 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData drift correction via time-varying importance weight estimator
Oct 04, 2022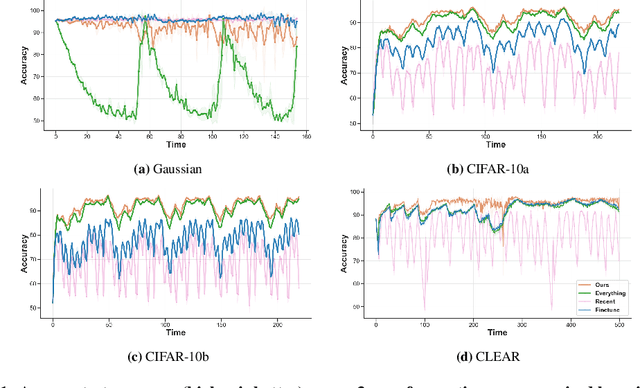

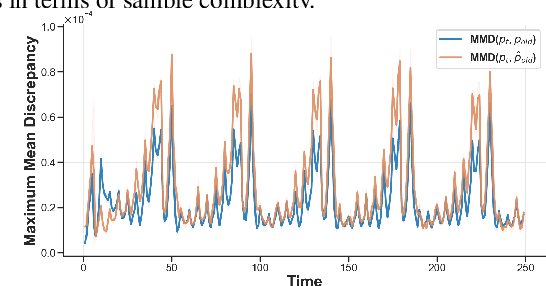
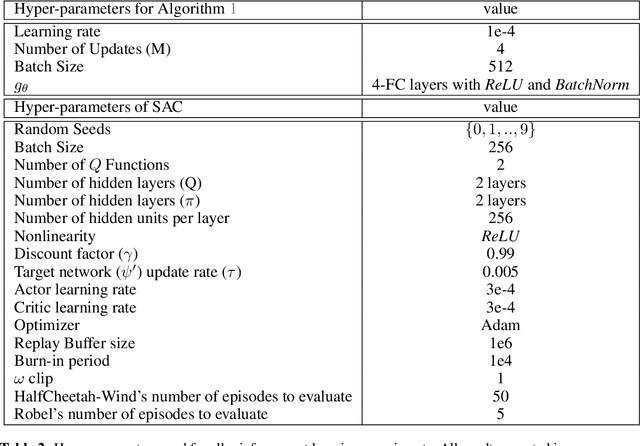
Real-world deployment of machine learning models is challenging when data evolves over time. And data does evolve over time. While no model can work when data evolves in an arbitrary fashion, if there is some pattern to these changes, we might be able to design methods to address it. This paper addresses situations when data evolves gradually. We introduce a novel time-varying importance weight estimator that can detect gradual shifts in the distribution of data. Such an importance weight estimator allows the training method to selectively sample past data -- not just similar data from the past like a standard importance weight estimator would but also data that evolved in a similar fashion in the past. Our time-varying importance weight is quite general. We demonstrate different ways of implementing it that exploit some known structure in the evolution of data. We demonstrate and evaluate this approach on a variety of problems ranging from supervised learning tasks (multiple image classification datasets) where the data undergoes a sequence of gradual shifts of our design to reinforcement learning tasks (robotic manipulation and continuous control) where data undergoes a shift organically as the policy or the task changes.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022
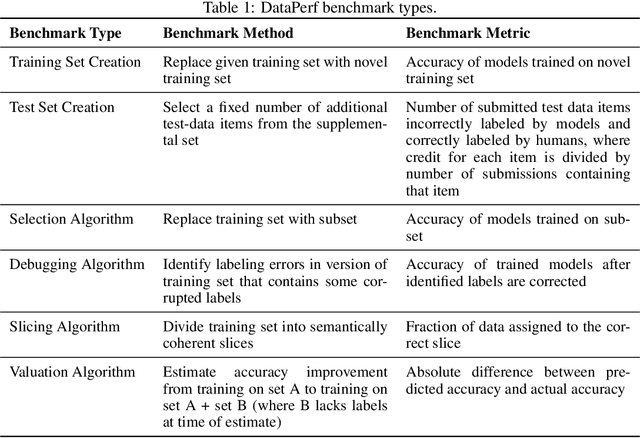
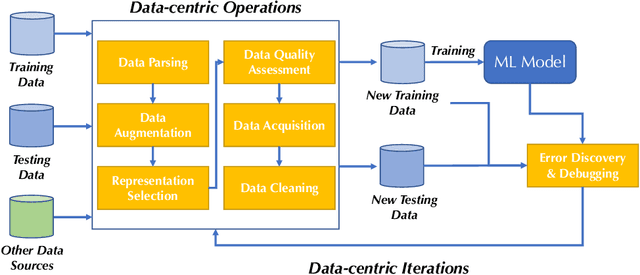
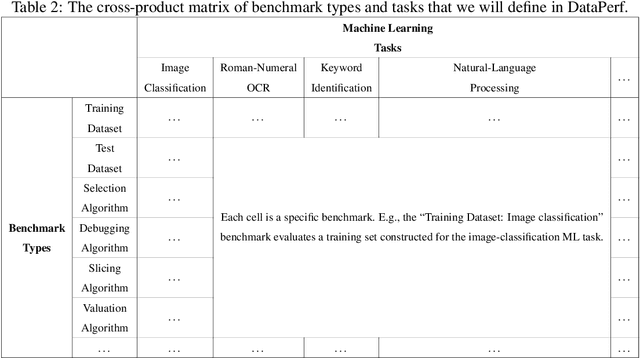
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Back to the Basics: Revisiting Out-of-Distribution Detection Baselines
Jul 07, 2022


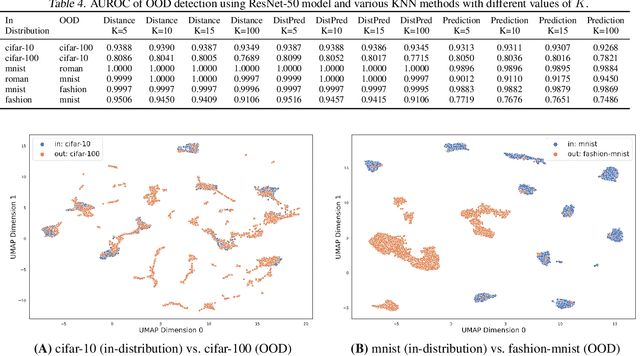
