 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sample-Optimal Compressive Phase Retrieval with Sparse and Generative Priors
Jun 29, 2021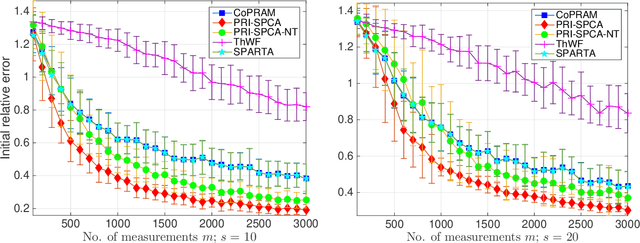
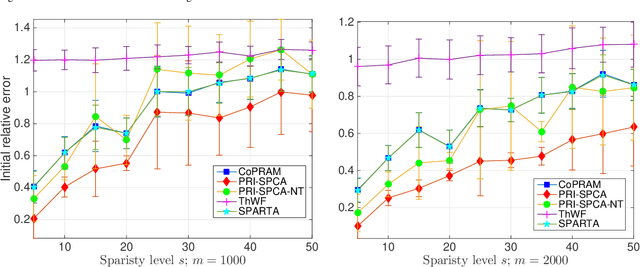
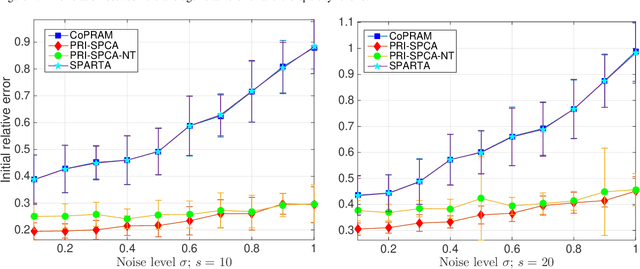
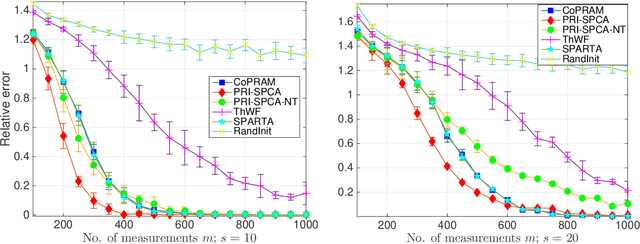
Compressive phase retrieval is a popular variant of the standard compressive sensing problem, in which the measurements only contain magnitude information. In this paper, motivated by recent advances in deep generative models, we provide recovery guarantees with order-optimal sample complexity bounds for phase retrieval with generative priors. We first show that when using i.i.d. Gaussian measurements and an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs, roughly $O(k \log L)$ samples suffice to guarantee that the signal is close to any vector that minimizes an amplitude-based empirical loss function. Attaining this sample complexity with a practical algorithm remains a difficult challenge, and a popular spectral initialization method has been observed to pose a major bottleneck. To partially address this, we further show that roughly $O(k \log L)$ samples ensure sufficient closeness between the signal and any {\em globally optimal} solution to an optimization problem designed for spectral initialization (though finding such a solution may still be challenging). We adapt this result to sparse phase retrieval, and show that $O(s \log n)$ samples are sufficient for a similar guarantee when the underlying signal is $s$-sparse and $n$-dimensional, matching an information-theoretic lower bound. While our guarantees do not directly correspond to a practical algorithm, we propose a practical spectral initialization method motivated by our findings, and experimentally observe significant performance gains over various existing spectral initialization methods of sparse phase retrieval.
