 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can AI do for me: Evaluating Machine Learning Interpretations in Cooperative Play
Oct 24, 2018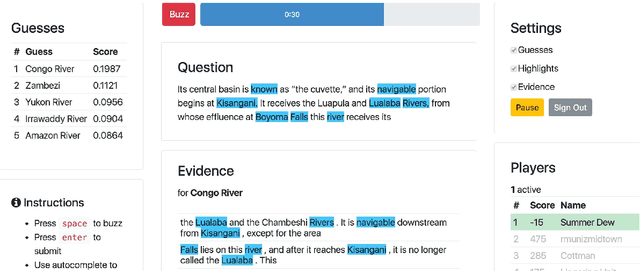
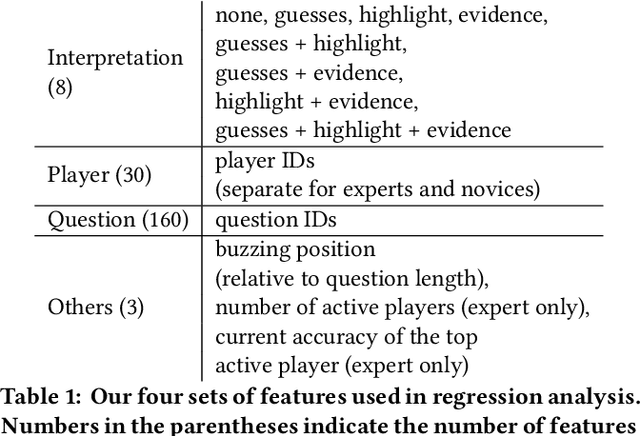
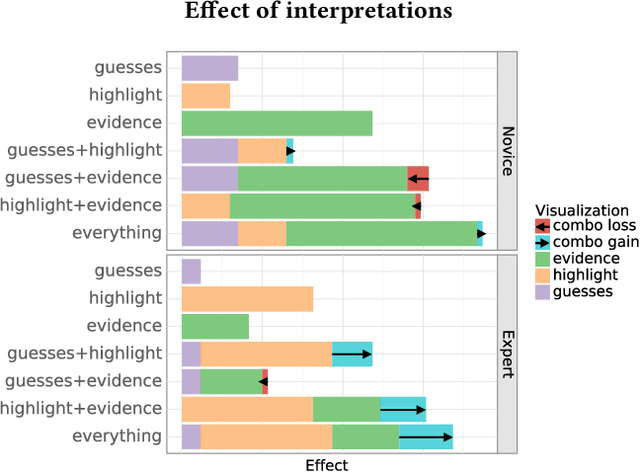
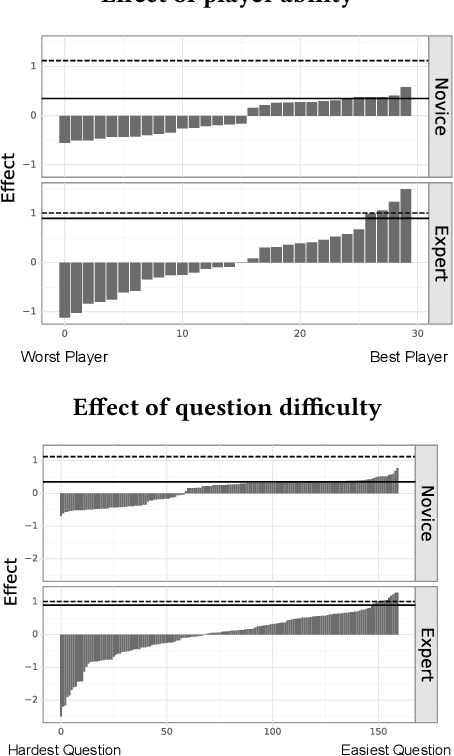
Machine learning is an important tool for decision making, but its ethical and responsible application requires rigorous vetting of its interpretability and utility: an understudied problem, particularly for natural language processing models. We design a task-specific evaluation for a question answering task and evaluate how well a model interpretation improves human performance in a human-machine cooperative setting. We evaluate interpretation methods in a grounded, realistic setting: playing a trivia game as a team. We also provide design guidance for natural language processing human-in-the-loop settings.
