 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRUE: Re-evaluating Factual Consistency Evaluation
Apr 11, 2022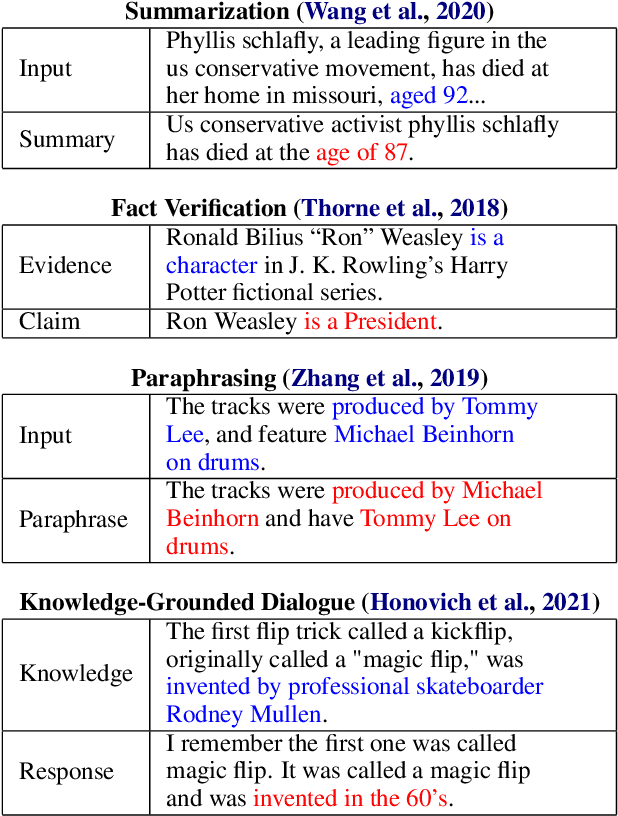
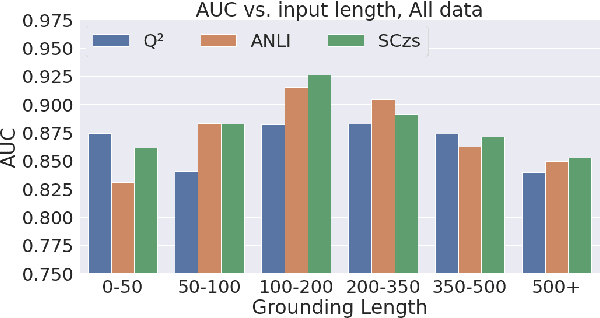
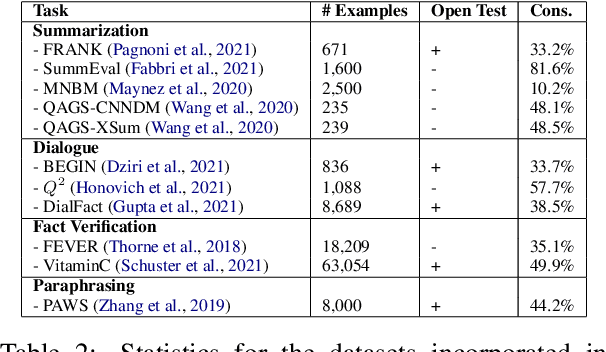

Grounded text generation systems often generate text that contains factual inconsistencies, hindering their real-world applicability. Automatic factual consistency evaluation may help alleviate this limitation by accelerating evaluation cycles, filtering inconsistent outputs and augmenting training data. While attracting increasing attention, such evaluation metrics are usually developed and evaluated in silo for a single task or dataset, slowing their adoption. Moreover, previous meta-evaluation protocols focused on system-level correlations with human annotations, which leave the example-level accuracy of such metrics unclear. In this work, we introduce TRUE: a comprehensive study of factual consistency metrics on a standardized collection of existing texts from diverse tasks, manually annotated for factual consistency. Our standardization enables an example-level meta-evaluation protocol that is more actionable and interpretable than previously reported correlations, yielding clearer quality measures. Across diverse state-of-the-art metrics and 11 datasets we find that large-scale NLI and question generation-and-answering-based approaches achieve strong and complementary results. We recommend those methods as a starting point for model and metric developers, and hope TRUE will foster progress towards even better methods.
