 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deterministic Uncertainty Estimation in Deep Learning for Classification and Regression
Feb 22, 2021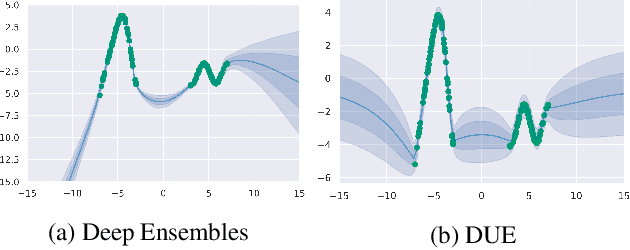

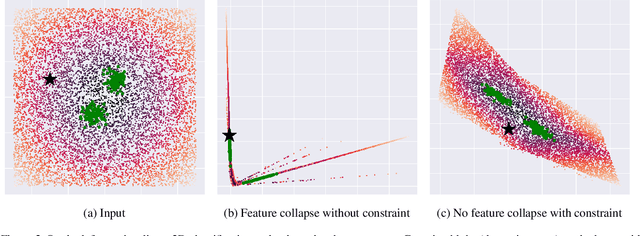
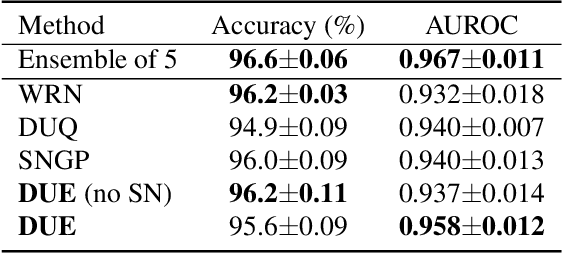
We propose a new model that estimates uncertainty in a single forward pass and works on both classification and regression problems. Our approach combines a bi-Lipschitz feature extractor with an inducing point approximate Gaussian process, offering robust and principled uncertainty estimation. This can be seen as a refinement of Deep Kernel Learning (DKL), with our changes allowing DKL to match softmax neural networks accuracy. Our method overcomes the limitations of previous work addressing deterministic uncertainty quantification, such as the dependence of uncertainty on ad hoc hyper-parameters. Our method matches SotA accuracy, 96.2% on CIFAR-10, while maintaining the speed of softmax models, and provides uncertainty estimates that outperform previous single forward pass uncertainty models. Finally, we demonstrate our method on a recently introduced benchmark for uncertainty in regression: treatment deferral in causal models for personalized medicine.
Single Shot Structured Pruning Before Training
Jul 01, 2020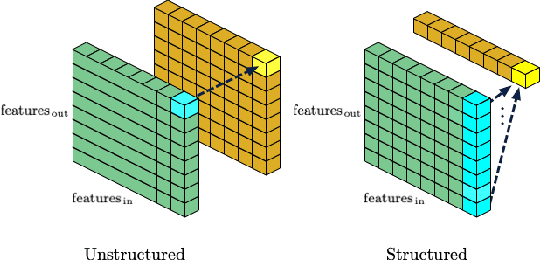
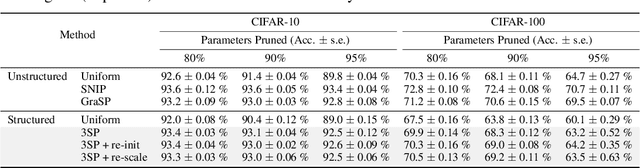
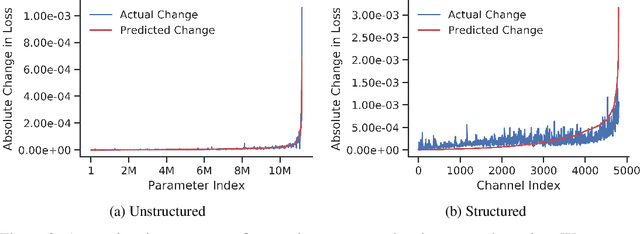

We introduce a method to speed up training by 2x and inference by 3x in deep neural networks using structured pruning applied before training. Unlike previous works on pruning before training which prune individual weights, our work develops a methodology to remove entire channels and hidden units with the explicit aim of speeding up training and inference. We introduce a compute-aware scoring mechanism which enables pruning in units of sensitivity per FLOP removed, allowing even greater speed ups. Our method is fast, easy to implement, and needs just one forward/backward pass on a single batch of data to complete pruning before training begins.
