 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD Spatio-Temporal Scene Graphs for Video Question Answering
Feb 18, 2022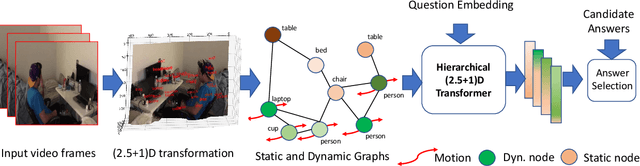
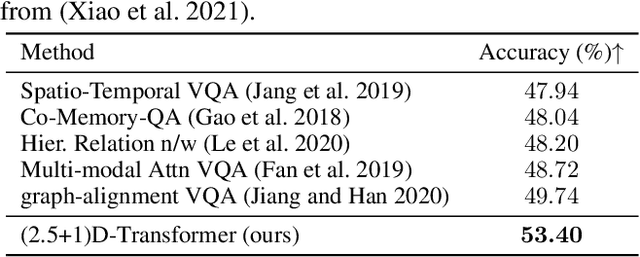
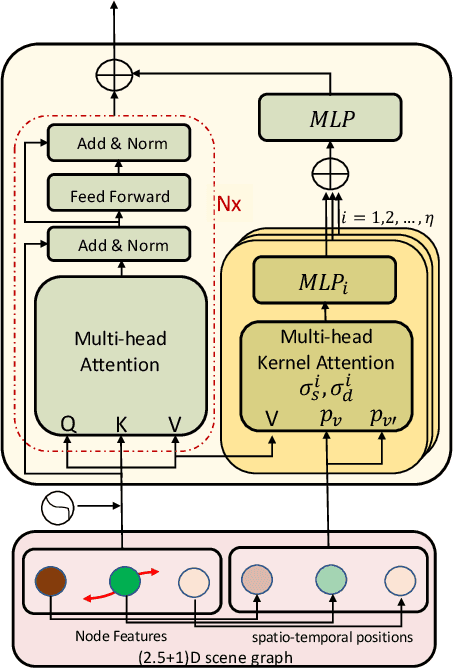
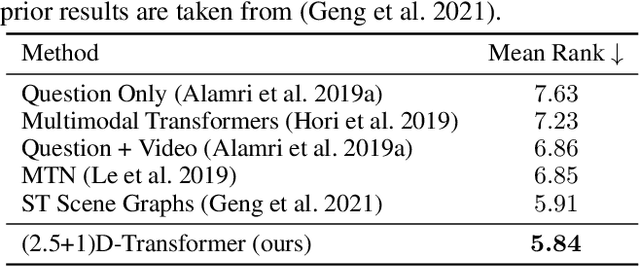
Spatio-temporal scene-graph approaches to video-based reasoning tasks such as video question-answering (QA) typically construct such graphs for every video frame. Such approaches often ignore the fact that videos are essentially sequences of 2D "views" of events happening in a 3D space, and that the semantics of the 3D scene can thus be carried over from frame to frame. Leveraging this insight, we propose a (2.5+1)D scene graph representation to better capture the spatio-temporal information flows inside the videos. Specifically, we first create a 2.5D (pseudo-3D) scene graph by transforming every 2D frame to have an inferred 3D structure using an off-the-shelf 2D-to-3D transformation module, following which we register the video frames into a shared (2.5+1)D spatio-temporal space and ground each 2D scene graph within it. Such a (2.5+1)D graph is then segregated into a static sub-graph and a dynamic sub-graph, corresponding to whether the objects within them usually move in the world. The nodes in the dynamic graph are enriched with motion features capturing their interactions with other graph nodes. Next, for the video QA task, we present a novel transformer-based reasoning pipeline that embeds the (2.5+1)D graph into a spatio-temporal hierarchical latent space, where the sub-graphs and their interactions are captured at varied granularity. To demonstrate the effectiveness of our approach, we present experiments on the NExT-QA and AVSD-QA datasets. Our results show that our proposed (2.5+1)D representation leads to faster training and inference, while our hierarchical model showcases superior performance on the video QA task versus the state of the art.
