 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based and Graph-Based Priors for Group Testing
May 24, 2022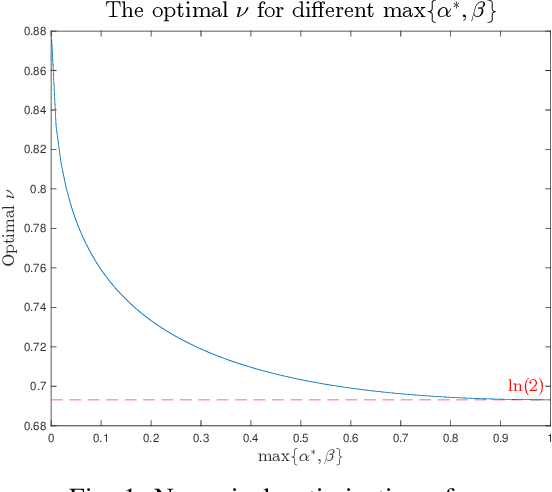
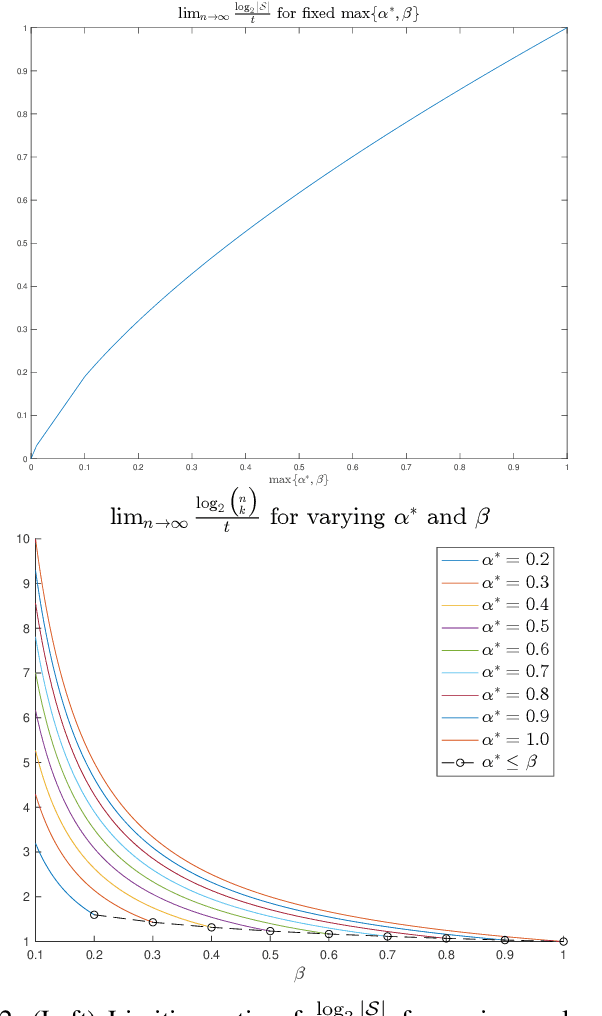
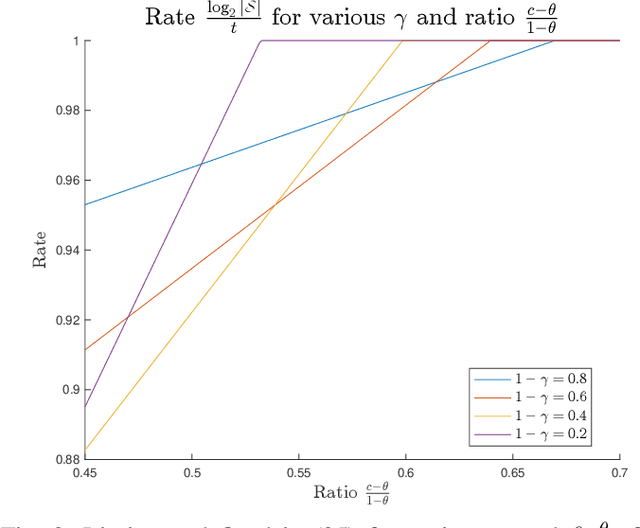
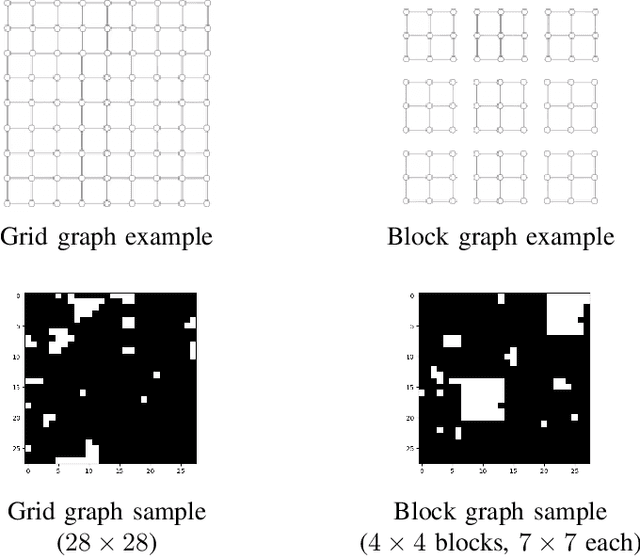
The goal of the group testing problem is to identify a set of defective items within a larger set of items, using suitably-designed tests whose outcomes indicate whether any defective item is present. In this paper, we study how the number of tests can be significantly decreased by leveraging the structural dependencies between the items, i.e., by incorporating prior information. To do so, we pursue two different perspectives: (i) As a generalization of the uniform combinatorial prior, we consider the case that the defective set is uniform over a \emph{subset} of all possible sets of a given size, and study how this impacts the information-theoretic limits on the number of tests for approximate recovery; (ii) As a generalization of the i.i.d.~prior, we introduce a new class of priors based on the Ising model, where the associated graph represents interactions between items. We show that this naturally leads to an Integer Quadratic Program decoder, which can be converted to an Integer Linear Program and/or relaxed to a non-integer variant for improved computational complexity, while maintaining strong empirical recovery performance.
Generative Principal Component Analysis
Mar 18, 2022
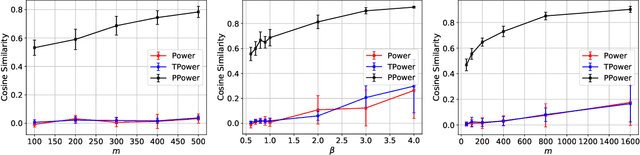


In this paper, we study the problem of principal component analysis with generative modeling assumptions, adopting a general model for the observed matrix that encompasses notable special cases, including spiked matrix recovery and phase retrieval. The key assumption is that the underlying signal lies near the range of an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs. We propose a quadratic estimator, and show that it enjoys a statistical rate of order $\sqrt{\frac{k\log L}{m}}$, where $m$ is the number of samples. We also provide a near-matching algorithm-independent lower bound. Moreover, we provide a variant of the classic power method, which projects the calculated data onto the range of the generative model during each iteration. We show that under suitable conditions, this method converges exponentially fast to a point achieving the above-mentioned statistical rate. We perform experiments on various image datasets for spiked matrix and phase retrieval models, and illustrate performance gains of our method to the classic power method and the truncated power method devised for sparse principal component analysis.
