 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving and Diagnosing Knowledge-Based Visual Question Answering via Entity Enhanced Knowledge Injection
Dec 13, 2021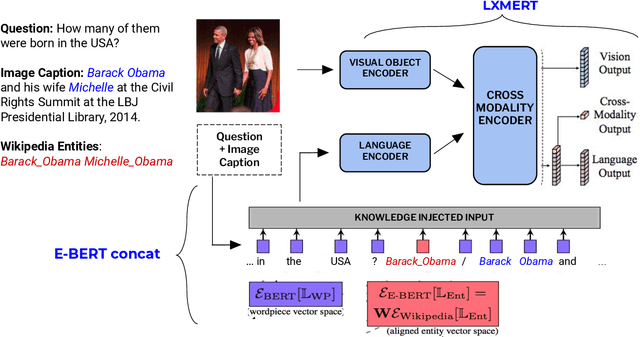
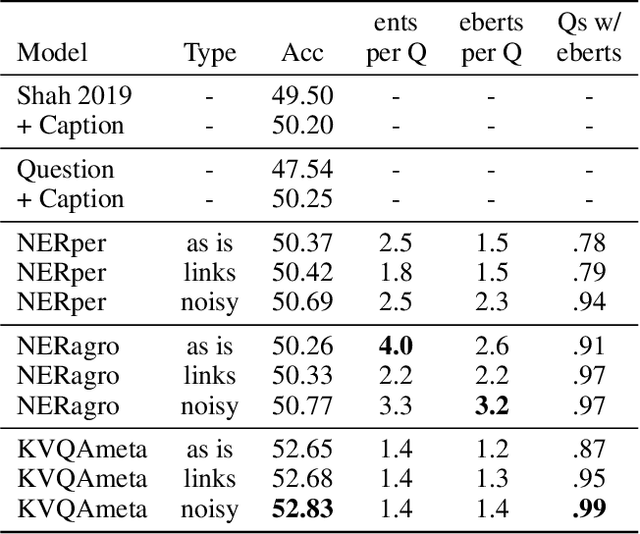
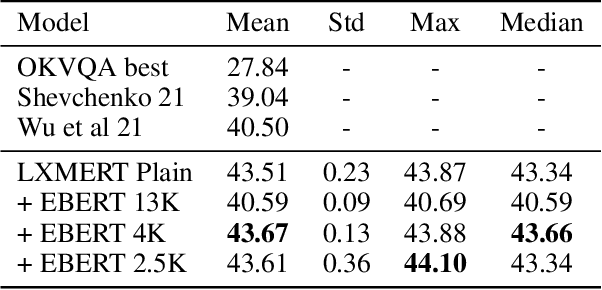
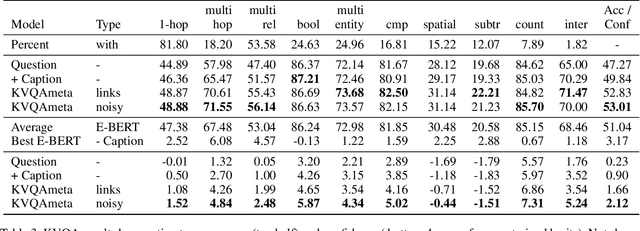
Knowledge-Based Visual Question Answering (KBVQA) is a bi-modal task requiring external world knowledge in order to correctly answer a text question and associated image. Recent single modality text work has shown knowledge injection into pre-trained language models, specifically entity enhanced knowledge graph embeddings, can improve performance on downstream entity-centric tasks. In this work, we empirically study how and whether such methods, applied in a bi-modal setting, can improve an existing VQA system's performance on the KBVQA task. We experiment with two large publicly available VQA datasets, (1) KVQA which contains mostly rare Wikipedia entities and (2) OKVQA which is less entity-centric and more aligned with common sense reasoning. Both lack explicit entity spans and we study the effect of different weakly supervised and manual methods for obtaining them. Additionally we analyze how recently proposed bi-modal and single modal attention explanations are affected by the incorporation of such entity enhanced representations. Our results show substantial improved performance on the KBVQA task without the need for additional costly pre-training and we provide insights for when entity knowledge injection helps improve a model's understanding. We provide code and enhanced datasets for reproducibility.