We study simple methods for out-of-distribution (OOD) image detection that are compatible with any already trained classifier, relying on only its predictions or learned representations. Evaluating the OOD detection performance of various methods when utilized with ResNet-50 and Swin Transformer models, we find methods that solely consider the model's predictions can be easily outperformed by also considering the learned representations. Based on our analysis, we advocate for a dead-simple approach that has been neglected in other studies: simply flag as OOD images whose average distance to their K nearest neighbors is large (in the representation space of an image classifier trained on the in-distribution data).
A Robust Stacking Framework for Training Deep Graph Models with Multifaceted Node Features
Jun 16, 2022
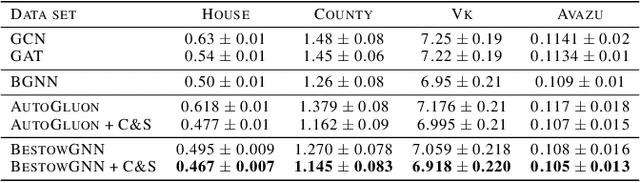
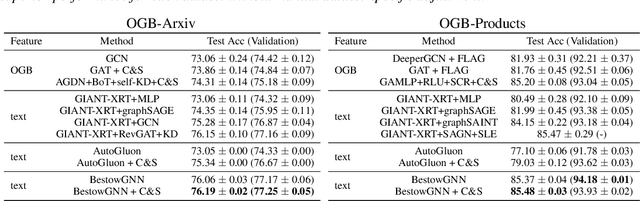

Graph Neural Networks (GNNs) with numerical node features and graph structure as inputs have demonstrated superior performance on various supervised learning tasks with graph data. However the numerical node features utilized by GNNs are commonly extracted from raw data which is of text or tabular (numeric/categorical) type in most real-world applications. The best models for such data types in most standard supervised learning settings with IID (non-graph) data are not simple neural network layers and thus are not easily incorporated into a GNN. Here we propose a robust stacking framework that fuses graph-aware propagation with arbitrary models intended for IID data, which are ensembled and stacked in multiple layers. Our layer-wise framework leverages bagging and stacking strategies to enjoy strong generalization, in a manner which effectively mitigates label leakage and overfitting. Across a variety of graph datasets with tabular/text node features, our method achieves comparable or superior performance relative to both tabular/text and graph neural network models, as well as existing state-of-the-art hybrid strategies that combine the two.
Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline
May 28, 2022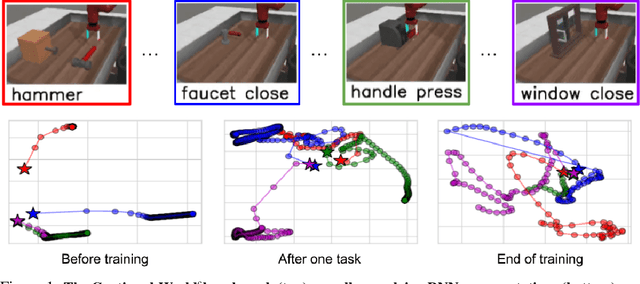

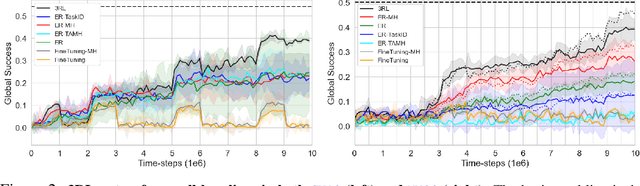

We study task-agnostic continual reinforcement learning (TACRL) in which standard RL challenges are compounded with partial observability stemming from task agnosticism, as well as additional difficulties of continual learning (CL), i.e., learning on a non-stationary sequence of tasks. Here we compare TACRL methods with their soft upper bounds prescribed by previous literature: multi-task learning (MTL) methods which do not have to deal with non-stationary data distributions, as well as task-aware methods, which are allowed to operate under full observability. We consider a previously unexplored and straightforward baseline for TACRL, replay-based recurrent RL (3RL), in which we augment an RL algorithm with recurrent mechanisms to address partial observability and experience replay mechanisms to address catastrophic forgetting in CL. Studying empirical performance in a sequence of RL tasks, we find surprising occurrences of 3RL matching and overcoming the MTL and task-aware soft upper bounds. We lay out hypotheses that could explain this inflection point of continual and task-agnostic learning research. Our hypotheses are empirically tested in continuous control tasks via a large-scale study of the popular multi-task and continual learning benchmark Meta-World. By analyzing different training statistics including gradient conflict, we find evidence that 3RL's outperformance stems from its ability to quickly infer how new tasks relate with the previous ones, enabling forward transfer.
Benchmarking Multimodal AutoML for Tabular Data with Text Fields
Nov 04, 2021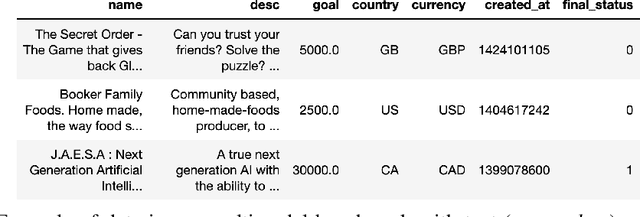
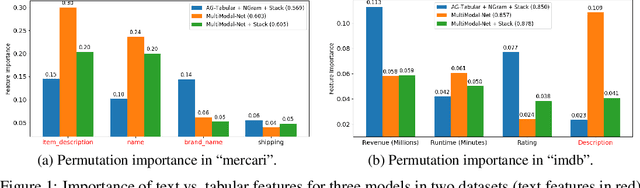
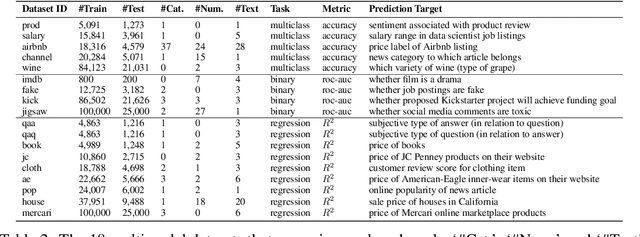
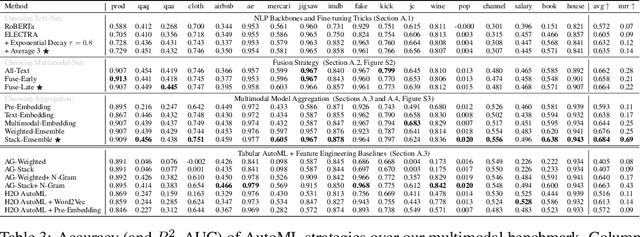
We consider the use of automated supervised learning systems for data tables that not only contain numeric/categorical columns, but one or more text fields as well. Here we assemble 18 multimodal data tables that each contain some text fields and stem from a real business application. Our publicly-available benchmark enables researchers to comprehensively evaluate their own methods for supervised learning with numeric, categorical, and text features. To ensure that any single modeling strategy which performs well over all 18 datasets will serve as a practical foundation for multimodal text/tabular AutoML, the diverse datasets in our benchmark vary greatly in: sample size, problem types (a mix of classification and regression tasks), number of features (with the number of text columns ranging from 1 to 28 between datasets), as well as how the predictive signal is decomposed between text vs. numeric/categorical features (and predictive interactions thereof). Over this benchmark, we evaluate various straightforward pipelines to model such data, including standard two-stage approaches where NLP is used to featurize the text such that AutoML for tabular data can then be applied. Compared with human data science teams, the fully automated methodology that performed best on our benchmark (stack ensembling a multimodal Transformer with various tree models) also manages to rank 1st place when fit to the raw text/tabular data in two MachineHack prediction competitions and 2nd place (out of 2380 teams) in Kaggle's Mercari Price Suggestion Challenge.
