 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Keypoint Correspondences for Multi-Person Pose Estimation and Tracking in Videos
Jun 02, 2020

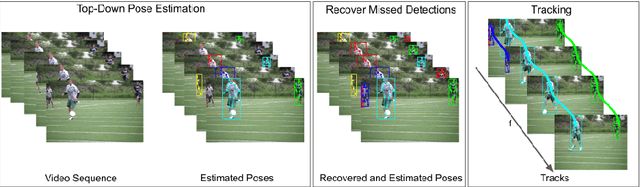

Video annotation is expensive and time consuming. Consequently, datasets for multi-person pose estimation and tracking are less diverse and have more sparse annotations compared to large scale image datasets for human pose estimation. This makes it challenging to learn deep learning based models for associating keypoints across frames that are robust to nuisance factors such as motion blur and occlusions for the task of multi-person pose tracking. To address this issue, we propose an approach that relies on keypoint correspondences for associating persons in videos. Instead of training the network for estimating keypoint correspondences on video data, it is trained on a large scale image datasets for human pose estimation using self-supervision. Combined with a top-down framework for human pose estimation, we use keypoints correspondences to (i) recover missed pose detections (ii) associate pose detections across video frames. Our approach achieves state-of-the-art results for multi-frame pose estimation and multi-person pose tracking on the PosTrack $2017$ and PoseTrack $2018$ data sets.
On Evaluating Weakly Supervised Action Segmentation Methods
May 21, 2020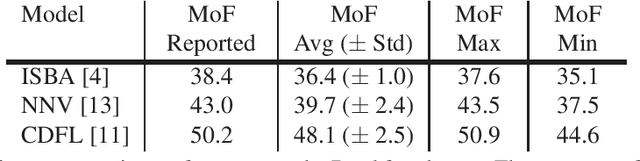
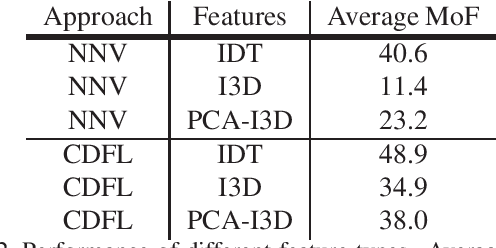

Action segmentation is the task of temporally segmenting every frame of an untrimmed video. Weakly supervised approaches to action segmentation, especially from transcripts have been of considerable interest to the computer vision community. In this work, we focus on two aspects of the use and evaluation of weakly supervised action segmentation approaches that are often overlooked: the performance variance over multiple training runs and the impact of selecting feature extractors for this task. To tackle the first problem, we train each method on the Breakfast dataset 5 times and provide average and standard deviation of the results. Our experiments show that the standard deviation over these repetitions is between 1 and 2.5% and significantly affects the comparison between different approaches. Furthermore, our investigation on feature extraction shows that, for the studied weakly-supervised action segmentation methods, higher-level I3D features perform worse than classical IDT features.
Adversarial Synthesis of Human Pose from Text
May 01, 2020
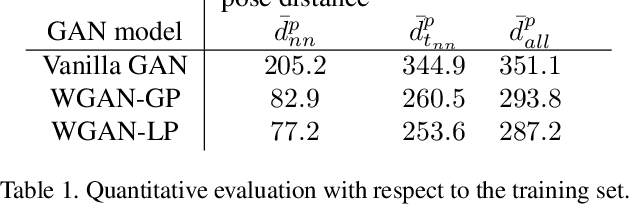
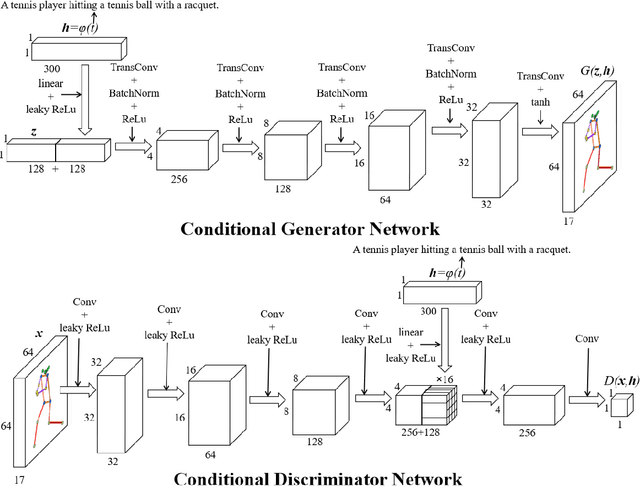
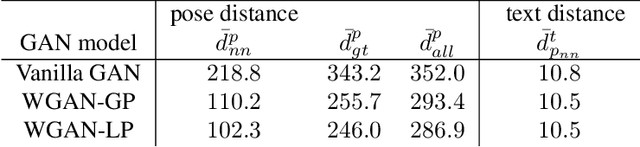
This work introduces the novel task of human pose synthesis from text. In order to solve this task, we propose a model that is based on a conditional generative adversarial network. It is designed to generate 2D human poses conditioned on human-written text descriptions. The model is trained and evaluated using the COCO dataset, which consists of images capturing complex everyday scenes. We show through qualitative and quantitative results that the model is capable of synthesizing plausible poses matching the given text, indicating it is possible to generate poses that are consistent with the given semantic features, especially for actions with distinctive poses. We also show that the model outperforms a vanilla GAN.
