 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
Oct 23, 2018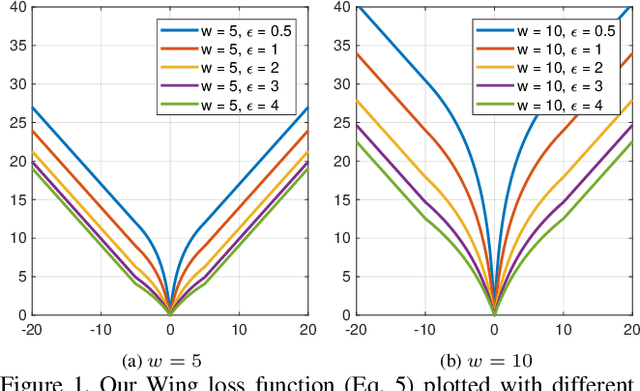
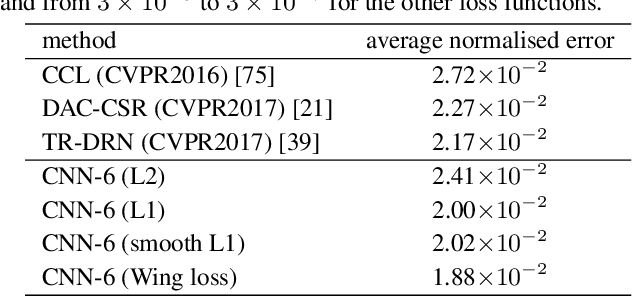
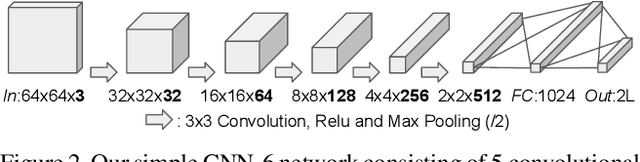
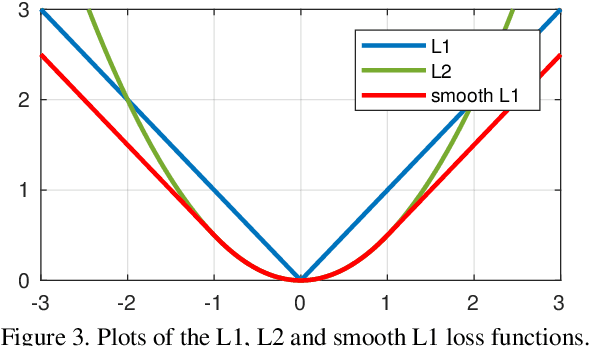
We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
Unconstrained Face Detection and Open-Set Face Recognition Challenge
Sep 25, 2018

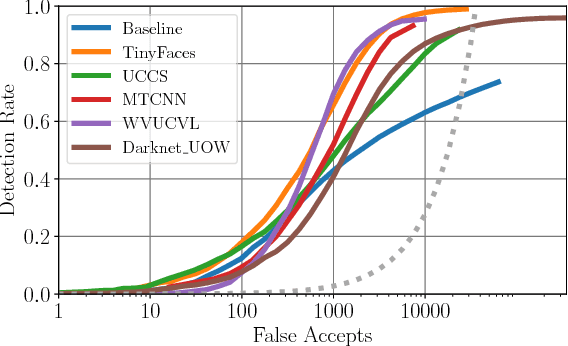

Face detection and recognition benchmarks have shifted toward more difficult environments. The challenge presented in this paper addresses the next step in the direction of automatic detection and identification of people from outdoor surveillance cameras. While face detection has shown remarkable success in images collected from the web, surveillance cameras include more diverse occlusions, poses, weather conditions and image blur. Although face verification or closed-set face identification have surpassed human capabilities on some datasets, open-set identification is much more complex as it needs to reject both unknown identities and false accepts from the face detector. We show that unconstrained face detection can approach high detection rates albeit with moderate false accept rates. By contrast, open-set face recognition is currently weak and requires much more attention.
