 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of RAG and Fine-Tuning for Industrial Question-Answering-Applications
May 10, 2026Large Language Models (LLMs) are increasingly employed in enterprise question-answering (QA) systems, requiring adaptation to domain-specific knowledge. Among the most prevalent methods for incorporating such knowledge are Retrieval-Augmented Generation (RAG) and fine-tuning (FT). Yet, from a cost-accuracy trade-off perspective, it remains unclear which approach best suits industry scenarios. This study examines the impact of RAG and FT on two closed datasets specific to the automotive industry, assessing answer quality and operational costs. We extend the Cost-of-Pass framework proposed by Erol et al. (arXiv:2504.13359) to jointly assess output quality, generation cost, and user interaction cost. Our findings reveal that while premium models perform best out of the box, open-source models can achieve comparable quality when enhanced with RAG. Overall, RAG emerges as the most effective and cost-efficient adaptation method for both closed- and open-source models.
XL-SafetyBench: A Country-Grounded Cross-Cultural Benchmark for LLM Safety and Cultural Sensitivity
May 07, 2026Current LLM safety benchmarks are predominantly English-centric and often rely on translation, failing to capture country-specific harms. Moreover, they rarely evaluate a model's ability to detect culturally embedded sensitivities as distinct from universal harms. We introduce XL-SafetyBench. a suite of 5,500 test cases across 10 country-language pairs, comprising a Jailbreak Benchmark of country-grounded adversarial prompts and a Cultural Benchmark where local sensitivities are embedded within innocuous requests. Each item is constructed via a multi-stage pipeline that combines LLM-assisted discovery, automated validation gates, and dual independent native-speaker annotators per country. To distinguish principled refusal from comprehension failure, we evaluate Attack Success Rate (ASR) alongside two complementary metrics we introduce: Neutral-Safe Rate (NSR) and Cultural Sensitivity Rate (CSR). Evaluating 10 frontier and 27 local LLMs reveals two key findings. First, jailbreak robustness and cultural awareness do not show a coupled relationship among frontier models, so a composite safety score obscures per-axis variation. Second, local models exhibit a near-linear ASR-NSR trade-off (r = -0.81), indicating that their apparent safety reflects generation failure rather than genuine alignment. XL-SafetyBench enables more nuanced, cross-cultural safety evaluation in the multilingual era.
Harnessing Chain-of-Thought Metadata for Task Routing and Adversarial Prompt Detection
Mar 27, 2025



In this work, we propose a metric called Number of Thoughts (NofT) to determine the difficulty of tasks pre-prompting and support Large Language Models (LLMs) in production contexts. By setting thresholds based on the number of thoughts, this metric can discern the difficulty of prompts and support more effective prompt routing. A 2% decrease in latency is achieved when routing prompts from the MathInstruct dataset through quantized, distilled versions of Deepseek with 1.7 billion, 7 billion, and 14 billion parameters. Moreover, this metric can be used to detect adversarial prompts used in prompt injection attacks with high efficacy. The Number of Thoughts can inform a classifier that achieves 95% accuracy in adversarial prompt detection. Our experiments ad datasets used are available on our GitHub page: https://github.com/rymarinelli/Number_Of_Thoughts/tree/main.
Expert Router: Orchestrating Efficient Language Model Inference through Prompt Classification
Apr 22, 2024