Biomedical Interpretable Entity Representations
Jun 17, 2021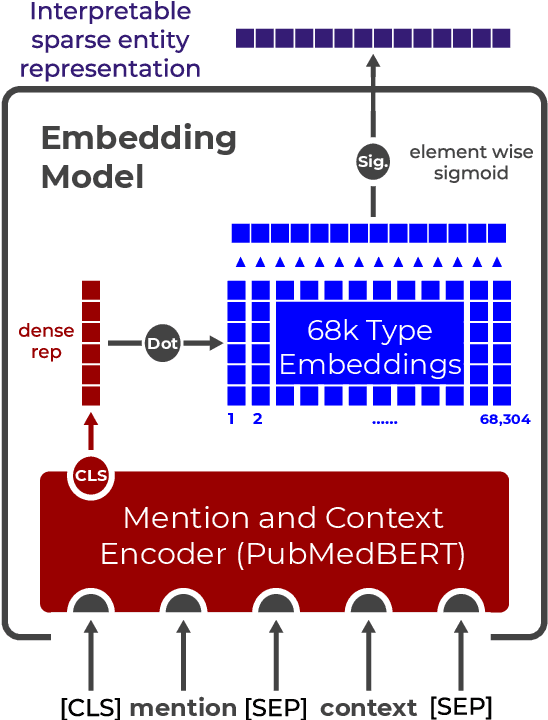
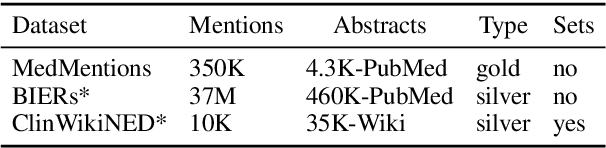
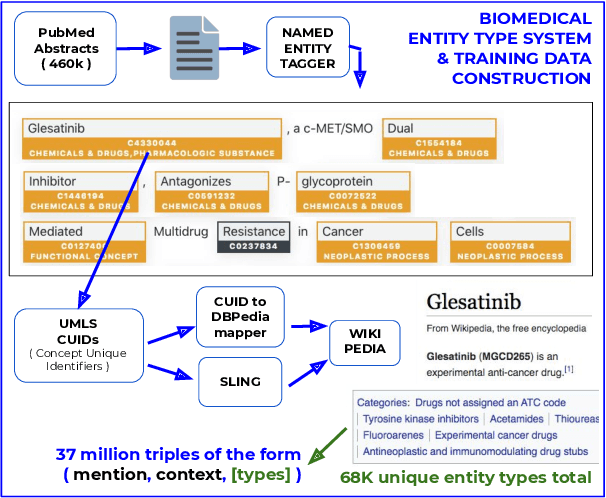
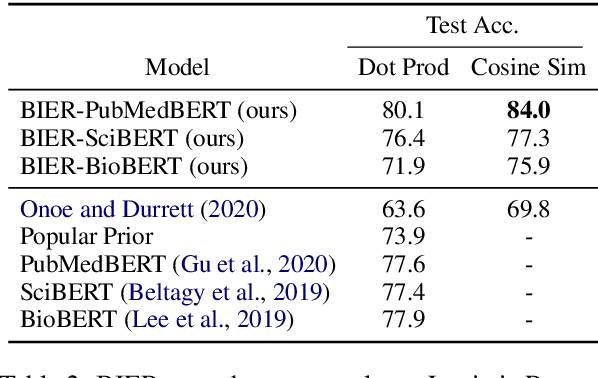
Pre-trained language models induce dense entity representations that offer strong performance on entity-centric NLP tasks, but such representations are not immediately interpretable. This can be a barrier to model uptake in important domains such as biomedicine. There has been recent work on general interpretable representation learning (Onoe and Durrett, 2020), but these domain-agnostic representations do not readily transfer to the important domain of biomedicine. In this paper, we create a new entity type system and training set from a large corpus of biomedical texts by mapping entities to concepts in a medical ontology, and from these to Wikipedia pages whose categories are our types. From this mapping we derive Biomedical Interpretable Entity Representations(BIERs), in which dimensions correspond to fine-grained entity types, and values are predicted probabilities that a given entity is of the corresponding type. We propose a novel method that exploits BIER's final sparse and intermediate dense representations to facilitate model and entity type debugging. We show that BIERs achieve strong performance in biomedical tasks including named entity disambiguation and entity label classification, and we provide error analysis to highlight the utility of their interpretability, particularly in low-supervision settings. Finally, we provide our induced 68K biomedical type system, the corresponding 37 million triples of derived data used to train BIER models and our best performing model.