One-Class Kernel Spectral Regression for Outlier Detection
Aug 20, 2018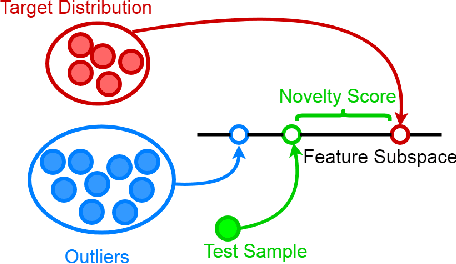
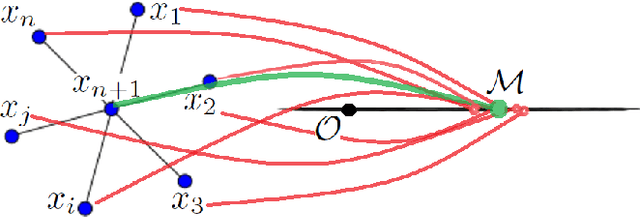
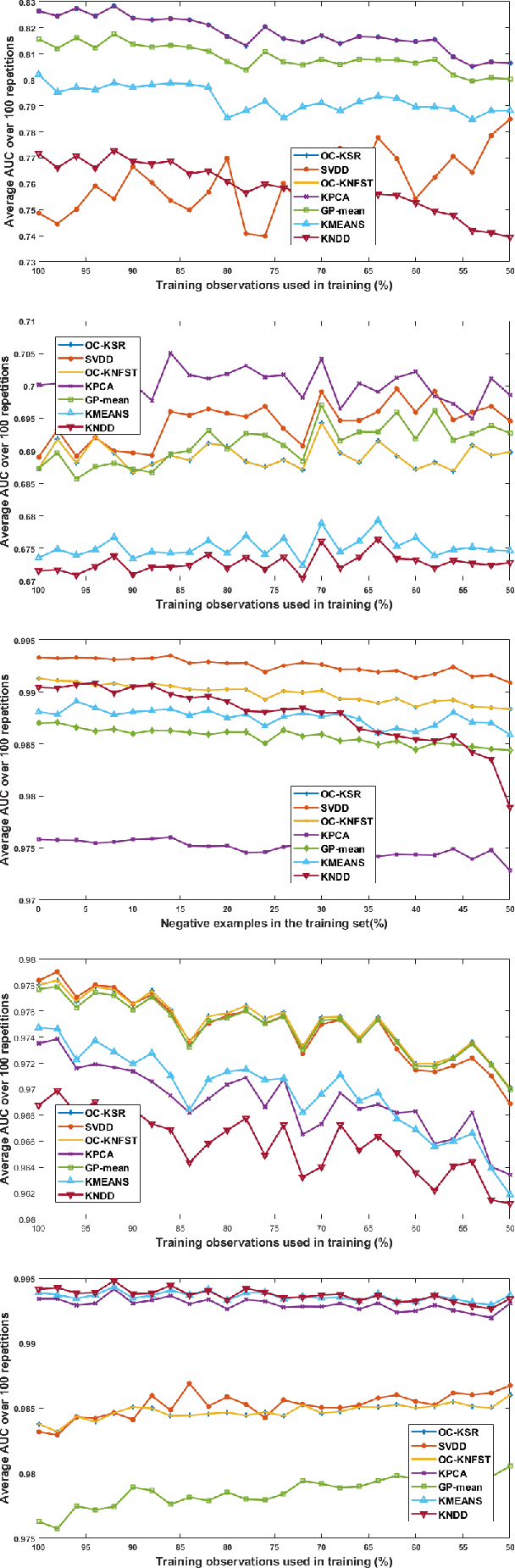
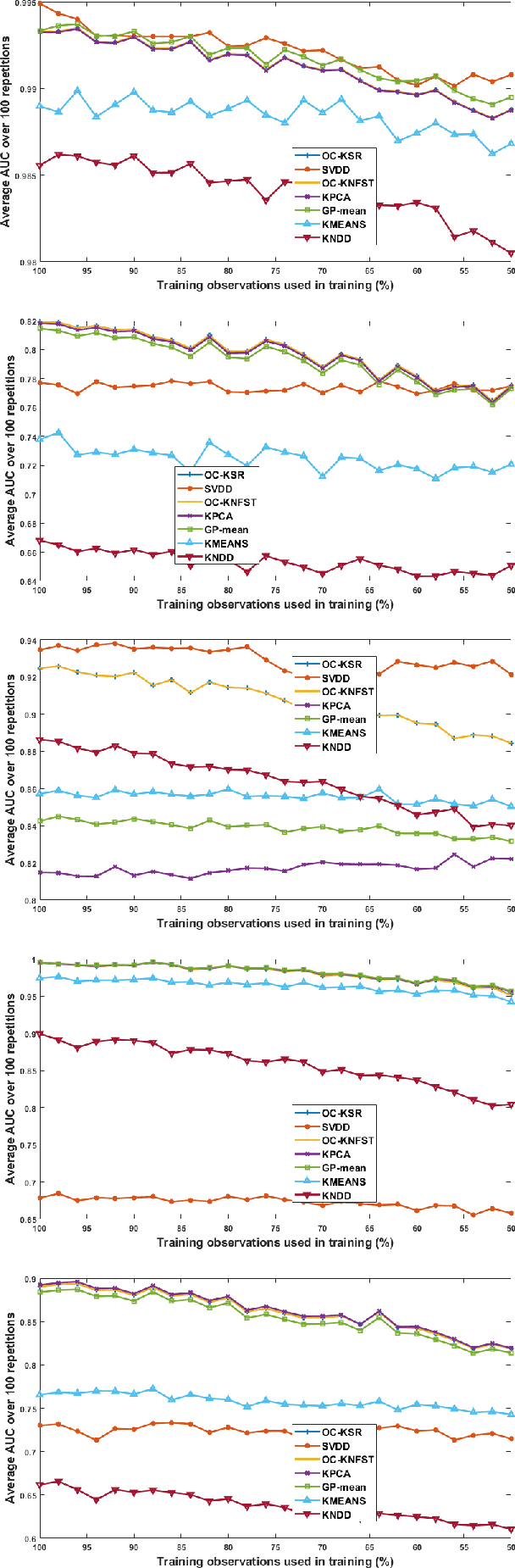
The paper introduces a new efficient nonlinear one-class classifier formulated as the Rayleigh quotient criterion optimisation. The method, operating in a reproducing kernel Hilbert subspace, minimises the scatter of target distribution along an optimal projection direction while at the same time keeping projections of positive observations distant from the mean of the negative class. We provide a graph embedding view of the problem which can then be solved efficiently using the spectral regression approach. In this sense, unlike previous similar methods which often require costly eigen-computations of dense matrices, the proposed approach casts the problem under consideration into a regression framework which is computationally more efficient. In particular, it is shown that the dominant complexity of the proposed method is the complexity of computing the kernel matrix. Additional appealing characteristics of the proposed one-class classifier are: 1-the ability to be trained in an incremental fashion (allowing for application in streaming data scenarios while also reducing the computational complexity in a non-streaming operation mode); 2-being unsupervised, but providing the option for refining the solution using negative training examples, when available; Last but not least, 3-the use of the kernel trick which facilitates a nonlinear mapping of the data into a high-dimensional feature space to seek better solutions.