Learning To Retrieve Prompts for In-Context Learning
Dec 16, 2021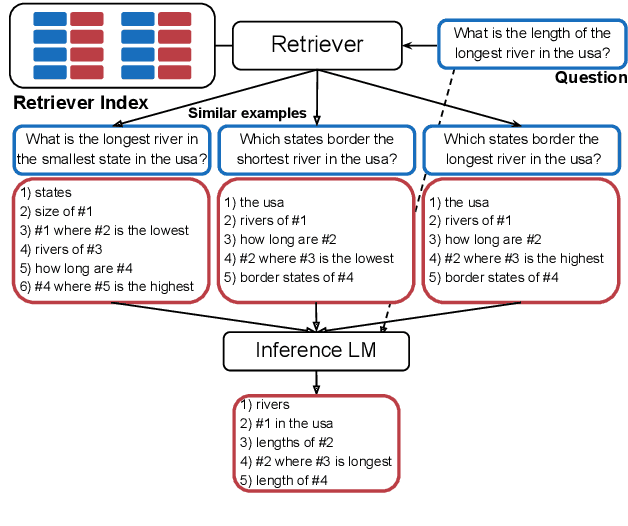

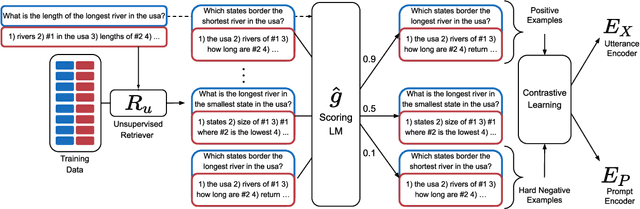
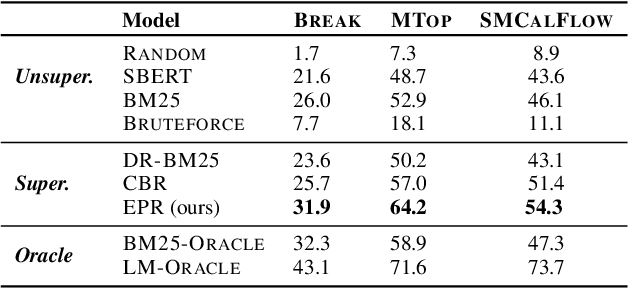
In-context learning is a recent paradigm in natural language understanding, where a large pre-trained language model (LM) observes a test instance and a few training examples as its input, and directly decodes the output without any update to its parameters. However, performance has been shown to strongly depend on the selected training examples (termed prompt). In this work, we propose an efficient method for retrieving prompts for in-context learning using annotated data and a LM. Given an input-output pair, we estimate the probability of the output given the input and a candidate training example as the prompt, and label training examples as positive or negative based on this probability. We then train an efficient dense retriever from this data, which is used to retrieve training examples as prompts at test time. We evaluate our approach on three sequence-to-sequence tasks where language utterances are mapped to meaning representations, and find that it substantially outperforms prior work and multiple baselines across the board.
Finding needles in a haystack: Sampling Structurally-diverse Training Sets from Synthetic Data for Compositional Generalization
Sep 06, 2021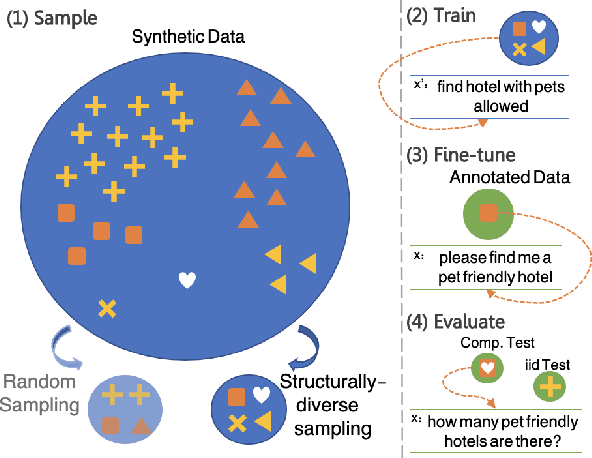



Modern semantic parsers suffer from two principal limitations. First, training requires expensive collection of utterance-program pairs. Second, semantic parsers fail to generalize at test time to new compositions/structures that have not been observed during training. Recent research has shown that automatic generation of synthetic utterance-program pairs can alleviate the first problem, but its potential for the second has thus far been under-explored. In this work, we investigate automatic generation of synthetic utterance-program pairs for improving compositional generalization in semantic parsing. Given a small training set of annotated examples and an "infinite" pool of synthetic examples, we select a subset of synthetic examples that are structurally-diverse and use them to improve compositional generalization. We evaluate our approach on a new split of the schema2QA dataset, and show that it leads to dramatic improvements in compositional generalization as well as moderate improvements in the traditional i.i.d setup. Moreover, structurally-diverse sampling achieves these improvements with as few as 5K examples, compared to 1M examples when sampling uniformly at random -- a 200x improvement in data efficiency.