Simultaneously Reconciled Quantile Forecasting of Hierarchically Related Time Series
Feb 25, 2021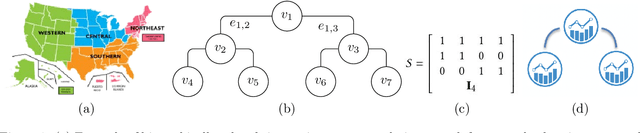
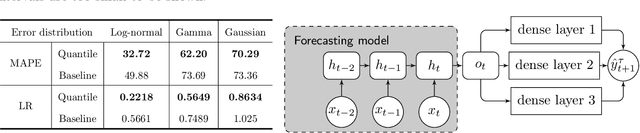
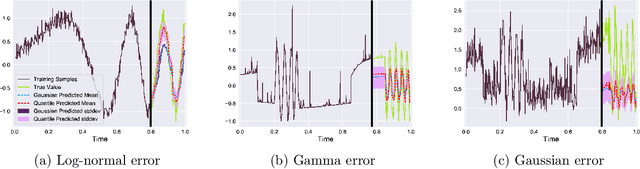
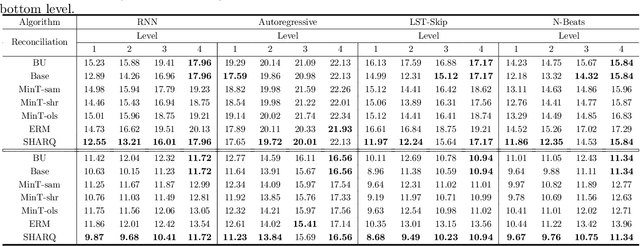
Many real-life applications involve simultaneously forecasting multiple time series that are hierarchically related via aggregation or disaggregation operations. For instance, commercial organizations often want to forecast inventories simultaneously at store, city, and state levels for resource planning purposes. In such applications, it is important that the forecasts, in addition to being reasonably accurate, are also consistent w.r.t one another. Although forecasting such hierarchical time series has been pursued by economists and data scientists, the current state-of-the-art models use strong assumptions, e.g., all forecasts being unbiased estimates, noise distribution being Gaussian. Besides, state-of-the-art models have not harnessed the power of modern nonlinear models, especially ones based on deep learning. In this paper, we propose using a flexible nonlinear model that optimizes quantile regression loss coupled with suitable regularization terms to maintain the consistency of forecasts across hierarchies. The theoretical framework introduced herein can be applied to any forecasting model with an underlying differentiable loss function. A proof of optimality of our proposed method is also provided. Simulation studies over a range of datasets highlight the efficacy of our approach.