Sequence Transduction with Graph-based Supervision
Nov 01, 2021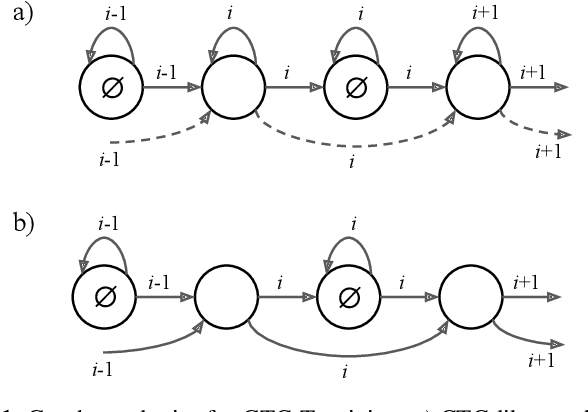
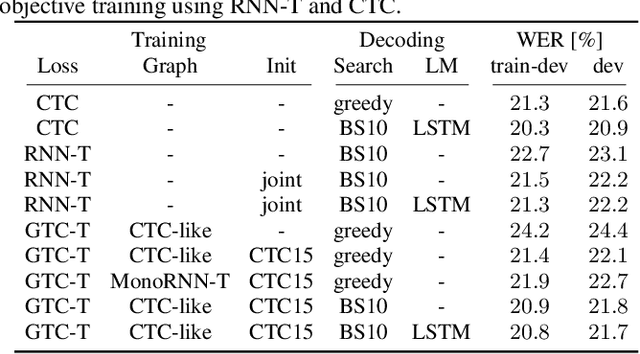
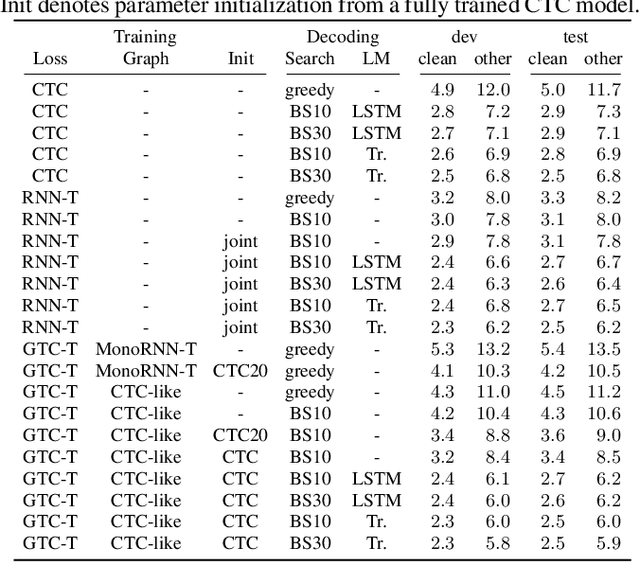
The recurrent neural network transducer (RNN-T) objective plays a major role in building today's best automatic speech recognition (ASR) systems for production. Similarly to the connectionist temporal classification (CTC) objective, the RNN-T loss uses specific rules that define how a set of alignments is generated to form a lattice for the full-sum training. However, it is yet largely unknown if these rules are optimal and do lead to the best possible ASR results. In this work, we present a new transducer objective function that generalizes the RNN-T loss to accept a graph representation of the labels, thus providing a flexible and efficient framework to manipulate training lattices, for example for restricting alignments or studying different transition rules. We demonstrate that transducer-based ASR with CTC-like lattice achieves better results compared to standard RNN-T, while also ensuring a strictly monotonic alignment, which will allow better optimization of the decoding procedure. For example, the proposed CTC-like transducer system achieves a word error rate of 5.9% for the test-other condition of LibriSpeech, corresponding to an improvement of 4.8% relative to an equivalent RNN-T based system.
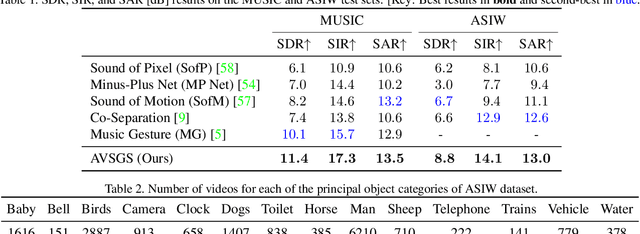
The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks
Oct 19, 2021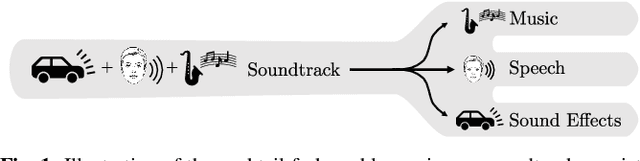
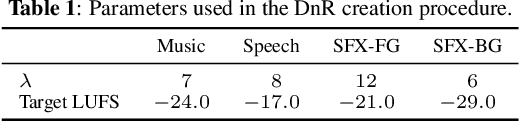
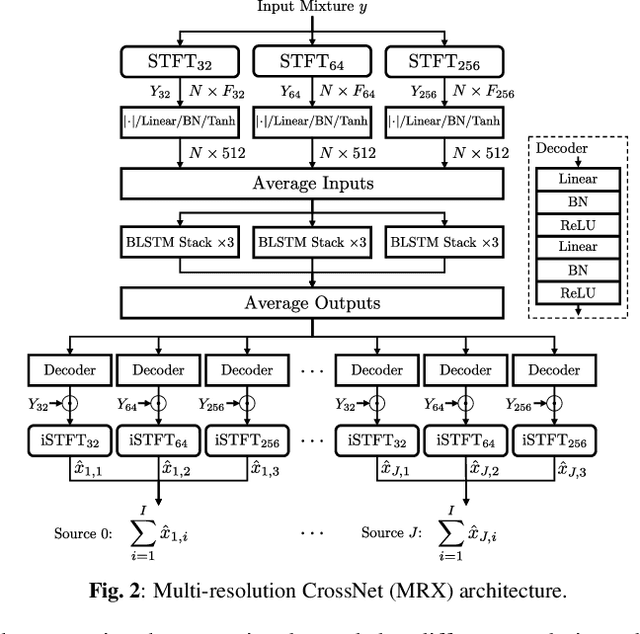
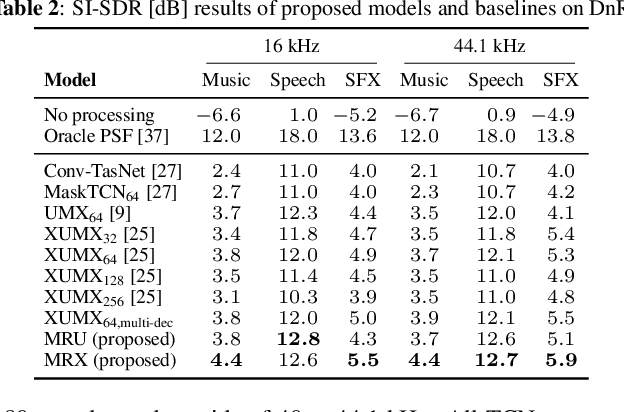
The cocktail party problem aims at isolating any source of interest within a complex acoustic scene, and has long inspired audio source separation research. Recent efforts have mainly focused on separating speech from noise, speech from speech, musical instruments from each other, or sound events from each other. However, separating an audio mixture (e.g., movie soundtrack) into the three broad categories of speech, music, and sound effects (here understood to include ambient noise and natural sound events) has been left largely unexplored, despite a wide range of potential applications. This paper formalizes this task as the cocktail fork problem, and presents the Divide and Remaster (DnR) dataset