 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Conditional Quantiles via Reduction to Classification
Jun 27, 2012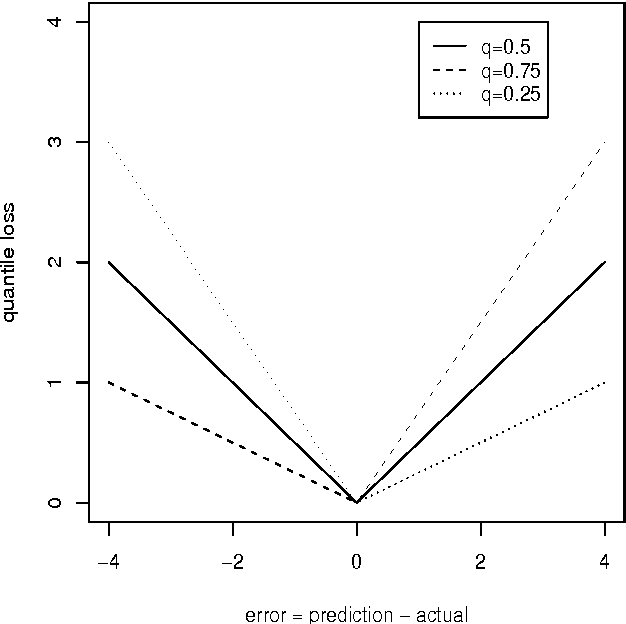
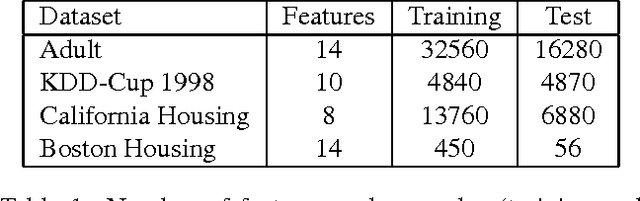
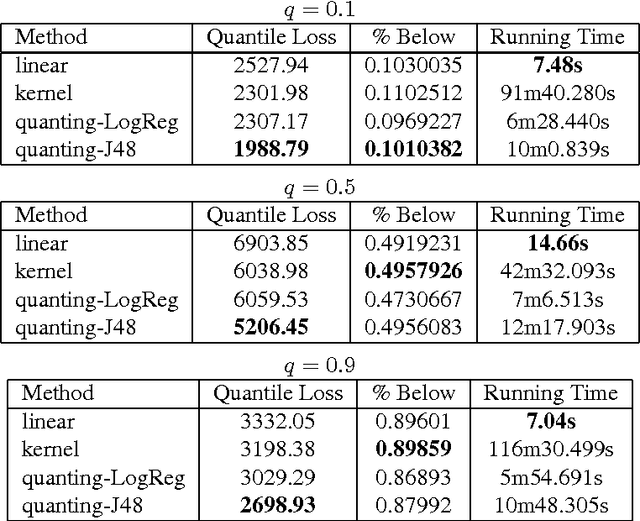
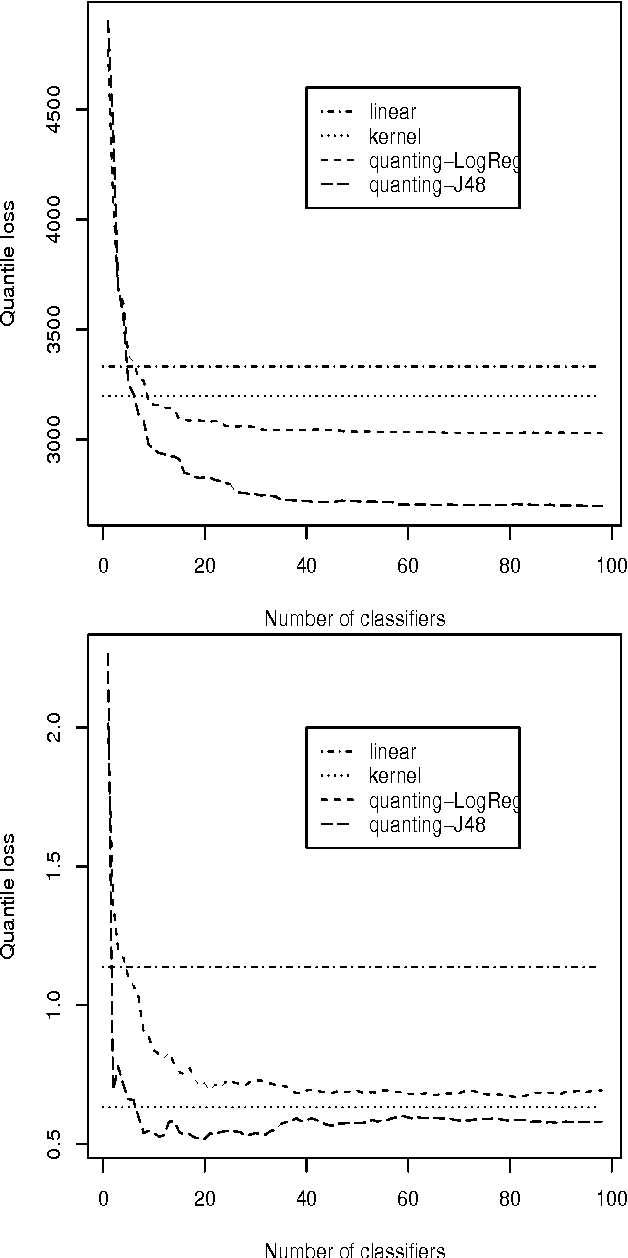
We show how to reduce the process of predicting general order statistics (and the median in particular) to solving classification. The accompanying theoretical statement shows that the regret of the classifier bounds the regret of the quantile regression under a quantile loss. We also test this reduction empirically against existing quantile regression methods on large real-world datasets and discover that it provides state-of-the-art performance.
Contextual Bandit Learning with Predictable Rewards
Mar 02, 2012Contextual bandit learning is a reinforcement learning problem where the learner repeatedly receives a set of features (context), takes an action and receives a reward based on the action and context. We consider this problem under a realizability assumption: there exists a function in a (known) function class, always capable of predicting the expected reward, given the action and context. Under this assumption, we show three things. We present a new algorithm---Regressor Elimination--- with a regret similar to the agnostic setting (i.e. in the absence of realizability assumption). We prove a new lower bound showing no algorithm can achieve superior performance in the worst case even with the realizability assumption. However, we do show that for any set of policies (mapping contexts to actions), there is a distribution over rewards (given context) such that our new algorithm has constant regret unlike the previous approaches.