Order-Optimal Error Bounds for Noisy Kernel-Based Bayesian Quadrature
Feb 22, 2022
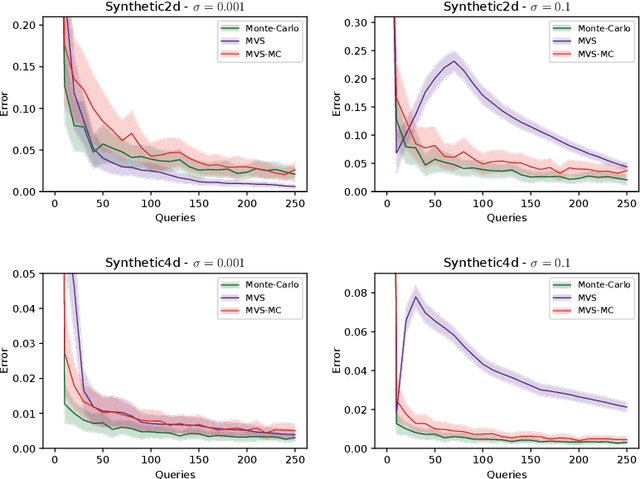
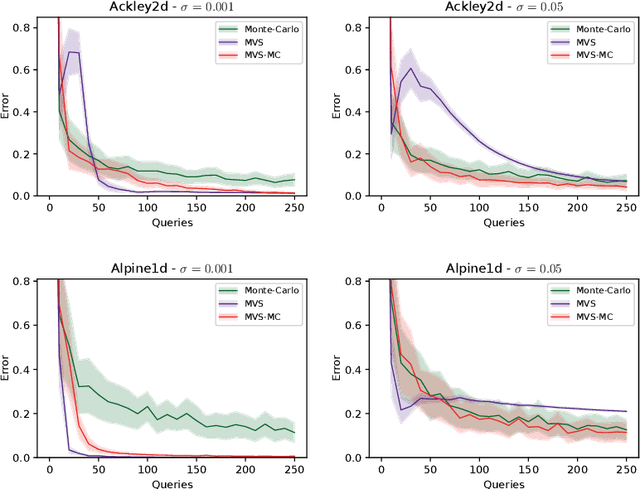
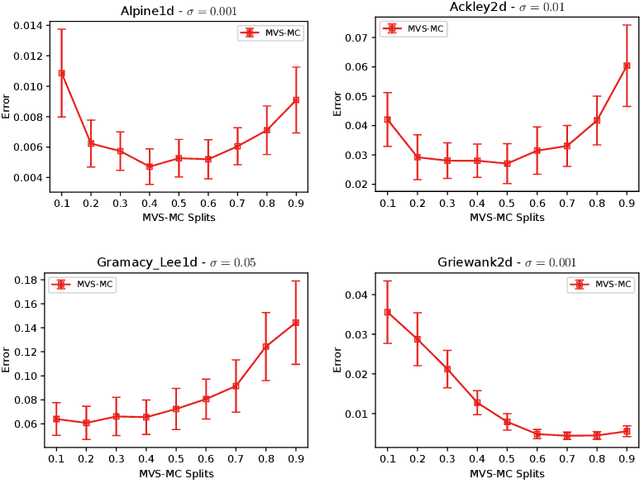
In this paper, we study the sample complexity of {\em noisy Bayesian quadrature} (BQ), in which we seek to approximate an integral based on noisy black-box queries to the underlying function. We consider functions in a {\em Reproducing Kernel Hilbert Space} (RKHS) with the Mat\'ern-$\nu$ kernel, focusing on combinations of the parameter $\nu$ and dimension $d$ such that the RKHS is equivalent to a Sobolev class. In this setting, we provide near-matching upper and lower bounds on the best possible average error. Specifically, we find that when the black-box queries are subject to Gaussian noise having variance $\sigma^2$, any algorithm making at most $T$ queries (even with adaptive sampling) must incur a mean absolute error of $\Omega(T^{-\frac{\nu}{d}-1} + \sigma T^{-\frac{1}{2}})$, and there exists a non-adaptive algorithm attaining an error of at most $O(T^{-\frac{\nu}{d}-1} + \sigma T^{-\frac{1}{2}})$. Hence, the bounds are order-optimal, and establish that there is no adaptivity gap in terms of scaling laws.