Landmark Weighting for 3DMM Shape Fitting
Aug 16, 2018


Human face is a 3D object with shape and surface texture. 3D Morphable Model (3DMM) is a powerful tool for reconstructing the 3D face from a single 2D face image. In the shape fitting process, 3DMM estimates the correspondence between 2D and 3D landmarks. Most traditional 3DMM fitting methods fail to reconstruct an accurate model because face shape fitting is a difficult non-linear optimization problem. In this paper we show that landmark weighting is instrumental to improve the accuracy of shape reconstruction and propose a novel 3D Morphable Model Fitting method. Different from previous works that treat all landmarks equally, we take into consideration the estimated errors for each pair of 2D and 3D corresponding landmarks. The landmark points are weighted in the optimization cost function based on these errors. Obviously, these landmarks have different semantics because they locate on different facial components. In the context of the solution of fitting is approximated, there are deviations in landmarks matching. However, these landmarks with different semantics have different effects on reconstructing 3D faces. Thus, it is necessary to consider each landmark individually. To our knowledge, we are the first to analyze each feature point for 3D face reconstruction by 3DMM. The weight is adaptive with the estimation residuals of landmarks. Experimental results show that the proposed method significantly reduces the reconstruction error and improves the authenticity of the 3D model expression.
Learning Discriminative Hashing Codes for Cross-Modal Retrieval based on Multiorder Statistical Features