SCT: Set Constrained Temporal Transformer for Set Supervised Action Segmentation
Mar 31, 2020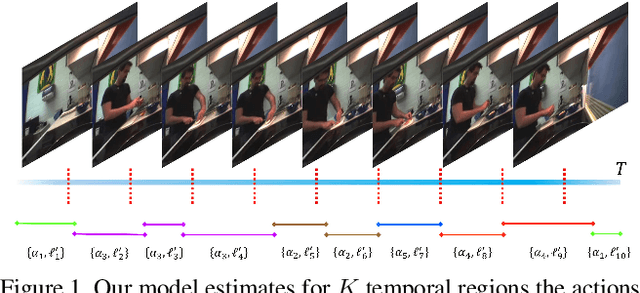
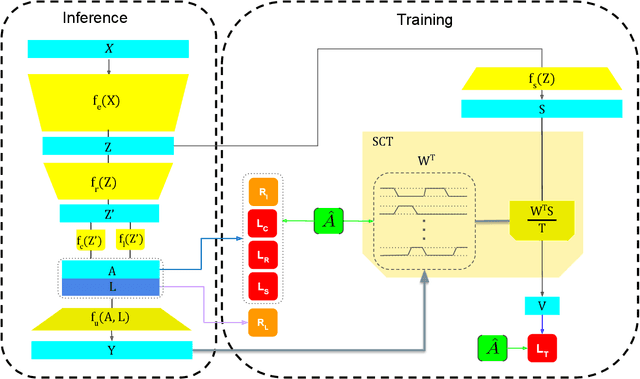


Temporal action segmentation is a topic of increasing interest, however, annotating each frame in a video is cumbersome and costly. Weakly supervised approaches therefore aim at learning temporal action segmentation from videos that are only weakly labeled. In this work, we assume that for each training video only the list of actions is given that occur in the video, but not when, how often, and in which order they occur. In order to address this task, we propose an approach that can be trained end-to-end on such data. The approach divides the video into smaller temporal regions and predicts for each region the action label and its length. In addition, the network estimates the action labels for each frame. By measuring how consistent the frame-wise predictions are with respect to the temporal regions and the annotated action labels, the network learns to divide a video into class-consistent regions. We evaluate our approach on three datasets where the approach achieves state-of-the-art results.
Discovering Latent Classes for Semi-Supervised Semantic Segmentation
Dec 30, 2019
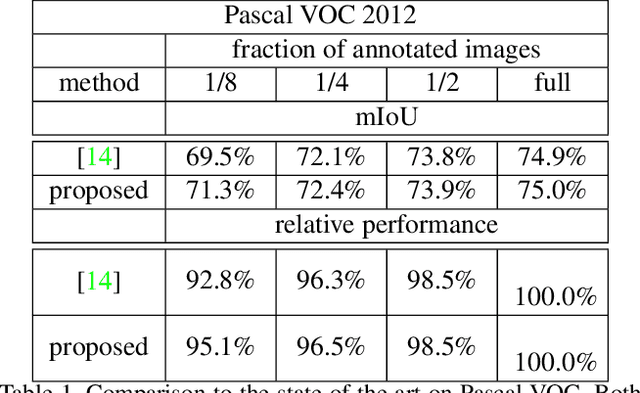
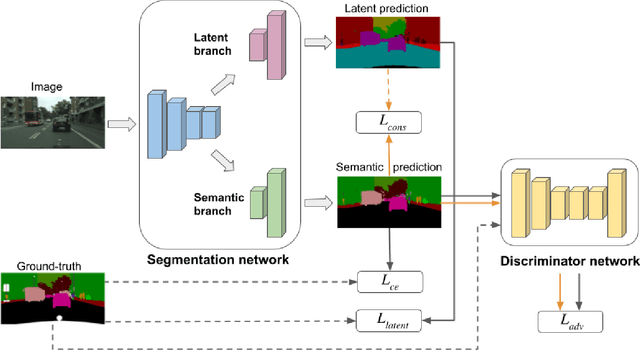
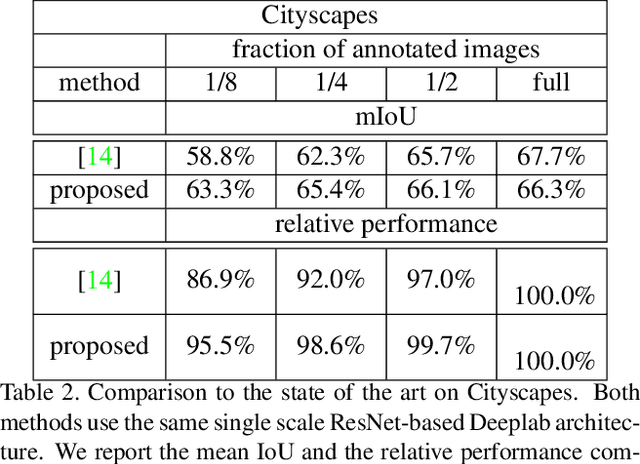
High annotation costs are a major bottleneck for the training of semantic segmentation systems. Therefore, methods working with less annotation effort are of special interest. This paper studies the problem of semi-supervised semantic segmentation. This means that only a small subset of the training images is annotated while the other training images do not contain any annotation. In order to leverage the information present in the unlabeled images, we propose to learn a second