A Contextual-Bandit Approach to Personalized News Article Recommendation
Mar 01, 2012
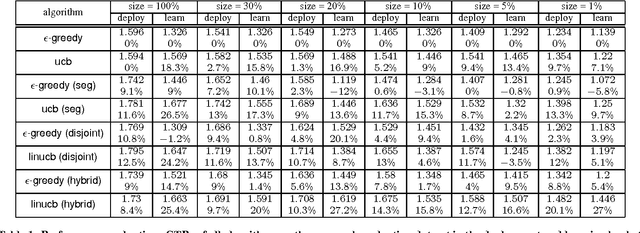
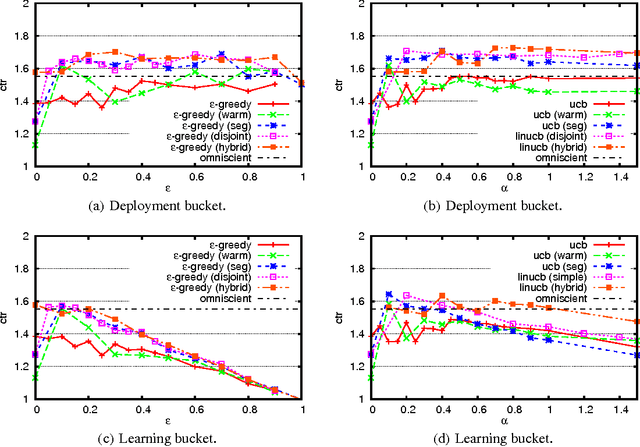
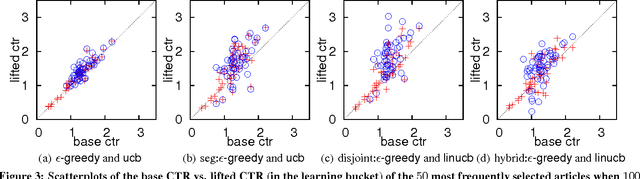
Personalized web services strive to adapt their services (advertisements, news articles, etc) to individual users by making use of both content and user information. Despite a few recent advances, this problem remains challenging for at least two reasons. First, web service is featured with dynamically changing pools of content, rendering traditional collaborative filtering methods inapplicable. Second, the scale of most web services of practical interest calls for solutions that are both fast in learning and computation. In this work, we model personalized recommendation of news articles as a contextual bandit problem, a principled approach in which a learning algorithm sequentially selects articles to serve users based on contextual information about the users and articles, while simultaneously adapting its article-selection strategy based on user-click feedback to maximize total user clicks. The contributions of this work are three-fold. First, we propose a new, general contextual bandit algorithm that is computationally efficient and well motivated from learning theory. Second, we argue that any bandit algorithm can be reliably evaluated offline using previously recorded random traffic. Finally, using this offline evaluation method, we successfully applied our new algorithm to a Yahoo! Front Page Today Module dataset containing over 33 million events. Results showed a 12.5% click lift compared to a standard context-free bandit algorithm, and the advantage becomes even greater when data gets more scarce.