Unlocking Compositional Generalization in Pre-trained Models Using Intermediate Representations
Apr 15, 2021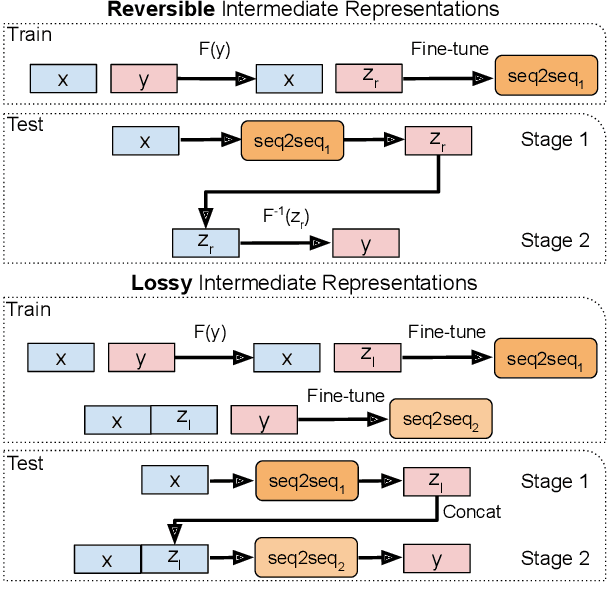
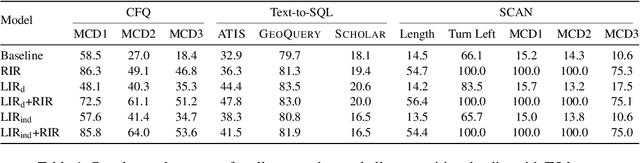
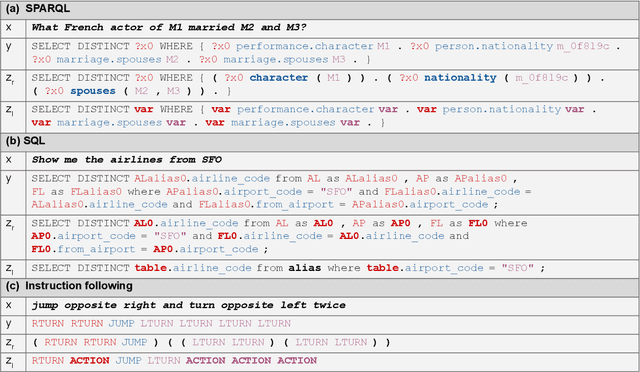
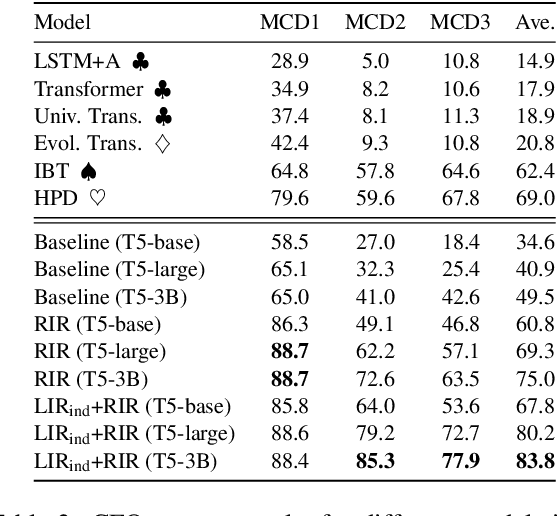
Sequence-to-sequence (seq2seq) models are prevalent in semantic parsing, but have been found to struggle at out-of-distribution compositional generalization. While specialized model architectures and pre-training of seq2seq models have been proposed to address this issue, the former often comes at the cost of generality and the latter only shows limited success. In this paper, we study the impact of intermediate representations on compositional generalization in pre-trained seq2seq models, without changing the model architecture at all, and identify key aspects for designing effective representations. Instead of training to directly map natural language to an executable form, we map to a reversible or lossy intermediate representation that has stronger structural correspondence with natural language. The combination of our proposed intermediate representations and pre-trained models is surprisingly effective, where the best combinations obtain a new state-of-the-art on CFQ (+14.8 accuracy points) and on the template-splits of three text-to-SQL datasets (+15.0 to +19.4 accuracy points). This work highlights that intermediate representations provide an important and potentially overlooked degree of freedom for improving the compositional generalization abilities of pre-trained seq2seq models.