Simple and Scalable Epistemic Uncertainty Estimation Using a Single Deep Deterministic Neural Network
Mar 04, 2020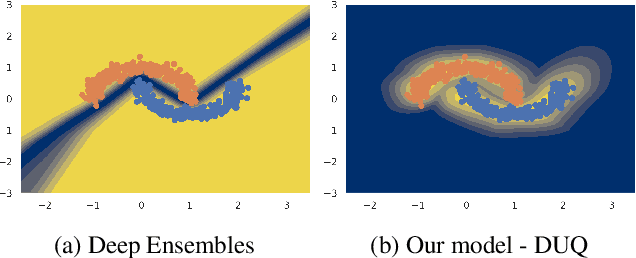

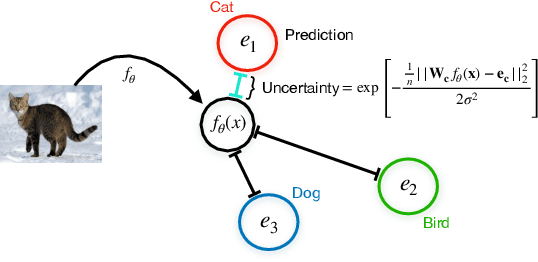

We propose a method for training a deterministic deep model that can find and reject out of distribution data points at test time with a single forward pass. Our approach, deterministic uncertainty quantification (DUQ), builds upon ideas of RBF networks. We scale training in these with a novel loss function and centroid updating scheme. By enforcing detectability of changes in the input using a gradient penalty, we are able to reliably detect out of distribution data. Our uncertainty quantification scales well to large datasets, and using a single model, we improve upon or match Deep Ensembles on notable difficult dataset pairs such as FashionMNIST vs. MNIST, and CIFAR-10 vs. SVHN, while maintaining competitive accuracy.
BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning
Jun 19, 2019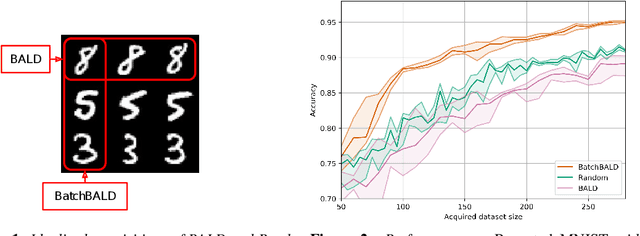
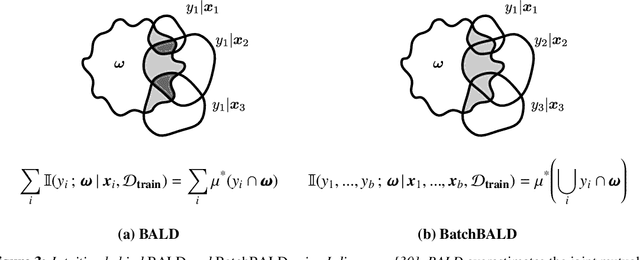
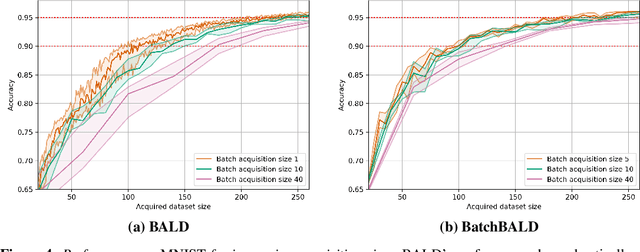
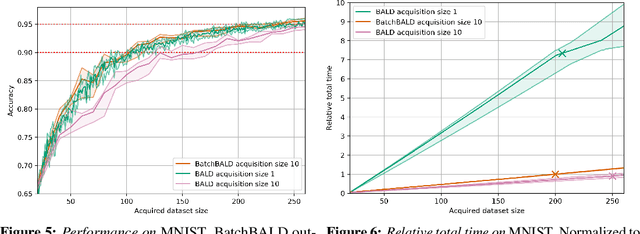
We develop BatchBALD, a tractable approximation to the mutual information between a batch of points and model parameters, which we use as an acquisition function to select multiple informative points jointly for the task of deep Bayesian active learning. BatchBALD is a greedy linear-time $1 - \frac{1}{e}$-approximate algorithm amenable to dynamic programming and efficient caching. We compare BatchBALD to the commonly used approach for batch data acquisition and find that the current approach acquires similar and redundant points, sometimes performing worse than randomly acquiring data. We finish by showing that, using BatchBALD to consider dependencies within an acquisition batch, we achieve new state of the art performance on standard benchmarks, providing substantial data efficiency improvements in batch acquisition.