Aug 13, 2018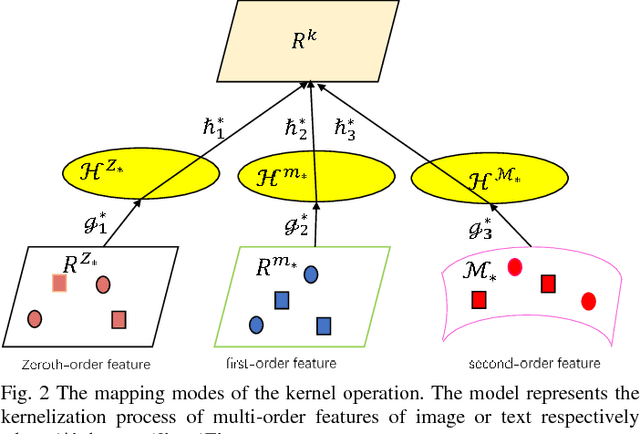
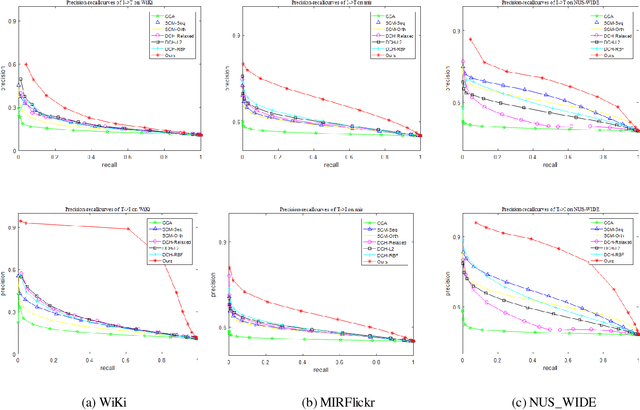
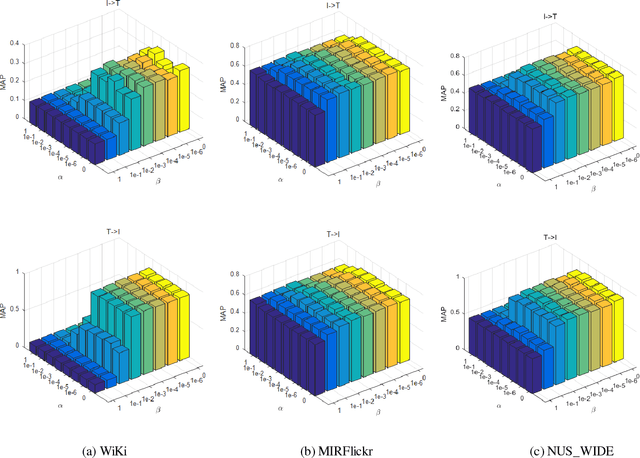
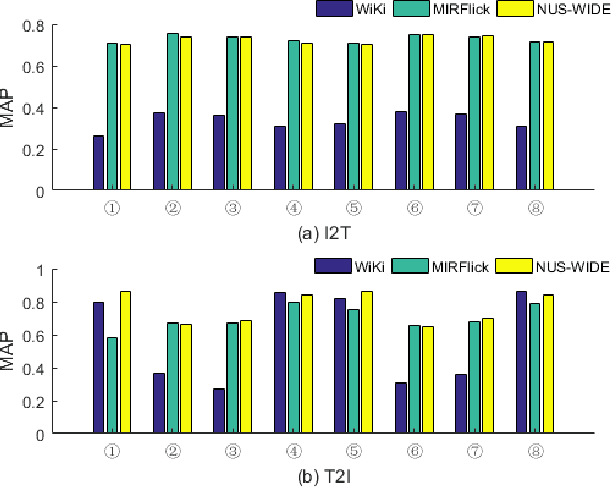
Hashing techniques have been applied broadly in large-scale retrieval tasks due to their low storage requirements and high speed of processing. Many hashing methods have shown promising performance but as they fail to exploit all structural information in learning the hashing function, they leave a scope for improvement. The paper proposes a novel discrete hashing learning framework which jointly performs classifier learning and subspace learning for cross-modal retrieval. Concretely, the framework proposed in the paper includes two stages, namely a kernelization process and a quantization process. The aim of kernelization is to learn a common subspace where heterogeneous data can be fused. The quantization process is designed to learn discriminative unified hashing codes. Extensive experiments on three publicly available datasets clearly indicate the superiority of our method compared with the state-of-the-art methods.
Learning Adaptive Discriminative Correlation Filters via Temporal Consistency Preserving Spatial Feature Selection for Robust Visual Tracking
Jul 30, 2018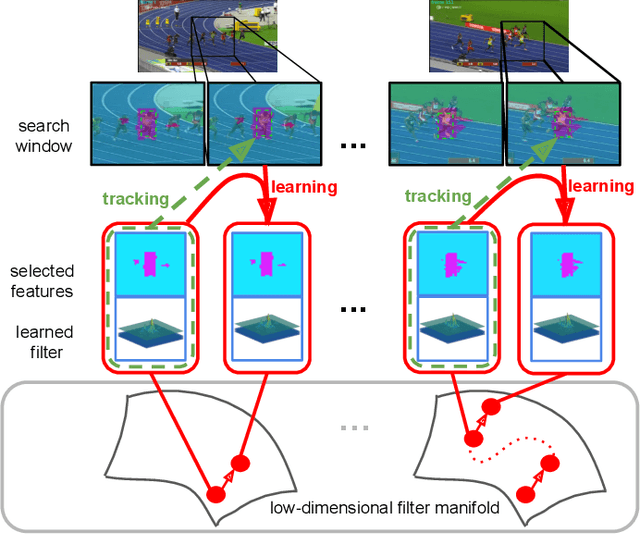
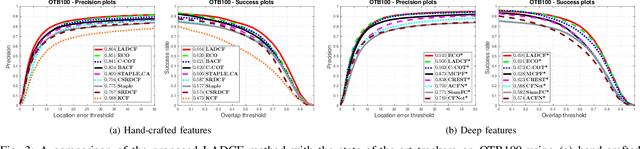
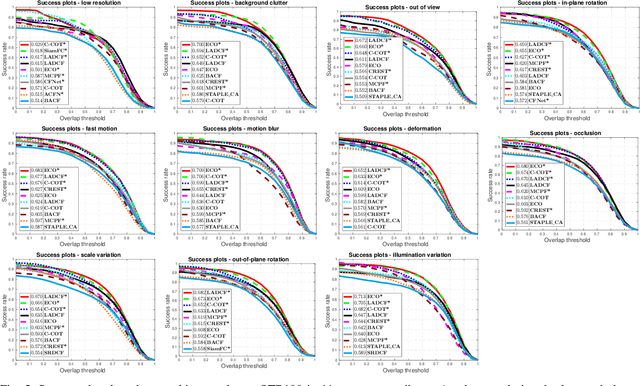
