 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks and the Chomsky Hierarchy
Jul 05, 2022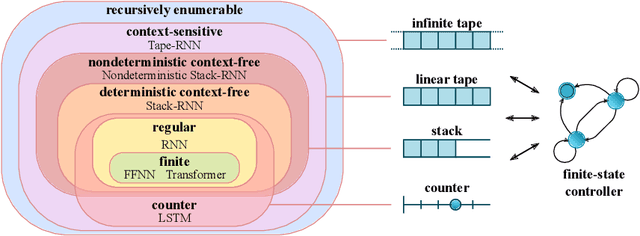



Reliable generalization lies at the heart of safe ML and AI. However, understanding when and how neural networks generalize remains one of the most important unsolved problems in the field. In this work, we conduct an extensive empirical study (2200 models, 16 tasks) to investigate whether insights from the theory of computation can predict the limits of neural network generalization in practice. We demonstrate that grouping tasks according to the Chomsky hierarchy allows us to forecast whether certain architectures will be able to generalize to out-of-distribution inputs. This includes negative results where even extensive amounts of data and training time never led to any non-trivial generalization, despite models having sufficient capacity to perfectly fit the training data. Our results show that, for our subset of tasks, RNNs and Transformers fail to generalize on non-regular tasks, LSTMs can solve regular and counter-language tasks, and only networks augmented with structured memory (such as a stack or memory tape) can successfully generalize on context-free and context-sensitive tasks.
Your Policy Regularizer is Secretly an Adversary
Apr 01, 2022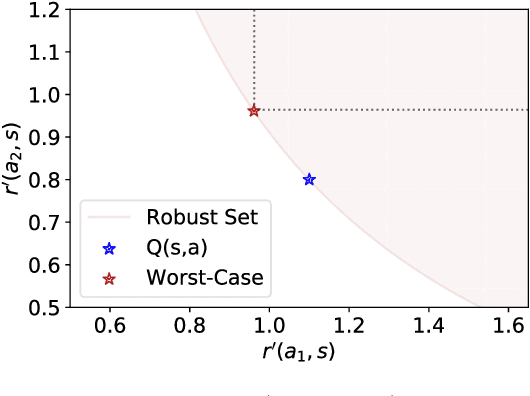


Policy regularization methods such as maximum entropy regularization are widely used in reinforcement learning to improve the robustness of a learned policy. In this paper, we show how this robustness arises from hedging against worst-case perturbations of the reward function, which are chosen from a limited set by an imagined adversary. Using convex duality, we characterize this robust set of adversarial reward perturbations under KL and alpha-divergence regularization, which includes Shannon and Tsallis entropy regularization as special cases. Importantly, generalization guarantees can be given within this robust set. We provide detailed discussion of the worst-case reward perturbations, and present intuitive empirical examples to illustrate this robustness and its relationship with generalization. Finally, we discuss how our analysis complements and extends previous results on adversarial reward robustness and path consistency optimality conditions.