task that is related to semantic segmentation but easier. On labeled images, we learn latent classes consistent with semantic classes so that the variety of semantic classes assigned to a latent class is as low as possible. On unlabeled images, we predict a probability map for latent classes and use it as a supervision signal to learn semantic segmentation. The latent classes, as well as the semantic classes, are simultaneously predicted by a two-branch network. In our experiments on Pascal VOC and Cityscapes, we show that the latent classes learned this way have an intuitive meaning and that the proposed method achieves state of the art results for semi-supervised semantic segmentation.
Human Motion Anticipation with Symbolic Label
Dec 13, 2019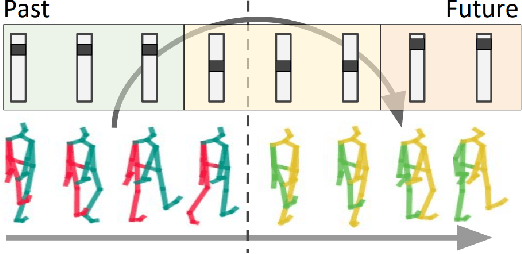
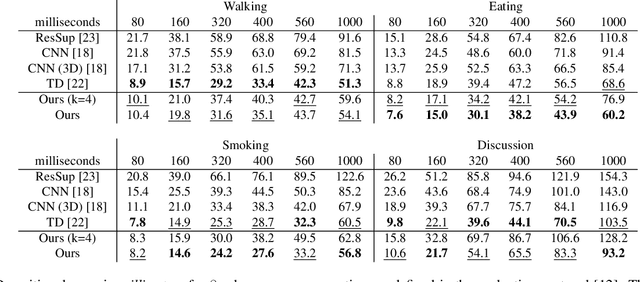
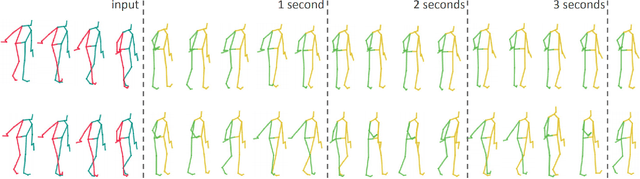
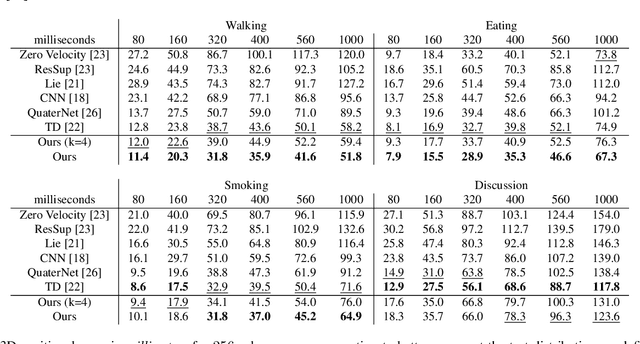
Anticipating human motion depends on two factors: the past motion and the person's intention. While the first factor has been extensively utilized to forecast short sequences of human motion, the second one remains elusive. In this work we approximate a person's intention via a symbolic representation, for example fine-grained action labels such as walking or sitting down. Forecasting a symbolic representation is much easier than forecasting the full body pose with its complex inter-dependencies. However, knowing the future actions makes forecasting human motion easier. We exploit this connection by first anticipating symbolic labels and then generate human motion, conditioned on the human motion input sequence as well as on the forecast labels. This allows the model to anticipate motion changes many steps ahead and adapt the poses accordingly. We achieve state-of-the-art results on short-term as well as on long-term human motion forecasting.