Interpreting Neural Networks With Nearest Neighbors
Sep 08, 2018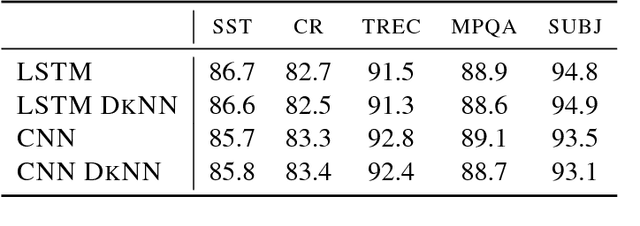
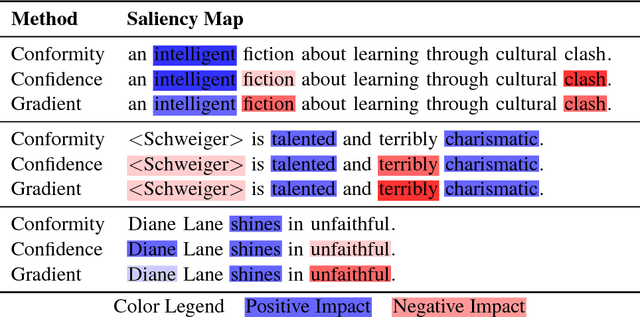

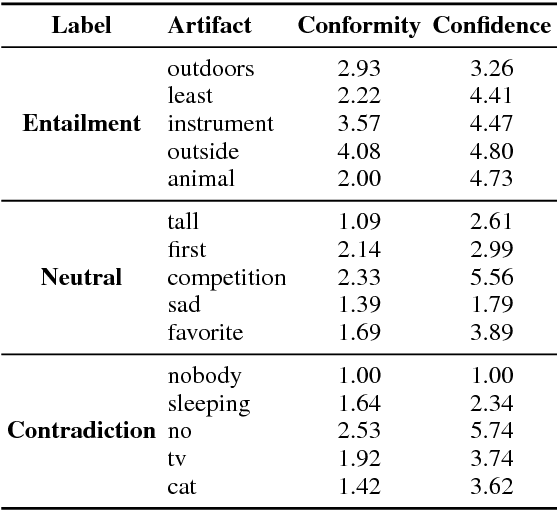
Local model interpretation methods explain individual predictions by assigning an importance value to each input feature. This value is often determined by measuring the change in confidence when a feature is removed. However, the confidence of neural networks is not a robust measure of model uncertainty. This issue makes reliably judging the importance of the input features difficult. We address this by changing the test-time behavior of neural networks using Deep k-Nearest Neighbors. Without harming text classification accuracy, this algorithm provides a more robust uncertainty metric which we use to generate feature importance values. The resulting interpretations better align with human perception than baseline methods. Finally, we use our interpretation method to analyze model predictions on dataset annotation artifacts.
Trick Me If You Can: Adversarial Writing of Trivia Challenge Questions
Sep 07, 2018

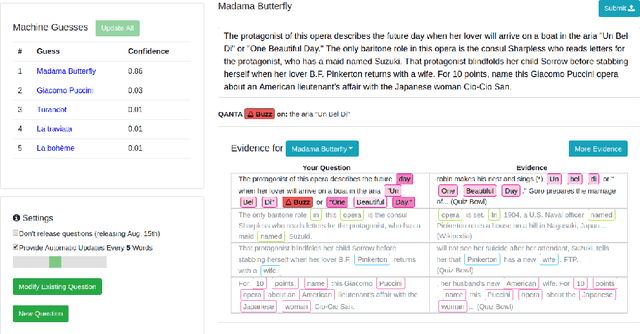

Modern natural language processing systems have been touted as approaching human performance. However, existing datasets are imperfect tests. Examples are written with humans in mind, not computers, and often do not properly expose model limitations. We address this by developing a new process for crowdsourced annotation, adversarial writing, where humans interact with trained models and try to break them. Applying this annotation process to Trivia question answering yields a challenge set, which despite being easy for human players to answer, systematically stumps automated question answering systems. Diagnosing model errors on the evaluation data provides actionable insights to explore in developing more robust and generalizable question answering systems.
