 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Available Corpora for Building Data-Driven Dialogue Systems
Mar 21, 2017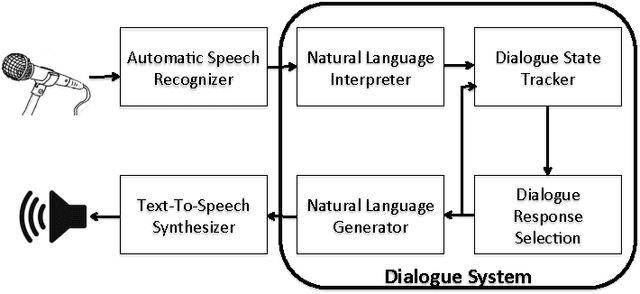
During the past decade, several areas of speech and language understanding have witnessed substantial breakthroughs from the use of data-driven models. In the area of dialogue systems, the trend is less obvious, and most practical systems are still built through significant engineering and expert knowledge. Nevertheless, several recent results suggest that data-driven approaches are feasible and quite promising. To facilitate research in this area, we have carried out a wide survey of publicly available datasets suitable for data-driven learning of dialogue systems. We discuss important characteristics of these datasets, how they can be used to learn diverse dialogue strategies, and their other potential uses. We also examine methods for transfer learning between datasets and the use of external knowledge. Finally, we discuss appropriate choice of evaluation metrics for the learning objective.
An Actor-Critic Algorithm for Sequence Prediction
Mar 03, 2017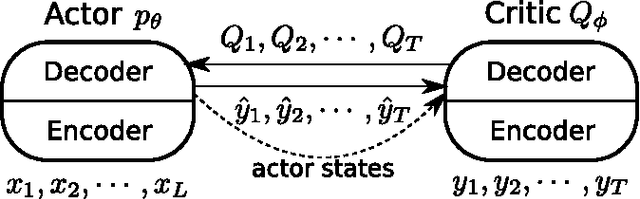
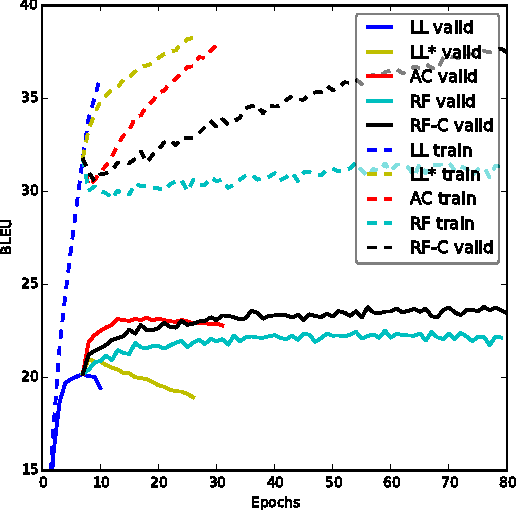
We present an approach to training neural networks to generate sequences using actor-critic methods from reinforcement learning (RL). Current log-likelihood training methods are limited by the discrepancy between their training and testing modes, as models must generate tokens conditioned on their previous guesses rather than the ground-truth tokens. We address this problem by introducing a \textit{critic} network that is trained to predict the value of an output token, given the policy of an \textit{actor} network. This results in a training procedure that is much closer to the test phase, and allows us to directly optimize for a task-specific score such as BLEU. Crucially, since we leverage these techniques in the supervised learning setting rather than the traditional RL setting, we condition the critic network on the ground-truth output. We show that our method leads to improved performance on both a synthetic task, and for German-English machine translation. Our analysis paves the way for such methods to be applied in natural language generation tasks, such as machine translation, caption generation, and dialogue modelling.
How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation
Jan 03, 2017
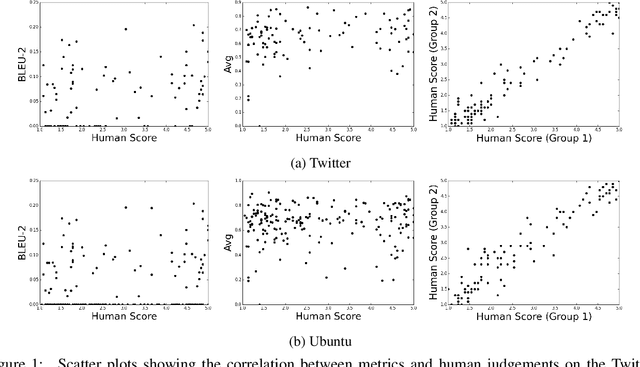
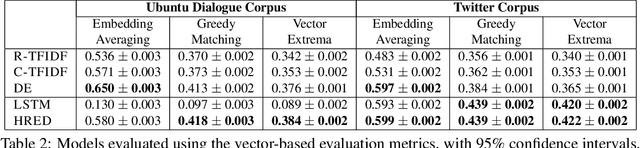

We investigate evaluation metrics for dialogue response generation systems where supervised labels, such as task completion, are not available. Recent works in response generation have adopted metrics from machine translation to compare a model's generated response to a single target response. We show that these metrics correlate very weakly with human judgements in the non-technical Twitter domain, and not at all in the technical Ubuntu domain. We provide quantitative and qualitative results highlighting specific weaknesses in existing metrics, and provide recommendations for future development of better automatic evaluation metrics for dialogue systems.