Bonn Activity Maps: Dataset Description
Dec 13, 2019
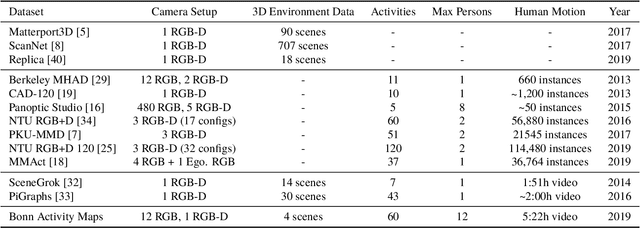


The key prerequisite for accessing the huge potential of current machine learning techniques is the availability of large databases that capture the complex relations of interest. Previous datasets are focused on either 3D scene representations with semantic information, tracking of multiple persons and recognition of their actions, or activity recognition of a single person in captured 3D environments. We present Bonn Activity Maps, a large-scale dataset for human tracking, activity recognition and anticipation of multiple persons. Our dataset comprises four different scenes that have been recorded by time-synchronized cameras each only capturing the scene partially, the reconstructed 3D models with semantic annotations, motion trajectories for individual people including 3D human poses as well as human activity annotations. We utilize the annotations to generate activity likelihoods on the 3D models called activity maps.
Joint Viewpoint and Keypoint Estimation with Real and Synthetic Data
Dec 13, 2019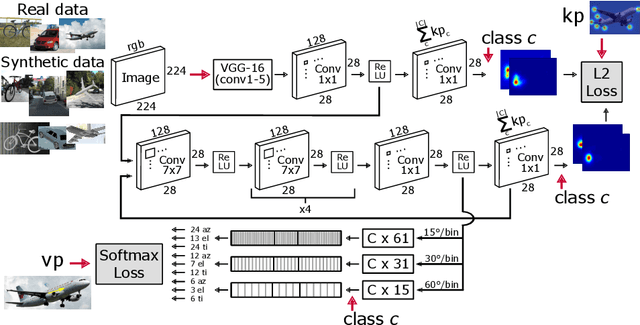
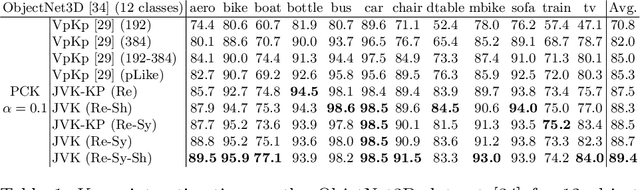
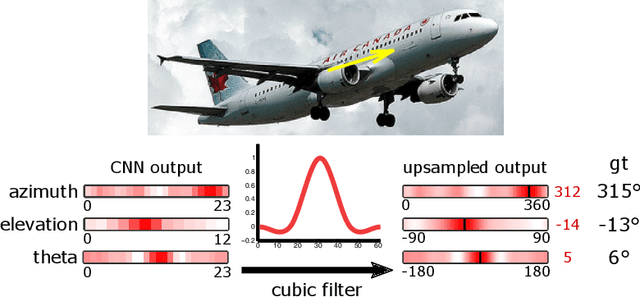
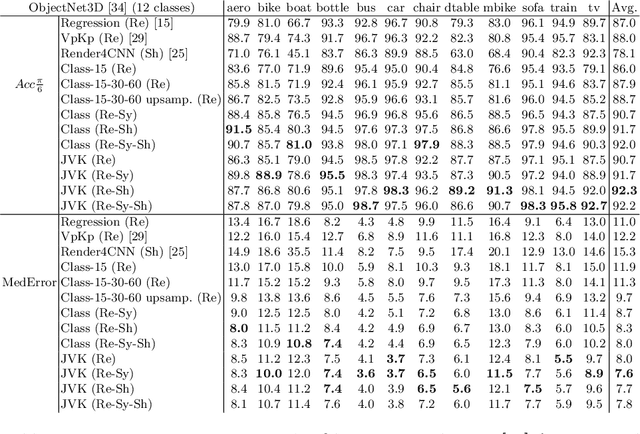
The estimation of viewpoints and keypoints effectively enhance object detection methods by extracting valuable traits of the object instances. While the output of both processes differ, i.e., angles vs. list of characteristic points, they indeed share the same focus on how the object is placed in the scene, inducing that there is a certain level of correlation between them. Therefore, we propose a convolutional neural network that jointly computes the viewpoint and keypoints for different object categories. By training both tasks together, each task improves the accuracy of the other. Since the labelling of object keypoints is very time consuming for human annotators, we also introduce a new synthetic dataset with automatically generated viewpoint and keypoints annotations. Our proposed network can also be trained on datasets that contain viewpoint and keypoints annotations or only one of them. The experiments show that the proposed approach successfully exploits this implicit correlation between the tasks and outperforms previous techniques that are trained independently.