Pathologies of Neural Models Make Interpretations Difficult
Aug 28, 2018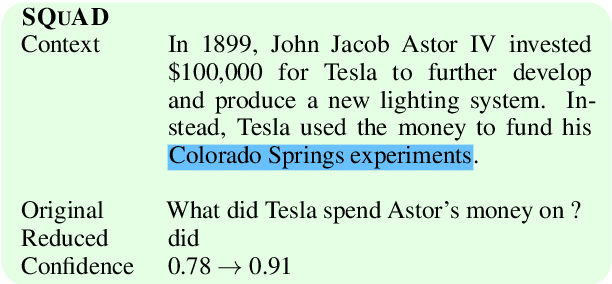
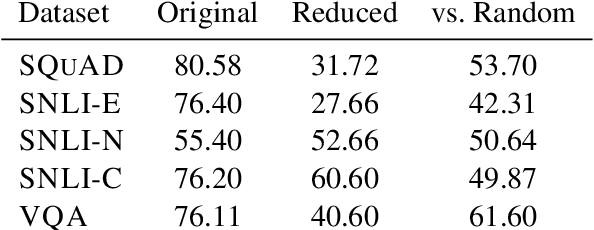

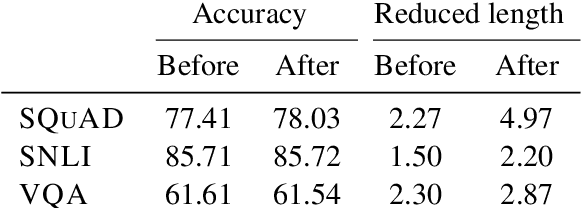
One way to interpret neural model predictions is to highlight the most important input features---for example, a heatmap visualization over the words in an input sentence. In existing interpretation methods for NLP, a word's importance is determined by either input perturbation---measuring the decrease in model confidence when that word is removed---or by the gradient with respect to that word. To understand the limitations of these methods, we use input reduction, which iteratively removes the least important word from the input. This exposes pathological behaviors of neural models: the remaining words appear nonsensical to humans and are not the ones determined as important by interpretation methods. As we confirm with human experiments, the reduced examples lack information to support the prediction of any label, but models still make the same predictions with high confidence. To explain these counterintuitive results, we draw connections to adversarial examples and confidence calibration: pathological behaviors reveal difficulties in interpreting neural models trained with maximum likelihood. To mitigate their deficiencies, we fine-tune the models by encouraging high entropy outputs on reduced examples. Fine-tuned models become more interpretable under input reduction without accuracy loss on regular examples.
Automatic Estimation of Simultaneous Interpreter Performance
Jul 06, 2018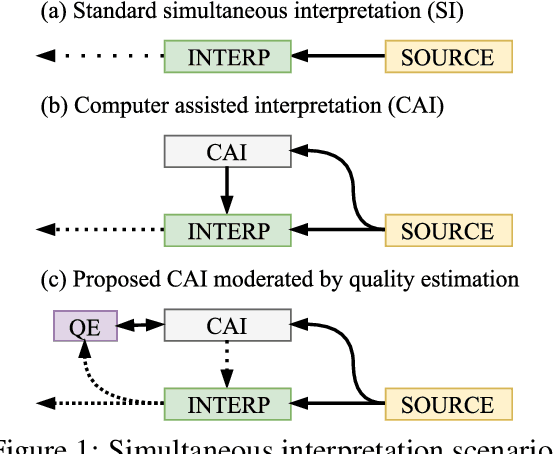
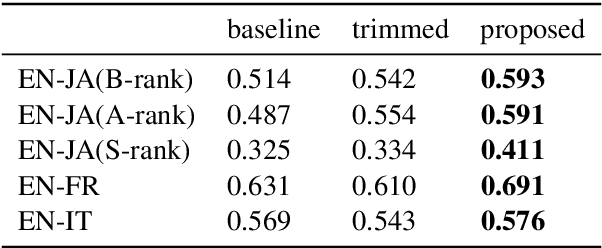
Simultaneous interpretation, translation of the spoken word in real-time, is both highly challenging and physically demanding. Methods to predict interpreter confidence and the adequacy of the interpreted message have a number of potential applications, such as in computer-assisted interpretation interfaces or pedagogical tools. We propose the task of predicting simultaneous interpreter performance by building on existing methodology for quality estimation (QE) of machine translation output. In experiments over five settings in three language pairs, we extend a QE pipeline to estimate interpreter performance (as approximated by the METEOR evaluation metric) and propose novel features reflecting interpretation strategy and evaluation measures that further improve prediction accuracy.