to foster research on this topic. DnR is built from three well-established audio datasets (LibriVox, FMA, FSD50k), taking care to reproduce conditions similar to professionally produced content in terms of source overlap and relative loudness, and made available at CD quality. We benchmark standard source separation algorithms on DnR, and further introduce a new mixed-STFT-resolution model to better address the variety of acoustic characteristics of the three source types. Our best model produces SI-SDR improvements over the mixture of 11.3 dB for music, 11.8 dB for speech, and 10.9 dB for sound effects.
Audio-Visual Scene-Aware Dialog and Reasoning using Audio-Visual Transformers with Joint Student-Teacher Learning
Oct 13, 2021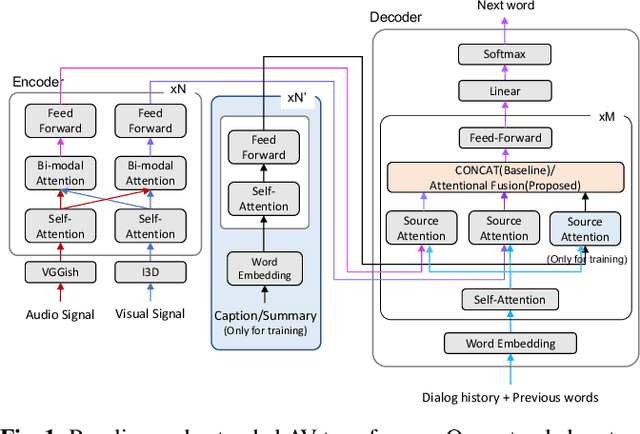
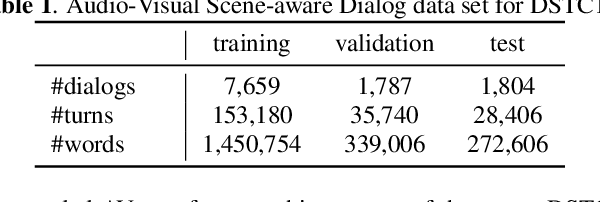
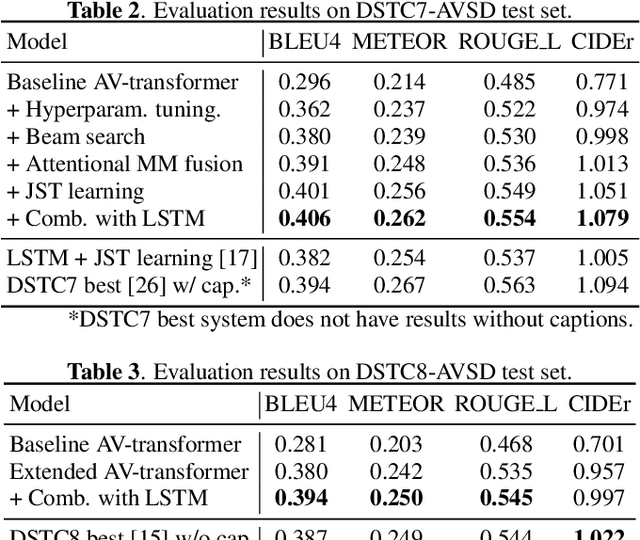
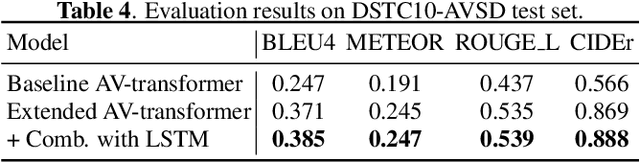
In previous work, we have proposed the Audio-Visual Scene-Aware Dialog (AVSD) task, collected an AVSD dataset, developed AVSD technologies, and hosted an AVSD challenge track at both the 7th and 8th Dialog System Technology Challenges (DSTC7, DSTC8). In these challenges, the best-performing systems relied heavily on human-generated descriptions of the video content, which were available in the datasets but would be unavailable in real-world applications. To promote further advancements for real-world applications, we proposed a third AVSD challenge, at DSTC10, with two modifications: 1) the human-created description is unavailable at inference time, and 2) systems must demonstrate temporal reasoning by finding evidence from the video to support each answer. This paper introduces the new task that includes temporal reasoning and our new extension of the AVSD dataset for DSTC10, for which we collected human-generated temporal reasoning data. We also introduce a baseline system built using an AV-transformer, which we released along with the new dataset. Finally, this paper introduces a new system that extends our baseline system with attentional multimodal fusion, joint student-teacher learning (JSTL), and model combination techniques, achieving state-of-the-art performances on the AVSD datasets for DSTC7, DSTC8, and DSTC10. We also propose two temporal reasoning methods for AVSD: one attention-based, and one based on a time-domain region proposal network.