* 10 pages, 5 figures
Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms
Mar 01, 2012

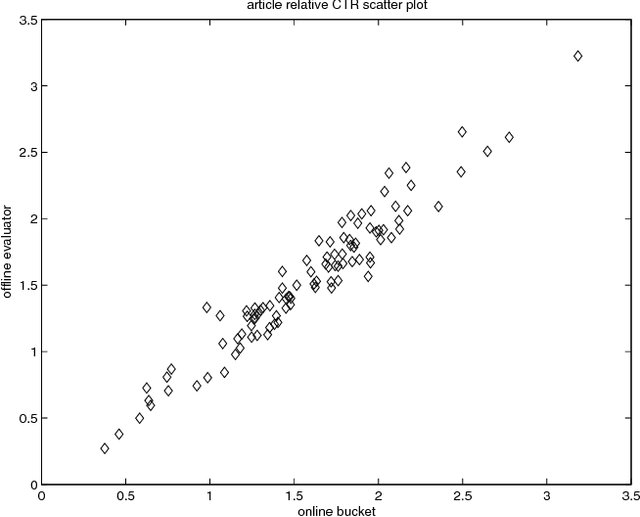
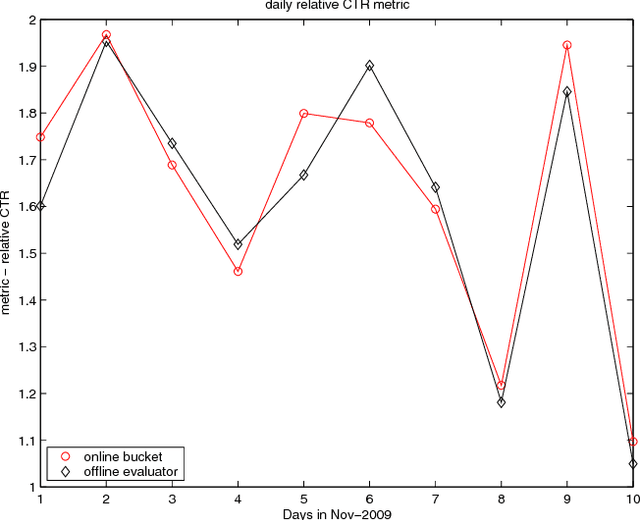
Contextual bandit algorithms have become popular for online recommendation systems such as Digg, Yahoo! Buzz, and news recommendation in general. \emph{Offline} evaluation of the effectiveness of new algorithms in these applications is critical for protecting online user experiences but very challenging due to their "partial-label" nature. Common practice is to create a simulator which simulates the online environment for the problem at hand and then run an algorithm against this simulator. However, creating simulator itself is often difficult and modeling bias is usually unavoidably introduced. In this paper, we introduce a \emph{replay} methodology for contextual bandit algorithm evaluation. Different from simulator-based approaches, our method is completely data-driven and very easy to adapt to different applications. More importantly, our method can provide provably unbiased evaluations. Our empirical results on a large-scale news article recommendation dataset collected from Yahoo! Front Page conform well with our theoretical results. Furthermore, comparisons between our offline replay and online bucket evaluation of several contextual bandit algorithms show accuracy and effectiveness of our offline evaluation method.
