 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the benefits of pixel-based hierarchical policies for task generalization
Jul 27, 2024



Reinforcement learning practitioners often avoid hierarchical policies, especially in image-based observation spaces. Typically, the single-task performance improvement over flat-policy counterparts does not justify the additional complexity associated with implementing a hierarchy. However, by introducing multiple decision-making levels, hierarchical policies can compose lower-level policies to more effectively generalize between tasks, highlighting the need for multi-task evaluations. We analyze the benefits of hierarchy through simulated multi-task robotic control experiments from pixels. Our results show that hierarchical policies trained with task conditioning can (1) increase performance on training tasks, (2) lead to improved reward and state-space generalizations in similar tasks, and (3) decrease the complexity of fine tuning required to solve novel tasks. Thus, we believe that hierarchical policies should be considered when building reinforcement learning architectures capable of generalizing between tasks.
Improving GFlowNets for Text-to-Image Diffusion Alignment
Jun 02, 2024



Diffusion models have become the \textit{de-facto} approach for generating visual data, which are trained to match the distribution of the training dataset. In addition, we also want to control generation to fulfill desired properties such as alignment to a text description, which can be specified with a black-box reward function. Prior works fine-tune pretrained diffusion models to achieve this goal through reinforcement learning-based algorithms. Nonetheless, they suffer from issues including slow credit assignment as well as low quality in their generated samples. In this work, we explore techniques that do not directly maximize the reward but rather generate high-reward images with relatively high probability -- a natural scenario for the framework of generative flow networks (GFlowNets). To this end, we propose the \textbf{D}iffusion \textbf{A}lignment with \textbf{G}FlowNet (DAG) algorithm to post-train diffusion models with black-box property functions. Extensive experiments on Stable Diffusion and various reward specifications corroborate that our method could effectively align large-scale text-to-image diffusion models with given reward information.
How Far Are We from Intelligent Visual Deductive Reasoning?
Mar 08, 2024



Vision-Language Models (VLMs) such as GPT-4V have recently demonstrated incredible strides on diverse vision language tasks. We dig into vision-based deductive reasoning, a more sophisticated but less explored realm, and find previously unexposed blindspots in the current SOTA VLMs. Specifically, we leverage Raven's Progressive Matrices (RPMs), to assess VLMs' abilities to perform multi-hop relational and deductive reasoning relying solely on visual clues. We perform comprehensive evaluations of several popular VLMs employing standard strategies such as in-context learning, self-consistency, and Chain-of-thoughts (CoT) on three diverse datasets, including the Mensa IQ test, IntelligenceTest, and RAVEN. The results reveal that despite the impressive capabilities of LLMs in text-based reasoning, we are still far from achieving comparable proficiency in visual deductive reasoning. We found that certain standard strategies that are effective when applied to LLMs do not seamlessly translate to the challenges presented by visual reasoning tasks. Moreover, a detailed analysis reveals that VLMs struggle to solve these tasks mainly because they are unable to perceive and comprehend multiple, confounding abstract patterns in RPM examples.
Overcoming the Pitfalls of Vision-Language Model Finetuning for OOD Generalization
Jan 29, 2024



Existing vision-language models exhibit strong generalization on a variety of visual domains and tasks. However, such models mainly perform zero-shot recognition in a closed-set manner, and thus struggle to handle open-domain visual concepts by design. There are recent finetuning methods, such as prompt learning, that not only study the discrimination between in-distribution (ID) and out-of-distribution (OOD) samples, but also show some improvements in both ID and OOD accuracies. In this paper, we first demonstrate that vision-language models, after long enough finetuning but without proper regularization, tend to overfit the known classes in the given dataset, with degraded performance on unknown classes. Then we propose a novel approach OGEN to address this pitfall, with the main focus on improving the OOD GENeralization of finetuned models. Specifically, a class-conditional feature generator is introduced to synthesize OOD features using just the class name of any unknown class. Such synthesized features will provide useful knowledge about unknowns and help regularize the decision boundary between ID and OOD data when optimized jointly. Equally important is our adaptive self-distillation mechanism to regularize our feature generation model during joint optimization, i.e., adaptively transferring knowledge between model states to further prevent overfitting. Experiments validate that our method yields convincing gains in OOD generalization performance in different settings.
What Algorithms can Transformers Learn? A Study in Length Generalization
Oct 24, 2023