Advancing Momentum Pseudo-Labeling with Conformer and Initialization Strategy
Oct 11, 2021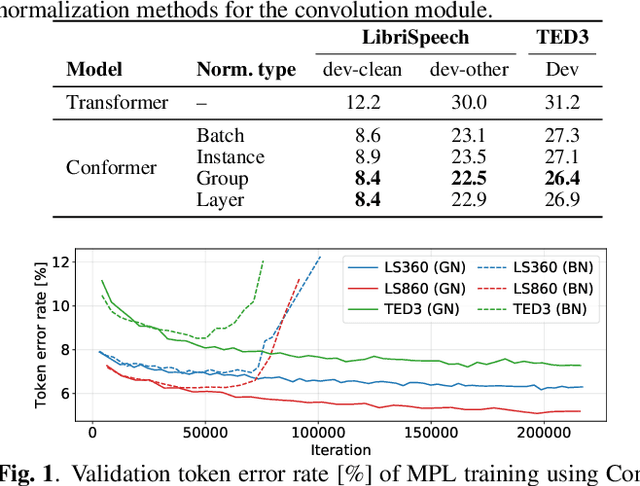
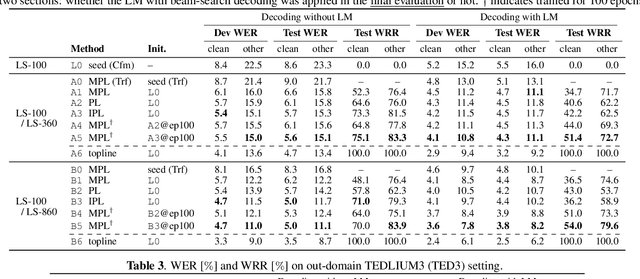
Pseudo-labeling (PL), a semi-supervised learning (SSL) method where a seed model performs self-training using pseudo-labels generated from untranscribed speech, has been shown to enhance the performance of end-to-end automatic speech recognition (ASR). Our prior work proposed momentum pseudo-labeling (MPL), which performs PL-based SSL via an interaction between online and offline models, inspired by the mean teacher framework. MPL achieves remarkable results on various semi-supervised settings, showing robustness to variations in the amount of data and domain mismatch severity. However, there is further room for improving the seed model used to initialize the MPL training, as it is in general critical for a PL-based method to start training from high-quality pseudo-labels. To this end, we propose to enhance MPL by (1) introducing the Conformer architecture to boost the overall recognition accuracy and (2) exploiting iterative pseudo-labeling with a language model to improve the seed model before applying MPL. The experimental results demonstrate that the proposed approaches effectively improve MPL performance, outperforming other PL-based methods. We also present in-depth investigations to make our improvements effective, e.g., with regard to batch normalization typically used in Conformer and LM quality.
Leveraging Low-Distortion Target Estimates for Improved Speech Enhancement
Oct 01, 2021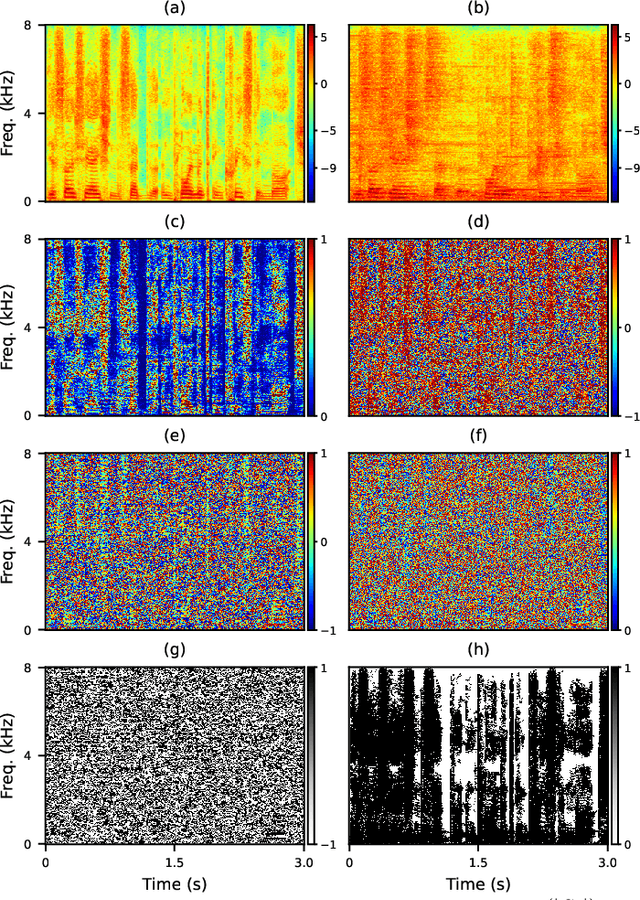
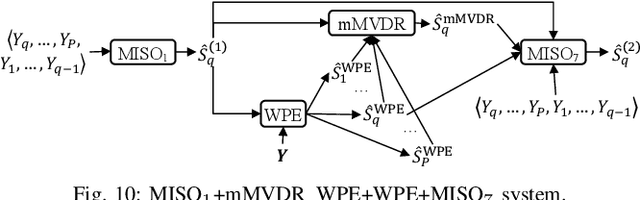
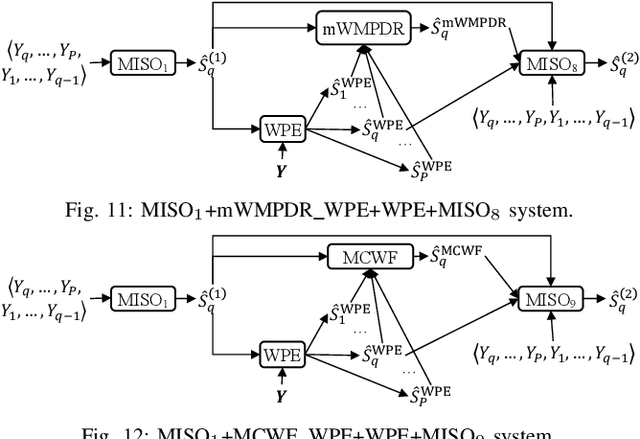
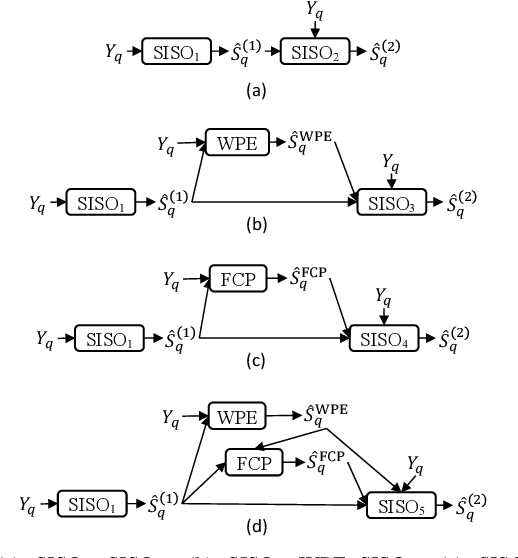
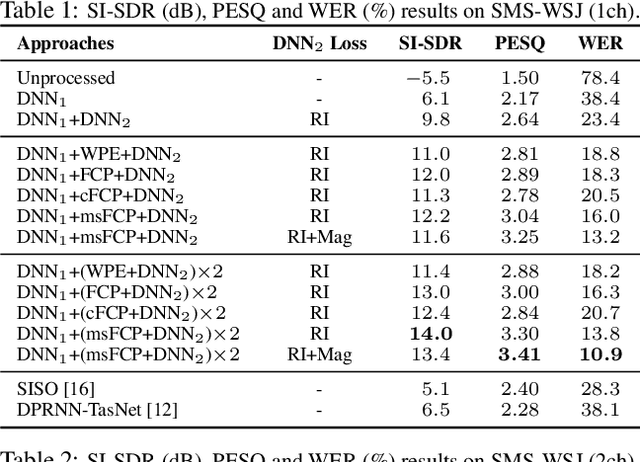