Learning Performance of Prediction Markets with Kelly Bettors
Jan 31, 2012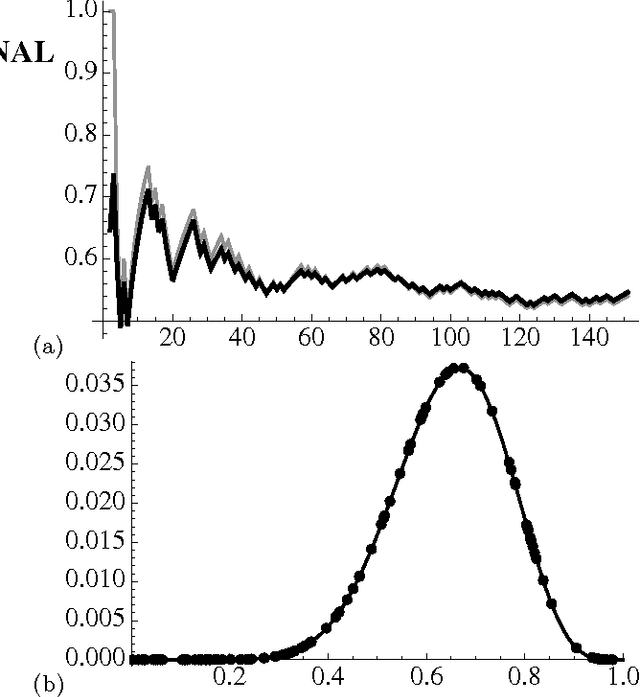
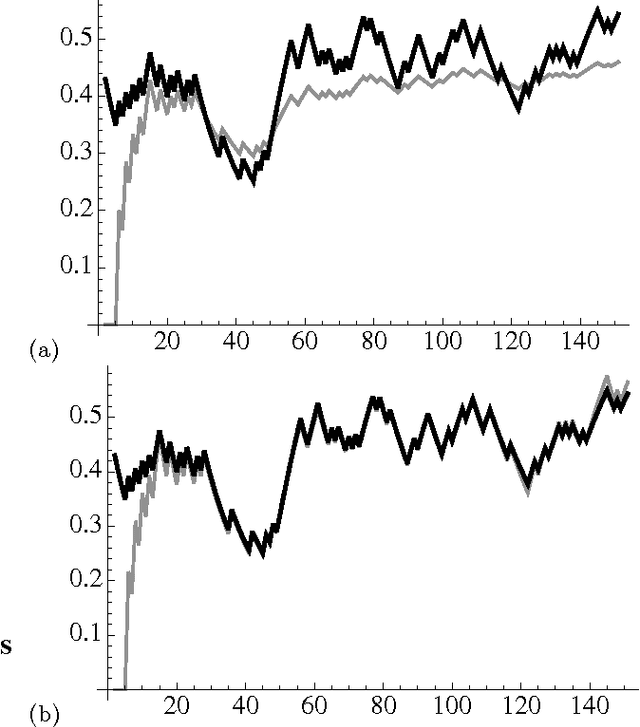
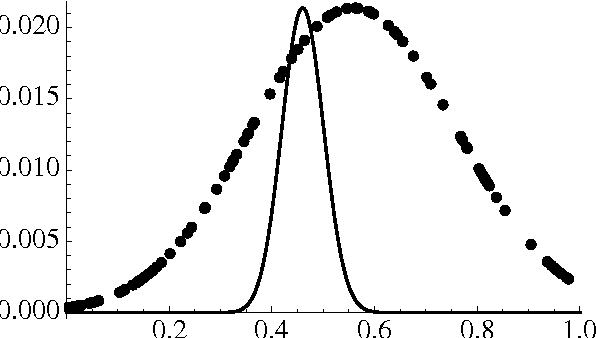
In evaluating prediction markets (and other crowd-prediction mechanisms), investigators have repeatedly observed a so-called "wisdom of crowds" effect, which roughly says that the average of participants performs much better than the average participant. The market price---an average or at least aggregate of traders' beliefs---offers a better estimate than most any individual trader's opinion. In this paper, we ask a stronger question: how does the market price compare to the best trader's belief, not just the average trader. We measure the market's worst-case log regret, a notion common in machine learning theory. To arrive at a meaningful answer, we need to assume something about how traders behave. We suppose that every trader optimizes according to the Kelly criteria, a strategy that provably maximizes the compound growth of wealth over an (infinite) sequence of market interactions. We show several consequences. First, the market prediction is a wealth-weighted average of the individual participants' beliefs. Second, the market learns at the optimal rate, the market price reacts exactly as if updating according to Bayes' Law, and the market prediction has low worst-case log regret to the best individual participant. We simulate a sequence of markets where an underlying true probability exists, showing that the market converges to the true objective frequency as if updating a Beta distribution, as the theory predicts. If agents adopt a fractional Kelly criteria, a common practical variant, we show that agents behave like full-Kelly agents with beliefs weighted between their own and the market's, and that the market price converges to a time-discounted frequency. Our analysis provides a new justification for fractional Kelly betting, a strategy widely used in practice for ad-hoc reasons. Finally, we propose a method for an agent to learn her own optimal Kelly fraction.