Deep Hashing using Entropy Regularised Product Quantisation Network
Feb 11, 2019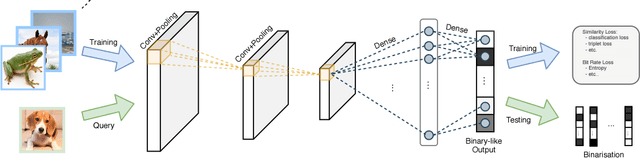
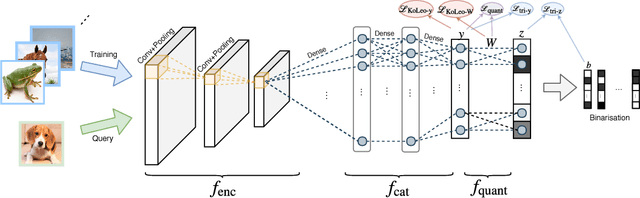
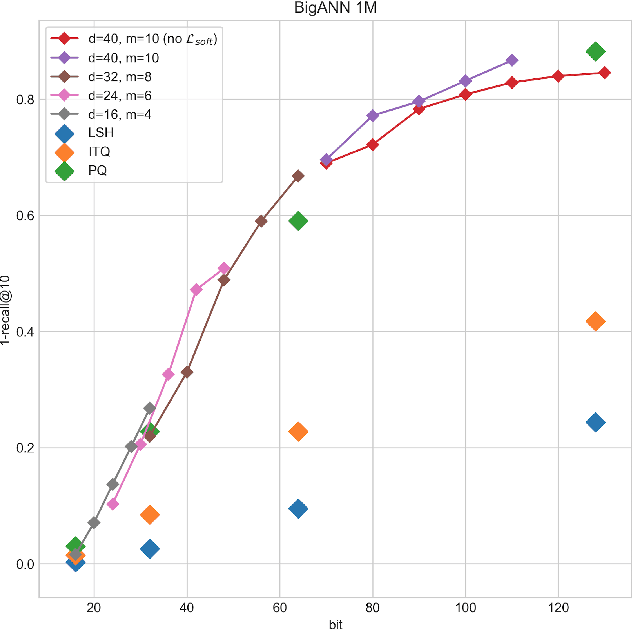
In large scale systems, approximate nearest neighbour search is a crucial algorithm to enable efficient data retrievals. Recently, deep learning-based hashing algorithms have been proposed as a promising paradigm to enable data dependent schemes. Often their efficacy is only demonstrated on data sets with fixed, limited numbers of classes. In practical scenarios, those labels are not always available or one requires a method that can handle a higher input variability, as well as a higher granularity. To fulfil those requirements, we look at more flexible similarity measures. In this work, we present a novel, flexible, end-to-end trainable network for large-scale data hashing. Our method works by transforming the data distribution to behave as a uniform distribution on a product of spheres. The transformed data is subsequently hashed to a binary form in a way that maximises entropy of the output, (i.e. to fully utilise the available bit-rate capacity) while maintaining the correctness (i.e. close items hash to the same key in the map). We show that the method outperforms baseline approaches such as locality-sensitive hashing and product quantisation in the limited capacity regime.
