 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpinion Dynamics with Varying Susceptibility to Persuasion
Jan 24, 2018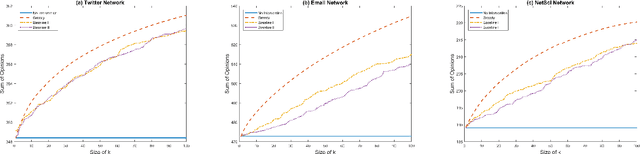
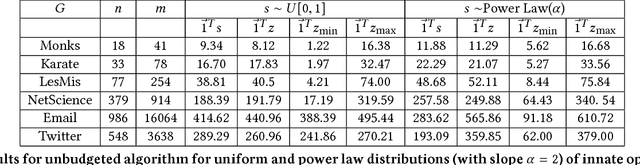
A long line of work in social psychology has studied variations in people's susceptibility to persuasion -- the extent to which they are willing to modify their opinions on a topic. This body of literature suggests an interesting perspective on theoretical models of opinion formation by interacting parties in a network: in addition to considering interventions that directly modify people's intrinsic opinions, it is also natural to consider interventions that modify people's susceptibility to persuasion. In this work, we adopt a popular model for social opinion dynamics, and we formalize the opinion maximization and minimization problems where interventions happen at the level of susceptibility. We show that modeling interventions at the level of susceptibility lead to an interesting family of new questions in network opinion dynamics. We find that the questions are quite different depending on whether there is an overall budget constraining the number of agents we can target or not. We give a polynomial-time algorithm for finding the optimal target-set to optimize the sum of opinions when there are no budget constraints on the size of the target-set. We show that this problem is NP-hard when there is a budget, and that the objective function is neither submodular nor supermodular. Finally, we propose a heuristic for the budgeted opinion optimization and show its efficacy at finding target-sets that optimize the sum of opinions compared on real world networks, including a Twitter network with real opinion estimates.
Selection Problems in the Presence of Implicit Bias
Jan 04, 2018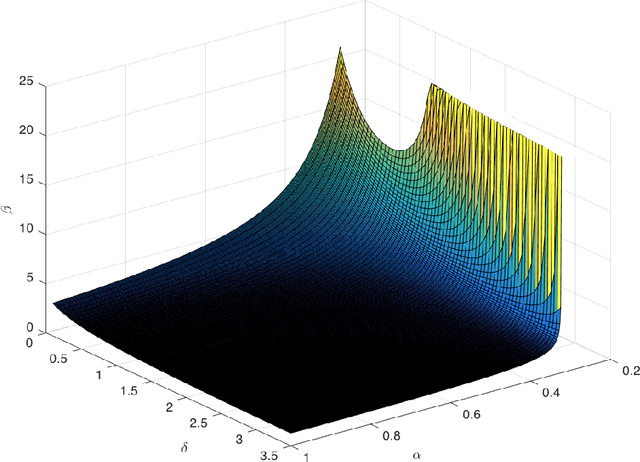
Over the past two decades, the notion of implicit bias has come to serve as an important component in our understanding of discrimination in activities such as hiring, promotion, and school admissions. Research on implicit bias posits that when people evaluate others -- for example, in a hiring context -- their unconscious biases about membership in particular groups can have an effect on their decision-making, even when they have no deliberate intention to discriminate against members of these groups. A growing body of experimental work has pointed to the effect that implicit bias can have in producing adverse outcomes. Here we propose a theoretical model for studying the effects of implicit bias on selection decisions, and a way of analyzing possible procedural remedies for implicit bias within this model. A canonical situation represented by our model is a hiring setting: a recruiting committee is trying to choose a set of finalists to interview among the applicants for a job, evaluating these applicants based on their future potential, but their estimates of potential are skewed by implicit bias against members of one group. In this model, we show that measures such as the Rooney Rule, a requirement that at least one of the finalists be chosen from the affected group, can not only improve the representation of this affected group, but also lead to higher payoffs in absolute terms for the organization performing the recruiting. However, identifying the conditions under which such measures can lead to improved payoffs involves subtle trade-offs between the extent of the bias and the underlying distribution of applicant characteristics, leading to novel theoretical questions about order statistics in the presence of probabilistic side information.
