 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesthetic Bot: Interactively Evolving Game Maps on Twitter
Aug 24, 2022
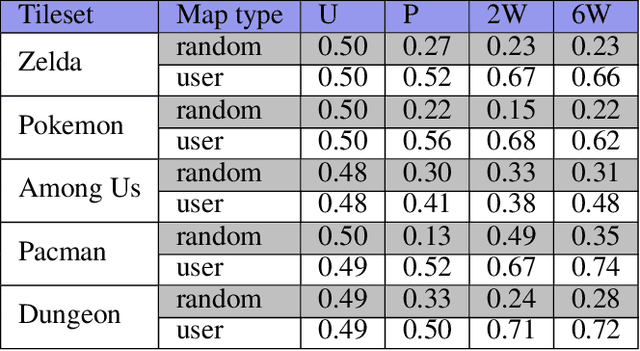

This paper describes the implementation of the Aesthetic Bot, an automated Twitter account that posts images of small game maps that are either user-made or generated from an evolutionary system. The bot then prompts users to vote via a poll posted in the image's thread for the most aesthetically pleasing map. This creates a rating system that allows for direct interaction with the bot in a way that is integrated seamlessly into a user's regularly updated Twitter content feed. Upon conclusion of the each voting round, the bot learns from the distribution of votes for each map to emulate user preferences for design and visual aesthetic in order to generate maps that would win future vote pairings. We discuss the ongoing results and emerging behaviors that have occurred since the release of this system from both the bot's generation of game maps and the participating Twitter users.
Learning Controllable 3D Level Generators
Jul 06, 2022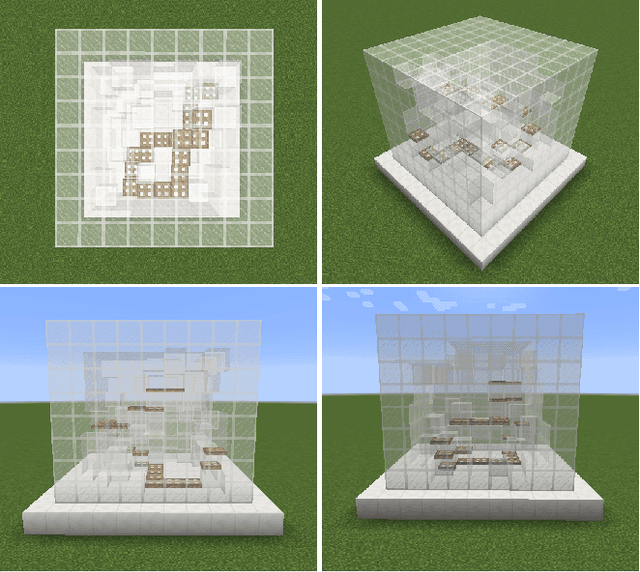

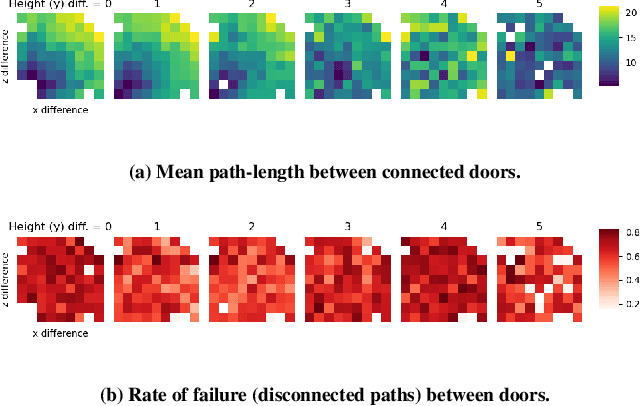
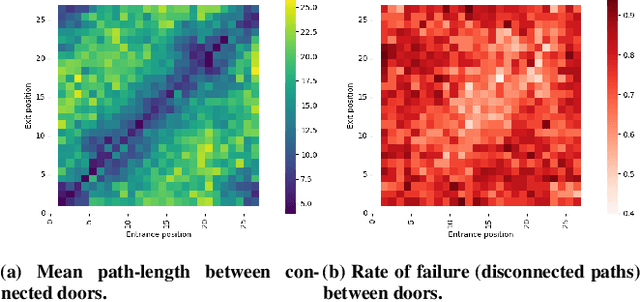
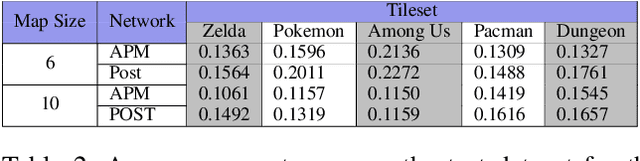
Procedural Content Generation via Reinforcement Learning (PCGRL) foregoes the need for large human-authored data-sets and allows agents to train explicitly on functional constraints, using computable, user-defined measures of quality instead of target output. We explore the application of PCGRL to 3D domains, in which content-generation tasks naturally have greater complexity and potential pertinence to real-world applications. Here, we introduce several PCGRL tasks for the 3D domain, Minecraft (Mojang Studios, 2009). These tasks will challenge RL-based generators using affordances often found in 3D environments, such as jumping, multiple dimensional movement, and gravity. We train an agent to optimize each of these tasks to explore the capabilities of previous research in PCGRL. This agent is able to generate relatively complex and diverse levels, and generalize to random initial states and control targets. Controllability tests in the presented tasks demonstrate their utility to analyze success and failure for 3D generators.
