 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Video Representations from Textual Web Supervision
Jul 29, 2020
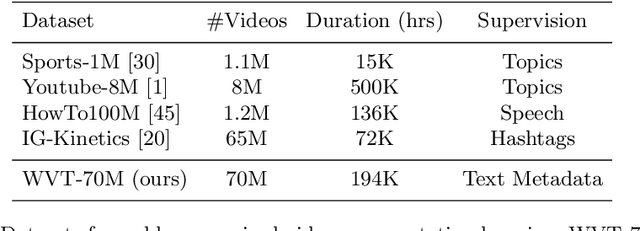
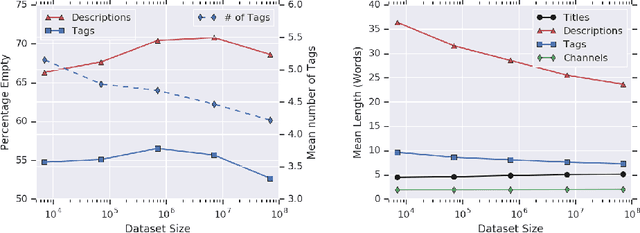

Videos found on the Internet are paired with pieces of text, such as titles and descriptions. This text typically describes the most important content in the video, such as the objects in the scene and the actions being performed. Based on this observation, we propose to use such text as a method for learning video representations. To accomplish this, we propose a data collection process and use it to collect 70M video clips shared publicly on the Internet, and we then train a model to pair each video with its associated text. We fine-tune the model on several down-stream action recognition tasks, including Kinetics, HMDB-51, and UCF-101. We find that this approach is an effective method of pretraining video representations. Specifically, it leads to improvements over from-scratch training on all benchmarks, outperforms many methods for self-supervised and webly-supervised video representation learning, and achieves an improvement of 2.2% accuracy on HMDB-51.
Compositional Temporal Visual Grounding of Natural Language Event Descriptions
Dec 04, 2019

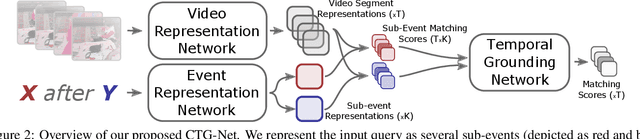
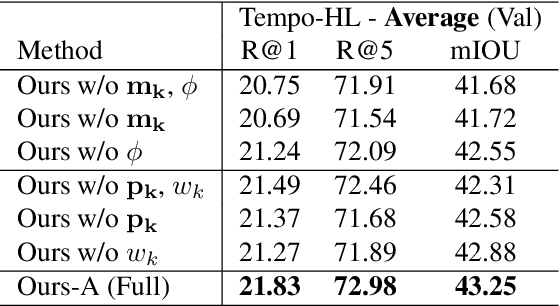
Temporal grounding entails establishing a correspondence between natural language event descriptions and their visual depictions. Compositional modeling becomes central: we first ground atomic descriptions "girl eating an apple," "batter hitting the ball" to short video segments, and then establish the temporal relationships between the segments. This compositional structure enables models to recognize a wider variety of events not seen during training through recognizing their atomic sub-events. Explicit temporal modeling accounts for a wide variety of temporal relationships that can be expressed in language: e.g., in the description "girl stands up from the table after eating an apple" the visual ordering of the events is reversed, with first "eating an apple" followed by "standing up from the table." We leverage these observations to develop a unified deep architecture, CTG-Net, to perform temporal grounding of natural language event descriptions to videos. We demonstrate that our system outperforms prior state-of-the-art methods on the DiDeMo, Tempo-TL, and Tempo-HL temporal grounding datasets.
D3D: Distilled 3D Networks for Video Action Recognition
Dec 19, 2018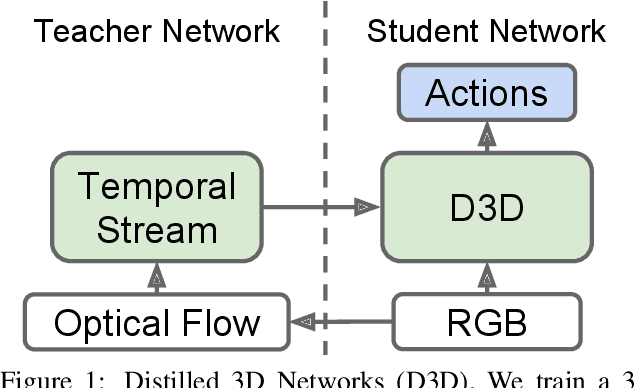
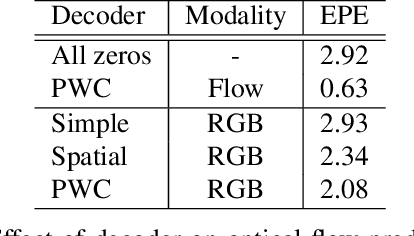
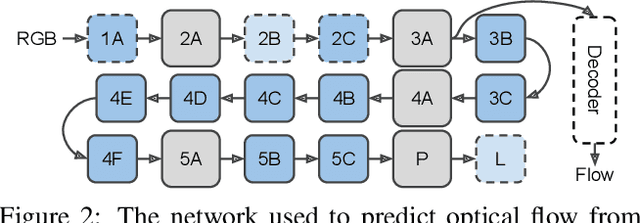
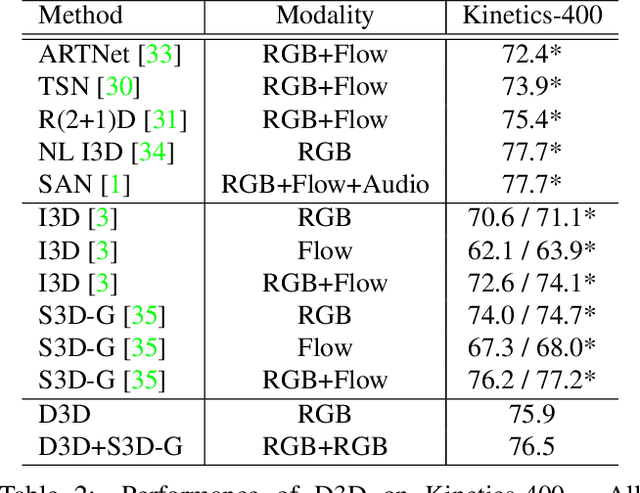
State-of-the-art methods for video action recognition commonly use an ensemble of two networks: the spatial stream, which takes RGB frames as input, and the temporal stream, which takes optical flow as input. In recent work, both of these streams consist of 3D Convolutional Neural Networks, which apply spatiotemporal filters to the video clip before performing classification. Conceptually, the temporal filters should allow the spatial stream to learn motion representations, making the temporal stream redundant. However, we still see significant benefits in action recognition performance by including an entirely separate temporal stream, indicating that the spatial stream is "missing" some of the signal captured by the temporal stream. In this work, we first investigate whether motion representations are indeed missing in the spatial stream of 3D CNNs. Second, we demonstrate that these motion representations can be improved by distillation, by tuning the spatial stream to predict the outputs of the temporal stream, effectively combining both models into a single stream. Finally, we show that our Distilled 3D Network (D3D) achieves performance on par with two-stream approaches, using only a single model and with no need to compute optical flow.