On Fairness and Calibration
Nov 03, 2017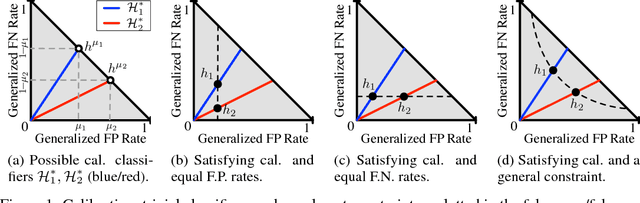
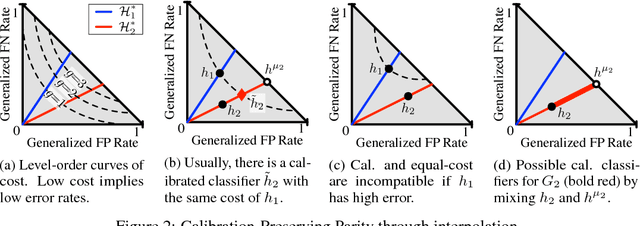
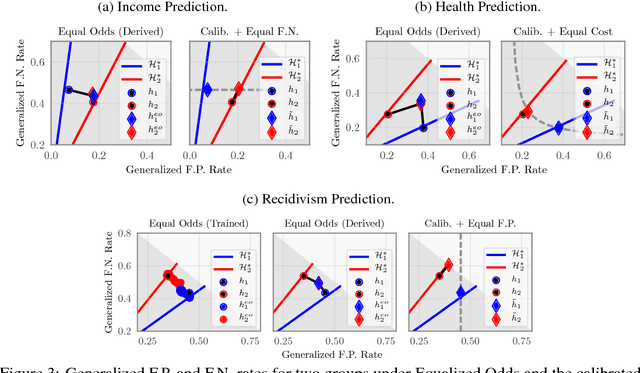
The machine learning community has become increasingly concerned with the potential for bias and discrimination in predictive models. This has motivated a growing line of work on what it means for a classification procedure to be "fair." In this paper, we investigate the tension between minimizing error disparity across different population groups while maintaining calibrated probability estimates. We show that calibration is compatible only with a single error constraint (i.e. equal false-negatives rates across groups), and show that any algorithm that satisfies this relaxation is no better than randomizing a percentage of predictions for an existing classifier. These unsettling findings, which extend and generalize existing results, are empirically confirmed on several datasets.
The Theory is Predictive, but is it Complete? An Application to Human Perception of Randomness
Jun 21, 2017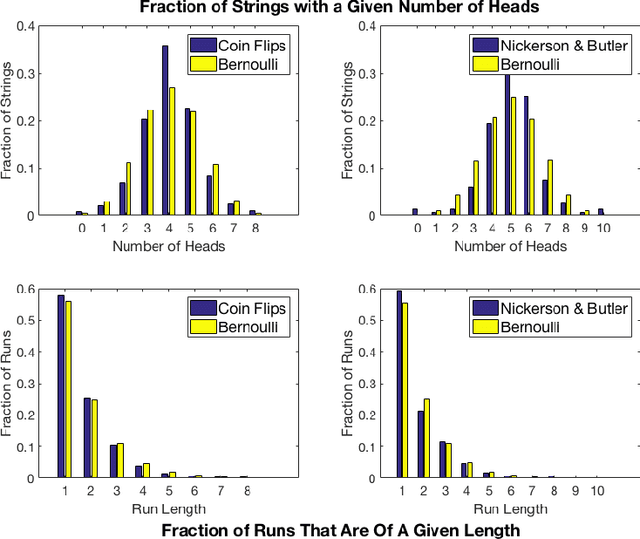
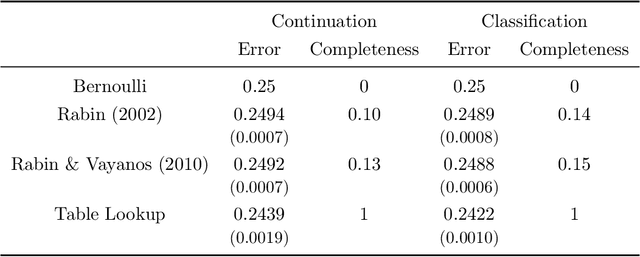
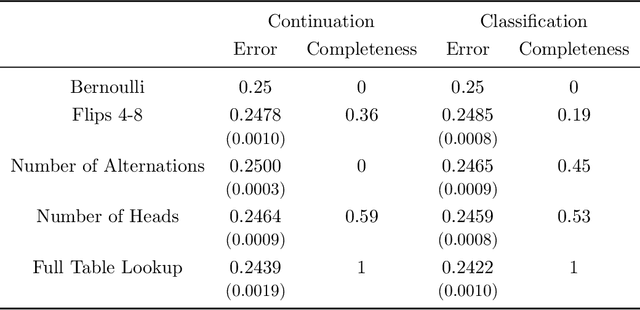
When we test a theory using data, it is common to focus on correctness: do the predictions of the theory match what we see in the data? But we also care about completeness: how much of the predictable variation in the data is captured by the theory? This question is difficult to answer, because in general we do not know how much "predictable variation" there is in the problem. In this paper, we consider approaches motivated by machine learning algorithms as a means of constructing a benchmark for the best attainable level of prediction. We illustrate our methods on the task of predicting human-generated random sequences. Relative to an atheoretical machine learning algorithm benchmark, we find that