Model-Free Risk-Sensitive Reinforcement Learning
Nov 04, 2021
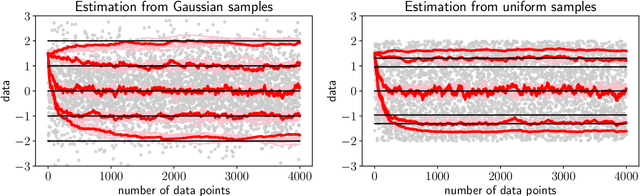

We extend temporal-difference (TD) learning in order to obtain risk-sensitive, model-free reinforcement learning algorithms. This extension can be regarded as modification of the Rescorla-Wagner rule, where the (sigmoidal) stimulus is taken to be either the event of over- or underestimating the TD target. As a result, one obtains a stochastic approximation rule for estimating the free energy from i.i.d. samples generated by a Gaussian distribution with unknown mean and variance. Since the Gaussian free energy is known to be a certainty-equivalent sensitive to the mean and the variance, the learning rule has applications in risk-sensitive decision-making.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021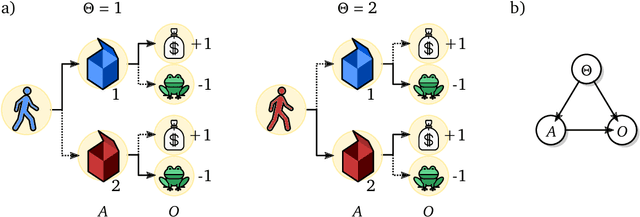
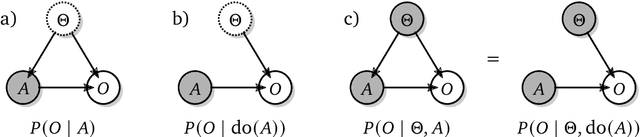
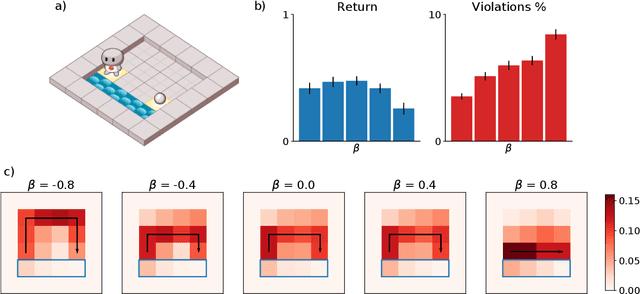
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Bellman: A Toolbox for Model-Based Reinforcement Learning in TensorFlow
Apr 13, 2021
In the past decade, model-free reinforcement learning (RL) has provided solutions to challenging domains such as robotics. Model-based RL shows the prospect of being more sample-efficient than model-free methods in terms of agent-environment interactions, because the model enables to extrapolate to unseen situations. In the more recent past, model-based methods have shown superior results compared to model-free methods in some challenging domains with non-linear state transitions. At the same time, it has become apparent that RL is not market-ready yet and that many real-world applications are going to require model-based approaches, because model-free methods are too sample-inefficient and show poor performance in early stages of training. The latter is particularly important in industry, e.g. in production systems that directly impact a company's revenue. This demonstrates the necessity for a toolbox to push the boundaries for model-based RL. While there is a plethora of toolboxes for model-free RL, model-based RL has received little attention in terms of toolbox development. Bellman aims to fill this gap and introduces the first thoroughly designed and tested model-based RL toolbox using state-of-the-art software engineering practices. Our modular approach enables to combine a wide range of environment models with generic model-based agent classes that recover state-of-the-art algorithms. We also provide an experiment harness to compare both model-free and model-based agents in a systematic fashion w.r.t. user-defined evaluation metrics (e.g. cumulative reward). This paves the way for new research directions, e.g. investigating uncertainty-aware environment models that are not necessarily neural-network-based, or developing algorithms to solve industrially-motivated benchmarks that share characteristics with real-world problems.