A promising approach for multi-microphone speech separation involves two deep neural networks (DNN), where the predicted target speech from the first DNN is used to compute signal statistics for time-invariant minimum variance distortionless response (MVDR) beamforming, and the MVDR result is then used as extra features for the second DNN to predict target speech. Previous studies suggested that the MVDR result can provide complementary information for the second DNN to better predict target speech. However, on fixed-geometry arrays, both DNNs can take in, for example, the real and imaginary (RI) components of the multi-channel mixture as features to leverage the spatial and spectral information for enhancement. It is not explained clearly why the linear MVDR result can be complementary and why it is still needed, considering that the DNNs and the beamformer use the same input, and the DNNs perform non-linear filtering and could render the linear filtering of MVDR unnecessary. Similarly, in monaural cases, one can replace the MVDR beamformer with a monaural weighted prediction error (WPE) filter. Although the linear WPE filter and the DNNs use the same mixture RI components as input, the WPE result is found to significantly improve the second DNN. This study provides a novel explanation from the perspective of the low-distortion nature of such algorithms, and finds that they can consistently improve phase estimation. Equipped with this understanding, we investigate several low-distortion target estimation algorithms including several beamformers, WPE, forward convolutive prediction, and their combinations, and use their results as extra features to train the second network to achieve better enhancement. Evaluation results on single- and multi-microphone speech dereverberation and enhancement tasks indicate the effectiveness of the proposed approach, and the validity of the proposed view.