existing behavioral models explain roughly 15 percent of the predictable variation in this problem. This fraction is robust across several variations on the problem. We also consider a version of this approach for analyzing field data from domains in which human perception and generation of randomness has been used as a conceptual framework; these include sequential decision-making and repeated zero-sum games. In these domains, our framework for testing the completeness of theories provides a way of assessing their effectiveness over different contexts; we find that despite some differences, the existing theories are fairly stable across our field domains in their performance relative to the benchmark. Overall, our results indicate that (i) there is a significant amount of structure in this problem that existing models have yet to capture and (ii) there are rich domains in which machine learning may provide a viable approach to testing completeness.
On the Expressive Power of Deep Neural Networks
Jun 18, 2017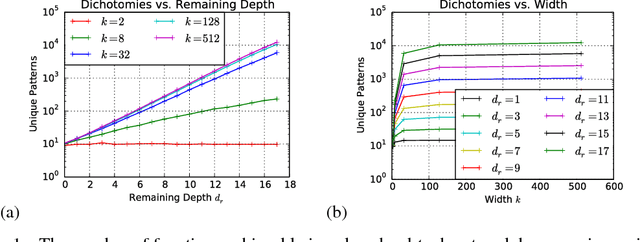


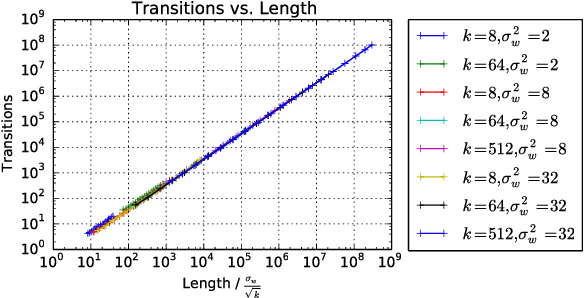
We propose a new approach to the problem of neural network expressivity, which seeks to characterize how structural properties of a neural network family affect the functions it is able to compute. Our approach is based on an interrelated set of measures of expressivity, unified by the novel notion of trajectory length, which measures how the output of a network changes as the input sweeps along a one-dimensional path. Our findings can be summarized as follows: (1) The complexity of the computed function grows exponentially with depth. (2) All weights are not equal: trained networks are more sensitive to their lower (initial) layer weights. (3) Regularizing on trajectory length (trajectory regularization) is a simpler alternative to batch normalization, with the same performance.