Generative Deep Neural Networks for Dialogue: A Short Review
Nov 18, 2016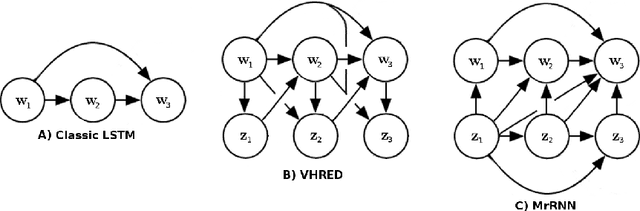


Researchers have recently started investigating deep neural networks for dialogue applications. In particular, generative sequence-to-sequence (Seq2Seq) models have shown promising results for unstructured tasks, such as word-level dialogue response generation. The hope is that such models will be able to leverage massive amounts of data to learn meaningful natural language representations and response generation strategies, while requiring a minimum amount of domain knowledge and hand-crafting. An important challenge is to develop models that can effectively incorporate dialogue context and generate meaningful and diverse responses. In support of this goal, we review recently proposed models based on generative encoder-decoder neural network architectures, and show that these models have better ability to incorporate long-term dialogue history, to model uncertainty and ambiguity in dialogue, and to generate responses with high-level compositional structure.
Bayesian Reinforcement Learning: A Survey
Sep 14, 2016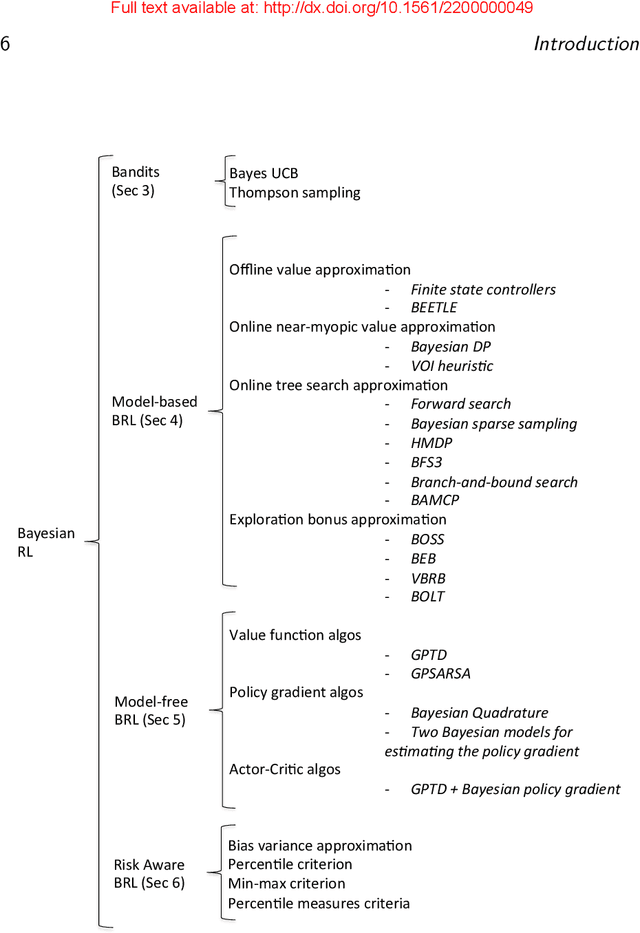
Bayesian methods for machine learning have been widely investigated, yielding principled methods for incorporating prior information into inference algorithms. In this survey, we provide an in-depth review of the role of Bayesian methods for the reinforcement learning (RL) paradigm. The major incentives for incorporating Bayesian reasoning in RL are: 1) it provides an elegant approach to action-selection (exploration/exploitation) as a function of the uncertainty in learning; and 2) it provides a machinery to incorporate prior knowledge into the algorithms. We first discuss models and methods for Bayesian inference in the simple single-step Bandit model. We then review the extensive recent literature on Bayesian methods for model-based RL, where prior information can be expressed on the parameters of the Markov model. We also present Bayesian methods for model-free RL, where priors are expressed over the value function or policy class. The objective of the paper is to provide a comprehensive survey on Bayesian RL algorithms and their theoretical and empirical properties.