Open Domain Question Answering over Tables via Dense Retrieval
Mar 22, 2021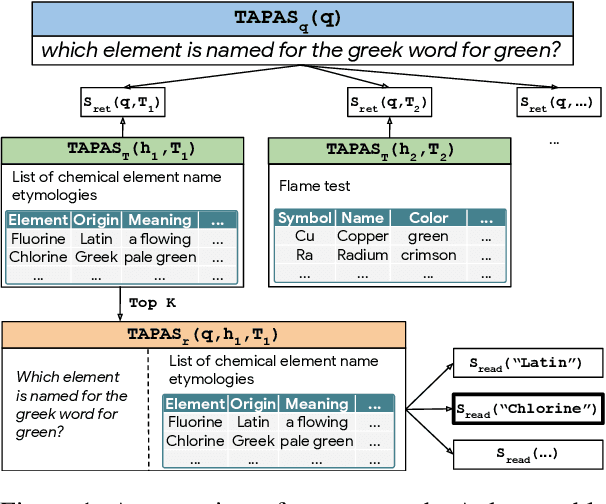
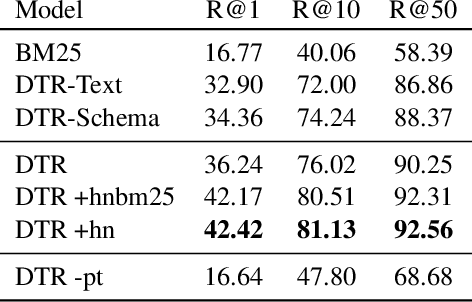
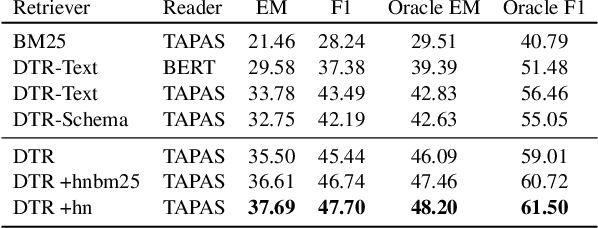

Recent advances in open-domain QA have led to strong models based on dense retrieval, but only focused on retrieving textual passages. In this work, we tackle open-domain QA over tables for the first time, and show that retrieval can be improved by a retriever designed to handle tabular context. We present an effective pre-training procedure for our retriever and improve retrieval quality with mined hard negatives. As relevant datasets are missing, we extract a subset of Natural Questions (Kwiatkowski et al., 2019) into a Table QA dataset. We find that our retriever improves retrieval results from 72.0 to 81.1 recall@10 and end-to-end QA results from 33.8 to 37.7 exact match, over a BERT based retriever.