Causal Analysis of Agent Behavior for AI Safety
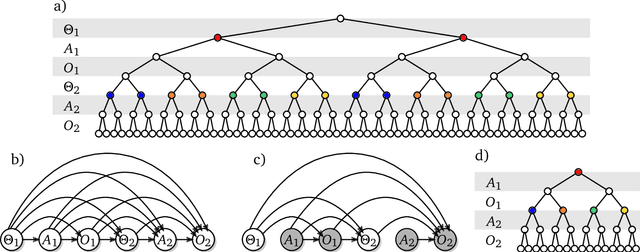
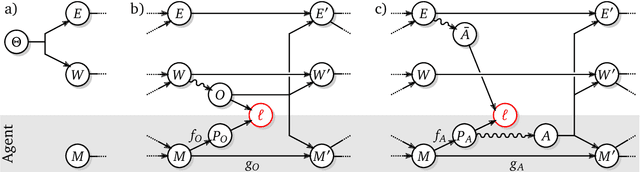
Mar 05, 2021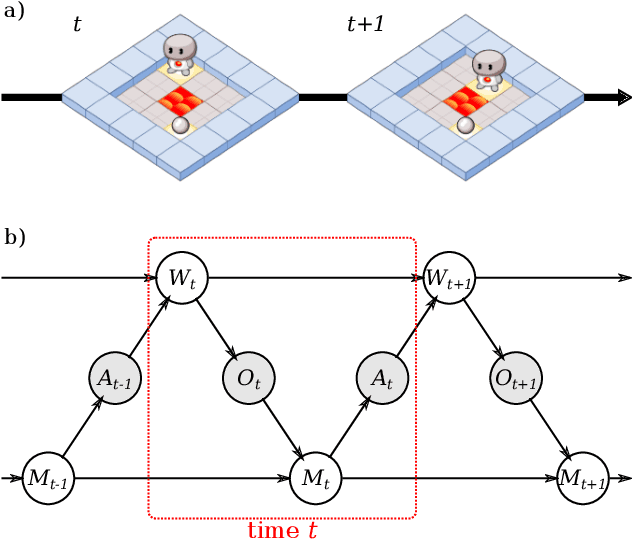
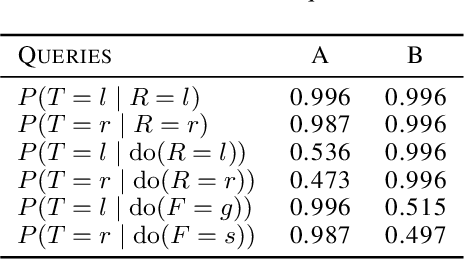
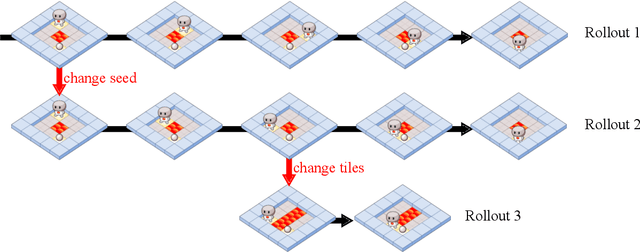
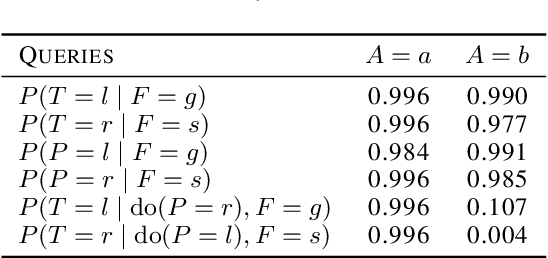
As machine learning systems become more powerful they also become increasingly unpredictable and opaque. Yet, finding human-understandable explanations of how they work is essential for their safe deployment. This technical report illustrates a methodology for investigating the causal mechanisms that drive the behaviour of artificial agents. Six use cases are covered, each addressing a typical question an analyst might ask about an agent. In particular, we show that each question cannot be addressed by pure observation alone, but instead requires conducting experiments with systematically chosen manipulations so as to generate the correct causal evidence.