Improved Convergence Rates for Sparse Approximation Methods in Kernel-Based Learning
Feb 08, 2022Kernel-based models such as kernel ridge regression and Gaussian processes are ubiquitous in machine learning applications for regression and optimization. It is well known that a serious downside for kernel-based models is the high computational cost; given a dataset of $n$ samples, the cost grows as $\mathcal{O}(n^3)$. Existing sparse approximation methods can yield a significant reduction in the computational cost, effectively reducing the real world cost down to as low as $\mathcal{O}(n)$ in certain cases. Despite this remarkable empirical success, significant gaps remain in the existing results for the analytical confidence bounds on the error due to approximation. In this work, we provide novel confidence intervals for the Nystr\"om method and the sparse variational Gaussian processes approximation method. Our confidence intervals lead to improved error bounds in both regression and optimization. We establish these confidence intervals using novel interpretations of the approximate (surrogate) posterior variance of the models.
A Robust Phased Elimination Algorithm for Corruption-Tolerant Gaussian Process Bandits
Feb 03, 2022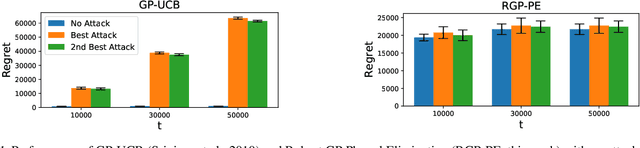

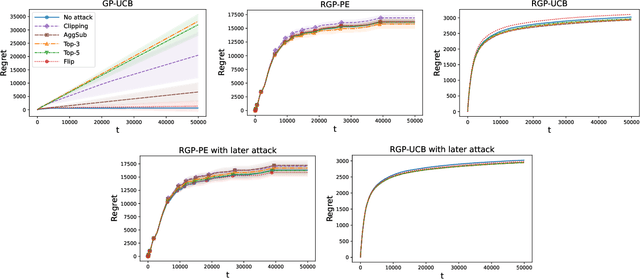
We consider the sequential optimization of an unknown, continuous, and expensive to evaluate reward function, from noisy and adversarially corrupted observed rewards. When the corruption attacks are subject to a suitable budget $C$ and the function lives in a Reproducing Kernel Hilbert Space (RKHS), the problem can be posed as corrupted Gaussian process (GP) bandit optimization. We propose a novel robust elimination-type algorithm that runs in epochs, combines exploration with infrequent switching to select a small subset of actions, and plays each action for multiple time instants. Our algorithm, Robust GP Phased Elimination (RGP-PE), successfully balances robustness to corruptions with exploration and exploitation such that its performance degrades minimally in the presence (or absence) of adversarial corruptions. When $T$ is the number of samples and $\gamma_T$ is the maximal information gain, the corruption-dependent term in our regret bound is $O(C \gamma_T^{3/2})$, which is significantly tighter than the existing $O(C \sqrt{T \gamma_T})$ for several commonly-considered kernels. We perform the first empirical study of robustness in the corrupted GP bandit setting, and show that our algorithm is robust against a variety of adversarial attacks.