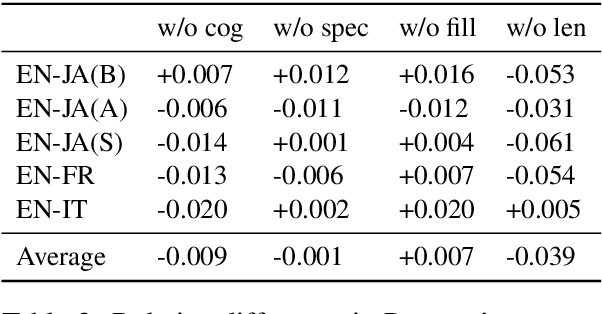
Lessons from the Bible on Modern Topics: Low-Resource Multilingual Topic Model Evaluation
Apr 26, 2018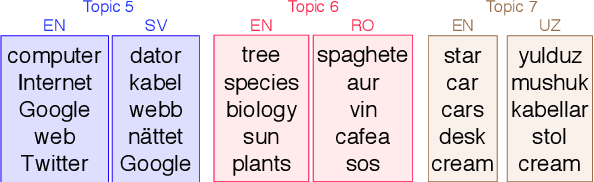
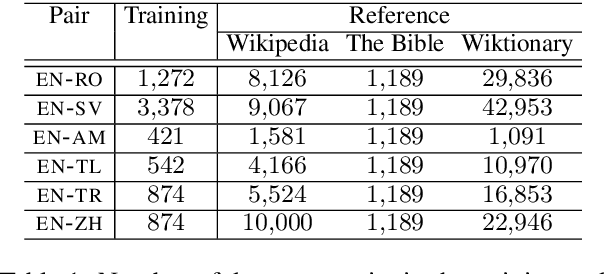
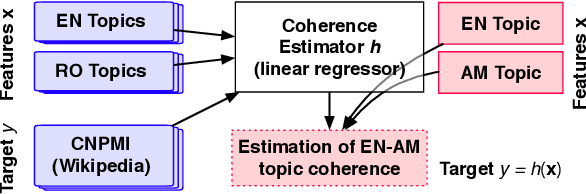
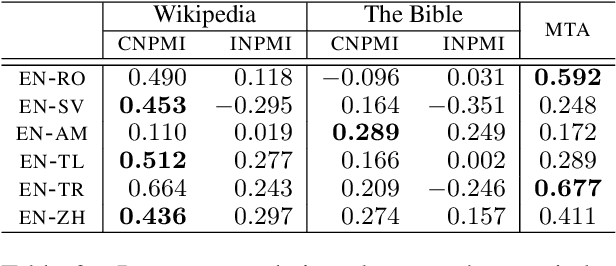
Multilingual topic models enable document analysis across languages through coherent multilingual summaries of the data. However, there is no standard and effective metric to evaluate the quality of multilingual topics. We introduce a new intrinsic evaluation of multilingual topic models that correlates well with human judgments of multilingual topic coherence as well as performance in downstream applications. Importantly, we also study evaluation for low-resource languages. Because standard metrics fail to accurately measure topic quality when robust external resources are unavailable, we propose an adaptation model that improves the accuracy and reliability of these metrics in low-resource settings.