Lenient Regret and Good-Action Identification in Gaussian Process Bandits
Feb 11, 2021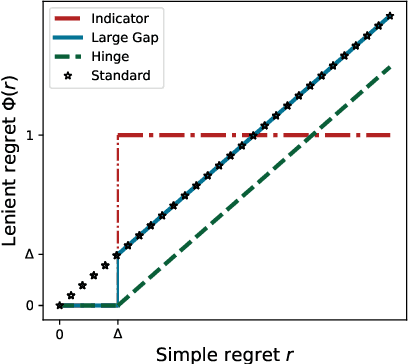
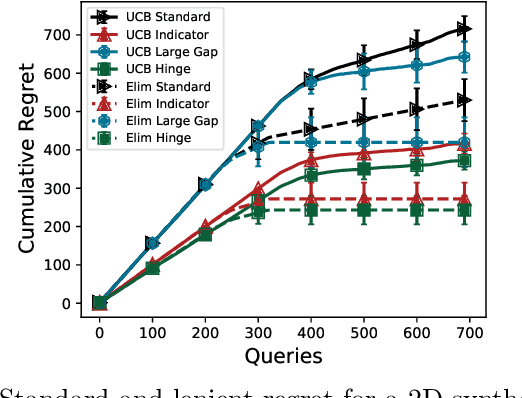
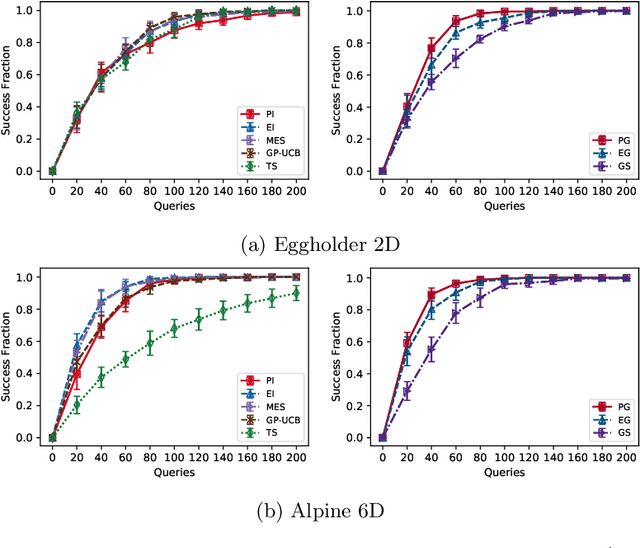
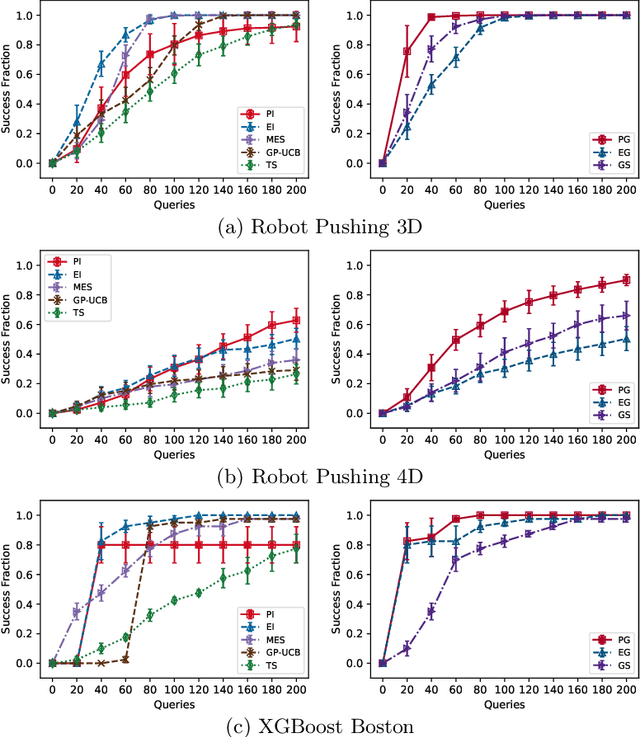
In this paper, we study the problem of Gaussian process (GP) bandits under relaxed optimization criteria stating that any function value above a certain threshold is "good enough". On the theoretical side, we study various \emph{\lenient regret} notions in which all near-optimal actions incur zero penalty, and provide upper bounds on the lenient regret for GP-UCB and an elimination algorithm, circumventing the usual $O(\sqrt{T})$ term (with time horizon $T$) resulting from zooming extremely close towards the function maximum. In addition, we complement these upper bounds with algorithm-independent lower bounds. On the practical side, we consider the problem of finding a single "good action" according to a known pre-specified threshold, and introduce several good-action identification algorithms that exploit knowledge of the threshold. We experimentally find that such algorithms can often find a good action faster than standard optimization-based approaches.