Comparison-Based Choices
May 16, 2017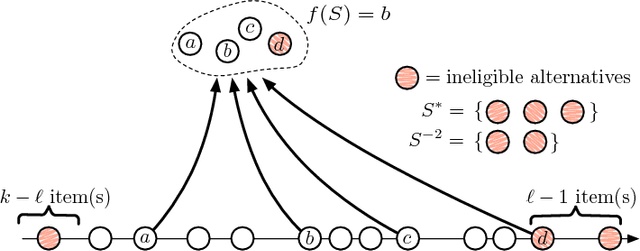
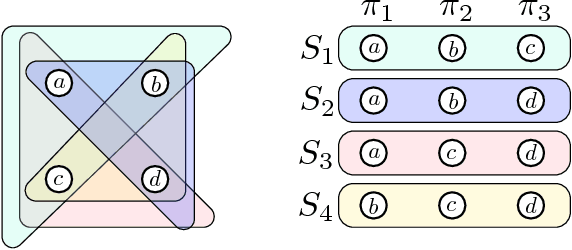
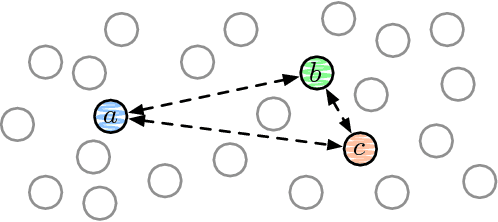
A broad range of on-line behaviors are mediated by interfaces in which people make choices among sets of options. A rich and growing line of work in the behavioral sciences indicate that human choices follow not only from the utility of alternatives, but also from the choice set in which alternatives are presented. In this work we study comparison-based choice functions, a simple but surprisingly rich class of functions capable of exhibiting so-called choice-set effects. Motivated by the challenge of predicting complex choices, we study the query complexity of these functions in a variety of settings. We consider settings that allow for active queries or passive observation of a stream of queries, and give analyses both at the granularity of individuals or populations that might exhibit heterogeneous choice behavior. Our main result is that any comparison-based choice function in one dimension can be inferred as efficiently as a basic maximum or minimum choice function across many query contexts, suggesting that choice-set effects need not entail any fundamental algorithmic barriers to inference. We also introduce a class of choice functions we call distance-comparison-based functions, and briefly discuss the analysis of such functions. The framework we outline provides intriguing connections between human choice behavior and a range of questions in the theory of sorting.
Survey of Expressivity in Deep Neural Networks
Nov 24, 2016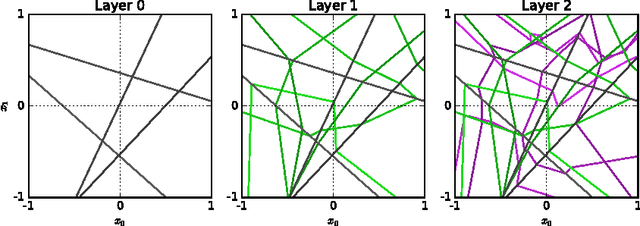

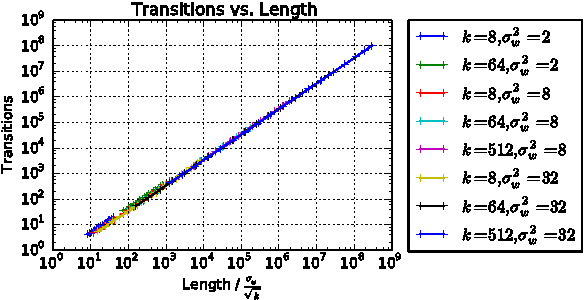
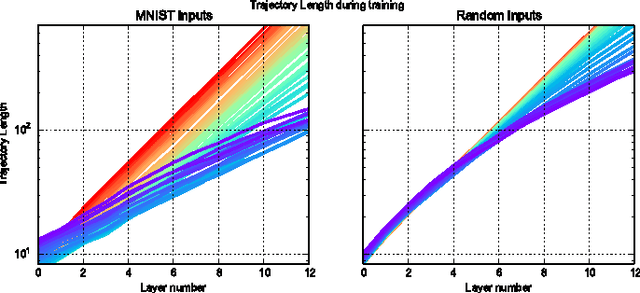
We survey results on neural network expressivity described in "On the Expressive Power of Deep Neural Networks". The paper motivates and develops three natural measures of expressiveness, which all display an exponential dependence on the depth of the network. In fact, all of these measures are related to a fourth quantity, trajectory length. This quantity grows exponentially in the depth of the network, and is responsible for the depth sensitivity observed. These results translate to consequences for networks during and after training. They suggest that parameters earlier in a network have greater influence on its expressive power -- in particular, given a layer, its influence on expressivity is determined by the remaining depth of the network after that layer. This is verified with experiments on MNIST and CIFAR-10. We also explore the effect of training on the input-output map, and find that it trades off between the stability and expressivity.