Inducing and Embedding Senses with Scaled Gumbel Softmax
Apr 22, 2018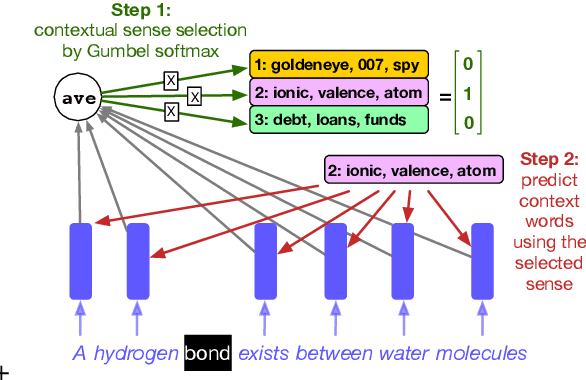
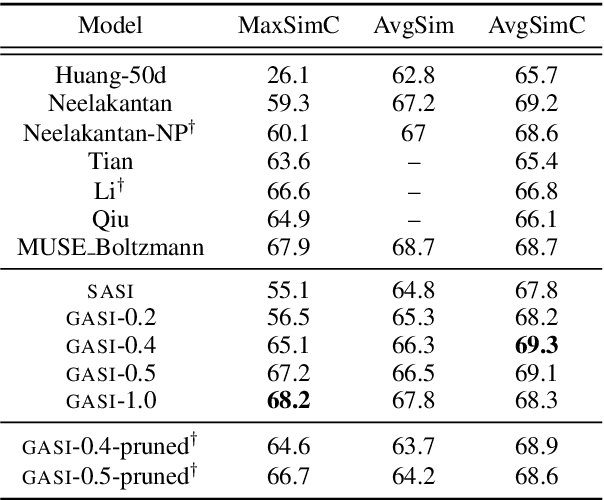
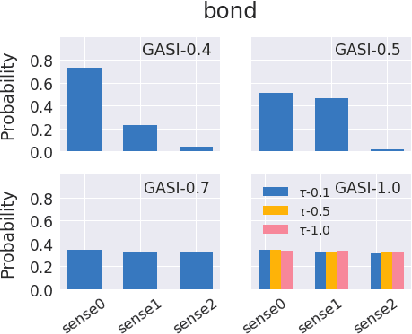
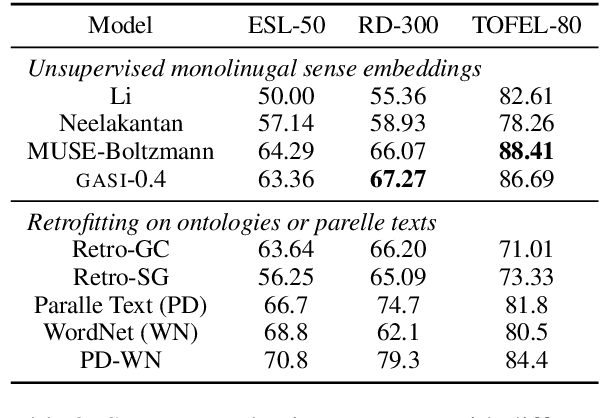
Methods for learning word sense embeddings represent a single word with multiple sense-specific vectors. These methods should not only produce interpretable sense embeddings, but should also learn how to select which sense to use in a given context. We propose an unsupervised model that learns sense embeddings using a modified Gumbel softmax function, which allows for differentiable discrete sense selection. Our model produces sense embeddings that are competitive (and sometimes state of the art) on multiple similarity based downstream evaluations. However, performance on these downstream evaluations tasks does not correlate with interpretability of sense embeddings, as we discover through an interpretability comparison with competing multi-sense embeddings. While many previous approaches perform well on downstream evaluations, they do not produce interpretable embeddings and learn duplicated sense groups; our method achieves the best of both worlds.
Learning to Color from Language
Apr 17, 2018

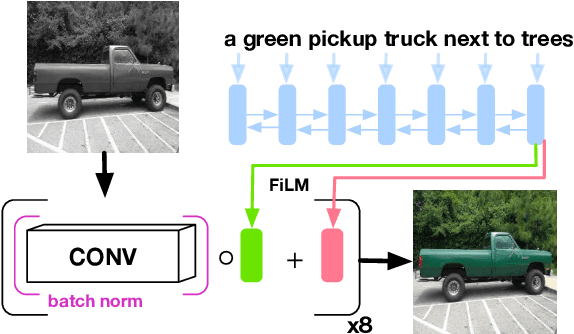

Automatic colorization is the process of adding color to greyscale images. We condition this process on language, allowing end users to manipulate a colorized image by feeding in different captions. We present two different architectures for language-conditioned colorization, both of which produce more accurate and plausible colorizations than a language-agnostic version. Through this language-based framework, we can dramatically alter colorizations by manipulating descriptive color words in captions.