Large language models exhibit surprising emergent generalization properties, yet also struggle on many simple reasoning tasks such as arithmetic and parity. This raises the question of if and when Transformer models can learn the true algorithm for solving a task. We study the scope of Transformers' abilities in the specific setting of length generalization on algorithmic tasks. Here, we propose a unifying framework to understand when and how Transformers can exhibit strong length generalization on a given task. Specifically, we leverage RASP (Weiss et al., 2021) -- a programming language designed for the computational model of a Transformer -- and introduce the RASP-Generalization Conjecture: Transformers tend to length generalize on a task if the task can be solved by a short RASP program which works for all input lengths. This simple conjecture remarkably captures most known instances of length generalization on algorithmic tasks. Moreover, we leverage our insights to drastically improve generalization performance on traditionally hard tasks (such as parity and addition). On the theoretical side, we give a simple example where the "min-degree-interpolator" model of learning from Abbe et al. (2023) does not correctly predict Transformers' out-of-distribution behavior, but our conjecture does. Overall, our work provides a novel perspective on the mechanisms of compositional generalization and the algorithmic capabilities of Transformers.
Matryoshka Diffusion Models
Oct 23, 2023Diffusion models are the de facto approach for generating high-quality images and videos, but learning high-dimensional models remains a formidable task due to computational and optimization challenges. Existing methods often resort to training cascaded models in pixel space or using a downsampled latent space of a separately trained auto-encoder. In this paper, we introduce Matryoshka Diffusion Models(MDM), an end-to-end framework for high-resolution image and video synthesis. We propose a diffusion process that denoises inputs at multiple resolutions jointly and uses a NestedUNet architecture where features and parameters for small-scale inputs are nested within those of large scales. In addition, MDM enables a progressive training schedule from lower to higher resolutions, which leads to significant improvements in optimization for high-resolution generation. We demonstrate the effectiveness of our approach on various benchmarks, including class-conditioned image generation, high-resolution text-to-image, and text-to-video applications. Remarkably, we can train a single pixel-space model at resolutions of up to 1024x1024 pixels, demonstrating strong zero-shot generalization using the CC12M dataset, which contains only 12 million images.
Generative Modeling with Phase Stochastic Bridges
Oct 13, 2023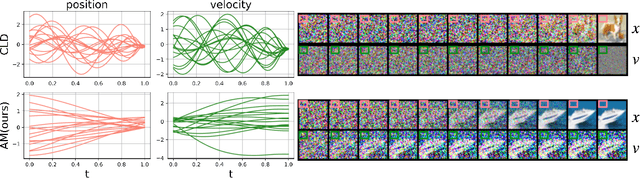