Mutual-Information Regularization in Markov Decision Processes and Actor-Critic Learning
Sep 11, 2019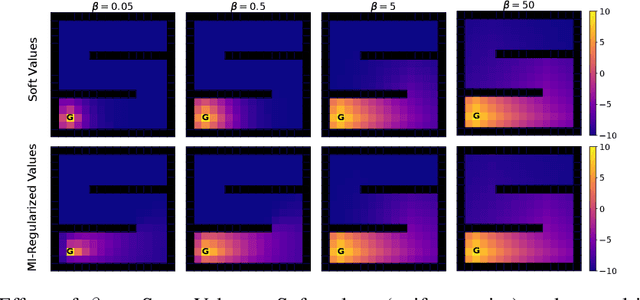
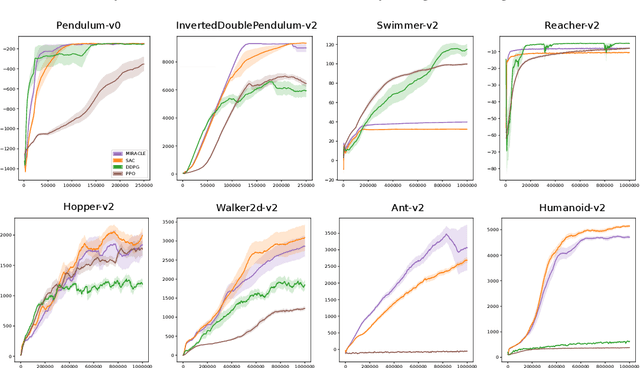
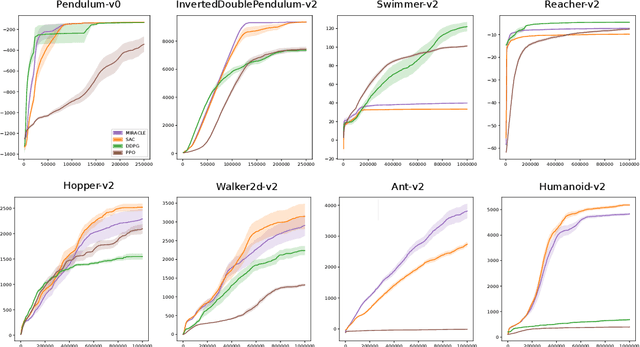
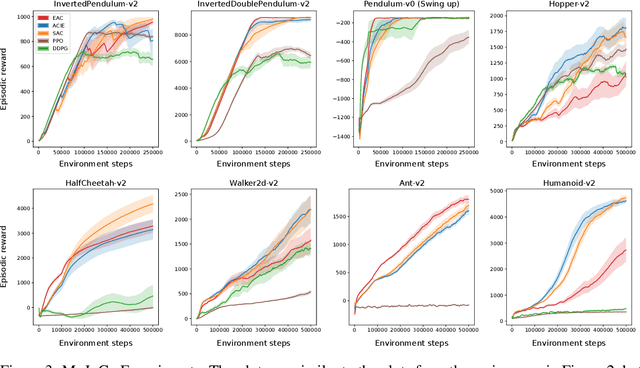
Cumulative entropy regularization introduces a regulatory signal to the reinforcement learning (RL) problem that encourages policies with high-entropy actions, which is equivalent to enforcing small deviations from a uniform reference marginal policy. This has been shown to improve exploration and robustness, and it tackles the value overestimation problem. It also leads to a significant performance increase in tabular and high-dimensional settings, as demonstrated via algorithms such as soft Q-learning (SQL) and soft actor-critic (SAC). Cumulative entropy regularization has been extended to optimize over the reference marginal policy instead of keeping it fixed, yielding a regularization that minimizes the mutual information between states and actions. While this has been initially proposed for Markov Decision Processes (MDPs) in tabular settings, it was recently shown that a similar principle leads to significant improvements over vanilla SQL in RL for high-dimensional domains with discrete actions and function approximators. Here, we follow the motivation of mutual-information regularization from an inference perspective and theoretically analyze the corresponding Bellman operator. Inspired by this Bellman operator, we devise a novel mutual-information regularized actor-critic learning (MIRACLE) algorithm for continuous action spaces that optimizes over the reference marginal policy. We empirically validate MIRACLE in the Mujoco robotics simulator, where we demonstrate that it can compete with contemporary RL methods. Most notably, it can improve over the model-free state-of-the-art SAC algorithm which implicitly assumes a fixed reference policy.
