 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reductions that Really Work
Feb 09, 2015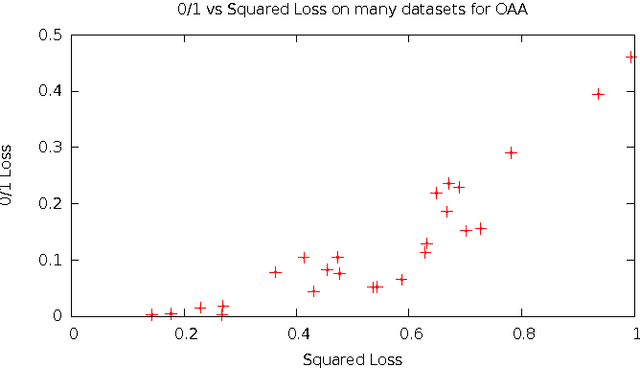
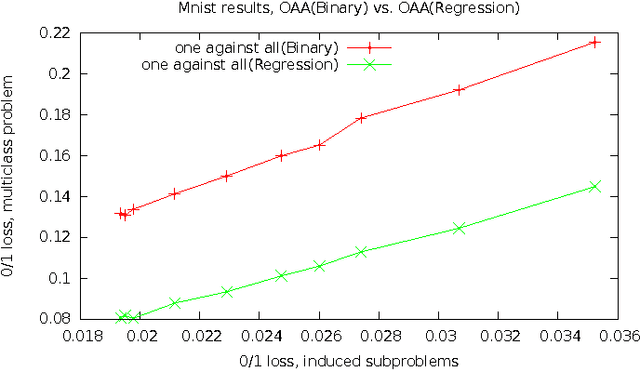
We provide a summary of the mathematical and computational techniques that have enabled learning reductions to effectively address a wide class of problems, and show that this approach to solving machine learning problems can be broadly useful.
Taming the Monster: A Fast and Simple Algorithm for Contextual Bandits
Oct 14, 2014
We present a new algorithm for the contextual bandit learning problem, where the learner repeatedly takes one of $K$ actions in response to the observed context, and observes the reward only for that chosen action. Our method assumes access to an oracle for solving fully supervised cost-sensitive classification problems and achieves the statistically optimal regret guarantee with only $\tilde{O}(\sqrt{KT/\log N})$ oracle calls across all $T$ rounds, where $N$ is the number of policies in the policy class we compete against. By doing so, we obtain the most practical contextual bandit learning algorithm amongst approaches that work for general policy classes. We further conduct a proof-of-concept experiment which demonstrates the excellent computational and prediction performance of (an online variant of) our algorithm relative to several baselines.
Scalable Nonlinear Learning with Adaptive Polynomial Expansions
Oct 02, 2014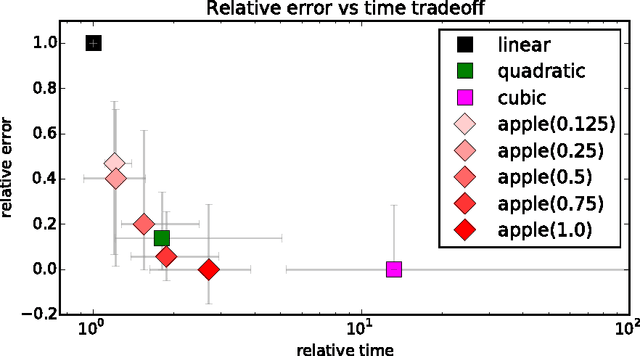

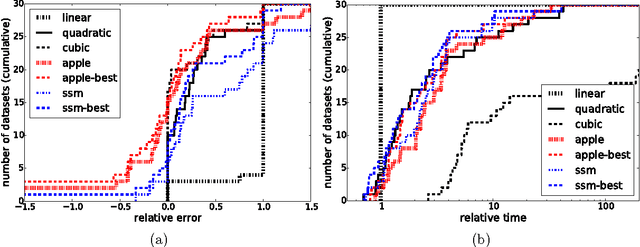
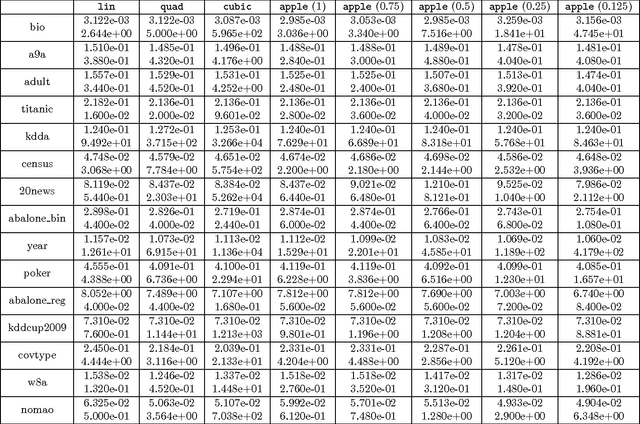
Can we effectively learn a nonlinear representation in time comparable to linear learning? We describe a new algorithm that explicitly and adaptively expands higher-order interaction features over base linear representations. The algorithm is designed for extreme computational efficiency, and an extensive experimental study shows that its computation/prediction tradeoff ability compares very favorably against strong baselines.