Contextual Bandit Algorithms with Supervised Learning Guarantees
Oct 27, 2011We address the problem of learning in an online, bandit setting where the learner must repeatedly select among $K$ actions, but only receives partial feedback based on its choices. We establish two new facts: First, using a new algorithm called Exp4.P, we show that it is possible to compete with the best in a set of $N$ experts with probability $1-\delta$ while incurring regret at most $O(\sqrt{KT\ln(N/\delta)})$ over $T$ time steps. The new algorithm is tested empirically in a large-scale, real-world dataset. Second, we give a new algorithm called VE that competes with a possibly infinite set of policies of VC-dimension $d$ while incurring regret at most $O(\sqrt{T(d\ln(T) + \ln (1/\delta))})$ with probability $1-\delta$. These guarantees improve on those of all previous algorithms, whether in a stochastic or adversarial environment, and bring us closer to providing supervised learning type guarantees for the contextual bandit setting.
Online Importance Weight Aware Updates
Jun 18, 2011
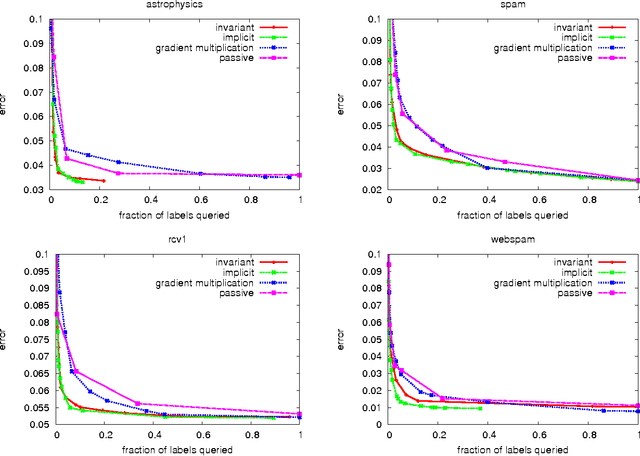
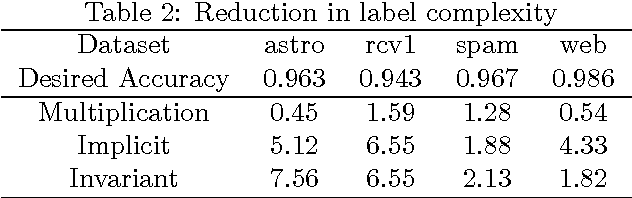
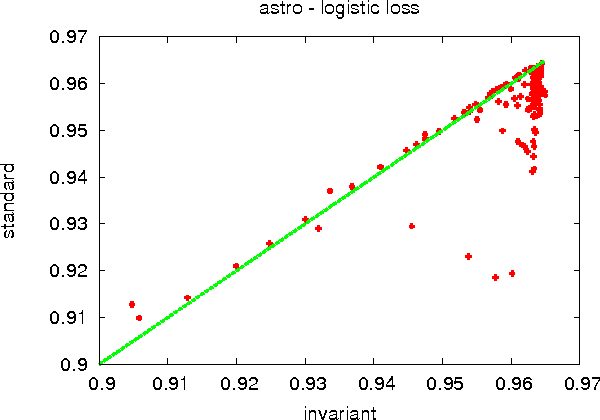
An importance weight quantifies the relative importance of one example over another, coming up in applications of boosting, asymmetric classification costs, reductions, and active learning. The standard approach for dealing with importance weights in gradient descent is via multiplication of the gradient. We first demonstrate the problems of this approach when importance weights are large, and argue in favor of more sophisticated ways for dealing with them. We then develop an approach which enjoys an invariance property: that updating twice with importance weight $h$ is equivalent to updating once with importance weight $2h$. For many important losses this has a closed form update which satisfies standard regret guarantees when all examples have $h=1$. We also briefly discuss two other reasonable approaches for handling large importance weights. Empirically, these approaches yield substantially superior prediction with similar computational performance while reducing the sensitivity of the algorithm to the exact setting of the learning rate. We apply these to online active learning yielding an extraordinarily fast active learning algorithm that works even in the presence of adversarial noise.