With efficient appearance learning models, Discriminative Correlation Filter (DCF) has been proven to be very successful in recent video object tracking benchmarks and competitions. However, the existing DCF paradigm suffers from two major problems, \ie spatial boundary effect and temporal filter degeneration. To mitigate these challenges, we propose a new DCF-based tracking method. The key innovations of the proposed method include adaptive spatial feature selection and temporal consistent constraints, with which the new tracker enables joint spatio-temporal filter learning in a lower dimensional discriminative manifold. More specifically, we apply structured sparsity constraints to multi-channel filers. Consequently, the process of learning spatial filters can be approximated by the lasso regularisation. To encourage temporal consistency, the filter model is restricted to lie around its historical value and updated locally to preserve the global structure in the manifold. Last, a unified optimisation framework is proposed to jointly select temporal consistency preserving spatial features and learn discriminative filters with the augmented Lagrangian method. Qualitative and quantitative evaluations have been conducted on a number of well-known benchmarking datasets such as OTB2013, OTB50, OTB100, Temple-Colour and UAV123. The experimental results demonstrate the superiority of the proposed method over the state-of-the-art approaches.
Client-Specific Anomaly Detection for Face Presentation Attack Detection
Jul 02, 2018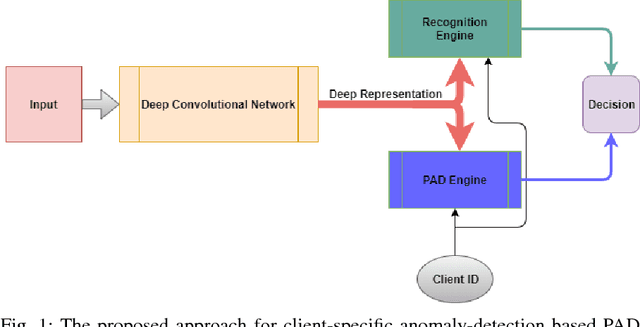
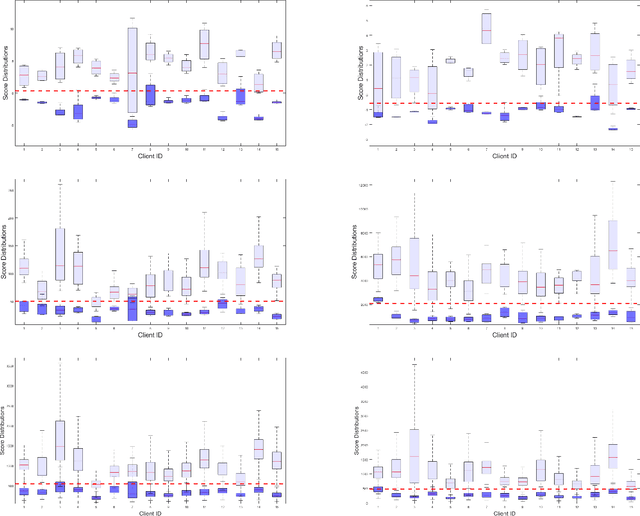
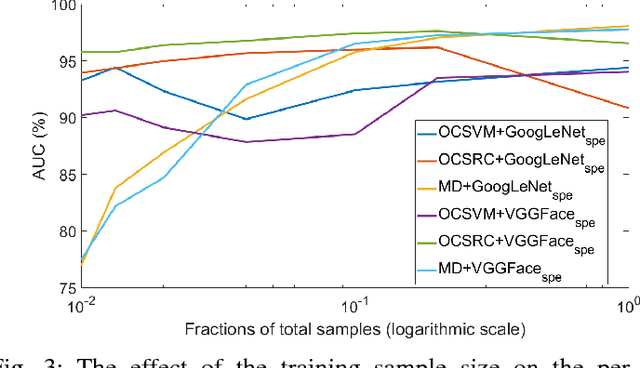
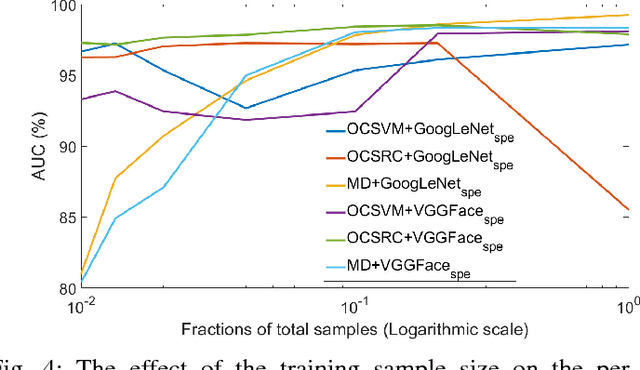