Improving Compositional Generalization in Semantic Parsing
Oct 12, 2020
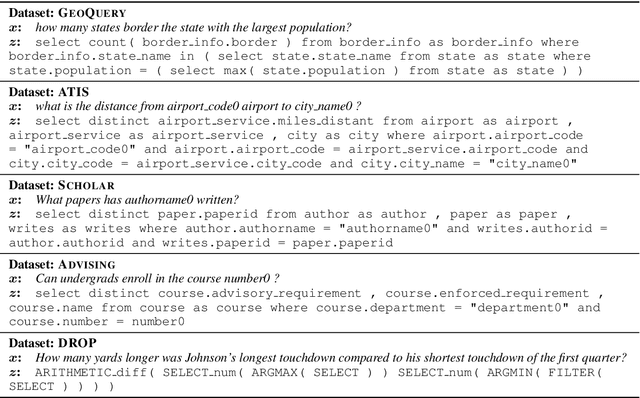

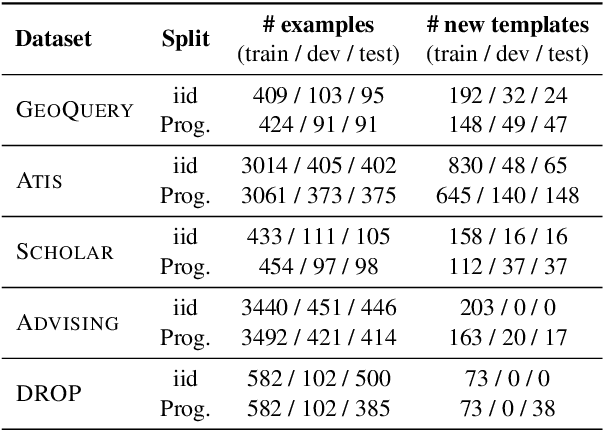
Generalization of models to out-of-distribution (OOD) data has captured tremendous attention recently. Specifically, compositional generalization, i.e., whether a model generalizes to new structures built of components observed during training, has sparked substantial interest. In this work, we investigate compositional generalization in semantic parsing, a natural test-bed for compositional generalization, as output programs are constructed from sub-components. We analyze a wide variety of models and propose multiple extensions to the attention module of the semantic parser, aiming to improve compositional generalization. We find that the following factors improve compositional generalization: (a) using contextual representations, such as ELMo and BERT, (b) informing the decoder what input tokens have previously been attended to, (c) training the decoder attention to agree with pre-computed token alignments, and (d) downsampling examples corresponding to frequent program templates. While we substantially reduce the gap between in-distribution and OOD generalization, performance on OOD compositions is still substantially lower.
Span-based Semantic Parsing for Compositional Generalization
Sep 13, 2020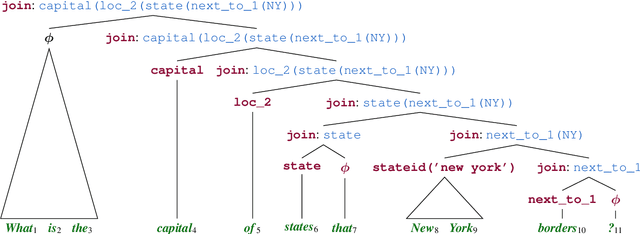
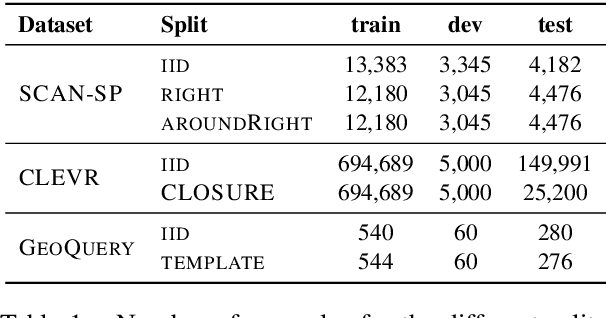

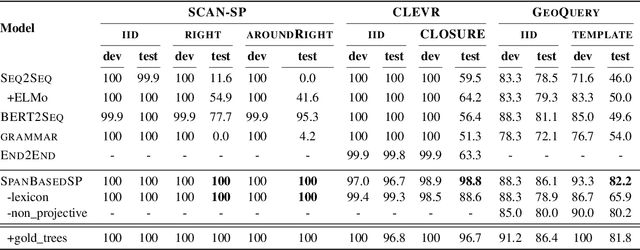
Despite the success of sequence-to-sequence (seq2seq) models in semantic parsing, recent work has shown that they fail in compositional generalization, i.e., the ability to generalize to new structures built of components observed during training. In this work, we posit that a span-based parser should lead to better compositional generalization. we propose SpanBasedSP, a parser that predicts a span tree over an input utterance, explicitly encoding how partial programs compose over spans in the input. SpanBasedSP extends Pasupat et al. (2019) to be comparable to seq2seq models by (i) training from programs, without access to gold trees, treating trees as latent variables, (ii) parsing a class of non-projective trees through an extension to standard CKY. On GeoQuery, SCAN and CLOSURE datasets, SpanBasedSP performs similarly to strong seq2seq baselines on random splits, but dramatically improves performance compared to baselines on splits that require compositional generalization: from $69.8 \rightarrow 95.3$ average accuracy.
