 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Human-Language Model Interaction
Dec 20, 2022



Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
Melody transcription via generative pre-training
Dec 04, 2022



Despite the central role that melody plays in music perception, it remains an open challenge in music information retrieval to reliably detect the notes of the melody present in an arbitrary music recording. A key challenge in melody transcription is building methods which can handle broad audio containing any number of instrument ensembles and musical styles - existing strategies work well for some melody instruments or styles but not all. To confront this challenge, we leverage representations from Jukebox (Dhariwal et al. 2020), a generative model of broad music audio, thereby improving performance on melody transcription by $20$% relative to conventional spectrogram features. Another obstacle in melody transcription is a lack of training data - we derive a new dataset containing $50$ hours of melody transcriptions from crowdsourced annotations of broad music. The combination of generative pre-training and a new dataset for this task results in $77$% stronger performance on melody transcription relative to the strongest available baseline. By pairing our new melody transcription approach with solutions for beat detection, key estimation, and chord recognition, we build Sheet Sage, a system capable of transcribing human-readable lead sheets directly from music audio. Audio examples can be found at https://chrisdonahue.com/sheetsage and code at https://github.com/chrisdonahue/sheetsage .
Diffusion-LM Improves Controllable Text Generation
May 27, 2022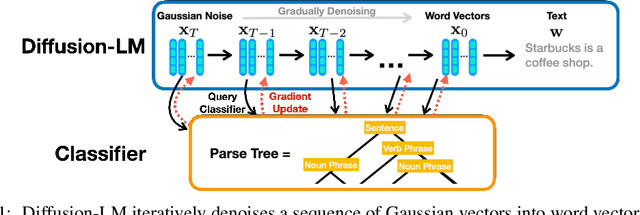

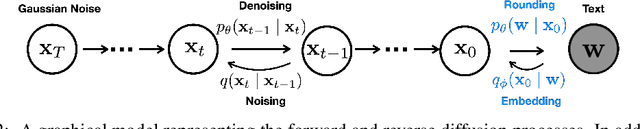
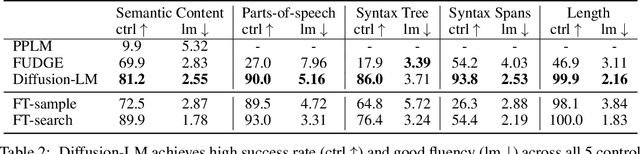
Controlling the behavior of language models (LMs) without re-training is a major open problem in natural language generation. While recent works have demonstrated successes on controlling simple sentence attributes (e.g., sentiment), there has been little progress on complex, fine-grained controls (e.g., syntactic structure). To address this challenge, we develop a new non-autoregressive language model based on continuous diffusions that we call Diffusion-LM. Building upon the recent successes of diffusion models in continuous domains, Diffusion-LM iteratively denoises a sequence of Gaussian vectors into word vectors, yielding a sequence of intermediate latent variables. The continuous, hierarchical nature of these intermediate variables enables a simple gradient-based algorithm to perform complex, controllable generation tasks. We demonstrate successful control of Diffusion-LM for six challenging fine-grained control tasks, significantly outperforming prior work.