The one-class anomaly detection approach has previously been found to be effective in face presentation attack detection, especially in an \textit{unseen} attack scenario, where the system is exposed to novel types of attacks. This work follows the same anomaly-based formulation of the problem and analyses the merits of deploying \textit{client-specific} information for face spoofing detection. We propose training one-class client-specific classifiers (both generative and discriminative) using representations obtained from pre-trained deep convolutional neural networks. Next, based on subject-specific score distributions, a distinct threshold is set for each client, which is then used for decision making regarding a test query. Through extensive experiments using different one-class systems, it is shown that the use of client-specific information in a one-class anomaly detection formulation (both in model construction as well as decision threshold tuning) improves the performance significantly. In addition, it is demonstrated that the same set of deep convolutional features used for the recognition purposes is effective for face presentation attack detection in the class-specific one-class anomaly detection paradigm.
Grassmannian Discriminant Maps (GDM) for Manifold Dimensionality Reduction with Application to Image Set Classification
Jun 28, 2018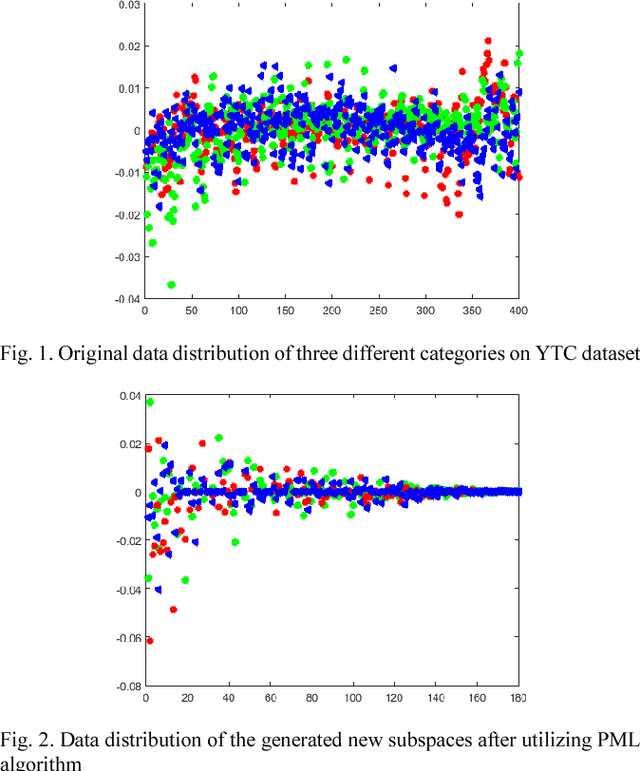
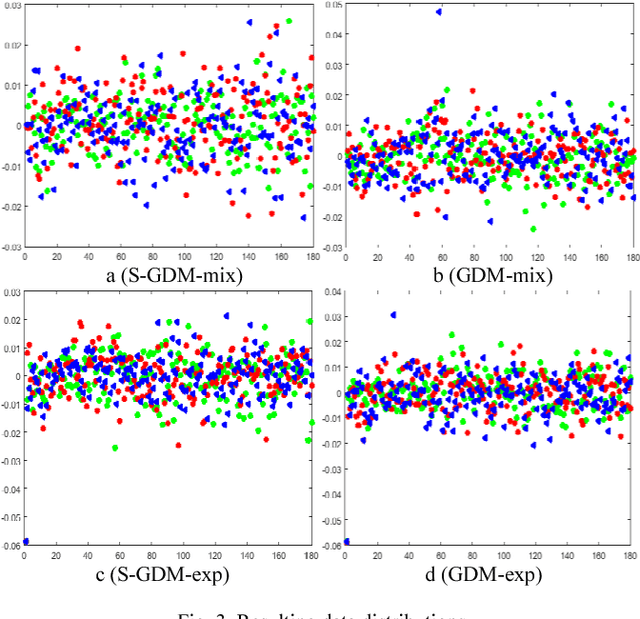
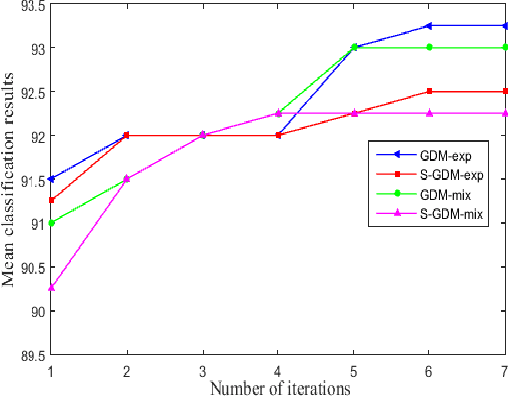
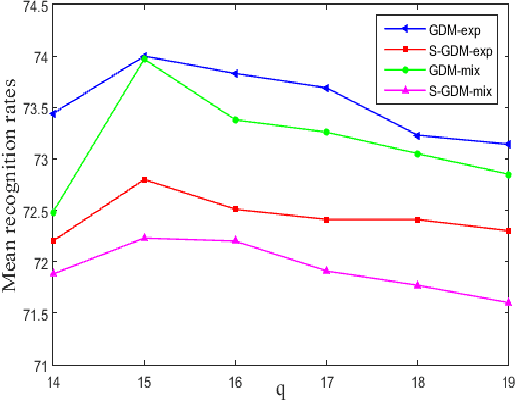
In image set classification, a considerable progress has been made by representing original image sets on Grassmann manifolds. In order to extend the advantages of the Euclidean based dimensionality reduction methods to the Grassmann Manifold, several methods have been suggested recently