Normalized Online Learning
Aug 09, 2014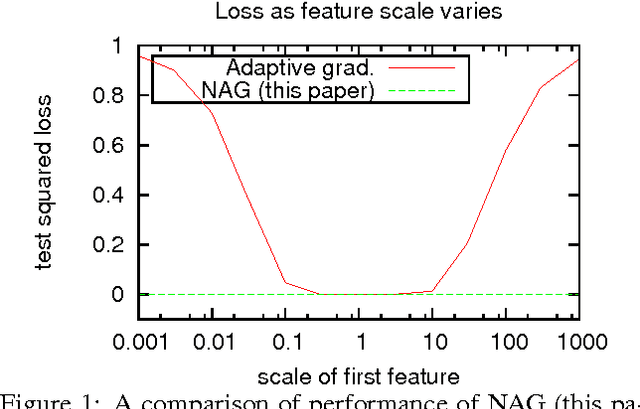
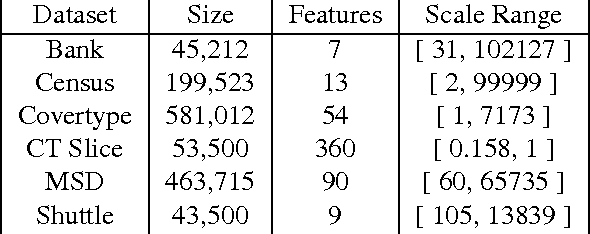
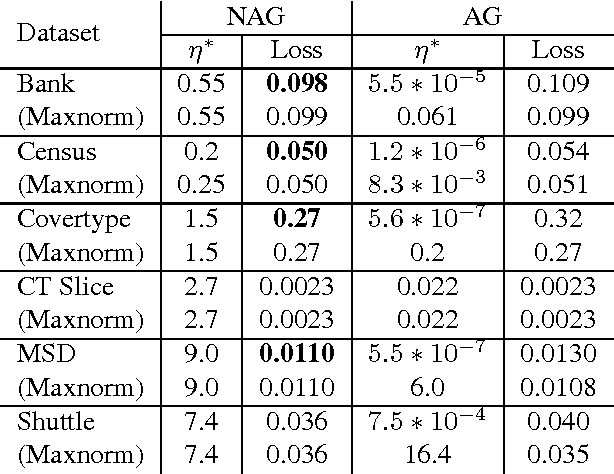
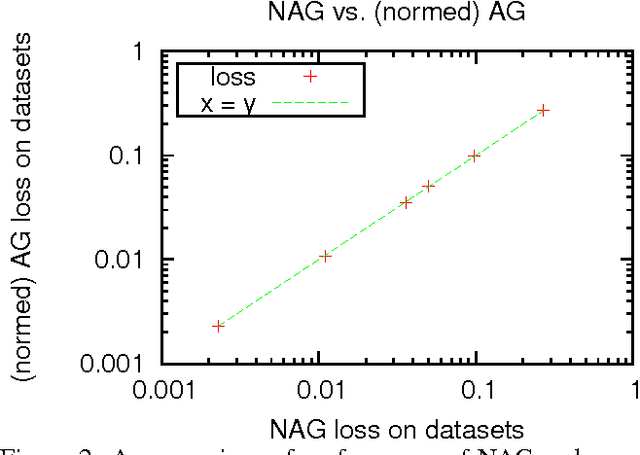
We introduce online learning algorithms which are independent of feature scales, proving regret bounds dependent on the ratio of scales existent in the data rather than the absolute scale. This has several useful effects: there is no need to pre-normalize data, the test-time and test-space complexity are reduced, and the algorithms are more robust.
Conditional Probability Tree Estimation Analysis and Algorithms
Aug 09, 2014We consider the problem of estimating the conditional probability of a label in time O(log n), where n is the number of possible labels. We analyze a natural reduction of this problem to a set of binary regression problems organized in a tree structure, proving a regret bound that scales with the depth of the tree. Motivated by this analysis, we propose the first online algorithm which provably constructs a logarithmic depth tree on the set of labels to solve this problem. We test the algorithm empirically, showing that it works succesfully on a dataset with roughly 106 labels.