Biased Models Have Biased Explanations
Dec 20, 2020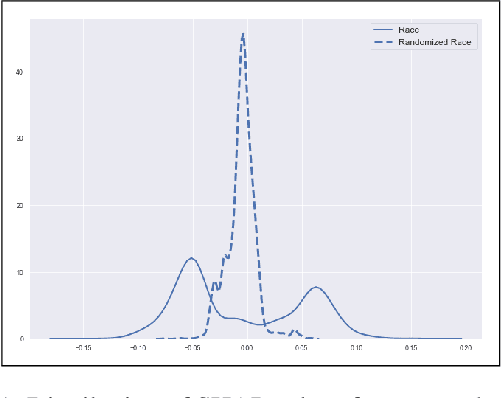

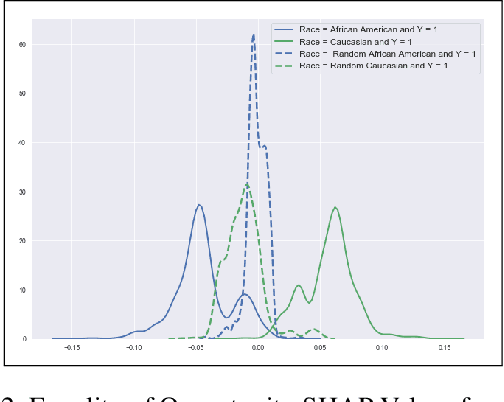

We study fairness in Machine Learning (FairML) through the lens of attribute-based explanations generated for machine learning models. Our hypothesis is: Biased Models have Biased Explanations. To establish that, we first translate existing statistical notions of group fairness and define these notions in terms of explanations given by the model. Then, we propose a novel way of detecting (un)fairness for any black box model. We further look at post-processing techniques for fairness and reason how explanations can be used to make a bias mitigation technique more individually fair. We also introduce a novel post-processing mitigation technique which increases individual fairness in recourse while maintaining group level fairness.
FaiR-N: Fair and Robust Neural Networks for Structured Data
Oct 13, 2020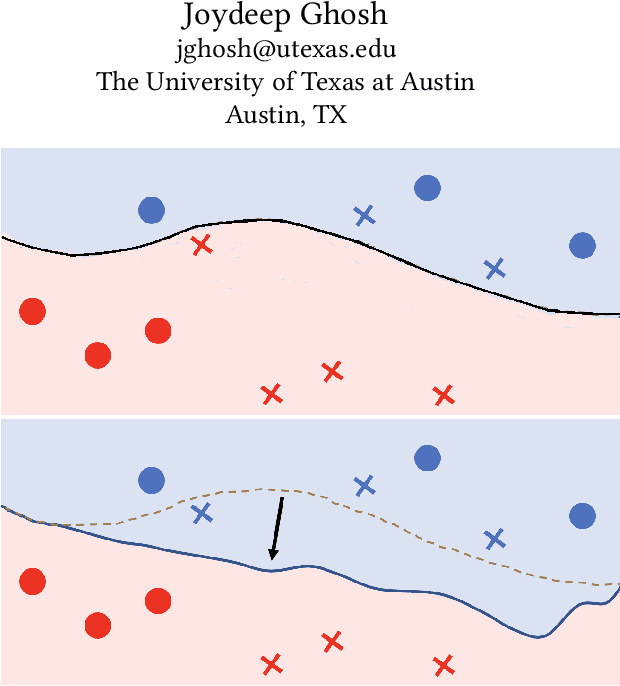

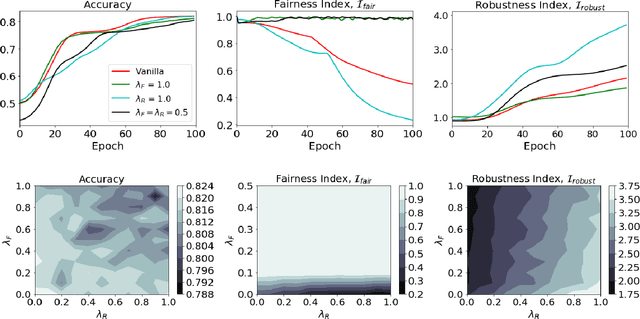
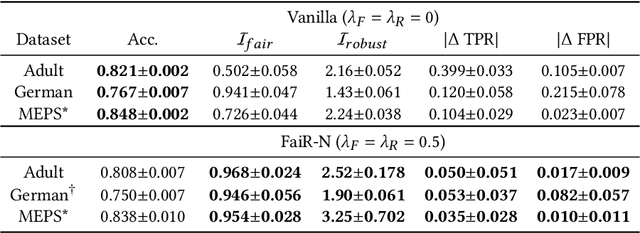
Fairness in machine learning is crucial when individuals are subject to automated decisions made by models in high-stake domains. Organizations that employ these models may also need to satisfy regulations that promote responsible and ethical A.I. While fairness metrics relying on comparing model error rates across subpopulations have been widely investigated for the detection and mitigation of bias, fairness in terms of the equalized ability to achieve recourse for different protected attribute groups has been relatively unexplored. We present a novel formulation for training neural networks that considers the distance of data points to the decision boundary such that the new objective: (1) reduces the average distance to the decision boundary between two groups for individuals subject to a negative outcome in each group, i.e. the network is more fair with respect to the ability to obtain recourse, and (2) increases the average distance of data points to the boundary to promote adversarial robustness. We demonstrate that training with this loss yields more fair and robust neural networks with similar accuracies to models trained without it. Moreover, we