 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Deep Learning DeepFake Detection Integrating Handcrafted Features
Jul 28, 2025



The rapid advancement of deepfake and face swap technologies has raised significant concerns in digital security, particularly in identity verification and onboarding processes. Conventional detection methods often struggle to generalize against sophisticated facial manipulations. This study proposes an enhanced deep-learning detection framework that combines handcrafted frequency-domain features with conventional RGB inputs. This hybrid approach exploits frequency and spatial domain artifacts introduced during image manipulation, providing richer and more discriminative information to the classifier. Several frequency handcrafted features were evaluated, including the Steganalysis Rich Model, Discrete Cosine Transform, Error Level Analysis, Singular Value Decomposition, and Discrete Fourier Transform
Second Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
Few-Shot Learning: Expanding ID Cards Presentation Attack Detection to Unknown ID Countries
Sep 10, 2024This paper proposes a Few-shot Learning (FSL) approach for detecting Presentation Attacks on ID Cards deployed in a remote verification system and its extension to new countries. Our research analyses the performance of Prototypical Networks across documents from Spain and Chile as a baseline and measures the extension of generalisation capabilities of new ID Card countries such as Argentina and Costa Rica. Specifically targeting the challenge of screen display presentation attacks. By leveraging convolutional architectures and meta-learning principles embodied in Prototypical Networks, we have crafted a model that demonstrates high efficacy with Few-shot examples. This research reveals that competitive performance can be achieved with as Few-shots as five unique identities and with under 100 images per new country added. This opens a new insight for novel generalised Presentation Attack Detection on ID cards to unknown attacks.
First Competition on Presentation Attack Detection on ID Card
Aug 31, 2024



This paper summarises the Competition on Presentation Attack Detection on ID Cards (PAD-IDCard) held at the 2024 International Joint Conference on Biometrics (IJCB2024). The competition attracted a total of ten registered teams, both from academia and industry. In the end, the participating teams submitted five valid submissions, with eight models to be evaluated by the organisers. The competition presented an independent assessment of current state-of-the-art algorithms. Today, no independent evaluation on cross-dataset is available; therefore, this work determined the state-of-the-art on ID cards. To reach this goal, a sequestered test set and baseline algorithms were used to evaluate and compare all the proposals. The sequestered test dataset contains ID cards from four different countries. In summary, a team that chose to be "Anonymous" reached the best average ranking results of 74.80%, followed very closely by the "IDVC" team with 77.65%.
Open-Set: ID Card Presentation Attack Detection using Neural Transfer Style
Dec 21, 2023The accurate detection of ID card Presentation Attacks (PA) is becoming increasingly important due to the rising number of online/remote services that require the presentation of digital photographs of ID cards for digital onboarding or authentication. Furthermore, cybercriminals are continuously searching for innovative ways to fool authentication systems to gain unauthorized access to these services. Although advances in neural network design and training have pushed image classification to the state of the art, one of the main challenges faced by the development of fraud detection systems is the curation of representative datasets for training and evaluation. The handcrafted creation of representative presentation attack samples often requires expertise and is very time-consuming, thus an automatic process of obtaining high-quality data is highly desirable. This work explores ID card Presentation Attack Instruments (PAI) in order to improve the generation of samples with four Generative Adversarial Networks (GANs) based image translation models and analyses the effectiveness of the generated data for training fraud detection systems. Using open-source data, we show that synthetic attack presentations are an adequate complement for additional real attack presentations, where we obtain an EER performance increase of 0.63% points for print attacks and a loss of 0.29% for screen capture attacks.
PANACEA cough sound-based diagnosis of COVID-19 for the DiCOVA 2021 Challenge
Jun 07, 2021
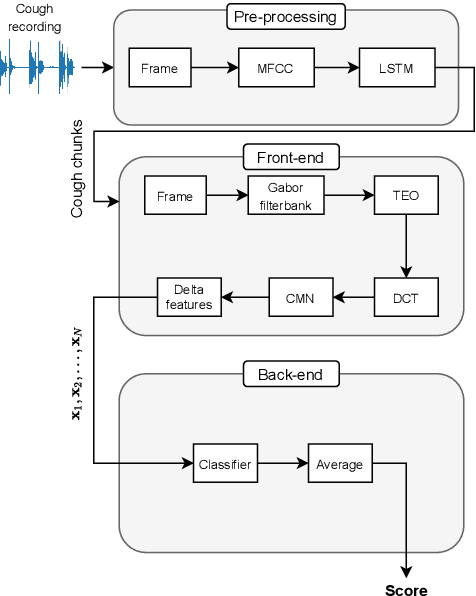
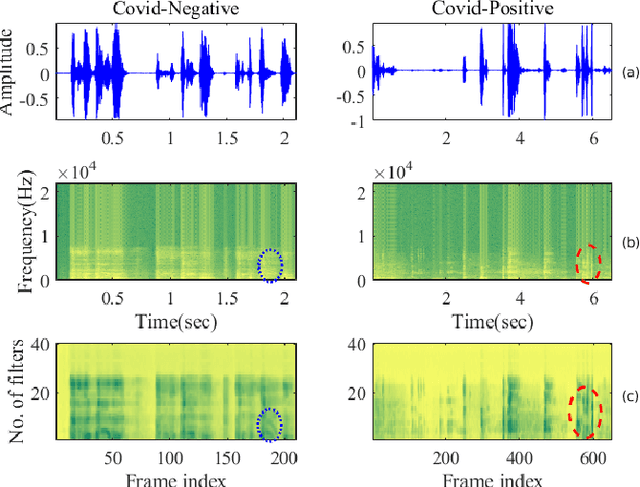
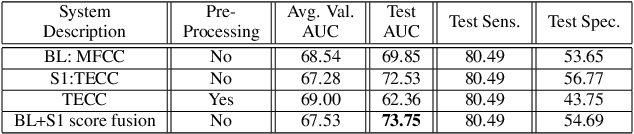
The COVID-19 pandemic has led to the saturation of public health services worldwide. In this scenario, the early diagnosis of SARS-Cov-2 infections can help to stop or slow the spread of the virus and to manage the demand upon health services. This is especially important when resources are also being stretched by heightened demand linked to other seasonal diseases, such as the flu. In this context, the organisers of the DiCOVA 2021 challenge have collected a database with the aim of diagnosing COVID-19 through the use of coughing audio samples. This work presents the details of the automatic system for COVID-19 detection from cough recordings presented by team PANACEA. This team consists of researchers from two European academic institutions and one company: EURECOM (France), University of Granada (Spain), and Biometric Vox S.L. (Spain). We developed several systems based on established signal processing and machine learning methods. Our best system employs a Teager energy operator cepstral coefficients (TECCs) based frontend and Light gradient boosting machine (LightGBM) backend. The AUC obtained by this system on the test set is 76.31% which corresponds to a 10% improvement over the official baseline.