Generating Diverse Indoor Furniture Arrangements
Jun 20, 2022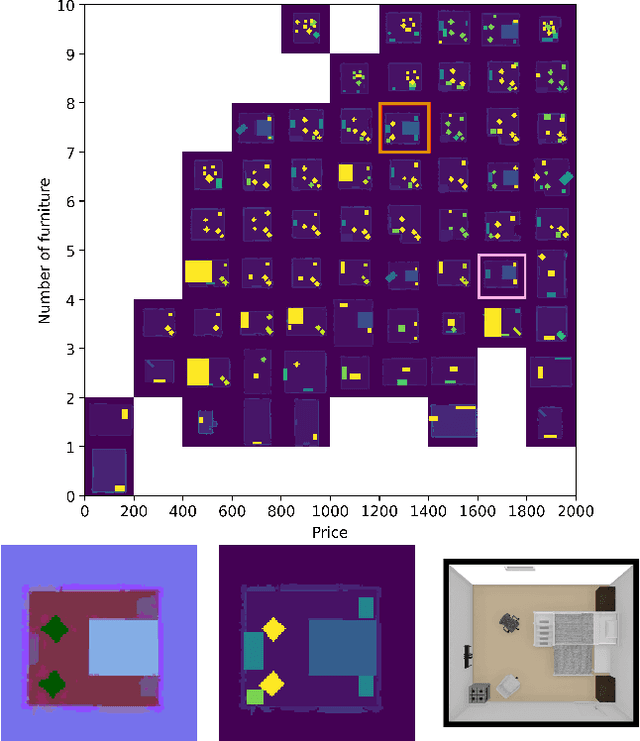

We present a method for generating arrangements of indoor furniture from human-designed furniture layout data. Our method creates arrangements that target specified diversity, such as the total price of all furniture in the room and the number of pieces placed. To generate realistic furniture arrangement, we train a generative adversarial network (GAN) on human-designed layouts. To target specific diversity in the arrangements, we optimize the latent space of the GAN via a quality diversity algorithm to generate a diverse arrangement collection. Experiments show our approach discovers a set of arrangements that are similar to human-designed layouts but varies in price and number of furniture pieces.