Large Language Models (LLMs) have experienced widespread adoption across scientific and industrial domains due to their versatility and utility for diverse tasks. Nevertheless, deploying and serving these models at scale with optimal throughput and latency remains a significant challenge, primarily because of the high computational and memory demands associated with LLMs. To tackle this limitation, we introduce Expert Router, a system designed to orchestrate multiple expert models efficiently, thereby enhancing scalability. Expert Router is a parallel inference system with a central routing gateway that distributes incoming requests using a clustering method. This approach effectively partitions incoming requests among available LLMs, maximizing overall throughput. Our extensive evaluations encompassed up to 1,000 concurrent users, providing comprehensive insights into the system's behavior from user and infrastructure perspectives. The results demonstrate Expert Router's effectiveness in handling high-load scenarios and achieving higher throughput rates, particularly under many concurrent users.
Evaluation of Parameterized Quantum Circuits: on the design, and the relation between classification accuracy, expressibility and entangling capability
Mar 22, 2020
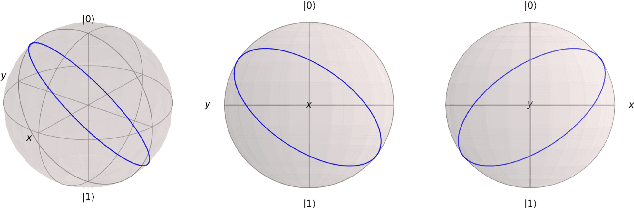

Quantum computers promise improvements in terms of both computational speedup and increased accuracy. Relevant areas are optimization, chemistry and machine learning, of which we will focus on the latter. Much of the prior art focuses on determining computational speedup, but how do we know if a particular quantum circuit shows promise for achieving high classification accuracy? Previous work by Sim et al. proposed descriptors to characterize and compare Parameterized Quantum Circuits. In this work, we will investigate any potential relation between the classification accuracy and two of these descriptors, being expressibility and entangling capability. We will first investigate different types of gates in quantum circuits and the changes they incur on the decision boundary. From this, we will propose design criteria for constructing circuits. We will also numerically compare the classifications performance of various quantum circuits and their quantified measure of expressibility and entangling capability, as derived in previous work. From this, we conclude that the common approach to layer combinations of rotational gates and conditional rotational gates provides the best accuracy. We also show that, for our experiments on a limited number of circuits, a coarse-grained relationship exists between entangling capability and classification accuracy, as well as a more fine-grained correlation between expressibility and classification accuracy. Future research will need to be performed to quantify this relation.
Integration and Evaluation of Quantum Accelerators for Data-Driven User Functions
Jan 25, 2020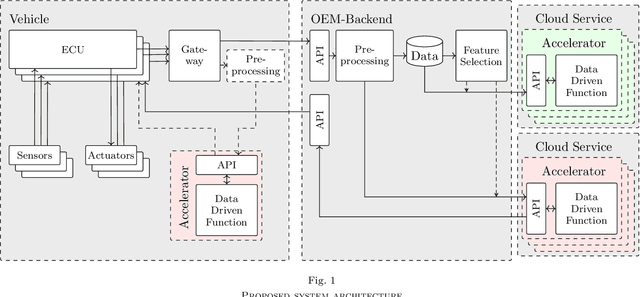

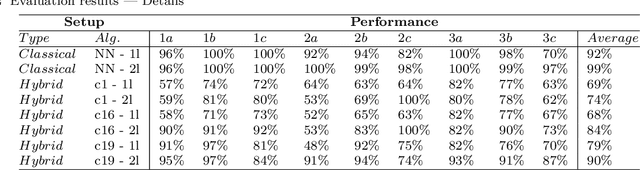
Quantum computers hold great promise for accelerating computationally challenging algorithms on noisy intermediate-scale quantum (NISQ) devices in the upcoming years. Much attention of the current research is directed to algorithmic research on artificial data that is disconnected from live systems, such as optimization of systems or training of learning algorithms. In this paper we investigate the integration of quantum systems into industry-grade system architectures. In this work we propose a system architecture for the integration of quantum accelerators. In order to evaluate our proposed system architecture we implemented various algorithms including a classical system, a gate-based quantum accelerator and a quantum annealer. This algorithm automates user habits using data-driven functions trained on real-world data. This also includes an evaluation of the quantum enhanced kernel, that previously was only evaluated on artificial data. In our evaluation, we showed that the quantum-enhanced kernel performs at least equally well to a classical state-of-the-art kernel. We also showed a low reduction in accuracy and latency numbers within acceptable bounds when running on the gate-based IBM quantum accelerator. We, therefore, conclude it is feasible to integrate NISQ-era devices in industry-grade system architecture in preparation for future hardware improvements.