which jointly perform dimensionality reduction and metric learning on Grassmann manifold to improve performance. Nevertheless, when applied to complex datasets, the learned features do not exhibit enough discriminatory power. To overcome this problem, we propose a new method named Grassmannian Discriminant Maps (GDM) for manifold dimensionality reduction problems. The core of the method is a new discriminant function for metric learning and dimensionality reduction. For comparison and better understanding, we also study a simple variations to GDM. The key difference between them is the discriminant function. We experiment on data sets corresponding to three tasks: face recognition, object categorization, and hand gesture recognition to evaluate the proposed method and its simple extensions. Compared with the state of the art, the results achieved show the effectiveness of the proposed algorithm.
Semi-supervised Hashing for Semi-Paired Cross-View Retrieval
Jun 19, 2018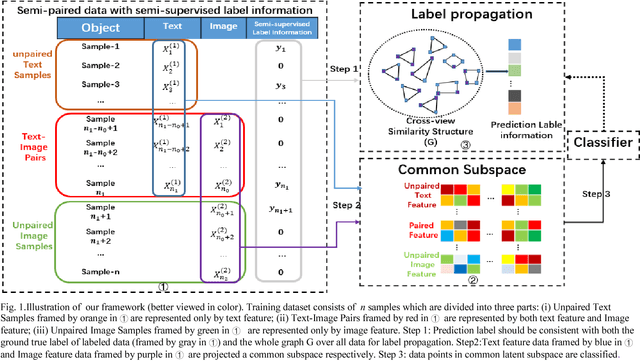
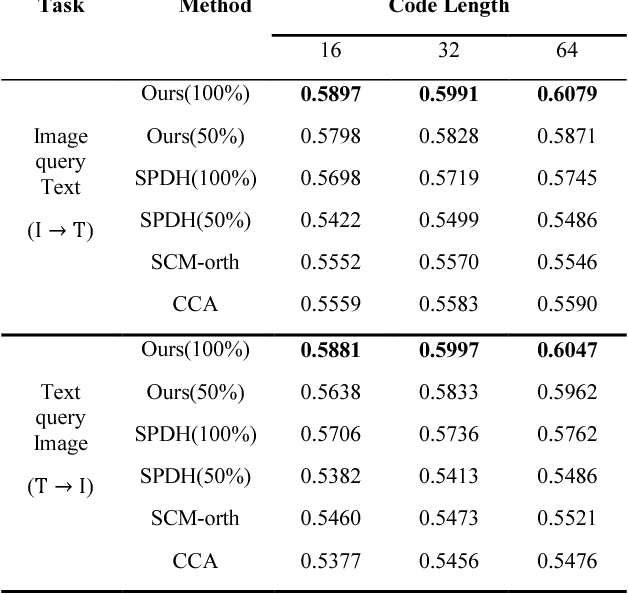
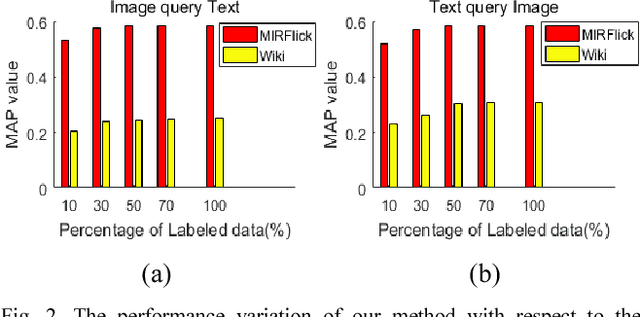
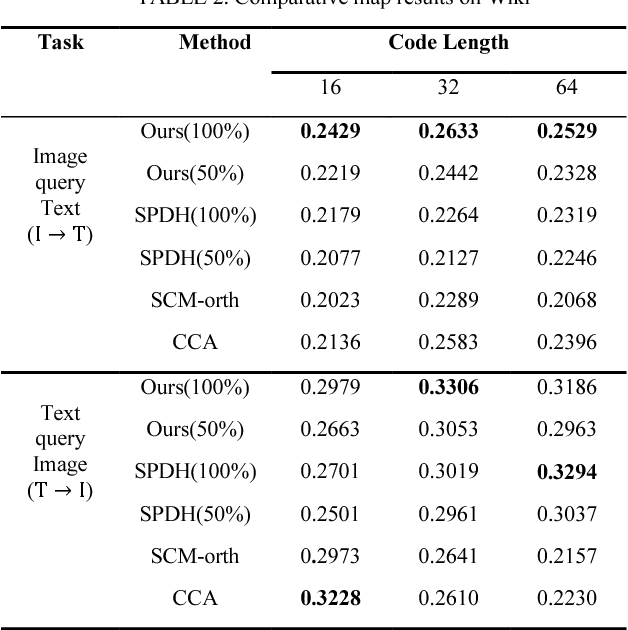
Recently, hashing techniques have gained importance in large-scale retrieval tasks because of their retrieval speed. Most of the existing cross-view frameworks assume that data are well paired. However, the fully-paired multiview situation is not universal in real applications. The aim of the method proposed in this paper is to learn the hashing function for semi-paired cross-view retrieval tasks. To utilize the label information of partial data, we propose a semi-supervised hashing learning framework which jointly performs feature extraction and classifier learning. The experimental results on two datasets show that our method outperforms several state-of-the-art methods in terms of retrieval accuracy.