Learning Robust Features using Deep Learning for Automatic Seizure Detection
Jul 31, 2016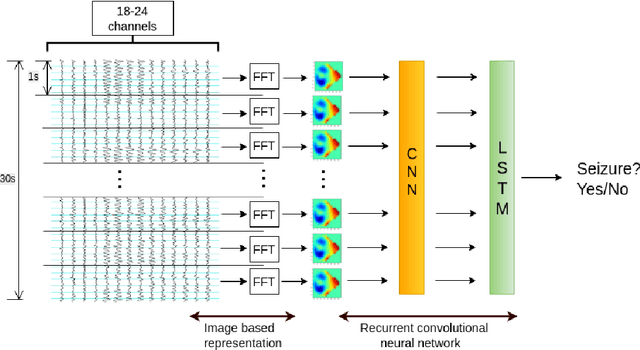
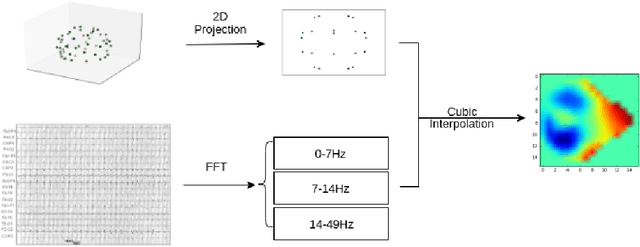
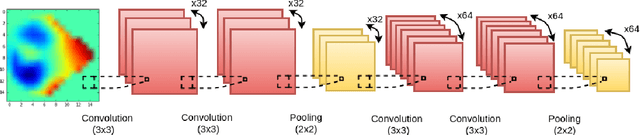
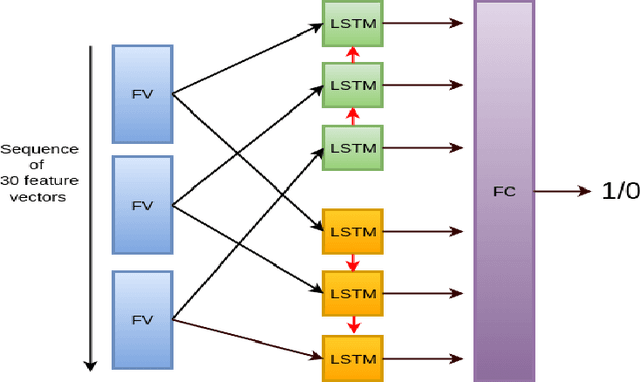
We present and evaluate the capacity of a deep neural network to learn robust features from EEG to automatically detect seizures. This is a challenging problem because seizure manifestations on EEG are extremely variable both inter- and intra-patient. By simultaneously capturing spectral, temporal and spatial information our recurrent convolutional neural network learns a general spatially invariant representation of a seizure. The proposed approach exceeds significantly previous results obtained on cross-patient classifiers both in terms of sensitivity and false positive rate. Furthermore, our model proves to be robust to missing channel and variable electrode montage.
On the Evaluation of Dialogue Systems with Next Utterance Classification
Jul 23, 2016
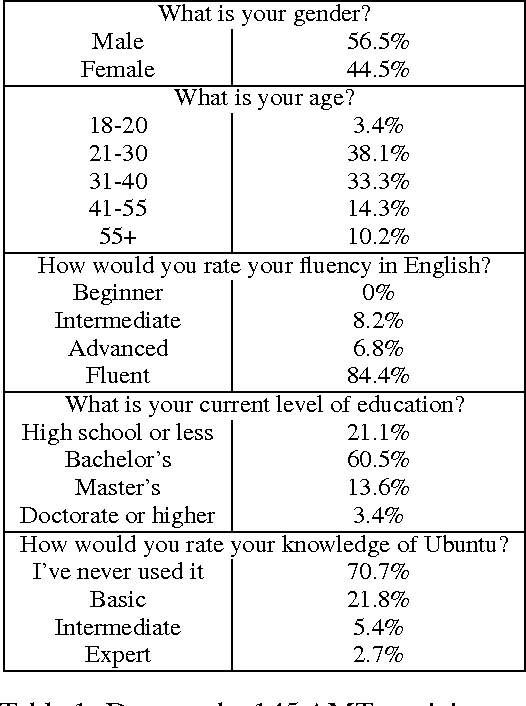

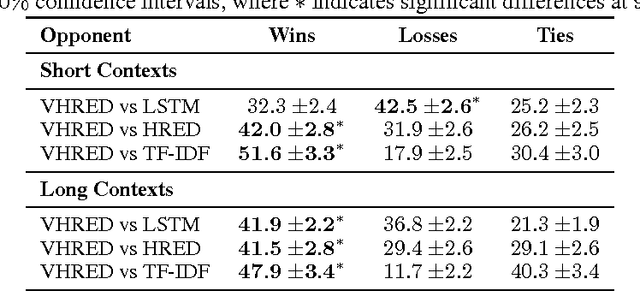
An open challenge in constructing dialogue systems is developing methods for automatically learning dialogue strategies from large amounts of unlabelled data. Recent work has proposed Next-Utterance-Classification (NUC) as a surrogate task for building dialogue systems from text data. In this paper we investigate the performance of humans on this task to validate the relevance of NUC as a method of evaluation. Our results show three main findings: (1) humans are able to correctly classify responses at a rate much better than chance, thus confirming that the task is feasible, (2) human performance levels vary across task domains (we consider 3 datasets) and expertise levels (novice vs experts), thus showing that a range of performance is possible on this type of task, (3) automated dialogue systems built using state-of-the-art machine learning methods have similar performance to the human novices, but worse than the experts, thus confirming the utility of this class of tasks for driving further research in automated dialogue systems.