Parallel and Flexible Sampling from Autoregressive Models via Langevin Dynamics
May 17, 2021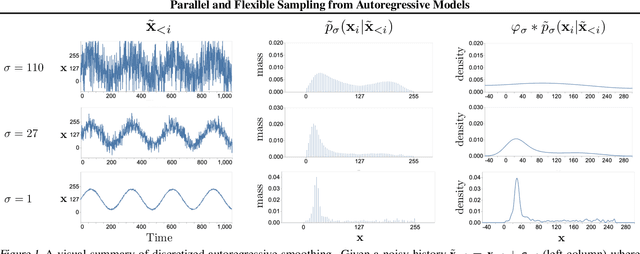
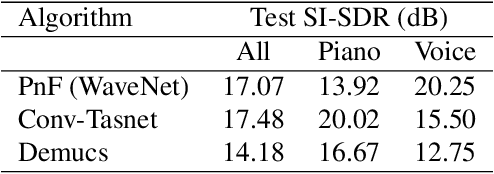
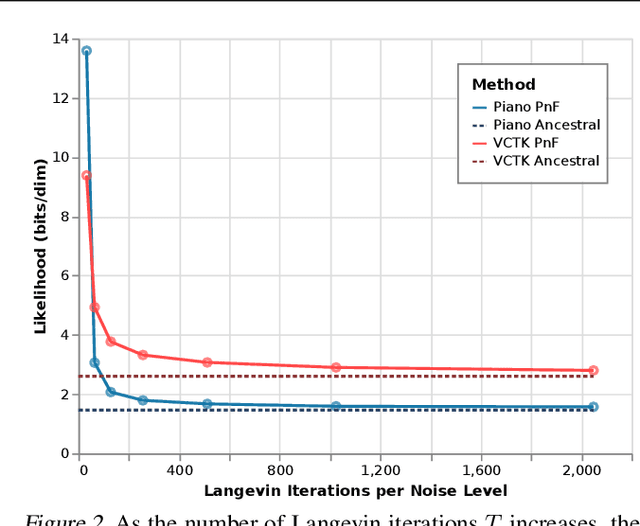
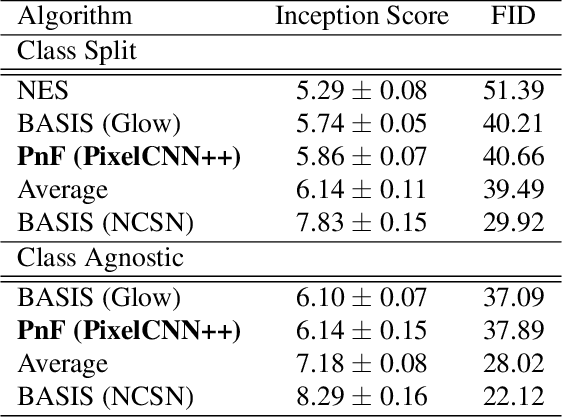
This paper introduces an alternative approach to sampling from autoregressive models. Autoregressive models are typically sampled sequentially, according to the transition dynamics defined by the model. Instead, we propose a sampling procedure that initializes a sequence with white noise and follows a Markov chain defined by Langevin dynamics on the global log-likelihood of the sequence. This approach parallelizes the sampling process and generalizes to conditional sampling. Using an autoregressive model as a Bayesian prior, we can steer the output of a generative model using a conditional likelihood or constraints. We apply these techniques to autoregressive models in the visual and audio domains, with competitive results for audio source separation, super-resolution, and inpainting.
MAUVE: Human-Machine Divergence Curves for Evaluating Open-Ended Text Generation
Feb 02, 2021
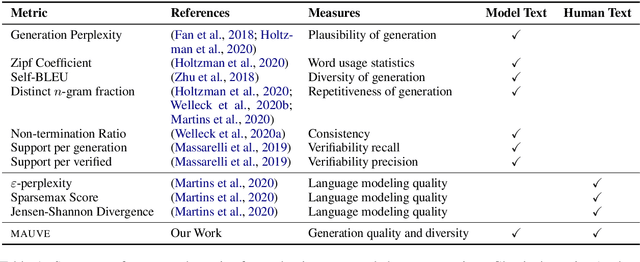
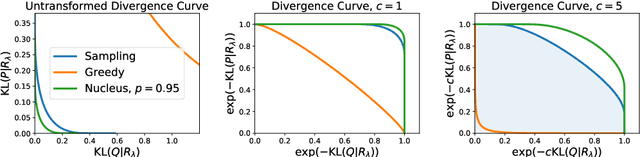
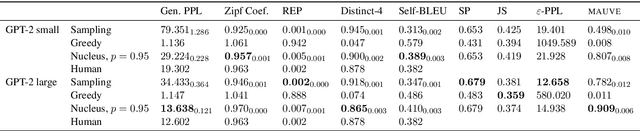
Despite major advances in open-ended text generation, there has been limited progress in designing evaluation metrics for this task. We propose MAUVE -- a metric for open-ended text generation, which directly compares the distribution of machine-generated text to that of human language. MAUVE measures the mean area under the divergence curve for the two distributions, exploring the trade-off between two types of errors: those arising from parts of the human distribution that the model distribution approximates well, and those it does not. We present experiments across two open-ended generation tasks in the web text domain and the story domain, and a variety of decoding algorithms and model sizes. Our results show that evaluation under MAUVE indeed reflects the more natural behavior with respect to model size, compared to prior metrics. MAUVE's ordering of the decoding algorithms also agrees with that of generation perplexity, the most widely used metric in open-ended text generation; however, MAUVE presents a more principled evaluation metric for the task as it considers both model and human text.