TAPAS: Weakly Supervised Table Parsing via Pre-training
Apr 21, 2020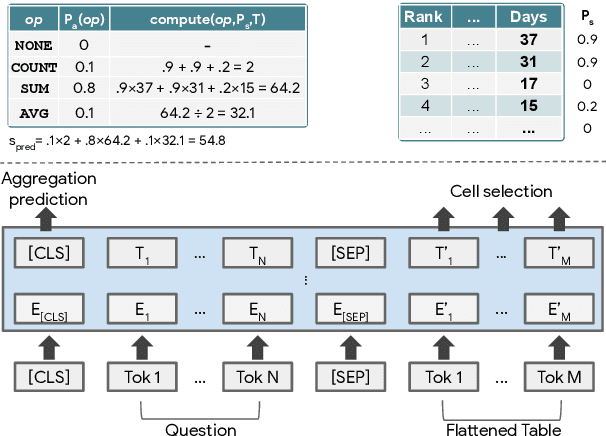
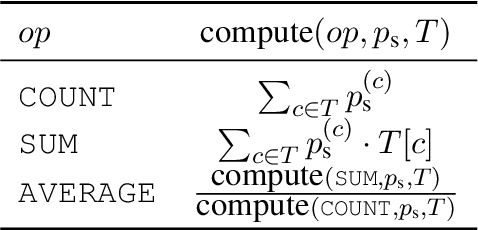
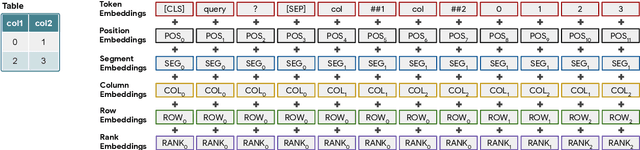
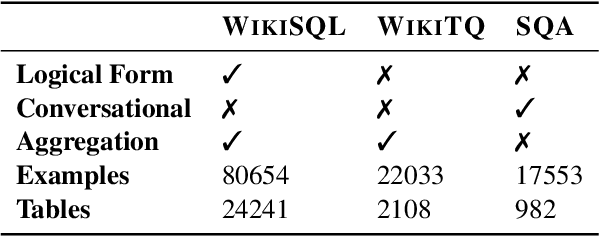
Answering natural language questions over tables is usually seen as a semantic parsing task. To alleviate the collection cost of full logical forms, one popular approach focuses on weak supervision consisting of denotations instead of logical forms. However, training semantic parsers from weak supervision poses difficulties, and in addition, the generated logical forms are only used as an intermediate step prior to retrieving the denotation. In this paper, we present TAPAS, an approach to question answering over tables without generating logical forms. TAPAS trains from weak supervision, and predicts the denotation by selecting table cells and optionally applying a corresponding aggregation operator to such selection. TAPAS extends BERT's architecture to encode tables as input, initializes from an effective joint pre-training of text segments and tables crawled from Wikipedia, and is trained end-to-end. We experiment with three different semantic parsing datasets, and find that TAPAS outperforms or rivals semantic parsing models by improving state-of-the-art accuracy on SQA from 55.1 to 67.2 and performing on par with the state-of-the-art on WIKISQL and WIKITQ, but with a simpler model architecture. We additionally find that transfer learning, which is trivial in our setting, from WIKISQL to WIKITQ, yields 48.7 accuracy, 4.2 points above the state-of-the-art.