High-Dimensional Bayesian Optimization via Tree-Structured Additive Models
Dec 24, 2020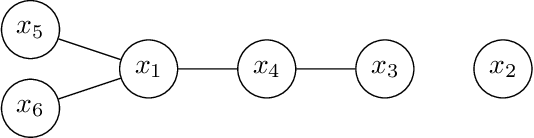
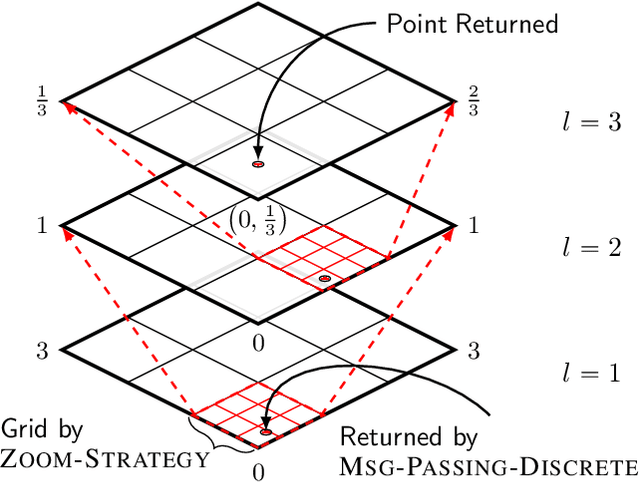
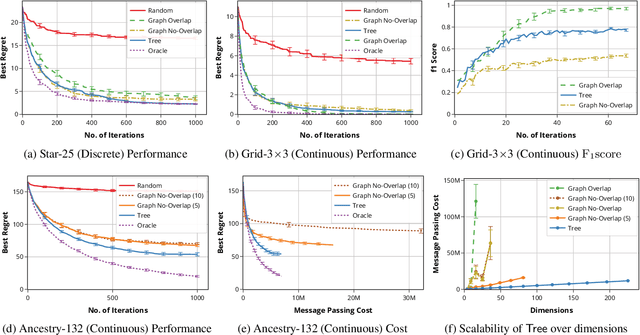
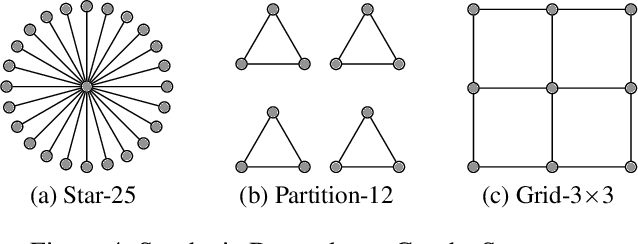
Bayesian Optimization (BO) has shown significant success in tackling expensive low-dimensional black-box optimization problems. Many optimization problems of interest are high-dimensional, and scaling BO to such settings remains an important challenge. In this paper, we consider generalized additive models in which low-dimensional functions with overlapping subsets of variables are composed to model a high-dimensional target function. Our goal is to lower the computational resources required and facilitate faster model learning by reducing the model complexity while retaining the sample-efficiency of existing methods. Specifically, we constrain the underlying dependency graphs to tree structures in order to facilitate both the structure learning and optimization of the acquisition function. For the former, we propose a hybrid graph learning algorithm based on Gibbs sampling and mutation. In addition, we propose a novel zooming-based algorithm that permits generalized additive models to be employed more efficiently in the case of continuous domains. We demonstrate and discuss the efficacy of our approach via a range of experiments on synthetic functions and real-world datasets.