Convergent Boosted Smoothing for Modeling Graph Data with Tabular Node Features
Oct 26, 2021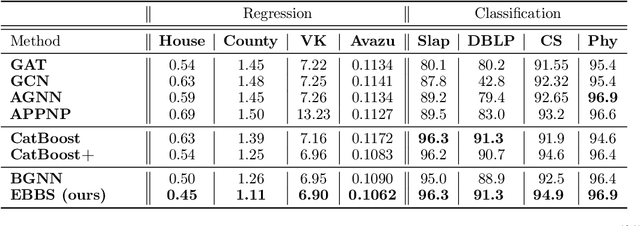
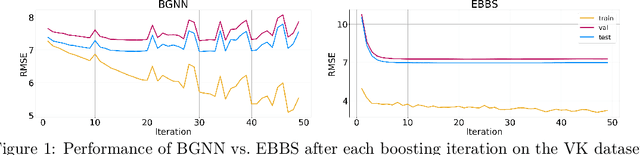

For supervised learning with tabular data, decision tree ensembles produced via boosting techniques generally dominate real-world applications involving iid training/test sets. However for graph data where the iid assumption is violated due to structured relations between samples, it remains unclear how to best incorporate this structure within existing boosting pipelines. To this end, we propose a generalized framework for iterating boosting with graph propagation steps that share node/sample information across edges connecting related samples. Unlike previous efforts to integrate graph-based models with boosting, our approach is anchored in a principled meta loss function such that provable convergence can be guaranteed under relatively mild assumptions. Across a variety of non-iid graph datasets with tabular node features, our method achieves comparable or superior performance than both tabular and graph neural network models, as well as existing hybrid strategies that combine the two. Beyond producing better predictive performance than recently proposed graph models, our proposed techniques are easy to implement, computationally more efficient, and enjoy stronger theoretical guarantees (which make our results more reproducible).
Distiller: A Systematic Study of Model Distillation Methods in Natural Language Processing
Sep 23, 2021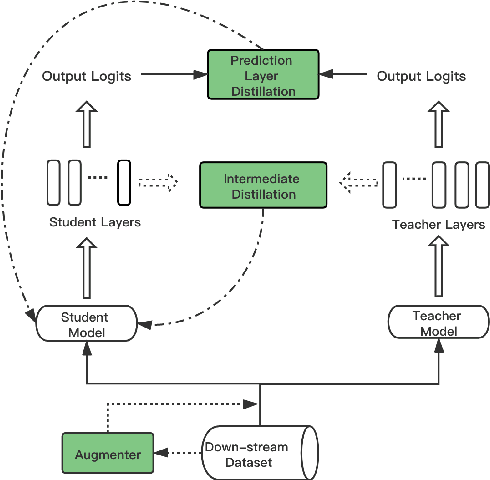
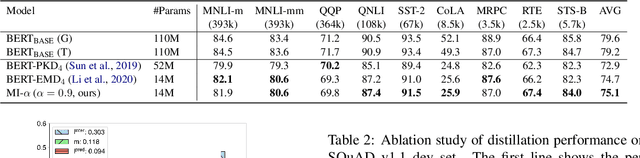
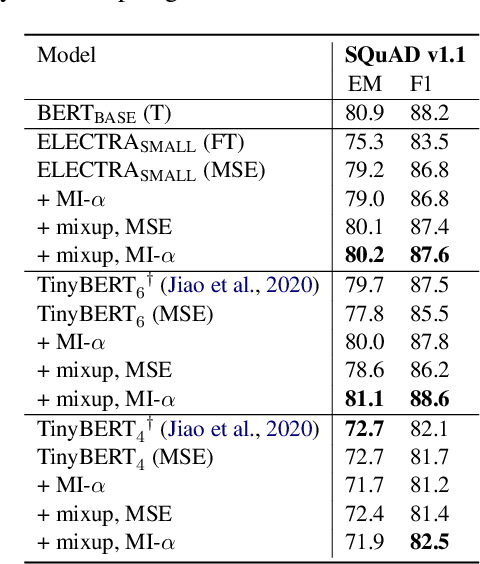
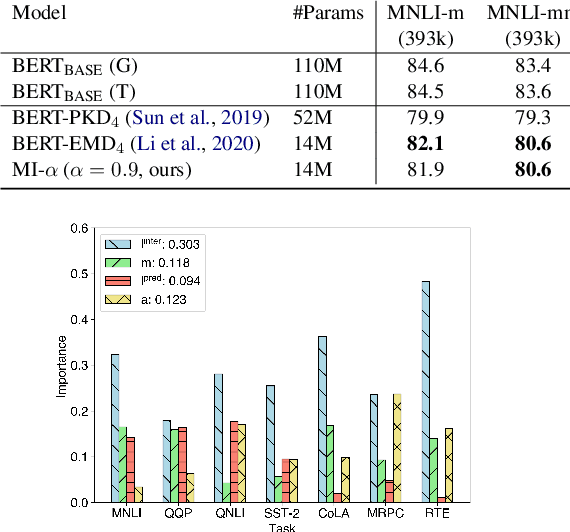