Riemannian kernel based Nyström method for approximate infinite-dimensional covariance descriptors with application to image set classification
Jun 16, 2018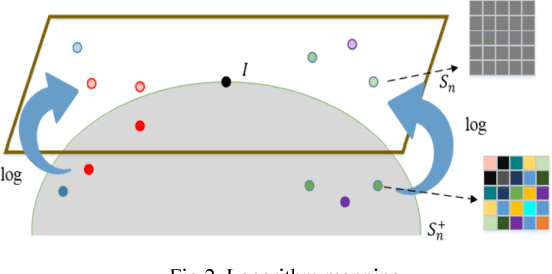
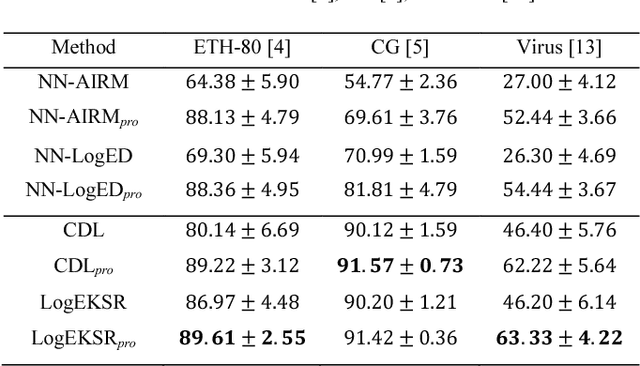
In the domain of pattern recognition, using the CovDs (Covariance Descriptors) to represent data and taking the metrics of the resulting Riemannian manifold into account have been widely adopted for the task of image set classification. Recently, it has been proven that infinite-dimensional CovDs are more discriminative than their low-dimensional counterparts. However, the form of infinite-dimensional CovDs is implicit and the computational load is high. We propose a novel framework for representing image sets by approximating infinite-dimensional CovDs in the paradigm of the Nystr\"om method based on a Riemannian kernel. We start by modeling the images via CovDs, which lie on the Riemannian manifold spanned by SPD (Symmetric Positive Definite) matrices. We then extend the Nystr\"om method to the SPD manifold and obtain the approximations of CovDs in RKHS (Reproducing Kernel Hilbert Space). Finally, we approximate infinite-dimensional CovDs via these approximations. Empirically, we apply our framework to the task of image set classification. The experimental results obtained on three benchmark datasets show that our proposed approximate infinite-dimensional CovDs outperform the original CovDs.