Max-Min Grouped Bandits
Nov 17, 2021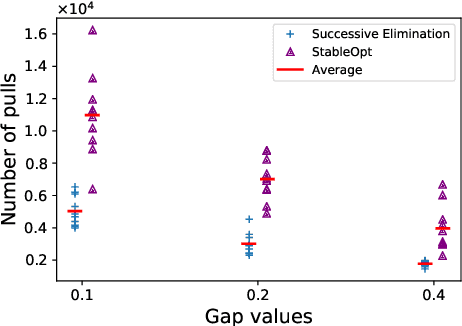
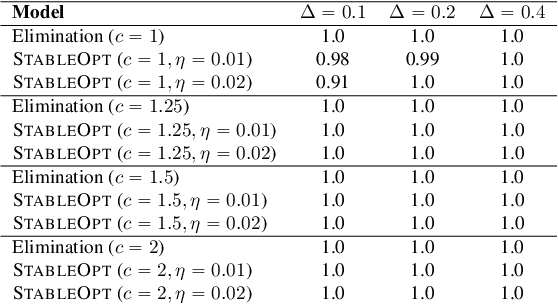
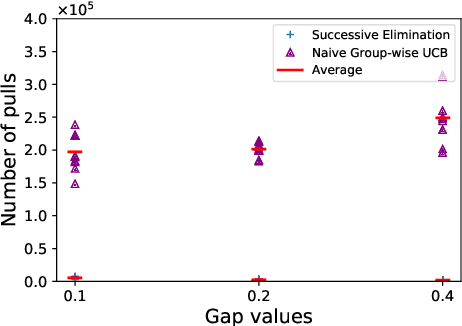
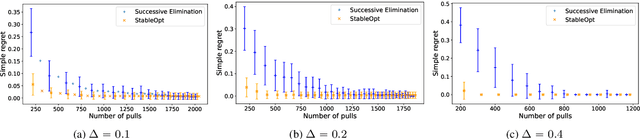
In this paper, we introduce a multi-armed bandit problem termed max-min grouped bandits, in which the arms are arranged in possibly-overlapping groups, and the goal is to find a group whose worst arm has the highest mean reward. This problem is of interest in applications such as recommendation systems, and is also closely related to widely-studied robust optimization problems. We present two algorithms based successive elimination and robust optimization, and derive upper bounds on the number of samples to guarantee finding a max-min optimal or near-optimal group, as well as an algorithm-independent lower bound. We discuss the degree of tightness of our bounds in various cases of interest, and the difficulties in deriving uniformly tight bounds.
Open Problem: Tight Online Confidence Intervals for RKHS Elements
Oct 28, 2021Confidence intervals are a crucial building block in the analysis of various online learning problems. The analysis of kernel based bandit and reinforcement learning problems utilize confidence intervals applicable to the elements of a reproducing kernel Hilbert space (RKHS). However, the existing confidence bounds do not appear to be tight, resulting in suboptimal regret bounds. In fact, the existing regret bounds for several kernelized bandit algorithms (e.g., GP-UCB, GP-TS, and their variants) may fail to even be sublinear. It is unclear whether the suboptimal regret bound is a fundamental shortcoming of