We aim to identify how different components in the KD pipeline affect the resulting performance and how much the optimal KD pipeline varies across different datasets/tasks, such as the data augmentation policy, the loss function, and the intermediate representation for transferring the knowledge between teacher and student. To tease apart their effects, we propose Distiller, a meta KD framework that systematically combines a broad range of techniques across different stages of the KD pipeline, which enables us to quantify each component's contribution. Within Distiller, we unify commonly used objectives for distillation of intermediate representations under a universal mutual information (MI) objective and propose a class of MI-$\alpha$ objective functions with better bias/variance trade-off for estimating the MI between the teacher and the student. On a diverse set of NLP datasets, the best Distiller configurations are identified via large-scale hyperparameter optimization. Our experiments reveal the following: 1) the approach used to distill the intermediate representations is the most important factor in KD performance, 2) among different objectives for intermediate distillation, MI-$\alpha$ performs the best, and 3) data augmentation provides a large boost for small training datasets or small student networks. Moreover, we find that different datasets/tasks prefer different KD algorithms, and thus propose a simple AutoDistiller algorithm that can recommend a good KD pipeline for a new dataset.
Deep Learning for Functional Data Analysis with Adaptive Basis Layers
Jun 19, 2021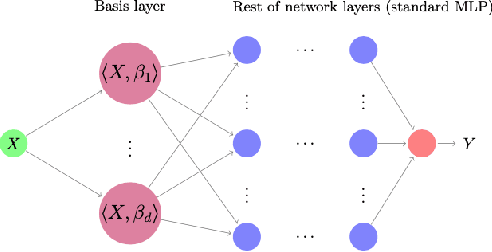
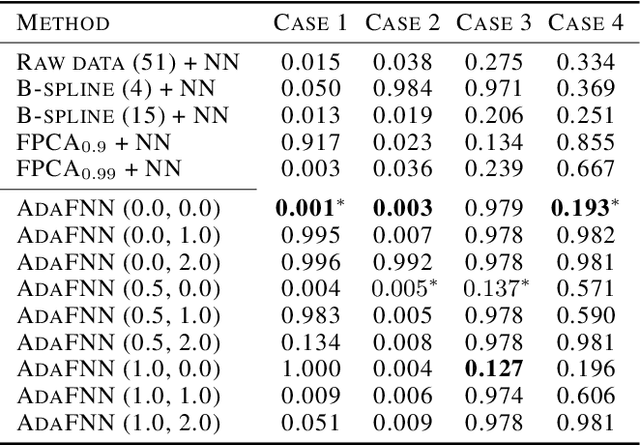
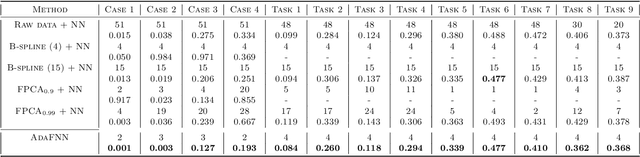
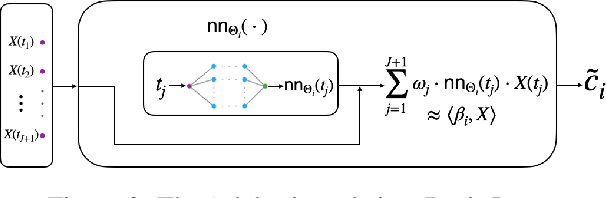
Despite their widespread success, the application of deep neural networks to functional data remains scarce today. The infinite dimensionality of functional data means standard learning algorithms can be applied only after appropriate dimension reduction, typically achieved via basis expansions. Currently, these bases