qualitatively motivate and empirically show that reducing recourse disparity across groups also improves fairness measures that rely on error rates. To the best of our knowledge, this is the first time that recourse capabilities across groups are considered to train fairer neural networks, and a relation between error rates based fairness and recourse based fairness is investigated.
Explainable Machine Learning in Deployment
Sep 13, 2019
Explainable machine learning seeks to provide various stakeholders with insights into model behavior via feature importance scores, counterfactual explanations, and influential samples, among other techniques. Recent advances in this line of work, however, have gone without surveys of how organizations are using these techniques in practice. This study explores how organizations view and use explainability for stakeholder consumption. We find that the majority of deployments are not for end users affected by the model but for machine learning engineers, who use explainability to debug the model itself. There is a gap between explainability in practice and the goal of public transparency, since explanations primarily serve internal stakeholders rather than external ones. Our study synthesizes the limitations with current explainability techniques that hamper their use for end users. To facilitate end user interaction, we develop a framework for establishing clear goals for explainability, including a focus on normative desiderata.
Vehicular Multi-object Tracking with Persistent Detector Failures
Jul 25, 2019


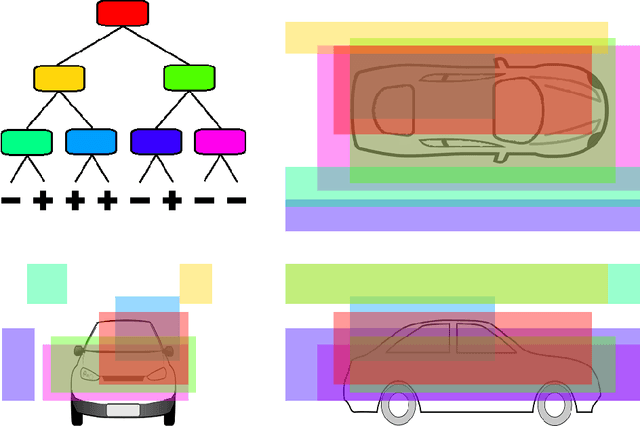
Autonomous vehicles often perceive the environment by feeding sensor data to a learned detector algorithm, then feeding detections to a multi-object tracker that models object motions over time. Probabilistic models of multi-object trackers typically assume that errors in the detector algorithm occur randomly over time. We instead assume that undetected objects and false detections will persist in certain conditions, and modify the tracking framework to account for them. The modifications are tested with a novel lidar-based vehicle detector, and shown to enable real-time detection and tracking without specialized computing hardware.