these algorithms or an artifact of the proof, and the main challenge seems to stem from the online (sequential) nature of the observation points. We formalize the question of online confidence intervals in the RKHS setting and overview the existing results.
Gaussian Process Bandit Optimization with Few Batches
Oct 26, 2021
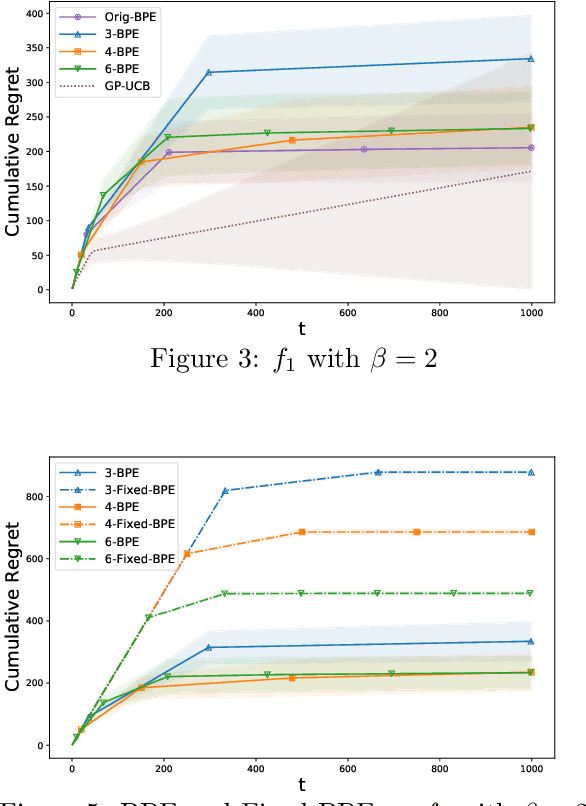
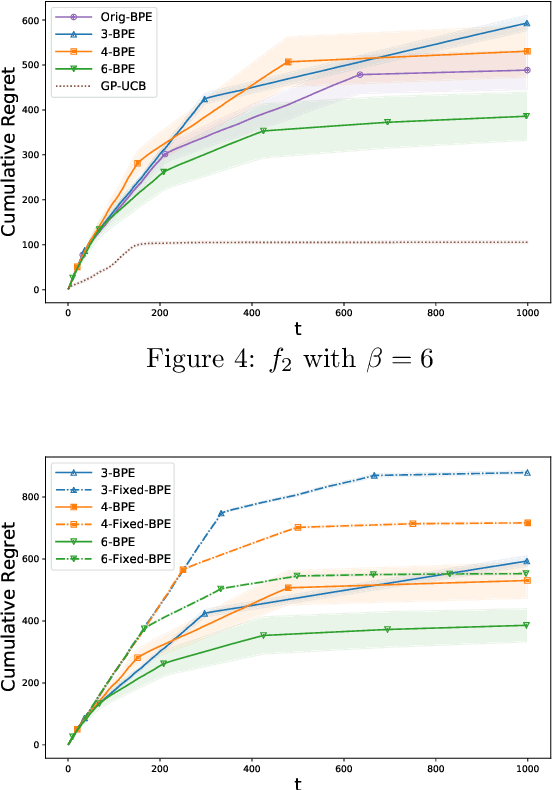
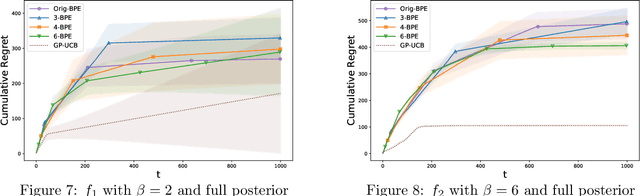
In this paper, we consider the problem of black-box optimization using Gaussian Process (GP) bandit optimization with a small number of batches. Assuming the unknown function has a low norm in the Reproducing Kernel Hilbert Space (RKHS), we introduce a batch algorithm inspired by batched finite-arm bandit algorithms, and show that it achieves the cumulative regret upper bound $O^\ast(\sqrt{T\gamma_T})$ using $O(\log\log T)$ batches within time horizon $T$, where the $O^\ast(\cdot)$ notation hides dimension-independent logarithmic factors and $\gamma_T$ is the maximum information gain associated with the kernel. This bound is near-optimal for several kernels of interest and improves on the typical $O^\ast(\sqrt{T}\gamma_T)$ bound, and our approach is arguably the simplest among algorithms attaining this improvement. In addition, in the case of a constant number of batches (not depending on $T$), we propose a modified version of our algorithm, and characterize how the regret is impacted by the number of batches, focusing on the squared exponential and Mat\'ern kernels. The algorithmic upper bounds are shown to be nearly minimax optimal via analogous algorithm-independent lower bounds.