A Summarization System for Scientific Documents
Aug 29, 2019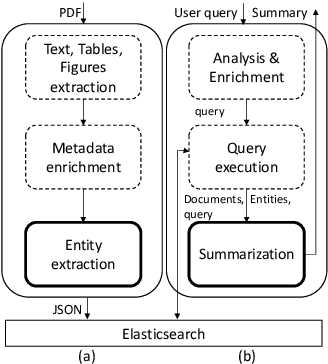
We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
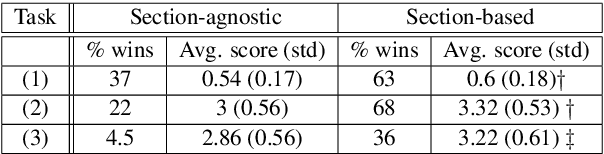
Don't paraphrase, detect! Rapid and Effective Data Collection for Semantic Parsing
Aug 29, 2019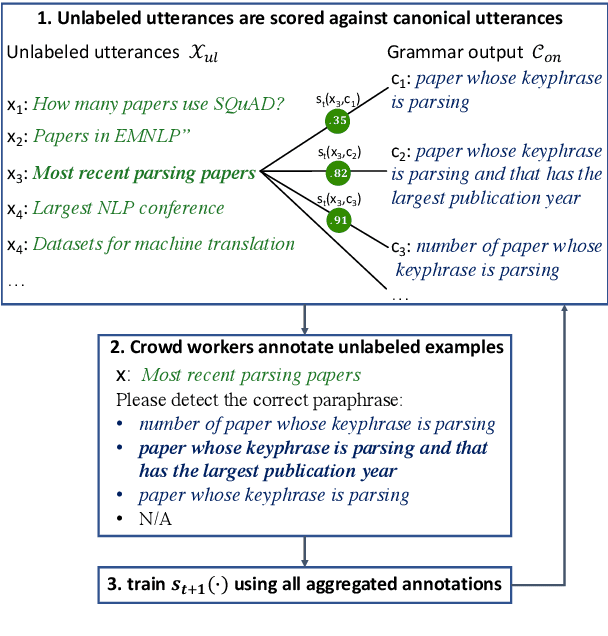
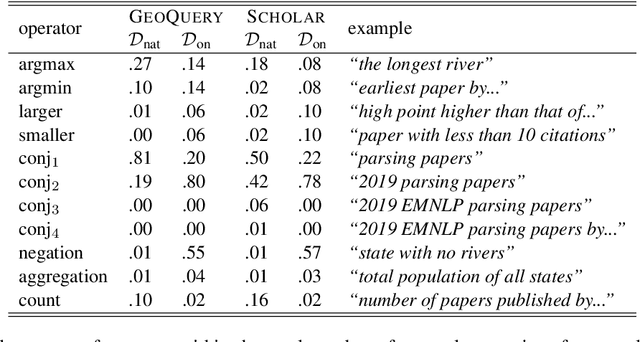
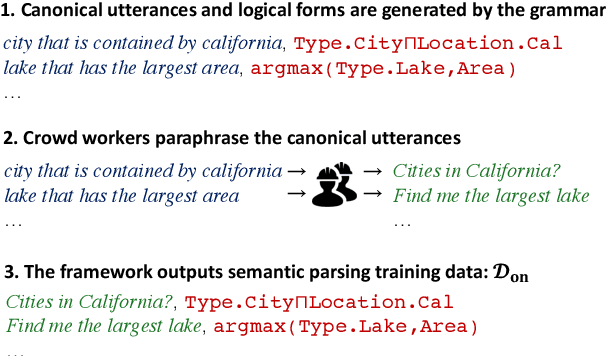
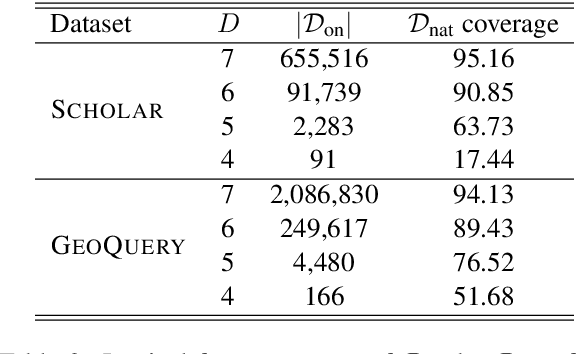
A major hurdle on the road to conversational interfaces is the difficulty in collecting data that maps language utterances to logical forms. One prominent approach for data collection has been to automatically generate pseudo-language paired with logical forms, and paraphrase the pseudo-language to natural language through crowdsourcing (Wang et al., 2015). However, this data collection procedure often leads to low performance on real data, due to a mismatch between the true distribution of examples and the distribution induced by the data collection procedure. In this paper, we thoroughly analyze two sources of mismatch in this process: the mismatch in logical form distribution and the mismatch in language distribution between the true and induced distributions. We quantify the effects of these mismatches, and propose a new data collection approach that mitigates them. Assuming access to unlabeled utterances from the true distribution, we combine crowdsourcing with a paraphrase model to detect correct logical forms for the unlabeled utterances. On two datasets, our method leads to 70.6 accuracy on average on the true distribution, compared to 51.3 in paraphrasing-based data collection.