Faster Policy Learning with Continuous-Time Gradients
Dec 12, 2020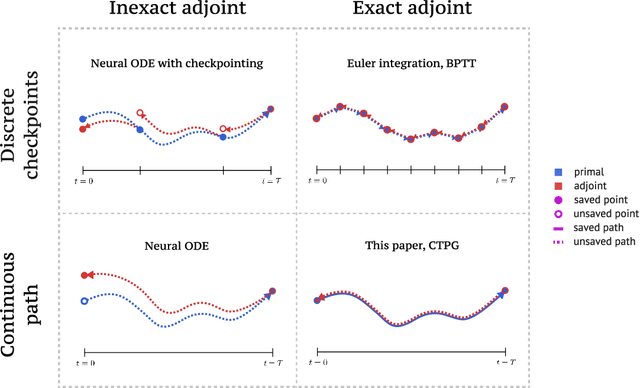
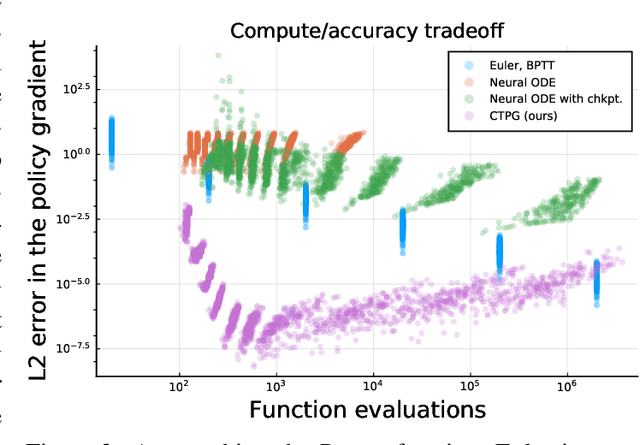
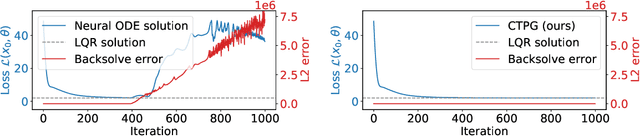
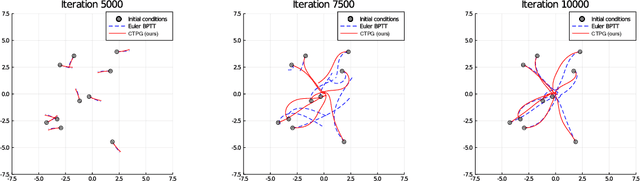
We study the estimation of policy gradients for continuous-time systems with known dynamics. By reframing policy learning in continuous-time, we show that it is possible construct a more efficient and accurate gradient estimator. The standard back-propagation through time estimator (BPTT) computes exact gradients for a crude discretization of the continuous-time system. In contrast, we approximate continuous-time gradients in the original system. With the explicit goal of estimating continuous-time gradients, we are able to discretize adaptively and construct a more efficient policy gradient estimator which we call the Continuous-Time Policy Gradient (CTPG). We show that replacing BPTT policy gradients with more efficient CTPG estimates results in faster and more robust learning in a variety of control tasks and simulators.