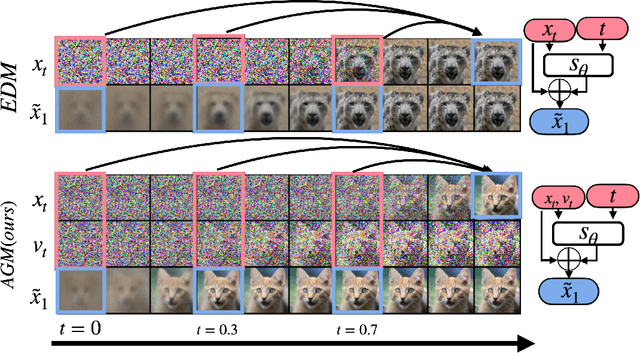

Diffusion models (DMs) represent state-of-the-art generative models for continuous inputs. DMs work by constructing a Stochastic Differential Equation (SDE) in the input space (ie, position space), and using a neural network to reverse it. In this work, we introduce a novel generative modeling framework grounded in \textbf{phase space dynamics}, where a phase space is defined as {an augmented space encompassing both position and velocity.} Leveraging insights from Stochastic Optimal Control, we construct a path measure in the phase space that enables efficient sampling. {In contrast to DMs, our framework demonstrates the capability to generate realistic data points at an early stage of dynamics propagation.} This early prediction sets the stage for efficient data generation by leveraging additional velocity information along the trajectory. On standard image generation benchmarks, our model yields favorable performance over baselines in the regime of small Number of Function Evaluations (NFEs). Furthermore, our approach rivals the performance of diffusion models equipped with efficient sampling techniques, underscoring its potential as a new tool generative modeling.
Adaptivity and Modularity for Efficient Generalization Over Task Complexity
Oct 13, 2023



Can transformers generalize efficiently on problems that require dealing with examples with different levels of difficulty? We introduce a new task tailored to assess generalization over different complexities and present results that indicate that standard transformers face challenges in solving these tasks. These tasks are variations of pointer value retrieval previously introduced by Zhang et al. (2021). We investigate how the use of a mechanism for adaptive and modular computation in transformers facilitates the learning of tasks that demand generalization over the number of sequential computation steps (i.e., the depth of the computation graph). Based on our observations, we propose a transformer-based architecture called Hyper-UT, which combines dynamic function generation from hyper networks with adaptive depth from Universal Transformers. This model demonstrates higher accuracy and a fairer allocation of computational resources when generalizing to higher numbers of computation steps. We conclude that mechanisms for adaptive depth and modularity complement each other in improving efficient generalization concerning example complexity. Additionally, to emphasize the broad applicability of our findings, we illustrate that in a standard image recognition task, Hyper- UT's performance matches that of a ViT model but with considerably reduced computational demands (achieving over 70\% average savings by effectively using fewer layers).
Boolformer: Symbolic Regression of Logic Functions with Transformers
Sep 21, 2023



In this work, we introduce Boolformer, the first Transformer architecture trained to perform end-to-end symbolic regression of Boolean functions. First, we show that it can predict compact formulas for complex functions which were not seen during training, when provided a clean truth table. Then, we demonstrate its ability to find approximate expressions when provided incomplete and noisy observations. We evaluate the Boolformer on a broad set of real-world binary classification datasets, demonstrating its potential as an interpretable alternative to classic machine learning methods. Finally, we apply it to the widespread task of modelling the dynamics of gene regulatory networks. Using a recent benchmark, we show that Boolformer is competitive with state-of-the art genetic algorithms with a speedup of several orders of magnitude. Our code and models are available publicly.
Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation
Sep 20, 2023



Datasets that pair Knowledge Graphs (KG) and text together (KG-T) can be used to train forward and reverse neural models that generate text from KG and vice versa. However models trained on datasets where KG and text pairs are not equivalent can suffer from more hallucination and poorer recall. In this paper, we verify this empirically by generating datasets with different levels of noise and find that noisier datasets do indeed lead to more hallucination. We argue that the ability of forward and reverse models trained on a dataset to cyclically regenerate source KG or text is a proxy for the equivalence between the KG and the text in the dataset. Using cyclic evaluation we find that manually created WebNLG is much better than automatically created TeKGen and T-REx. Guided by these observations, we construct a new, improved dataset called LAGRANGE using heuristics meant to improve equivalence between KG and text and show the impact of each of the heuristics on cyclic evaluation. We also construct two synthetic datasets using large language models (LLMs), and observe that these are conducive to models that perform significantly well on cyclic generation of text, but less so on cyclic generation of KGs, probably because of a lack of a consistent underlying ontology.