are chosen a priori without the information for the task at hand and thus may not be effective for the designated task. We instead propose to adaptively learn these bases in an end-to-end fashion. We introduce neural networks that employ a new Basis Layer whose hidden units are each basis functions themselves implemented as a micro neural network. Our architecture learns to apply parsimonious dimension reduction to functional inputs that focuses only on information relevant to the target rather than irrelevant variation in the input function. Across numerous classification/regression tasks with functional data, our method empirically outperforms other types of neural networks, and we prove that our approach is statistically consistent with low generalization error. Code is available at: \url{https://github.com/jwyyy/AdaFNN}.
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
Apr 08, 2021
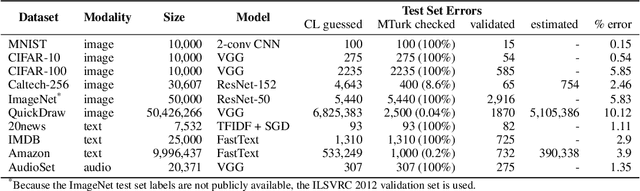
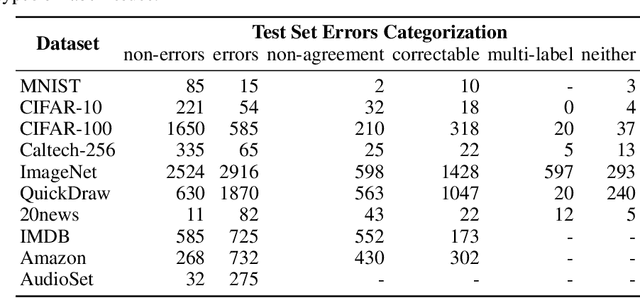
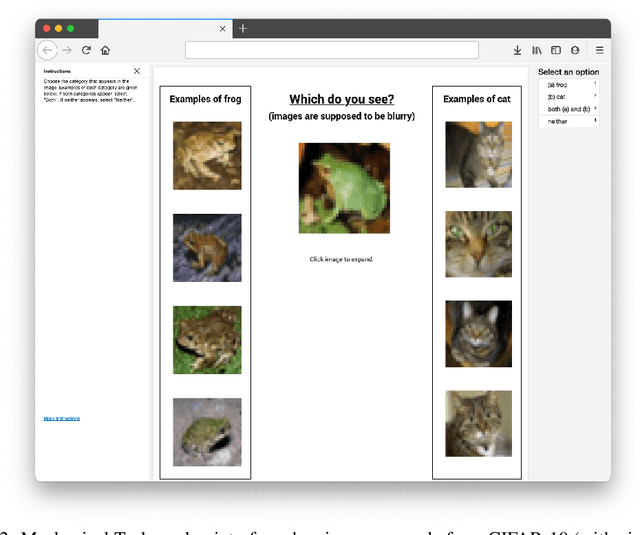
We algorithmically identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and widespread: we estimate an average of 3.4% errors across the 10 datasets, where for example 2916 label errors comprise 6% of the ImageNet validation set. Putative label errors are found using confident learning and then human-validated via crowdsourcing (54% of the algorithmically-flagged candidates are indeed erroneously labeled). Surprisingly, we find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data. For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. On CIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by 5%. Traditionally, ML practitioners choose which model to deploy based on test accuracy -- our findings advise caution here, proposing that judging models over correctly labeled test sets may be more useful, especially for noisy real-world datasets.