* 11 pages, 4 figures
Cross-modal knowledge distillation for action recognition
Oct 10, 2019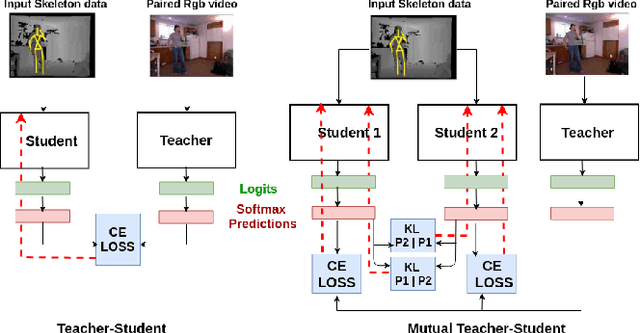


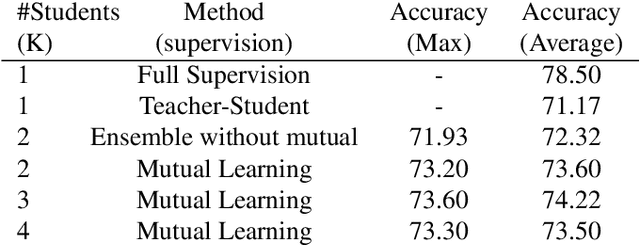
In this work, we address the problem how a network for action recognition that has been trained on a modality like RGB videos can be adapted to recognize actions for another modality like sequences of 3D human poses. To this end, we extract the knowledge of the trained teacher network for the source modality and transfer it to a small ensemble of student networks for the target modality. For the cross-modal knowledge distillation, we do not require any annotated data. Instead we use pairs of sequences of both modalities as supervision, which are straightforward to acquire. In contrast to previous works for knowledge distillation that use a KL-loss, we show that the cross-entropy loss together with mutual learning of a small ensemble of student networks performs better. In fact, the proposed approach for cross-modal knowledge distillation nearly achieves the accuracy of a student network trained with full supervision.
Uncertainty-Aware Anticipation of Activities
Aug 29, 2019
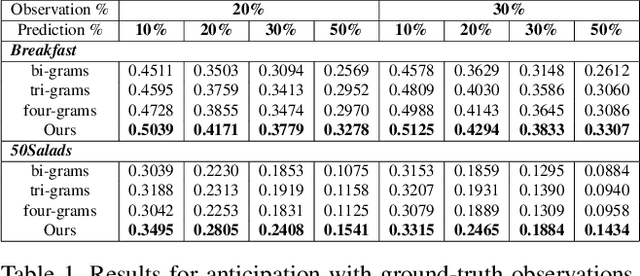
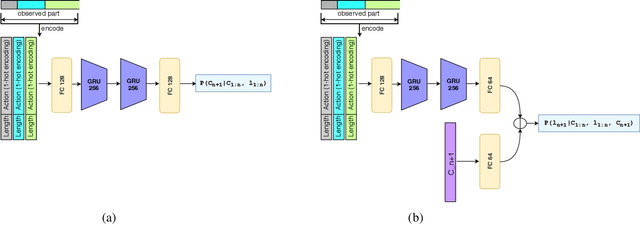
Anticipating future activities in video is a task with many practical applications. While earlier approaches are limited to just a few seconds in the future, the prediction time horizon has just recently been extended to several minutes in the future. However, as increasing the predicted time horizon, the future becomes more uncertain and models that generate a single prediction fail at capturing the different possible future activities. In this paper, we address the uncertainty modelling for predicting long-term future activities. Both an action model and a length model are trained to model the probability distribution of the future activities. At test time, we sample from the predicted distributions multiple samples that correspond to the different possible sequences of future activities. Our model is evaluated on two challenging datasets and shows a good performance in capturing the multi-modal future activities without compromising the accuracy when predicting a single sequence of future activities.