A Unified Bellman Optimality Principle Combining Reward Maximization and Empowerment
Sep 09, 2019
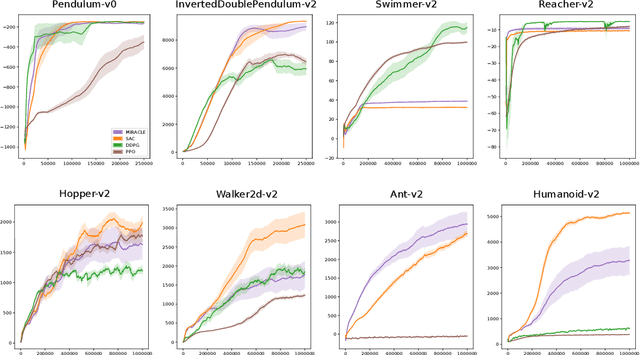
Empowerment is an information-theoretic method that can be used to intrinsically motivate learning agents. It attempts to maximize an agent's control over the environment by encouraging visiting states with a large number of reachable next states. Empowered learning has been shown to lead to complex behaviors, without requiring an explicit reward signal. In this paper, we investigate the use of empowerment in the presence of an extrinsic reward signal. We hypothesize that empowerment can guide reinforcement learning (RL) agents to find good early behavioral solutions by encouraging highly empowered states. We propose a unified Bellman optimality principle for empowered reward maximization. Our empowered reward maximization approach generalizes both Bellman's optimality principle as well as recent information-theoretical extensions to it. We prove uniqueness of the empowered values and show convergence to the optimal solution. We then apply this idea to develop off-policy actor-critic RL algorithms for high-dimensional continuous domains. We experimentally validate our methods in robotics domains (MuJoCo). Our methods demonstrate improved initial and competitive final performance compared to model-free state-of-the-art techniques.
Disentangled Skill Embeddings for Reinforcement Learning
Jun 21, 2019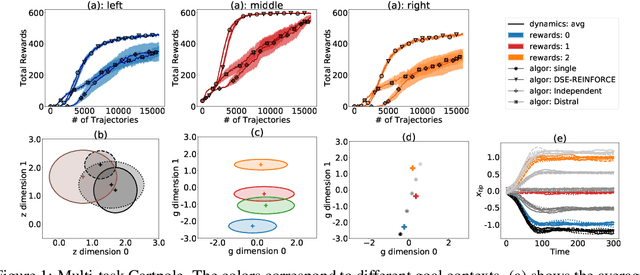
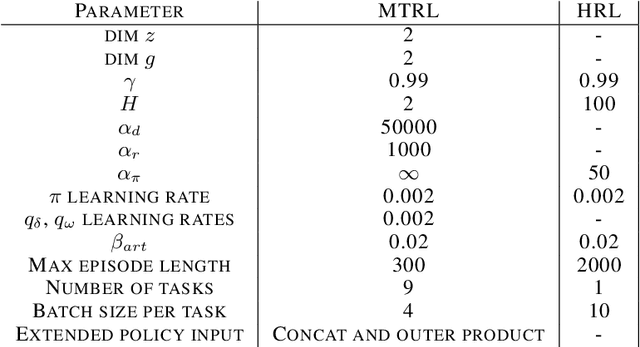
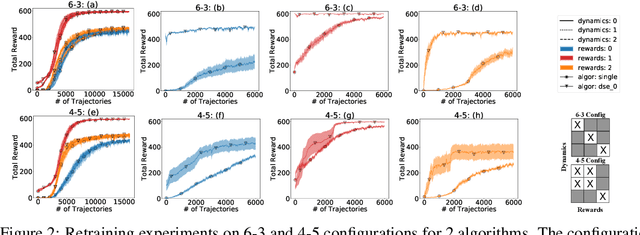
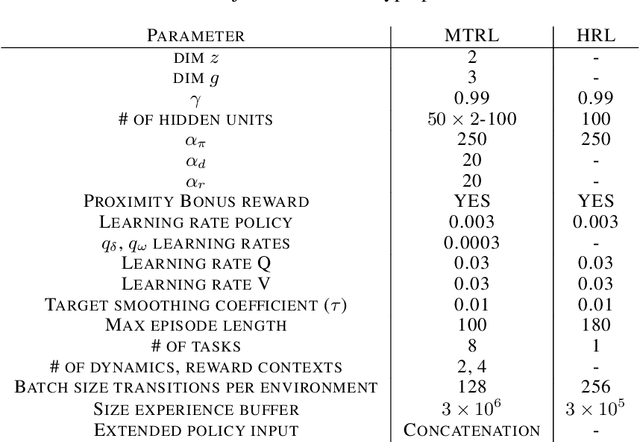
We propose a novel framework for multi-task reinforcement learning (MTRL). Using a variational inference formulation, we learn policies that generalize across both changing dynamics and goals. The resulting policies are parametrized by shared parameters that allow for transfer between different dynamics and goal conditions, and by task-specific latent-space embeddings that allow for specialization to particular tasks. We show how the latent-spaces enable generalization to unseen dynamics and goals conditions. Additionally, policies equipped with such embeddings serve as a space of skills (or options) for hierarchical reinforcement learning. Since we can change task dynamics and goals independently, we name our framework Disentangled Skill Embeddings (DSE).