Efficient Optimal Learning for Contextual Bandits
Jun 13, 2011We address the problem of learning in an online setting where the learner repeatedly observes features, selects among a set of actions, and receives reward for the action taken. We provide the first efficient algorithm with an optimal regret. Our algorithm uses a cost sensitive classification learner as an oracle and has a running time $\mathrm{polylog}(N)$, where $N$ is the number of classification rules among which the oracle might choose. This is exponentially faster than all previous algorithms that achieve optimal regret in this setting. Our formulation also enables us to create an algorithm with regret that is additive rather than multiplicative in feedback delay as in all previous work.
Doubly Robust Policy Evaluation and Learning
May 06, 2011
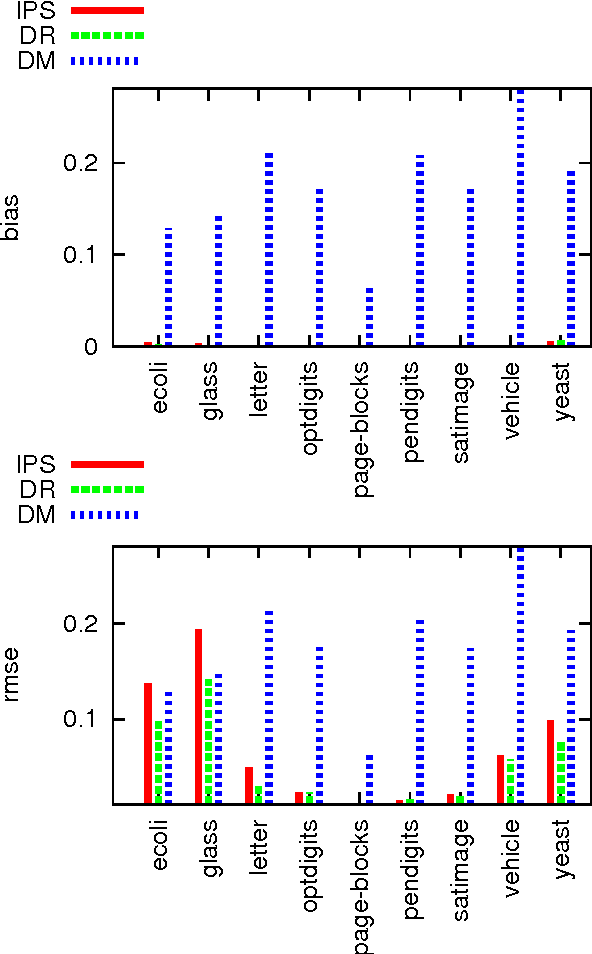
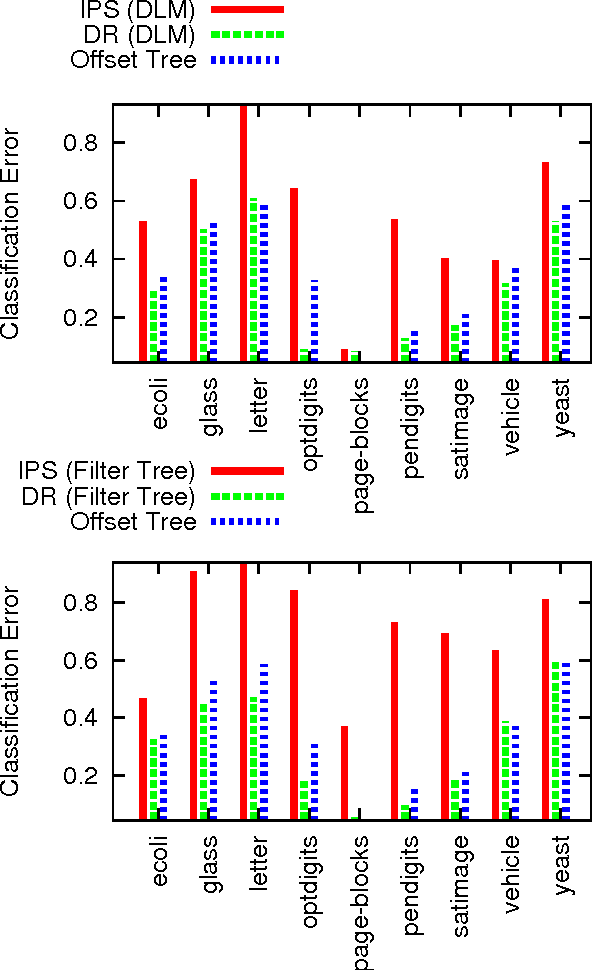
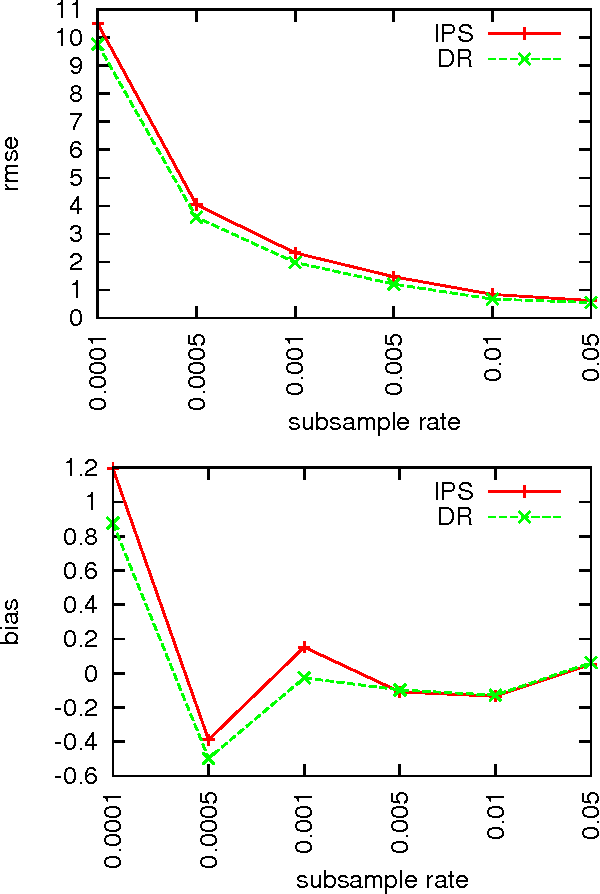
We study decision making in environments where the reward is only partially observed, but can be modeled as a function of an action and an observed context. This setting, known as contextual bandits, encompasses a wide variety of applications including health-care policy and Internet advertising. A central task is evaluation of a new policy given historic data consisting of contexts, actions and received rewards. The key challenge is that the past data typically does not faithfully represent proportions of actions taken by a new policy. Previous approaches rely either on models of rewards or models of the past policy. The former are plagued by a large bias whereas the latter have a large variance. In this work, we leverage the strength and overcome the weaknesses of the two approaches by applying the doubly robust technique to the problems of policy evaluation and optimization. We prove that this approach yields accurate value estimates when we have either a good (but not necessarily consistent) model of rewards or a good (but not necessarily consistent) model of past policy. Extensive empirical comparison demonstrates that the doubly robust approach uniformly improves over existing techniques, achieving both lower variance in value estimation and better policies. As such, we expect the doubly robust approach to become common practice.
Parallel Online Learning
Mar 22, 2011In this work we study parallelization of online learning, a core primitive in machine learning. In a parallel environment all known approaches for parallel online learning lead to delayed updates, where the model is updated using out-of-date information. In the worst case, or when examples are temporally correlated, delay can have a very adverse effect on the learning algorithm. Here, we analyze and present preliminary empirical results on a set of learning architectures based on a feature sharding approach that present various tradeoffs between delay, degree of parallelism, representation power and empirical performance.