On Lower Bounds for Standard and Robust Gaussian Process Bandit Optimization
Aug 20, 2020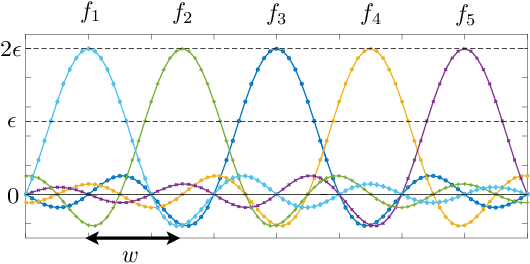
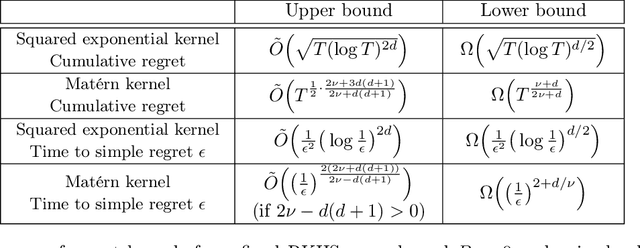
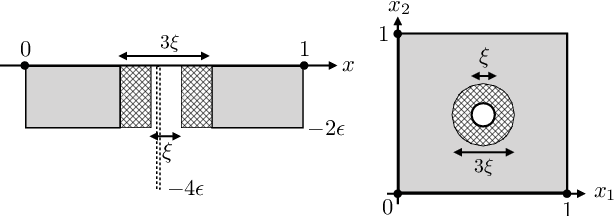
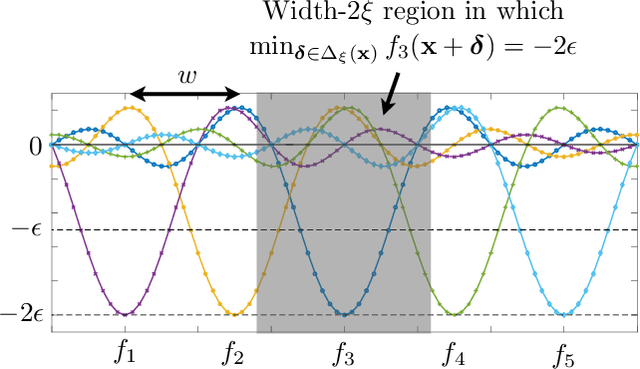
In this paper, we consider algorithm-independent lower bounds for the problem of black-box optimization of functions having a bounded norm is some Reproducing Kernel Hilbert Space (RKHS), which can be viewed as a non-Bayesian Gaussian process bandit problem. In the standard noisy setting, we provide a novel proof technique for deriving lower bounds on the regret, with benefits including simplicity, versatility, and an improved dependence on the error probability. In a robust setting in which every sampled point may be perturbed by a suitably-constrained adversary, we provide a novel lower bound for deterministic strategies, demonstrating an inevitable joint dependence of the cumulative regret on the corruption level and the time horizon, in contrast with existing lower bounds that only characterize the individual dependencies. Furthermore, in a distinct robust setting in which the final point is perturbed by an adversary, we strengthen an existing lower bound that only holds for target success probabilities very close to one, by allowing for arbitrary success probabilities in $(0,1)$.
Stochastic Linear Bandits Robust to Adversarial Attacks
Jul 07, 2020

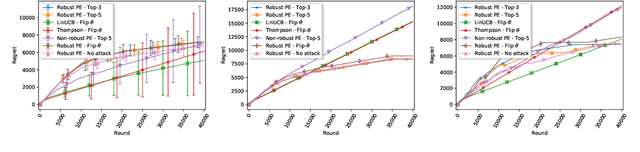
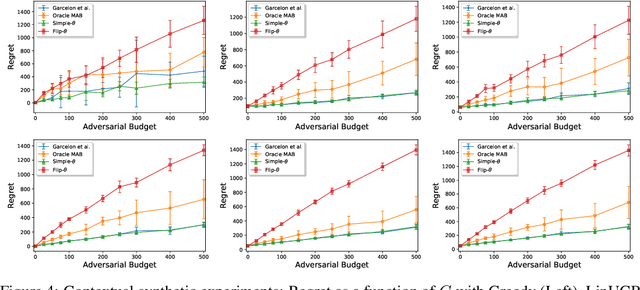
We consider a stochastic linear bandit problem in which the rewards are not only subject to random noise, but also adversarial attacks subject to a suitable budget $C$ (i.e., an upper bound on the sum of corruption magnitudes across the time horizon). We provide two variants of a Robust Phased Elimination algorithm, one that knows $C$ and one that does not. Both variants are shown to attain near-optimal regret in the non-corrupted case $C = 0$, while incurring additional additive terms respectively having a linear and quadratic dependency on $C$ in general. We present algorithm independent lower bounds showing that these additive terms are near-optimal. In addition, in a contextual setting, we revisit a setup of diverse contexts, and show that a simple greedy algorithm is provably robust with a near-optimal additive regret term, despite performing no explicit exploration and not knowing $C$.