Visual Scene Graphs for Audio Source Separation
Sep 24, 2021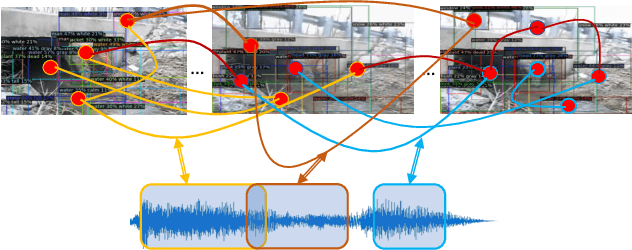
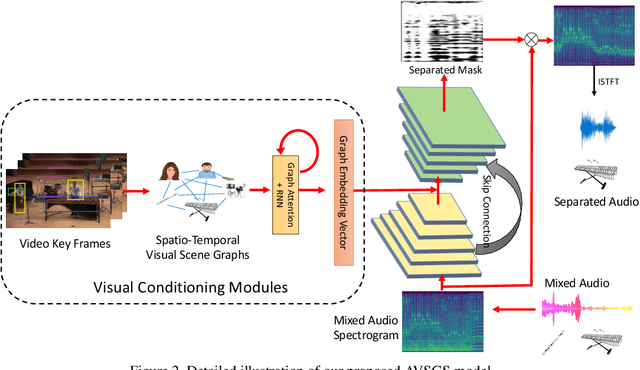
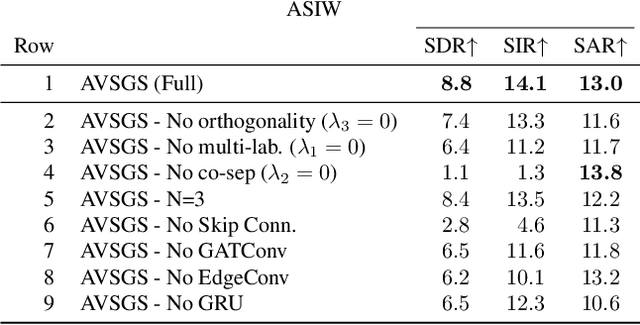
State-of-the-art approaches for visually-guided audio source separation typically assume sources that have characteristic sounds, such as musical instruments. These approaches often ignore the visual context of these sound sources or avoid modeling object interactions that may be useful to better characterize the sources, especially when the same object class may produce varied sounds from distinct interactions. To address this challenging problem, we propose Audio Visual Scene Graph Segmenter (AVSGS), a novel deep learning model that embeds the visual structure of the scene as a graph and segments this graph into subgraphs, each subgraph being associated with a unique sound obtained by co-segmenting the audio spectrogram. At its core, AVSGS uses a recursive neural network that emits mutually-orthogonal sub-graph embeddings of the visual graph using multi-head attention. These embeddings are used for conditioning an audio encoder-decoder towards source separation. Our pipeline is trained end-to-end via a self-supervised task consisting of separating audio sources using the visual graph from artificially mixed sounds. In this paper, we also introduce an "in the wild'' video dataset for sound source separation that contains multiple non-musical sources, which we call Audio Separation in the Wild (ASIW). This dataset is adapted from the AudioCaps dataset, and provides a challenging, natural, and daily-life setting for source separation. Thorough experiments on the proposed ASIW and the standard MUSIC datasets demonstrate state-of-the-art sound separation performance of our method against recent prior approaches.