Frame Interpolation with Multi-Scale Deep Loss Functions and Generative Adversarial Networks
Nov 16, 2017

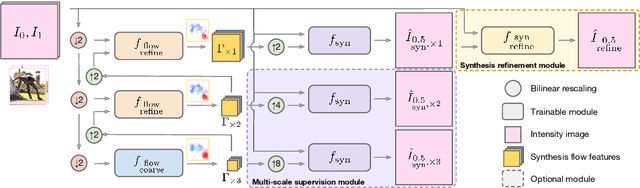
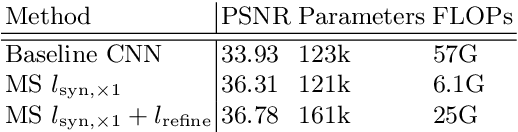
Frame interpolation attempts to synthesise intermediate frames given one or more consecutive video frames. In recent years, deep learning approaches, and in particular convolutional neural networks, have succeeded at tackling low- and high-level computer vision problems including frame interpolation. There are two main pursuits in this line of research, namely algorithm efficiency and reconstruction quality. In this paper, we present a multi-scale generative adversarial network for frame interpolation (FIGAN). To maximise the efficiency of our network, we propose a novel multi-scale residual estimation module where the predicted flow and synthesised frame are constructed in a coarse-to-fine fashion. To improve the quality of synthesised intermediate video frames, our network is jointly supervised at different levels with a perceptual loss function that consists of an adversarial and two content losses. We evaluate the proposed approach using a collection of 60fps videos from YouTube-8m. Our results improve the state-of-the-art accuracy and efficiency, and a subjective visual quality comparable to the best performing interpolation method.
Transformation-Based Models of Video Sequences
Apr 24, 2017

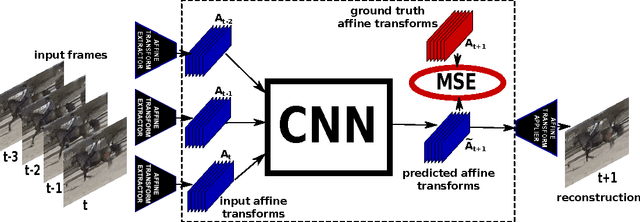
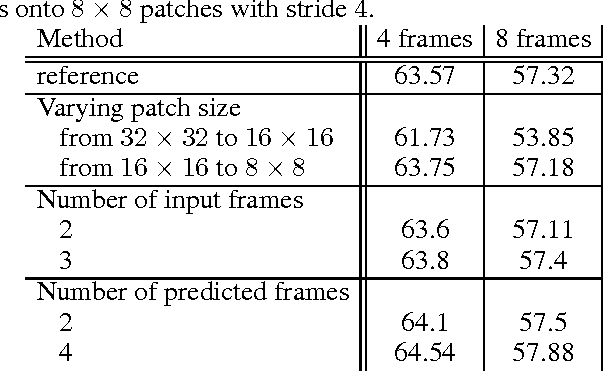
In this work we propose a simple unsupervised approach for next frame prediction in video. Instead of directly predicting the pixels in a frame given past frames, we predict the transformations needed for generating the next frame in a sequence, given the transformations of the past frames. This leads to sharper results, while using a smaller prediction model. In order to enable a fair comparison between different video frame prediction models, we also propose a new evaluation protocol. We use generated frames as input to a classifier trained with ground truth sequences. This criterion guarantees that models scoring high are those producing sequences which preserve discrim- inative features, as opposed to merely penalizing any deviation, plausible or not, from the ground truth. Our proposed approach compares favourably against more sophisticated ones on the UCF-101 data set, while also being more efficient in terms of the number of parameters and computational cost.