Adversarial Attacks on Gaussian Process Bandits
Oct 16, 2021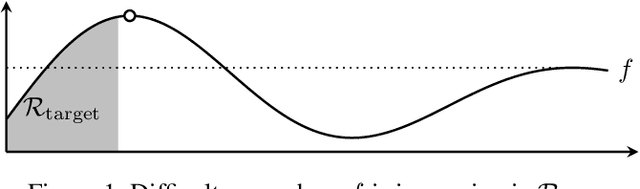
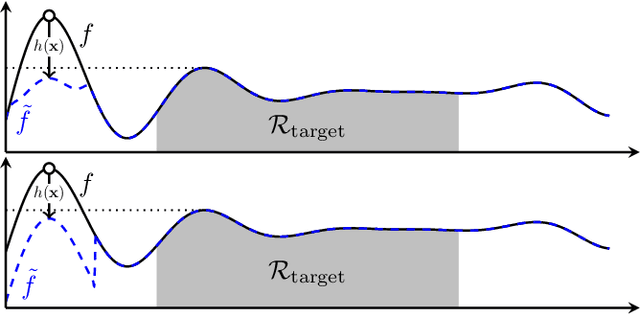
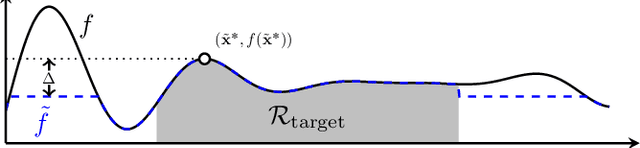
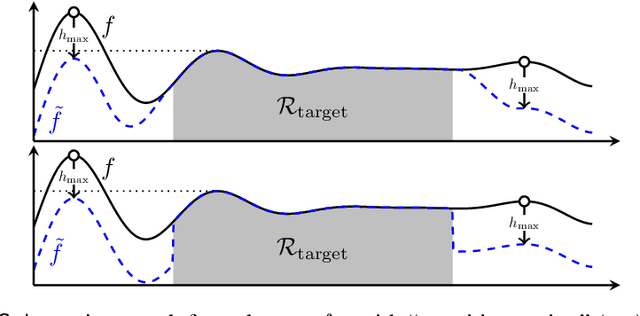
Gaussian processes (GP) are a widely-adopted tool used to sequentially optimize black-box functions, where evaluations are costly and potentially noisy. Recent works on GP bandits have proposed to move beyond random noise and devise algorithms robust to adversarial attacks. In this paper, we study this problem from the attacker's perspective, proposing various adversarial attack methods with differing assumptions on the attacker's strength and prior information. Our goal is to understand adversarial attacks on GP bandits from both a theoretical and practical perspective. We focus primarily on targeted attacks on the popular GP-UCB algorithm and a related elimination-based algorithm, based on adversarially perturbing the function $f$ to produce another function $\tilde{f}$ whose optima are in some region $\mathcal{R}_{\rm target}$. Based on our theoretical analysis, we devise both white-box attacks (known $f$) and black-box attacks (unknown $f$), with the former including a Subtraction attack and Clipping attack, and the latter including an Aggressive subtraction attack. We demonstrate that adversarial attacks on GP bandits can succeed in forcing the algorithm towards $\mathcal{R}_{\rm target}$ even with a low attack budget, and we compare our attacks' performance and efficiency on several real and synthetic functions.
Robust 1-bit Compressive Sensing with Partial Gaussian Circulant Matrices and Generative Priors
Aug 08, 2021

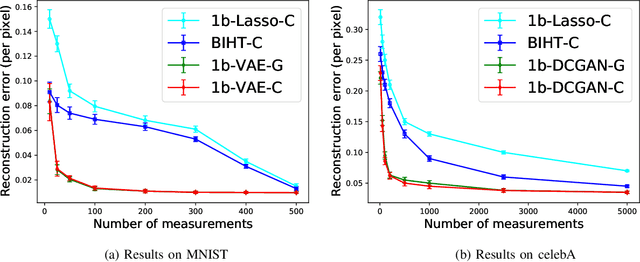

In 1-bit compressive sensing, each measurement is quantized to a single bit, namely the sign of a linear function of an unknown vector, and the goal is to accurately recover the vector. While it is most popular to assume a standard Gaussian sensing matrix for 1-bit compressive sensing, using structured sensing matrices such as partial Gaussian circulant matrices is of significant practical importance due to their faster matrix operations. In this paper, we provide recovery guarantees for a correlation-based optimization algorithm for robust 1-bit compressive sensing with randomly signed partial Gaussian circulant matrices and generative models. Under suitable assumptions, we match guarantees that were previously only known to hold for i.i.d.~Gaussian matrices that require significantly more computation. We make use of a practical iterative algorithm, and perform numerical experiments on image datasets to corroborate our theoretical results.