Regularised Deep Reinforcement Learning with Guaranteed Convergence
Sep 06, 2018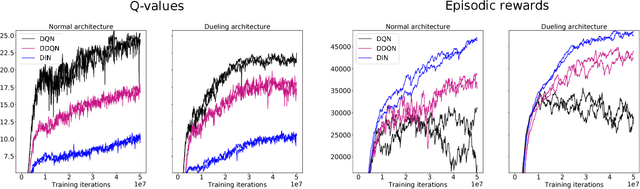
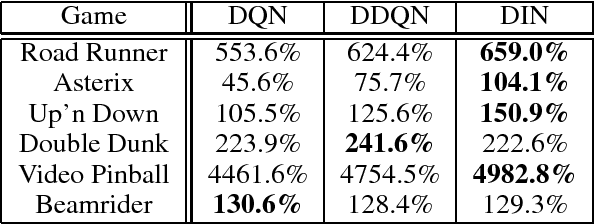
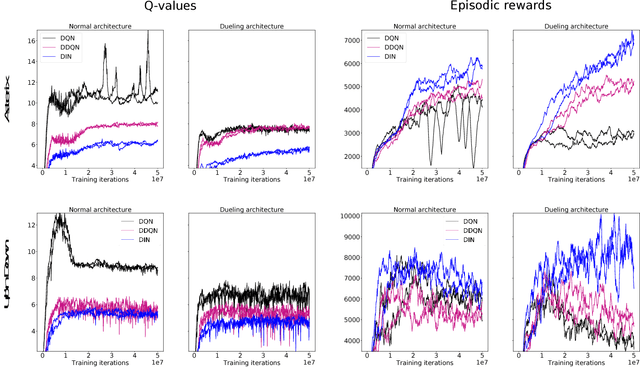
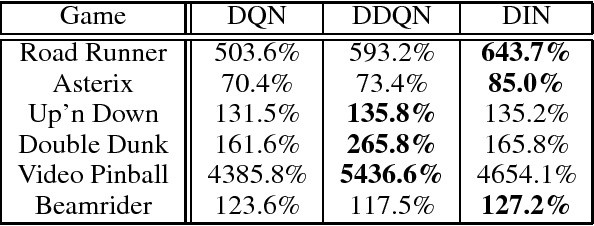
Deep Q-networks (DQNs) suffer from two important challenges hindering their application in real-world scenarios. First, DQNs overestimate Q-values which leads to increased sample complexity, and second, no theoretical convergence guarantees have been established. In this paper, we address both problems by introducing an intrinsic penalty signal arising from a Kullback-Leibler (KL) constraint that encourages reduced Q-value estimates. We then prove, for the first time, convergence to a stationary point under a specific scheduling of the penalisation magnitude. Our proofs operate in the deep reinforcement learning setting that considers convolutional and dense layers for Q-function approximation. Furthermore, we prove divergence of standard DQNs using a counter example that relates to the non-optimal choice of the history-scheduling parameter adopted by `vanilla' DQNs. We believe this can shed the light on some of the difficulties reported by researchers and practitioners in the field.