The Generalized Lasso with Nonlinear Observations and Generative Priors
Jun 23, 2020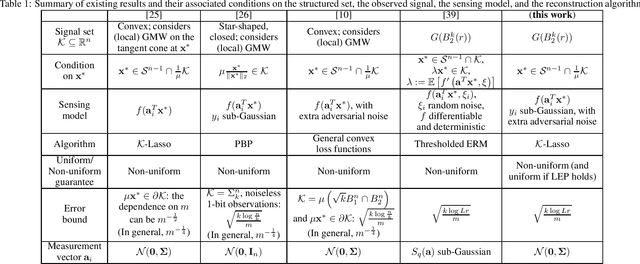
In this paper, we study the problem of signal estimation from noisy non-linear measurements when the unknown $n$-dimensional signal is in the range of an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs. We make the assumption of sub-Gaussian measurements, which is satisfied by a wide range of measurement models, such as linear, logistic, 1-bit, and other quantized models. In addition, we consider the impact of adversarial corruptions on these measurements. Our analysis is based on a generalized Lasso approach (Plan and Vershynin, 2016). We first provide a non-uniform recovery guarantee, which states that under i.i.d. Gaussian measurements, roughly $O\left(\frac{k}{\epsilon^2}\log L\right)$ samples suffice for recovery with an $\ell_2$-error of $\epsilon$, and that this scheme is robust to adversarial noise. Then, we apply this result to neural network generative models, and discuss various extensions to other models and non-i.i.d. measurements. Moreover, we show that our result can be extended to the uniform recovery guarantee whenever a so-called local embedding property holds. For instance, under 1-bit measurements, this recovers an existing $O\left(\frac{k}{\epsilon^2}\log L\right)$ sample complexity bound with the advantage of using an algorithm that is more amenable to practical implementation.
Corruption-Tolerant Gaussian Process Bandit Optimization
Mar 04, 2020
We consider the problem of optimizing an unknown (typically non-convex) function with a bounded norm in some Reproducing Kernel Hilbert Space (RKHS), based on noisy bandit feedback. We consider a novel variant of this problem in which the point evaluations are not only corrupted by random noise, but also adversarial corruptions. We introduce an algorithm Fast-Slow GP-UCB based on Gaussian process methods, randomized selection between two instances labeled "fast" (but non-robust) and "slow" (but robust), enlarged confidence bounds, and the principle of optimism under uncertainty. We present a novel theoretical analysis upper bounding the cumulative regret in terms of the corruption level, the time horizon, and the underlying kernel, and we argue that certain dependencies cannot be improved. We observe that distinct algorithmic ideas are required depending on whether one is required to perform well in both the corrupted and non-corrupted settings, and whether the corruption level is known or not.
Learning Gaussian Graphical Models via Multiplicative Weights
Feb 25, 2020Graphical model selection in Markov random fields is a fundamental problem in statistics and machine learning. Two particularly prominent models, the Ising model and Gaussian model, have largely developed in parallel using different (though often related) techniques, and several practical algorithms with rigorous sample complexity bounds have been established for each. In this paper, we adapt a recently proposed algorithm of Klivans and Meka (FOCS, 2017), based on the method of multiplicative weight updates, from the Ising model to the Gaussian model, via non-trivial modifications to both the algorithm and its analysis. The algorithm enjoys a sample complexity bound that is qualitatively similar to others in the literature, has a low runtime $O(mp^2)$ in the case of $m$ samples and $p$ nodes, and can trivially be implemented in an online manner.
Sample Complexity Bounds for 1-bit Compressive Sensing and Binary Stable Embeddings with Generative Priors
Feb 12, 2020
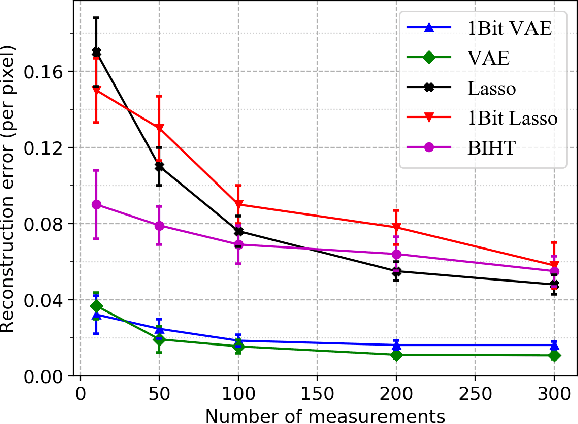
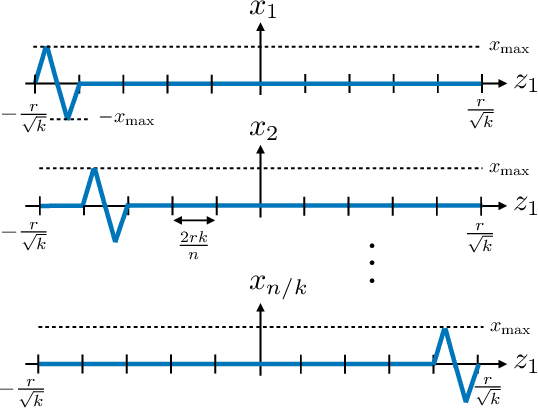
The goal of standard 1-bit compressive sensing is to accurately recover an unknown sparse vector from binary-valued measurements, each indicating the sign of a linear function of the vector. Motivated by recent advances in compressive sensing with generative models, where a generative modeling assumption replaces the usual sparsity assumption, we study the problem of 1-bit compressive sensing with generative models. We first consider noiseless 1-bit measurements, and provide sample complexity bounds for approximate recovery under i.i.d.~Gaussian measurements and a Lipschitz continuous generative prior, as well as a near-matching algorithm-independent lower bound. Moreover, we demonstrate that the Binary $\epsilon$-Stable Embedding property, which characterizes the robustness of the reconstruction to measurement errors and noise, also holds for 1-bit compressive sensing with Lipschitz continuous generative models with sufficiently many Gaussian measurements. In addition, we apply our results to neural network generative models, and provide a proof-of-concept numerical experiment demonstrating significant improvements over sparsity-based approaches.
