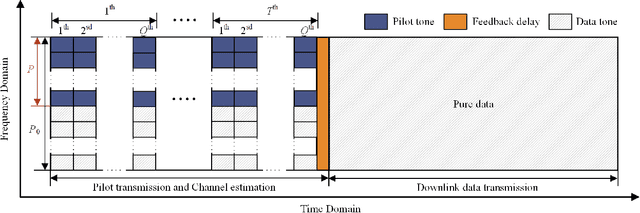
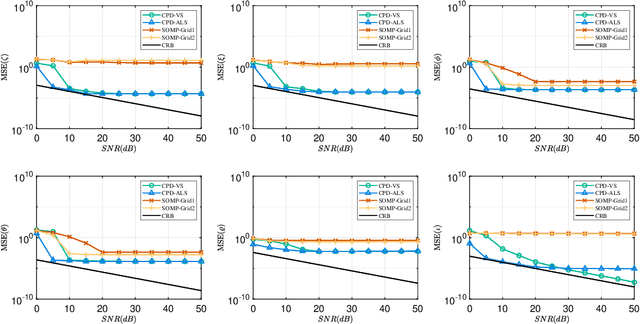
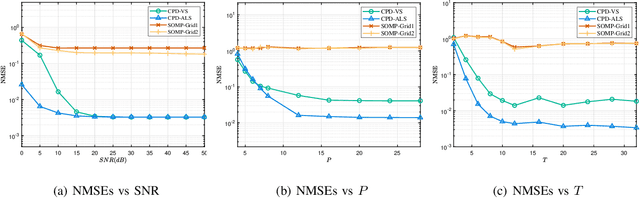
We consider the problem of channel estimation and joint active and passive beamforming for reconfigurable intelligent surface (RIS) assisted millimeter wave (mmWave) multiple-input multiple-output (MIMO) orthogonal frequency division multiplexing (OFDM) systems. We show that, with a well-designed frame-based training protocol, the received pilot signal can be organized into a low-rank third-order tensor that admits a canonical polyadic decomposition (CPD). Based on this observation, we propose two CPD-based methods for estimating the cascade channels associated with different subcarriers. The proposed methods exploit the intrinsic low-rankness of the CPD formulation, which is a result of the sparse scattering characteristics of mmWave channels, and thus have the potential to achieve a significant training overhead reduction. Specifically, our analysis shows that the proposed methods have a sample complexity that scales quadratically with the sparsity of the cascade channel. Also, by utilizing the singular value decomposition-like structure of the effective channel, this paper develops a joint active and passive beamforming method based on the estimated cascade channels. Simulation results show that the proposed CPD-based channel estimation methods attain mean square errors that are close to the Cramer-Rao bound (CRB) and present a clear advantage over the compressed sensing-based method. In addition, the proposed joint beamforming method can effectively utilize the estimated channel parameters to achieve superior beamforming performance.
An In-depth Study of Stochastic Backpropagation
Sep 30, 2022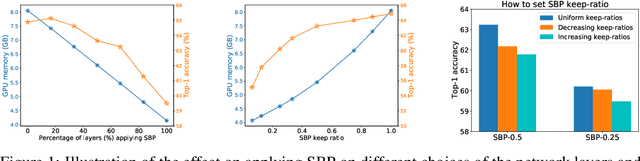
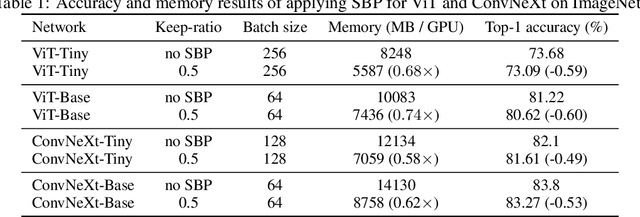
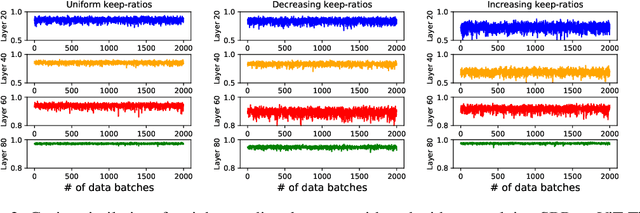
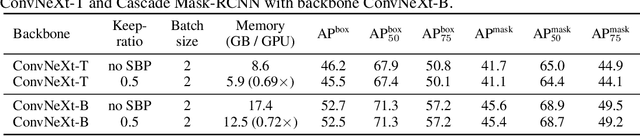
In this paper, we provide an in-depth study of Stochastic Backpropagation (SBP) when training deep neural networks for standard image classification and object detection tasks. During backward propagation, SBP calculates the gradients by only using a subset of feature maps to save the GPU memory and computational cost. We interpret SBP as an efficient way to implement stochastic gradient decent by performing backpropagation dropout, which leads to considerable memory saving and training process speedup, with a minimal impact on the overall model accuracy. We offer some good practices to apply SBP in training image recognition models, which can be adopted in learning a wide range of deep neural networks. Experiments on image classification and object detection show that SBP can save up to 40% of GPU memory with less than 1% accuracy degradation.