An Information Bottleneck Approach for Controlling Conciseness in Rationale Extraction
May 01, 2020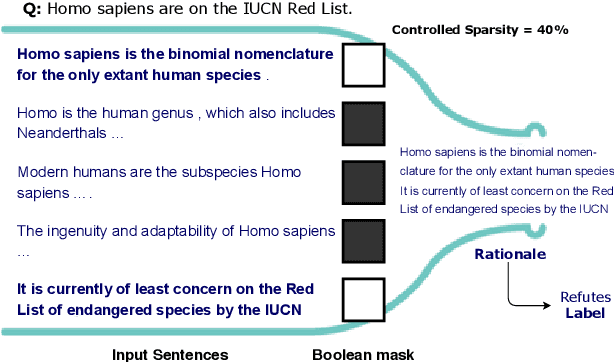
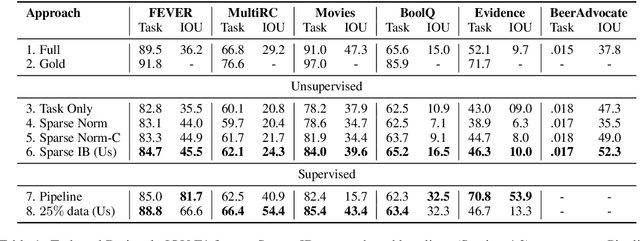
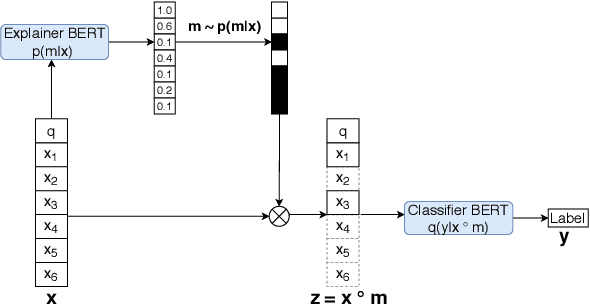
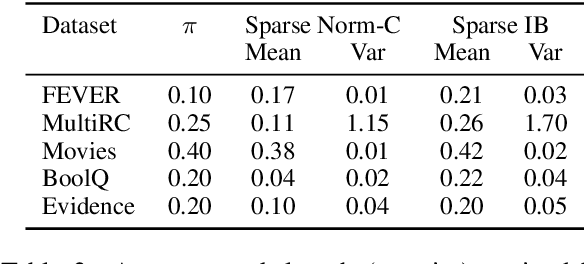
Decisions of complex language understanding models can be rationalized by limiting their inputs to a relevant subsequence of the original text. A rationale should be as concise as possible without significantly degrading task performance, but this balance can be difficult to achieve in practice. In this paper, we show that it is possible to better manage this trade-off by optimizing a bound on the Information Bottleneck (IB) objective. Our fully unsupervised approach jointly learns an explainer that predicts sparse binary masks over sentences, and an end-task predictor that considers only the extracted rationale. Using IB, we derive a learning objective that allows direct control of mask sparsity levels through a tunable sparse prior. Experiments on ERASER benchmark tasks demonstrate significant gains over norm-minimization techniques for both task performance and agreement with human rationales. Furthermore, we find that in the semi-supervised setting, a modest amount of gold rationales (25% of training examples) closes the gap with a model that uses the full input. Code: https://github.com/bhargaviparanjape/explainable_qa
Source Separation with Deep Generative Priors
Feb 19, 2020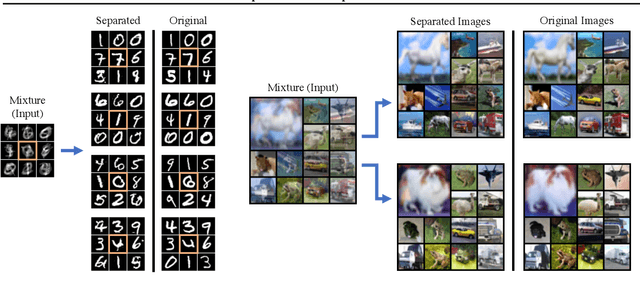
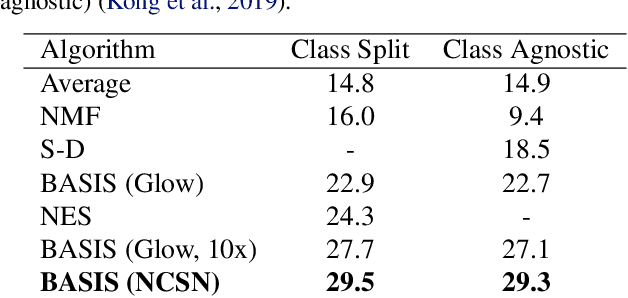