Inherent Trade-Offs in the Fair Determination of Risk Scores
Nov 17, 2016Recent discussion in the public sphere about algorithmic classification has involved tension between competing notions of what it means for a probabilistic classification to be fair to different groups. We formalize three fairness conditions that lie at the heart of these debates, and we prove that except in highly constrained special cases, there is no method that can satisfy these three conditions simultaneously. Moreover, even satisfying all three conditions approximately requires that the data lie in an approximate version of one of the constrained special cases identified by our theorem. These results suggest some of the ways in which key notions of fairness are incompatible with each other, and hence provide a framework for thinking about the trade-offs between them.
Assessing Human Error Against a Benchmark of Perfection
Jun 15, 2016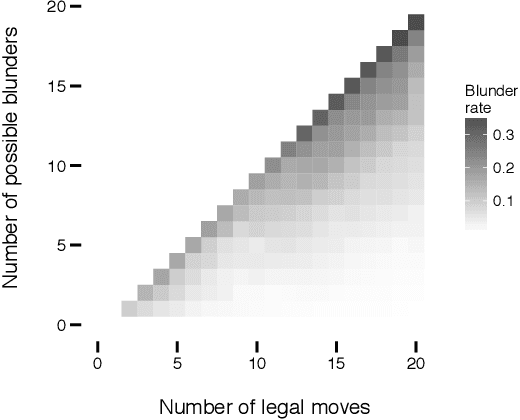

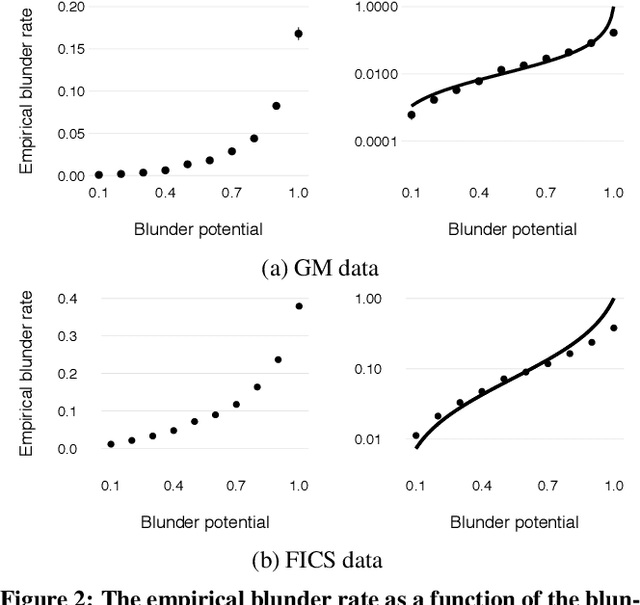
An increasing number of domains are providing us with detailed trace data on human decisions in settings where we can evaluate the quality of these decisions via an algorithm. Motivated by this development, an emerging line of work has begun to consider whether we can characterize and predict the kinds of decisions where people are likely to make errors. To investigate what a general framework for human error prediction might look like, we focus on a model system with a rich history in the behavioral sciences: the decisions made by chess players as they select moves in a game. We carry out our analysis at a large scale, employing datasets with several million recorded games, and using chess tablebases to acquire a form of ground truth for a subset of chess positions that have been completely solved by computers but remain challenging even for the best players in the world. We organize our analysis around three categories of features that we argue are present in most settings where the analysis of human error is applicable: the skill of the decision-maker, the time available to make the decision, and the inherent difficulty of the decision. We identify rich structure in all three of these categories of features, and find strong evidence that in our domain, features describing the inherent difficulty of an instance are significantly more powerful than features based on skill or time.