Tight Regret Bounds for Noisy Optimization of a Brownian Motion
Jan 25, 2020
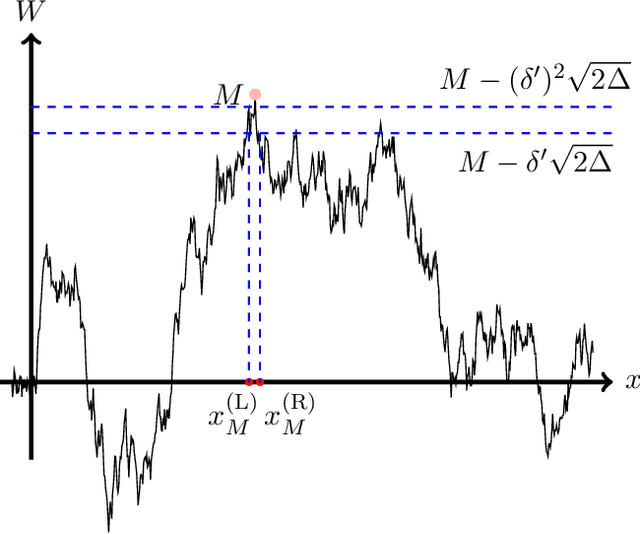
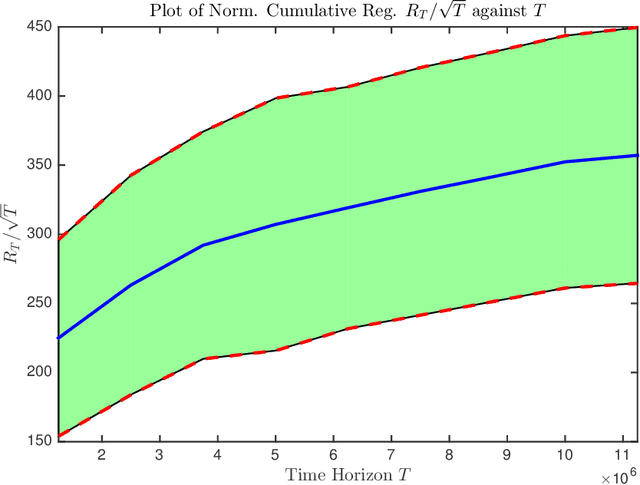
We consider the problem of Bayesian optimization of a one-dimensional Brownian motion in which the $T$ adaptively chosen observations are corrupted by Gaussian noise. We show that as the smallest possible expected simple regret and the smallest possible expected cumulative regret scale as $\Omega(1 / \sqrt{T \log (T)}) \cap \mathcal{O}(\log T / \sqrt{T})$ and $\Omega(\sqrt{T / \log (T)}) \cap \mathcal{O}(\sqrt{T} \cdot \log T)$ respectively. Thus, our upper and lower bounds are tight up to a factor of $\mathcal{O}( (\log T)^{1.5} )$. The upper bound uses an algorithm based on confidence bounds and the Markov property of Brownian motion, and the lower bound is based on a reduction to binary hypothesis testing.