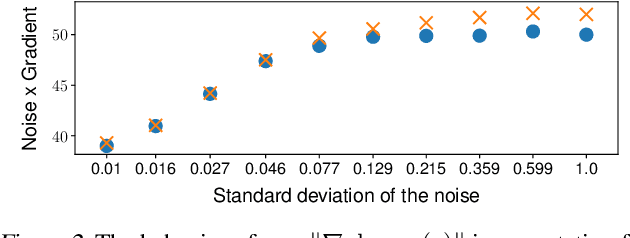
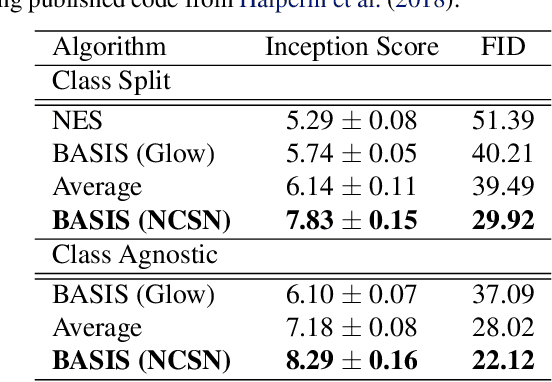
Despite substantial progress in signal source separation, results for richly structured data continue to contain perceptible artifacts. In contrast, recent deep generative models can produce authentic samples in a variety of domains that are indistinguishable from samples of the data distribution. This paper introduces a Bayesian approach to source separation that uses generative models as priors over the components of a mixture of sources, and Langevin dynamics to sample from the posterior distribution of sources given a mixture. This decouples the source separation problem from generative modeling, enabling us to directly use cutting-edge generative models as priors. The method achieves state-of-the-art performance for MNIST digit separation. We introduce new methodology for evaluating separation quality on richer datasets, providing quantitative evaluation of separation results on CIFAR-10. We also provide qualitative results on LSUN.
Convolutional Composer Classification
Nov 26, 2019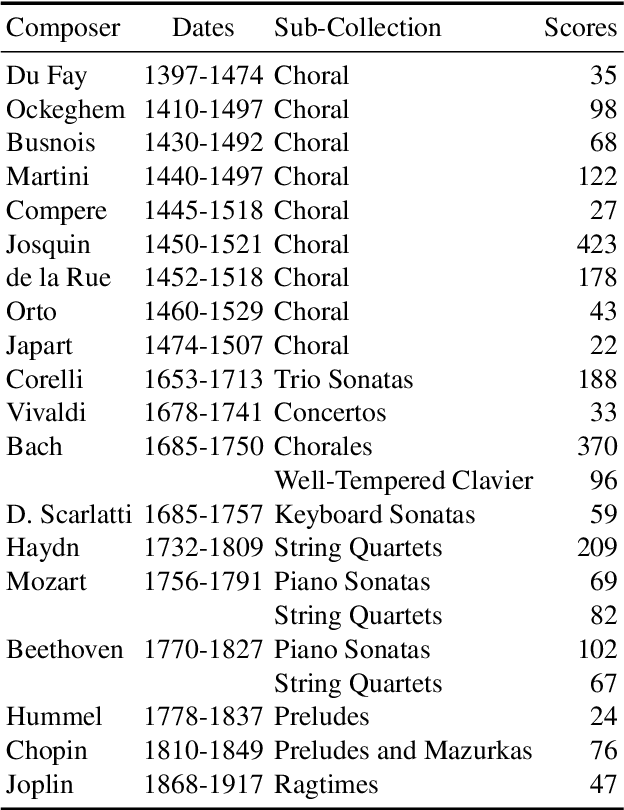

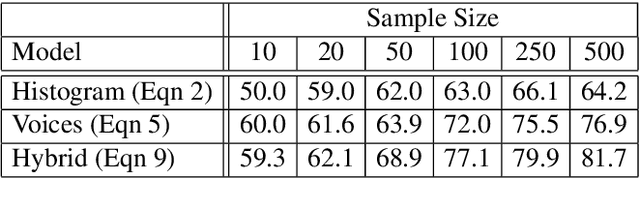
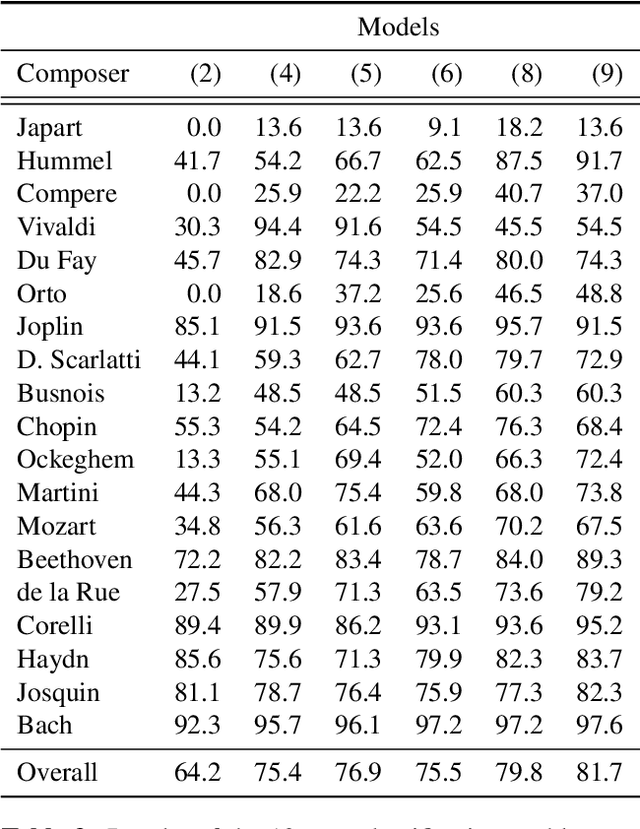
This paper investigates end-to-end learnable models for attributing composers to musical scores. We introduce several pooled, convolutional architectures for this task and draw connections between our approach and classical learning approaches based on global and n-gram features. We evaluate models on a corpus of 2,500 scores from