Do Cascades Recur?
Feb 02, 2016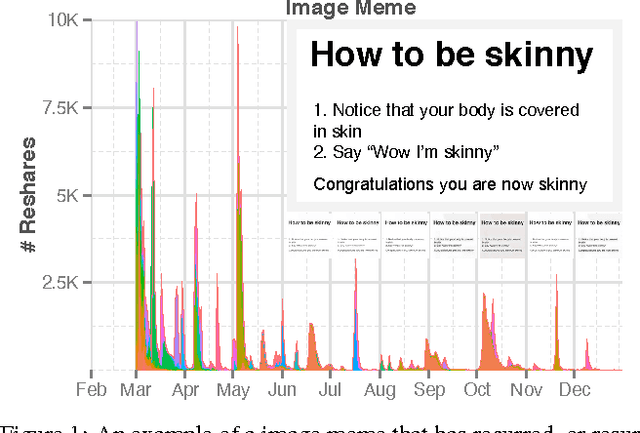

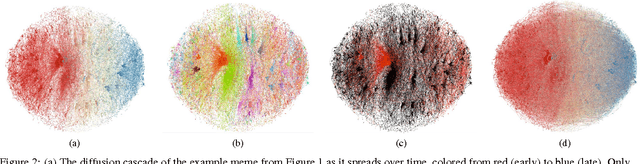
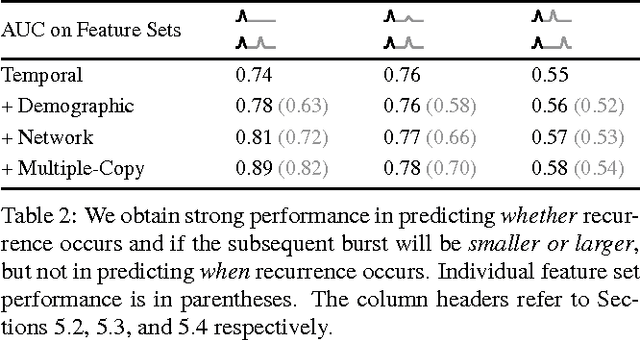
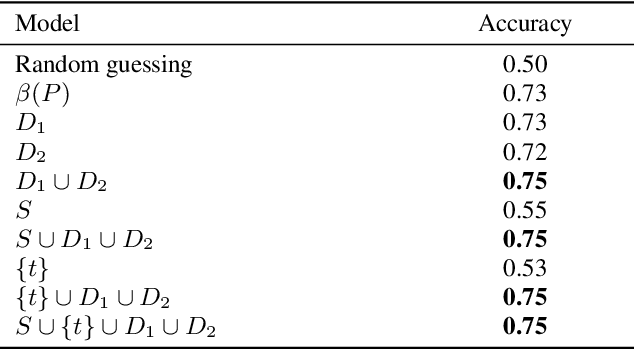
Cascades of information-sharing are a primary mechanism by which content reaches its audience on social media, and an active line of research has studied how such cascades, which form as content is reshared from person to person, develop and subside. In this paper, we perform a large-scale analysis of cascades on Facebook over significantly longer time scales, and find that a more complex picture emerges, in which many large cascades recur, exhibiting multiple bursts of popularity with periods of quiescence in between. We characterize recurrence by measuring the time elapsed between bursts, their overlap and proximity in the social network, and the diversity in the demographics of individuals participating in each peak. We discover that content virality, as revealed by its initial popularity, is a main driver of recurrence, with the availability of multiple copies of that content helping to spark new bursts. Still, beyond a certain popularity of content, the rate of recurrence drops as cascades start exhausting the population of interested individuals. We reproduce these observed patterns in a simple model of content recurrence simulated on a real social network. Using only characteristics of a cascade's initial burst, we demonstrate strong performance in predicting whether it will recur in the future.