Towards Realistic Individual Recourse and Actionable Explanations in Black-Box Decision Making Systems
Jul 22, 2019
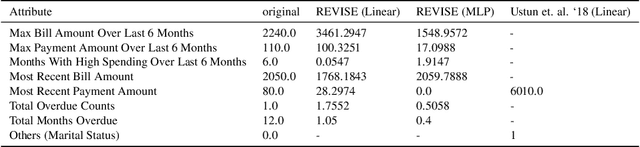
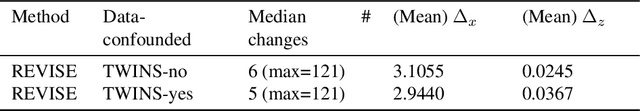
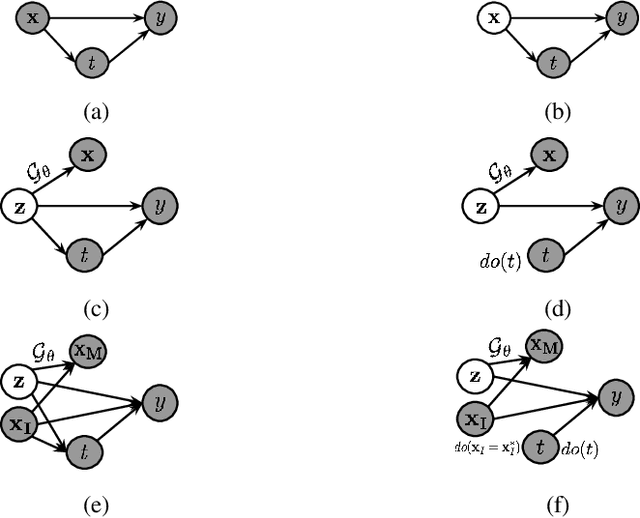
Machine learning based decision making systems are increasingly affecting humans. An individual can suffer an undesirable outcome under such decision making systems (e.g. denied credit) irrespective of whether the decision is fair or accurate. Individual recourse pertains to the problem of providing an actionable set of changes a person can undertake in order to improve their outcome. We propose a recourse algorithm that models the underlying data distribution or manifold. We then provide a mechanism to generate the smallest set of changes that will improve an individual's outcome. This mechanism can be easily used to provide recourse for any differentiable machine learning based decision making system. Further, the resulting algorithm is shown to be applicable to both supervised classification and causal decision making systems. Our work attempts to fill gaps in existing fairness literature that have primarily focused on discovering and/or algorithmically enforcing fairness constraints on decision making systems. This work also provides an alternative approach to generating counterfactual explanations.
Learning More From Less: Towards Strengthening Weak Supervision for Ad-Hoc Retrieval
Jul 19, 2019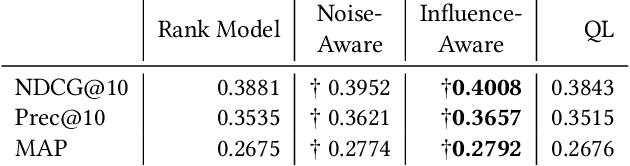
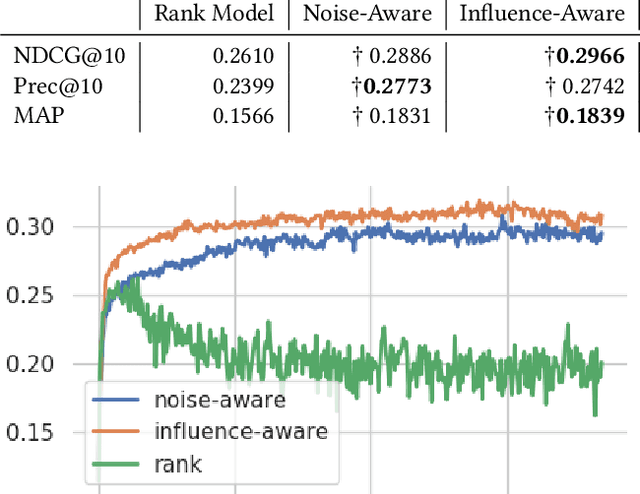
The limited availability of ground truth relevance labels has been a major impediment to the application of supervised methods to ad-hoc retrieval. As a result, unsupervised scoring methods, such as BM25, remain strong competitors to deep learning techniques which have brought on dramatic improvements in other domains, such as computer vision and natural language processing. Recent works have shown that it is possible to take advantage of the performance of these unsupervised methods to generate training data for learning-to-rank models. The key limitation to this line of work is the size of the training set required to surpass the performance of the original unsupervised method, which can be as large as $10^{13}$ training examples. Building on these insights, we propose two methods to reduce the amount of training data required. The first method takes inspiration from crowdsourcing, and leverages multiple unsupervised rankers to generate soft, or noise-aware, training labels. The second identifies harmful, or mislabeled, training examples and removes them from the training set. We show that our methods allow us to surpass the performance of the unsupervised baseline with far fewer training examples than previous works.