Efficient Online Bootstrapping for Large Scale Learning
Dec 18, 2013
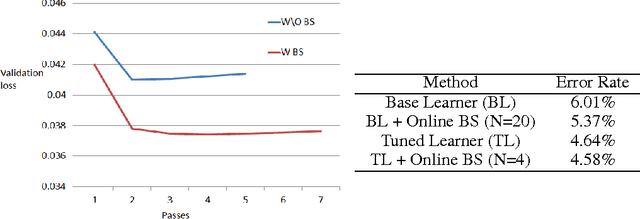
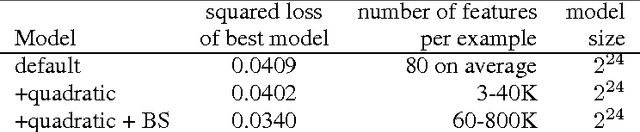
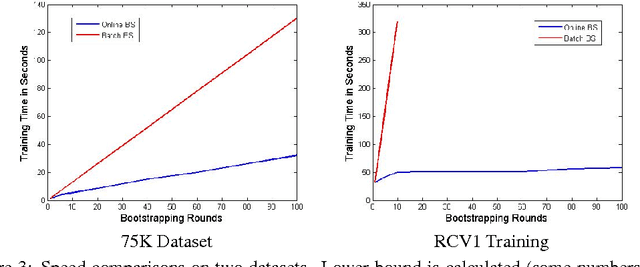
Bootstrapping is a useful technique for estimating the uncertainty of a predictor, for example, confidence intervals for prediction. It is typically used on small to moderate sized datasets, due to its high computation cost. This work describes a highly scalable online bootstrapping strategy, implemented inside Vowpal Wabbit, that is several times faster than traditional strategies. Our experiments indicate that, in addition to providing a black box-like method for estimating uncertainty, our implementation of online bootstrapping may also help to train models with better prediction performance due to model averaging.
Para-active learning
Oct 30, 2013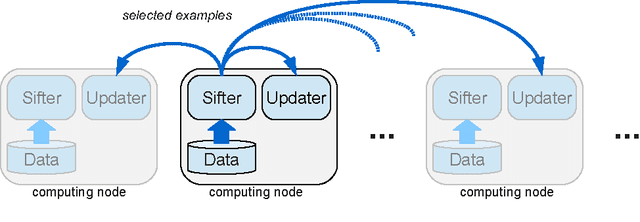

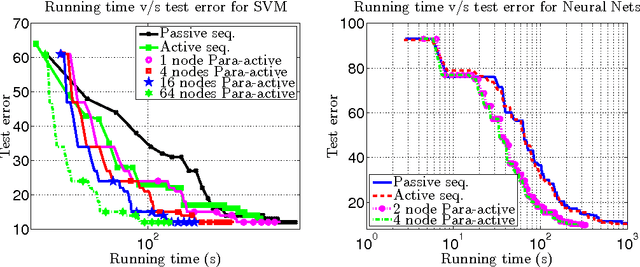
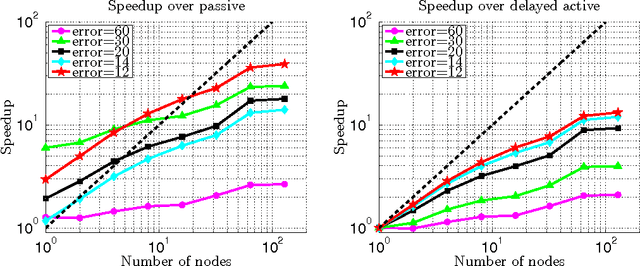
Training examples are not all equally informative. Active learning strategies leverage this observation in order to massively reduce the number of examples that need to be labeled. We leverage the same observation to build a generic strategy for parallelizing learning algorithms. This strategy is effective because the search for informative examples is highly parallelizable and because we show that its performance does not deteriorate when the sifting process relies on a slightly outdated model. Parallel active learning is particularly attractive to train nonlinear models with non-linear representations because there are few practical parallel learning algorithms for such models. We report preliminary experiments using both kernel SVMs and SGD-trained neural networks.