Convolutive Prediction for Monaural Speech Dereverberation and Noisy-Reverberant Speaker Separation
Aug 16, 2021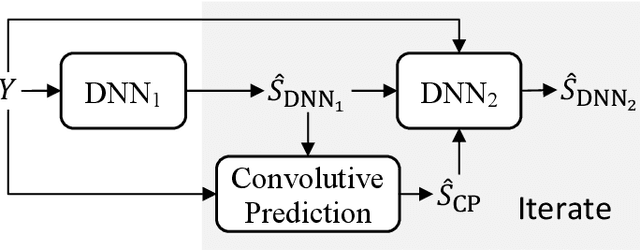
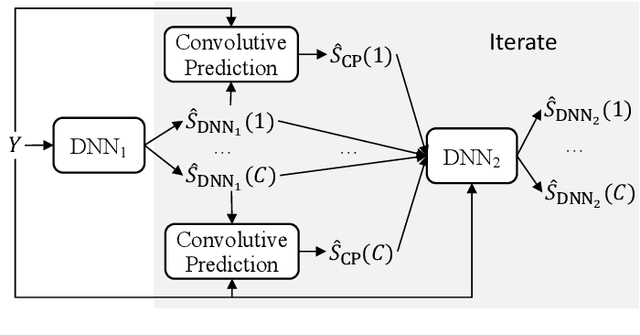
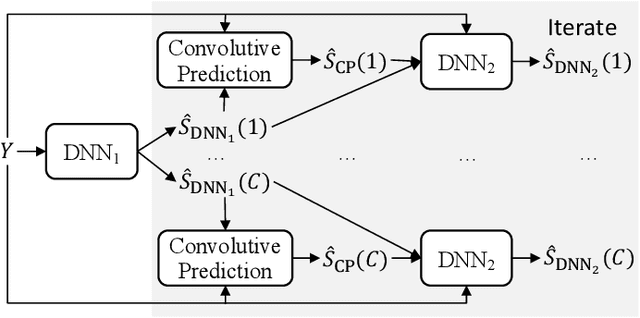
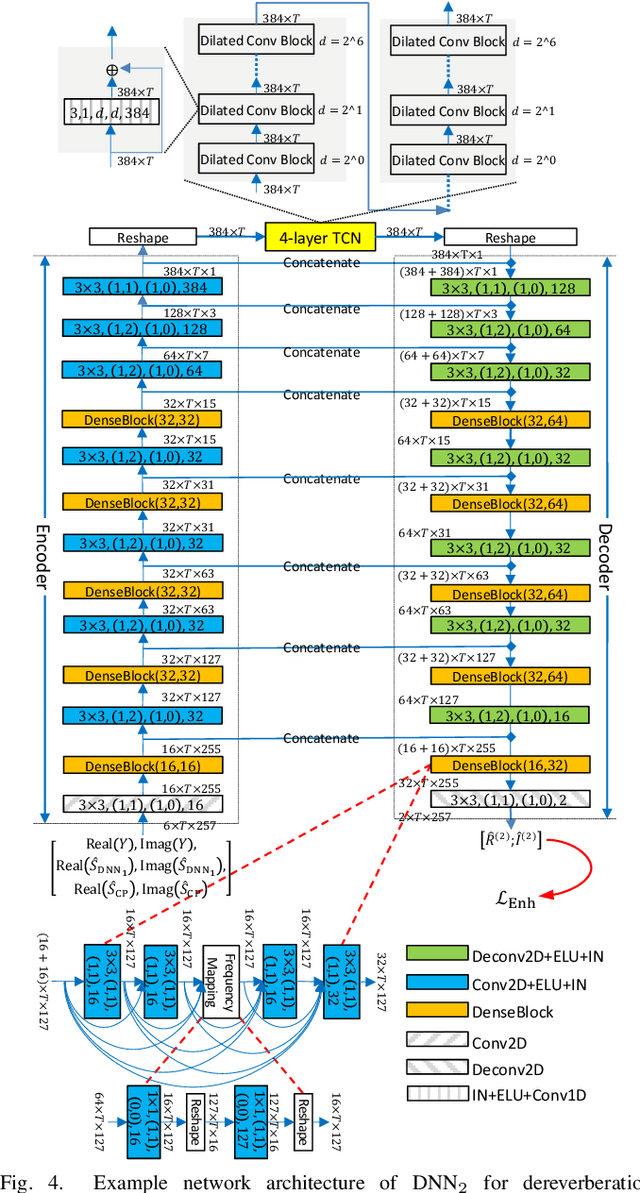
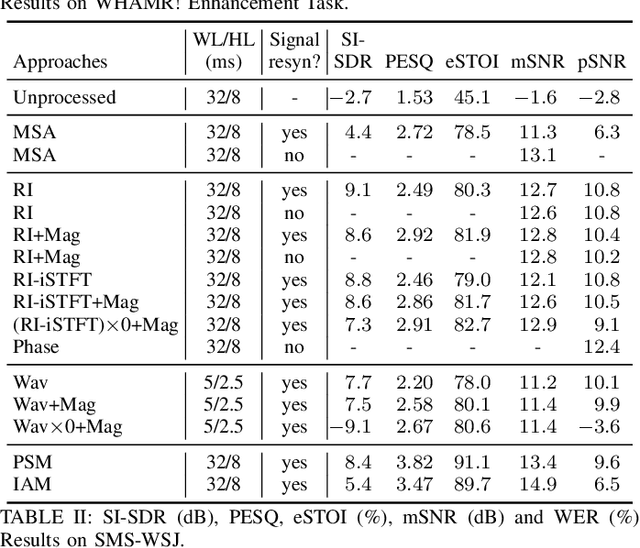
A promising approach for speech dereverberation is based on supervised learning, where a deep neural network (DNN) is trained to predict the direct sound from noisy-reverberant speech. This data-driven approach is based on leveraging prior knowledge of clean speech patterns and does not explicitly exploit the linear-filter structure in reverberation, i.e., that reverberation results from a linear convolution between a room impulse response (RIR) and a dry source signal. In this work, we propose to exploit this linear-filter structure within a deep learning based monaural speech dereverberation framework. The key idea is to first estimate the direct-path signal of the target speaker using a DNN and then identify signals that are decayed and delayed copies of the estimated direct-path signal, as these can be reliably considered as reverberation. They can be either directly removed for dereverberation, or used as extra features for another DNN to perform better dereverberation. To identify the copies, we estimate the underlying filter (or RIR) by efficiently solving a linear regression problem per frequency in the time-frequency domain. We then modify the proposed algorithm for speaker separation in reverberant and noisy-reverberant conditions. State-of-the-art speech dereverberation and speaker separation results are obtained on the REVERB, SMS-WSJ, and WHAMR! datasets.