Learning to Generate Levels by Imitating Evolution
Jun 11, 2022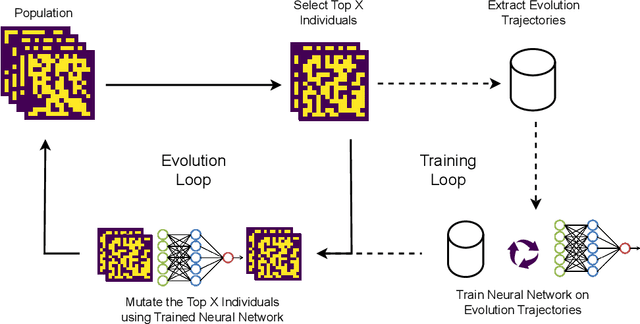
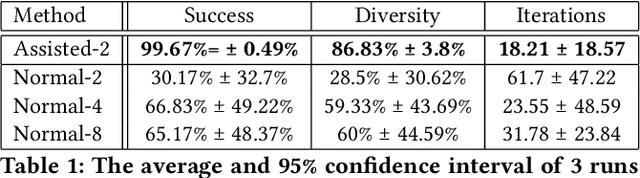

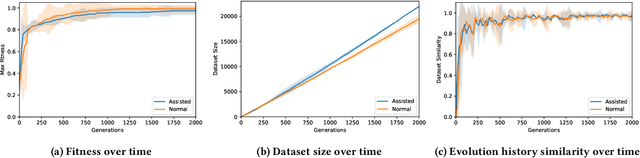
Search-based procedural content generation (PCG) is a well-known method used for level generation in games. Its key advantage is that it is generic and able to satisfy functional constraints. However, due to the heavy computational costs to run these algorithms online, search-based PCG is rarely utilized for real-time generation. In this paper, we introduce a new type of iterative level generator using machine learning. We train a model to imitate the evolutionary process and use the model to generate levels. This trained model is able to modify noisy levels sequentially to create better levels without the need for a fitness function during inference. We evaluate our trained models on a 2D maze generation task. We compare several different versions of the method: training the models either at the end of evolution (normal evolution) or every 100 generations (assisted evolution) and using the model as a mutation function during evolution. Using the assisted evolution process, the final trained models are able to generate mazes with a success rate of 99% and high diversity of 86%. This work opens the door to a new way of learning level generators guided by the evolutionary process and perhaps will increase the adoption of search-based PCG in the game industry.
Watts: Infrastructure for Open-Ended Learning
Apr 28, 2022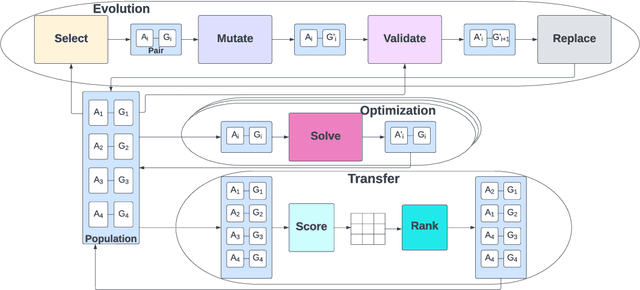

This paper proposes a framework called Watts for implementing, comparing, and recombining open-ended learning (OEL) algorithms. Motivated by modularity and algorithmic flexibility, Watts atomizes the components of OEL systems to promote the study of and direct comparisons between approaches. Examining implementations of three OEL algorithms, the paper introduces the modules of the framework. The hope is for Watts to enable benchmarking and to explore new types of OEL algorithms. The repo is available at \url{https://github.com/aadharna/watts}
Persona-driven Dominant/Submissive Map (PDSM) Generation for Tutorials
Apr 11, 2022
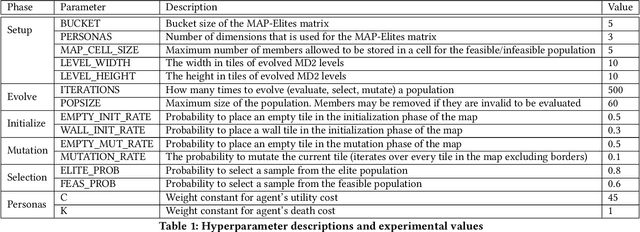
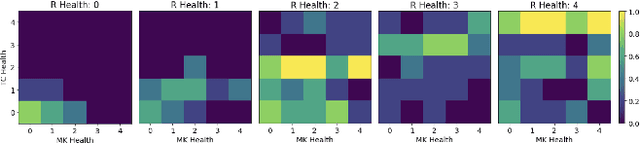
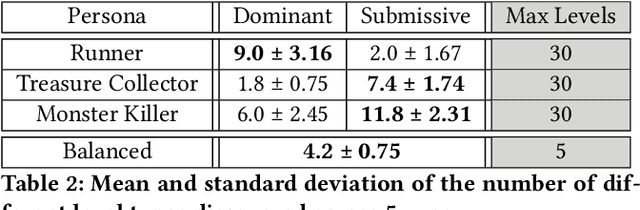
In this paper, we present a method for automated persona-driven video game tutorial level generation. Tutorial levels are scenarios in which the player can explore and discover different rules and game mechanics. Procedural personas can guide generators to create content which encourages or discourages certain playstyle behaviors. In this system, we use procedural personas to calculate the behavioral characteristics of levels which are evolved using the quality-diversity algorithm known as Constrained MAP-Elites. An evolved map's quality is determined by its simplicity: the simpler it is, the better it is. Within this work, we show that the generated maps can strongly encourage or discourage different persona-like behaviors and range from simple solutions to complex puzzle-levels, making them perfect candidates for a tutorial generative system.