* 6 pages
Reinforcement Learning for Bandit Neural Machine Translation with Simulated Human Feedback
Nov 11, 2017
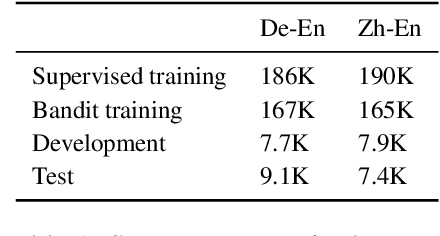
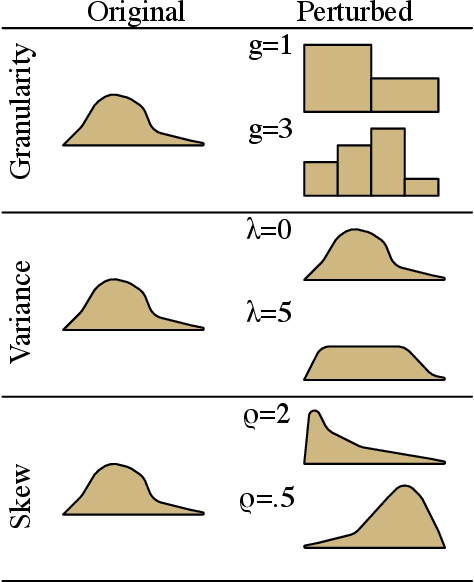
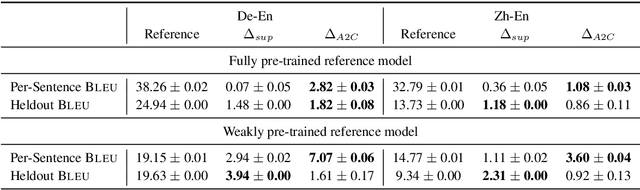
Machine translation is a natural candidate problem for reinforcement learning from human feedback: users provide quick, dirty ratings on candidate translations to guide a system to improve. Yet, current neural machine translation training focuses on expensive human-generated reference translations. We describe a reinforcement learning algorithm that improves neural machine translation systems from simulated human feedback. Our algorithm combines the advantage actor-critic algorithm (Mnih et al., 2016) with the attention-based neural encoder-decoder architecture (Luong et al., 2015). This algorithm (a) is well-designed for problems with a large action space and delayed rewards, (b) effectively optimizes traditional corpus-level machine translation metrics, and (c) is robust to skewed, high-variance, granular feedback modeled after actual human behaviors.
The Amazing Mysteries of the Gutter: Drawing Inferences Between Panels in Comic Book Narratives
May 07, 2017
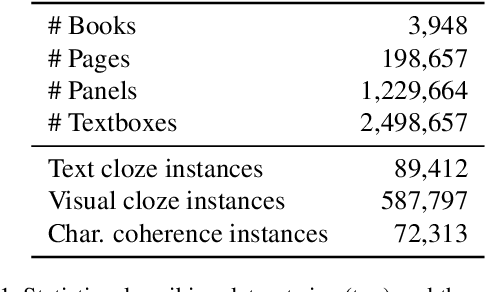

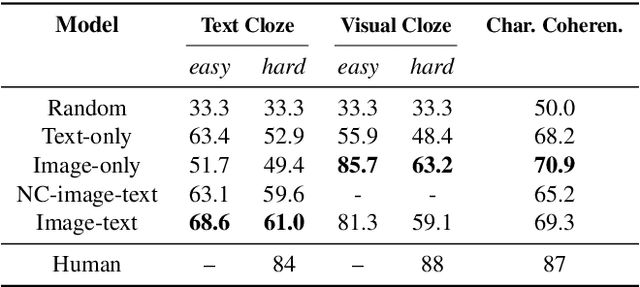
Visual narrative is often a combination of explicit information and judicious omissions, relying on the viewer to supply missing details. In comics, most movements in time and space are hidden in the "gutters" between panels. To follow the story, readers logically connect panels together by inferring unseen actions through a process called "closure". While computers can now describe what is explicitly depicted in natural images, in this paper we examine whether they can understand the closure-driven narratives conveyed by stylized artwork and dialogue in comic book panels. We construct a dataset, COMICS, that consists of over 1.2 million panels (120 GB) paired with automatic textbox transcriptions. An in-depth analysis of COMICS demonstrates that neither text nor image alone can tell a comic book story, so a computer must understand both modalities to keep up with the plot. We introduce three cloze-style tasks that ask models to predict narrative and character-centric aspects of a panel given n preceding panels as context. Various deep neural architectures underperform human baselines on these tasks, suggesting that COMICS contains fundamental challenges for both vision and language.