Convolutive Prediction for Reverberant Speech Separation
Aug 16, 2021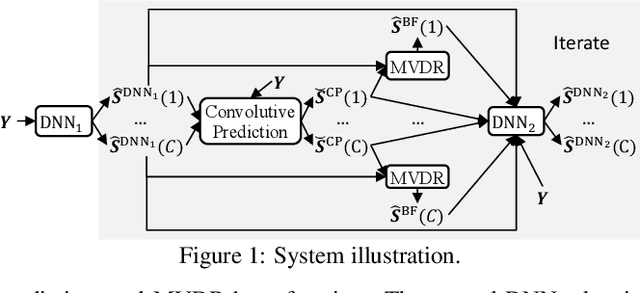
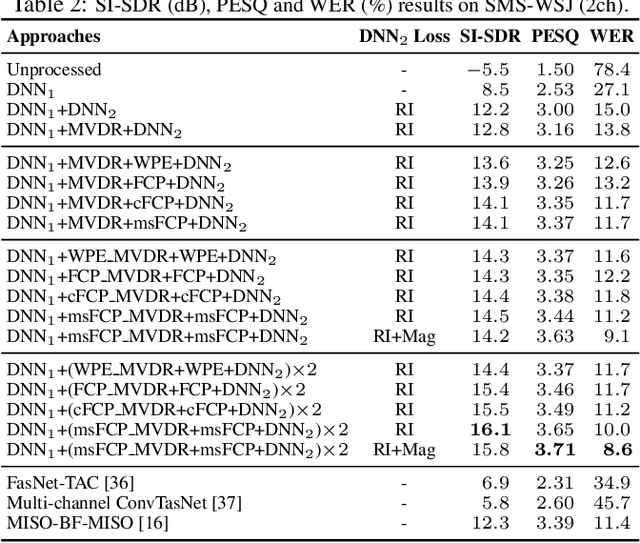
We investigate the effectiveness of convolutive prediction, a novel formulation of linear prediction for speech dereverberation, for speaker separation in reverberant conditions. The key idea is to first use a deep neural network (DNN) to estimate the direct-path signal of each speaker, and then identify delayed and decayed copies of the estimated direct-path signal. Such copies are likely due to reverberation, and can be directly removed for dereverberation or used as extra features for another DNN to perform better dereverberation and separation. To identify such copies, we solve a linear regression problem per frequency efficiently in the time-frequency (T-F) domain to estimate the underlying room impulse response (RIR). In the multi-channel extension, we perform minimum variance distortionless response (MVDR) beamforming on the outputs of convolutive prediction. The beamforming and dereverberation results are used as extra features for a second DNN to perform better separation and dereverberation. State-of-the-art results are obtained on the SMS-WSJ corpus.
On The Compensation Between Magnitude and Phase in Speech Separation
Aug 11, 2021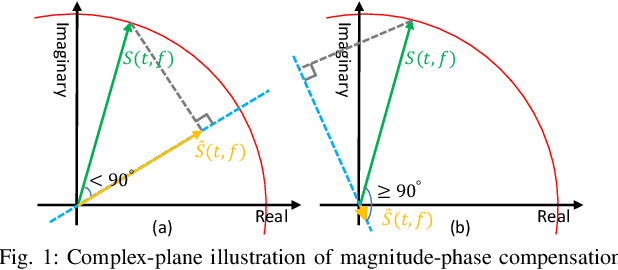
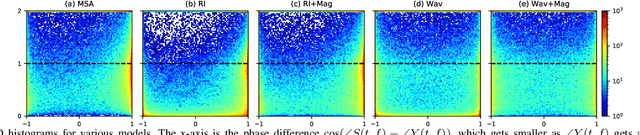
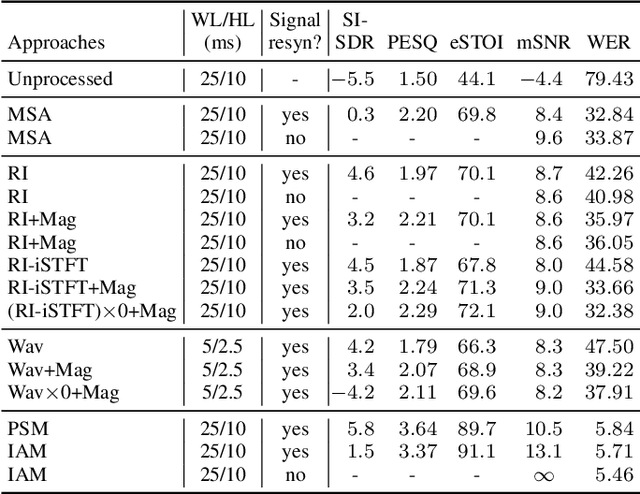
Deep neural network (DNN) based end-to-end optimization in the complex time-frequency (T-F) domain or time domain has shown considerable potential in monaural speech separation. Many recent studies optimize loss functions defined solely in the time or complex domain, without including a loss on magnitude. Although such loss functions typically produce better scores if the evaluation metrics are objective time-domain metrics, they however produce worse scores on speech quality and intelligibility metrics and usually lead to worse speech recognition performance, compared with including a loss on magnitude. While this phenomenon has been experimentally observed by many studies, it is often not accurately explained and there lacks a thorough understanding on its fundamental cause. This paper provides a novel view from the perspective of the implicit compensation between estimated magnitude and phase. Analytical results based on monaural speech separation and robust automatic speech recognition (ASR) tasks in noisy-reverberant conditions support the validity of our view.