Predicting Personas Using Mechanic Frequencies and Game State Traces
Mar 24, 2022
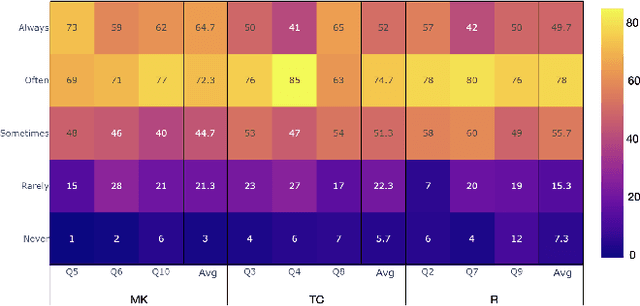


We investigate how to efficiently predict play personas based on playtraces. Play personas can be computed by calculating the action agreement ratio between a player and a generative model of playing behavior, a so-called procedural persona. But this is computationally expensive and assumes that appropriate procedural personas are readily available. We present two methods for estimating player persona, one using regular supervised learning and aggregate measures of game mechanics initiated, and another based on sequence learning on a trace of closely cropped gameplay observations. While both of these methods achieve high accuracy when predicting play personas defined by agreement with procedural personas, they utterly fail to predict play style as defined by the players themselves using a questionnaire. This interesting result highlights the value of using computational methods in defining play personas.
Transfer Dynamics in Emergent Evolutionary Curricula
Mar 03, 2022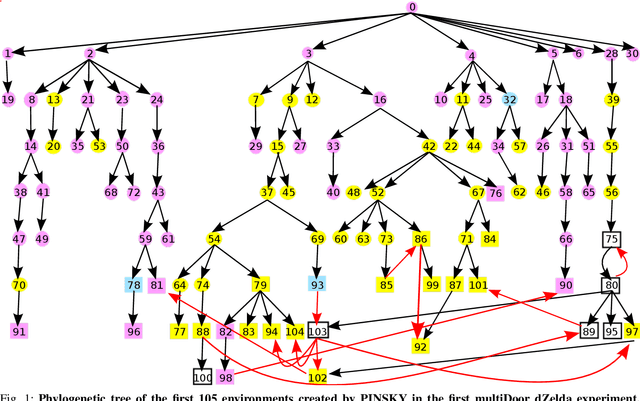
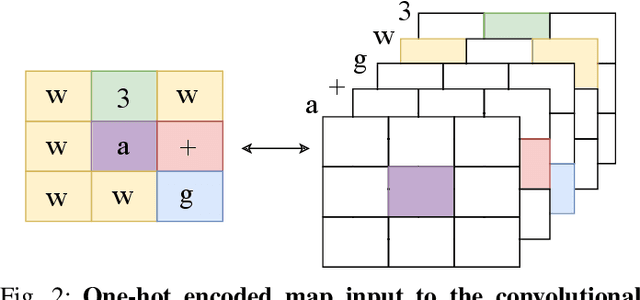
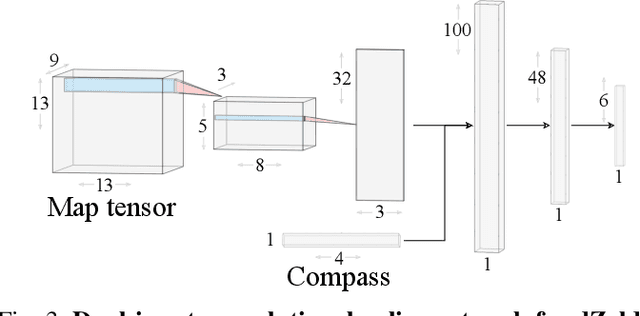
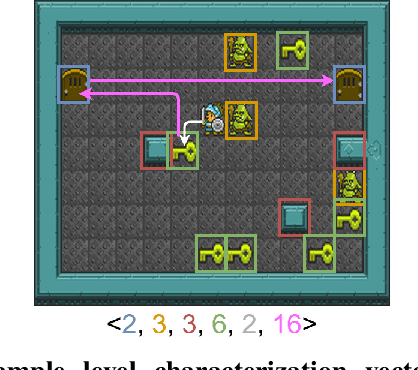
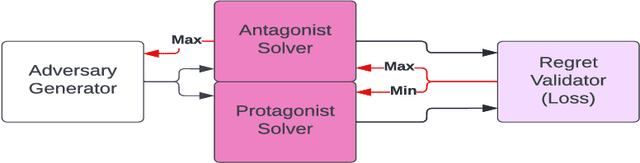
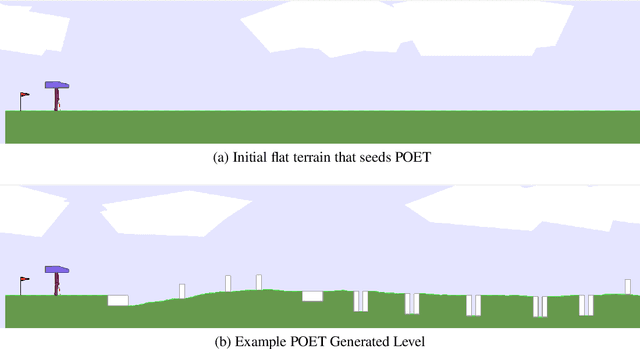
PINSKY is a system for open-ended learning through neuroevolution in game-based domains. It builds on the Paired Open-Ended Trailblazer (POET) system, which originally explored learning and environment generation for bipedal walkers, and adapts it to games in the General Video Game AI (GVGAI) system. Previous work showed that by co-evolving levels and neural network policies, levels could be found for which successful policies could not be created via optimization alone. Studied in the realm of Artificial Life as a potentially open-ended alternative to gradient-based fitness, minimal criteria (MC)-based selection helps foster diversity in evolutionary populations. The main question addressed by this paper is how the open-ended learning actually works, focusing in particular on the role of transfer of policies from one evolutionary branch ("species") to another. We analyze the dynamics of the system through creating phylogenetic trees, analyzing evolutionary trajectories of policies, and temporally breaking down transfers according to species type. Furthermore, we analyze the impact of the minimal criterion on generated level diversity and inter-species transfer. The most insightful finding is that inter-species transfer, while rare, is crucial to the system's success.
Path of Destruction: Learning an Iterative Level Generator Using a Small Dataset
Feb 21, 2022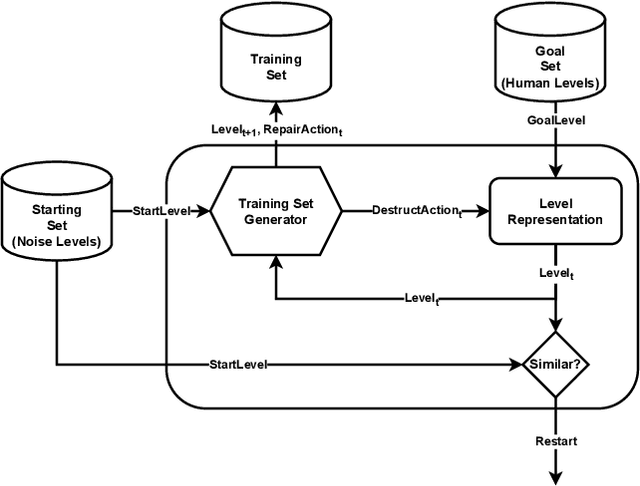
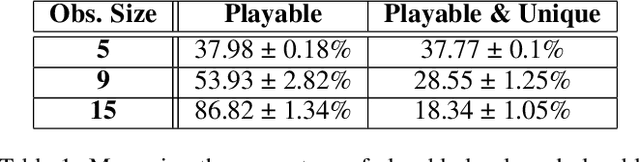
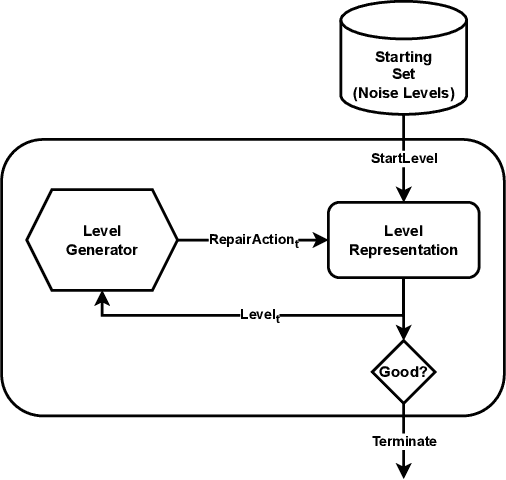
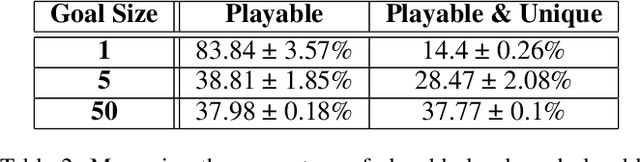
We propose a new procedural content generation method which learns iterative level generators from a dataset of existing levels. The Path of Destruction method, as we call it, views level generation as repair; levels are created by iteratively repairing from a random starting state. The first step is to generate an artificial dataset from the original set of levels by introducing many different sequences of mutations to existing levels. In the generated dataset, features are observations of destroyed levels and targets are the specific actions that repair the mutated tile in the middle of the observations. Using this dataset, a convolutional network is trained to map from observations to their respective appropriate repair actions. The trained network is then used to iteratively produce levels from random starting states. We demonstrate this method by applying it to generate unique and playable tile-based levels for several 2D games (Zelda, Danger Dave, and Sokoban) and vary key hyperparameters.
Approximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
Feb 08, 2022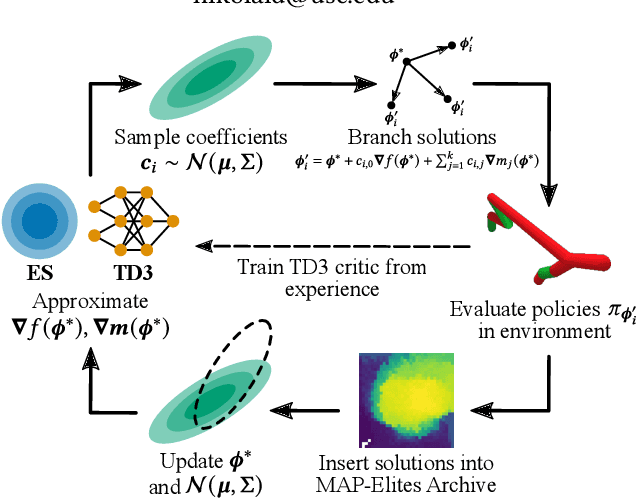

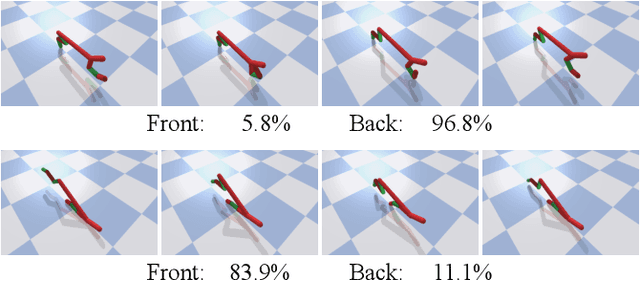
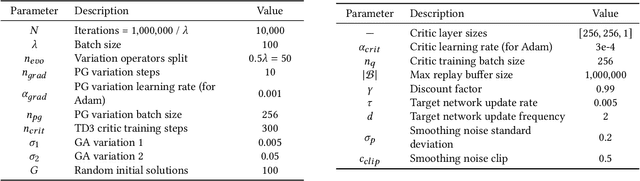
Consider a walking agent that must adapt to damage. To approach this task, we can train a collection of policies and have the agent select a suitable policy when damaged. Training this collection may be viewed as a quality diversity (QD) optimization problem, where we search for solutions (policies) which maximize an objective (walking forward) while spanning a set of measures (measurable characteristics). Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available for the objective and measures. However, such gradients are typically unavailable in RL settings due to non-differentiable environments. To apply DQD in RL settings, we propose to approximate objective and measure gradients with evolution strategies and actor-critic methods. We develop two variants of the DQD algorithm CMA-MEGA, each with different gradient approximations, and evaluate them on four simulated walking tasks. One variant achieves comparable performance (QD score) with the state-of-the-art PGA-MAP-Elites in two tasks. The other variant performs comparably in all tasks but is less efficient than PGA-MAP-Elites in two tasks. These results provide insight into the limitations of CMA-MEGA in domains that require rigorous optimization of the objective and where exact gradients are unavailable.