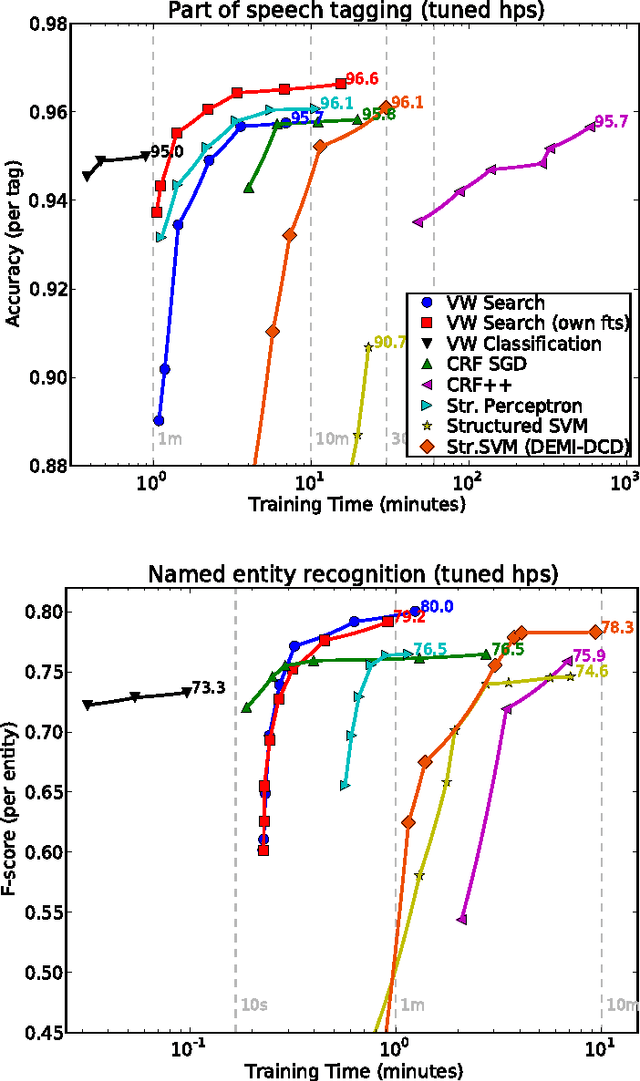
A Reliable Effective Terascale Linear Learning System
Jul 12, 2013We present a system and a set of techniques for learning linear predictors with convex losses on terascale datasets, with trillions of features, {The number of features here refers to the number of non-zero entries in the data matrix.} billions of training examples and millions of parameters in an hour using a cluster of 1000 machines. Individually none of the component techniques are new, but the careful synthesis required to obtain an efficient implementation is. The result is, up to our knowledge, the most scalable and efficient linear learning system reported in the literature (as of 2011 when our experiments were conducted). We describe and thoroughly evaluate the components of the system, showing the importance of the various design choices.
Sample-efficient Nonstationary Policy Evaluation for Contextual Bandits
Oct 16, 2012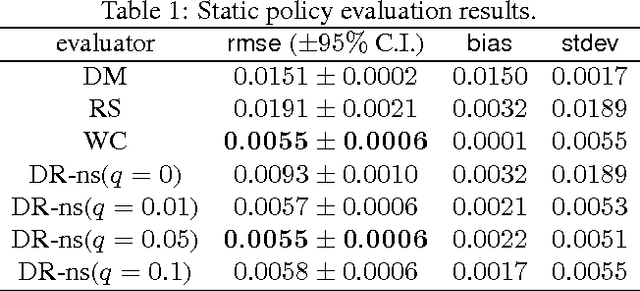
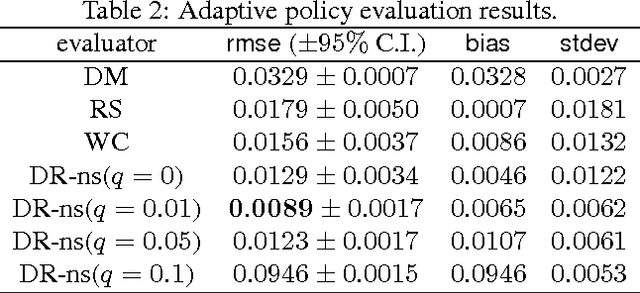
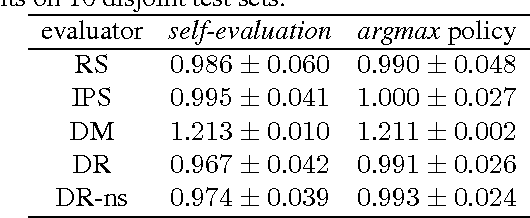
We present and prove properties of a new offline policy evaluator for an exploration learning setting which is superior to previous evaluators. In particular, it simultaneously and correctly incorporates techniques from importance weighting, doubly robust evaluation, and nonstationary policy evaluation approaches. In addition, our approach allows generating longer histories by careful control of a bias-variance tradeoff, and further decreases variance by incorporating information about randomness of the target policy. Empirical evidence from synthetic and realworld exploration learning problems shows the new evaluator successfully unifies previous approaches and uses information an order of magnitude more efficiently.
Proceedings of the 29th International Conference on Machine Learning (ICML-12)
Sep 16, 2012This is an index to the papers that appear in the Proceedings of the 29th International Conference on Machine Learning (ICML-12). The conference was held in Edinburgh, Scotland, June 27th - July 3rd, 2012.