the KernScores collection, authored by a variety of composers spanning the Renaissance era to the early 20th century. This corpus has substantial overlap with the corpora used in several previous, smaller studies; we compare our results on subsets of the corpus to these previous works.
Coupled Recurrent Models for Polyphonic Music Composition
Nov 20, 2018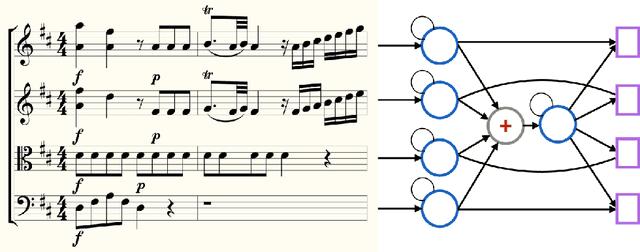



This work describes a novel recurrent model for music composition, which accounts for the rich statistical structure of polyphonic music. There are many ways to factor the probability distribution over musical scores; we consider the merits of various approaches and propose a new factorization that decomposes a score into a collection of concurrent, coupled time series: 'parts.' The model we propose borrows ideas from both convolutional neural models and recurrent neural models; we argue that these ideas are natural for capturing music's pitch invariances, temporal structure, and polyphony. We train generative models for homophonic and polyphonic composition on the KernScores dataset (Sapp, 2005) a collection of 2,300 musical scores comprised of around 2.8 million notes spanning time from the Renaissance to the early 20th century. While evaluation of generative models is known to be hard (Theis et al., 2016), we present careful quantitative results using a unit-adjusted cross entropy metric that is independent of how we factor the distribution over scores. We also present qualitative results using a blind discrimination test.