On Single Source Robustness in Deep Fusion Models
Jun 11, 2019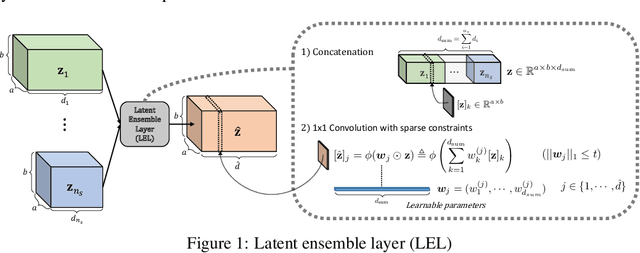
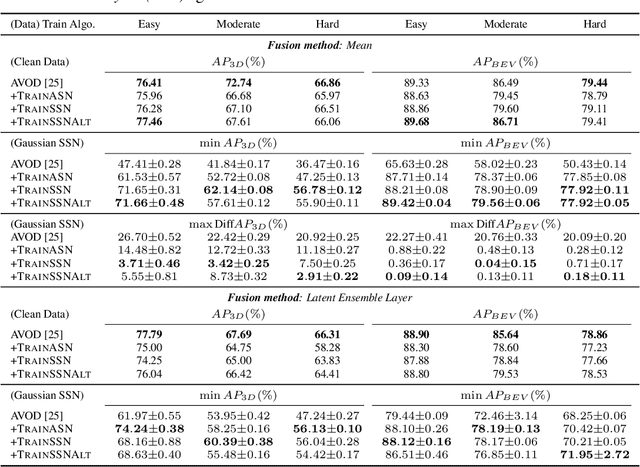

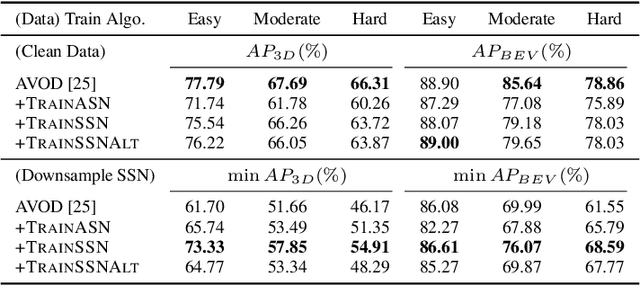
Algorithms that fuse multiple input sources benefit from both complementary and shared information. Shared information may provide robustness to faulty or noisy inputs, which is indispensable for safety-critical applications like self-driving cars. We investigate learning fusion algorithms that are robust against noise added to a single source. We first demonstrate that robustness against single source noise is not guaranteed in a linear fusion model. Motivated by this discovery, two possible approaches are proposed to increase robustness: a carefully designed loss with corresponding training algorithms for deep fusion models, and a simple convolutional fusion layer that has a structural advantage in dealing with noise. Experimental results show that both training algorithms and our fusion layer make a deep fusion-based 3D object detector robust against noise applied to a single source, while preserving the original performance on clean data.