A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues
Jun 14, 2016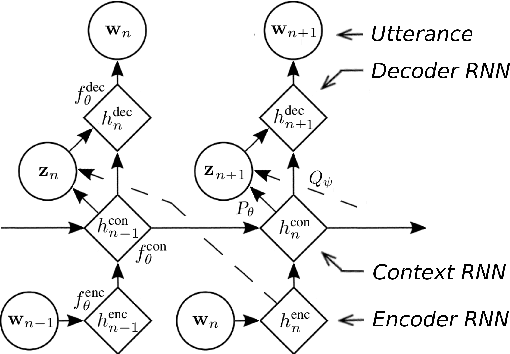
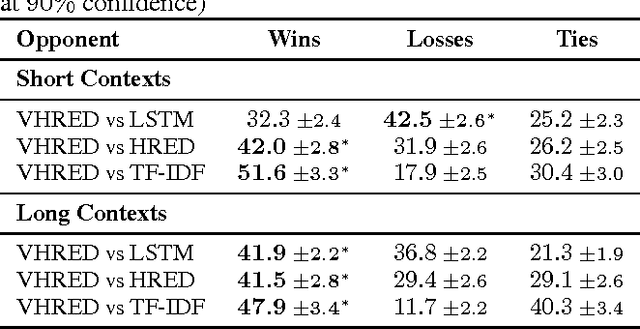

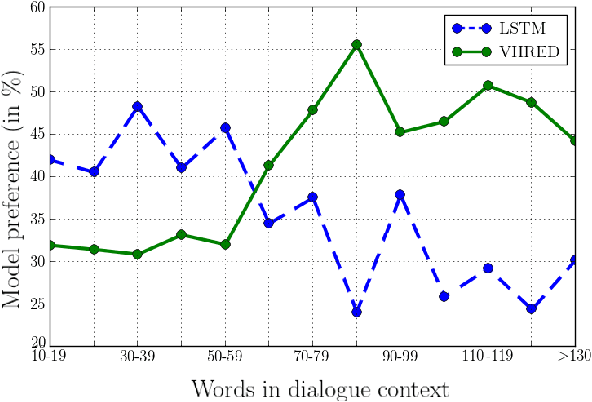
Sequential data often possesses a hierarchical structure with complex dependencies between subsequences, such as found between the utterances in a dialogue. In an effort to model this kind of generative process, we propose a neural network-based generative architecture, with latent stochastic variables that span a variable number of time steps. We apply the proposed model to the task of dialogue response generation and compare it with recent neural network architectures. We evaluate the model performance through automatic evaluation metrics and by carrying out a human evaluation. The experiments demonstrate that our model improves upon recently proposed models and that the latent variables facilitate the generation of long outputs and maintain the context.
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models
Apr 06, 2016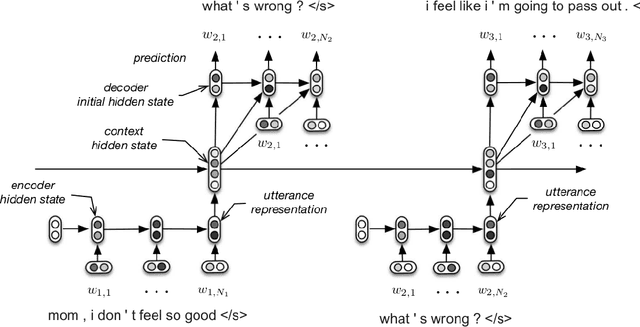

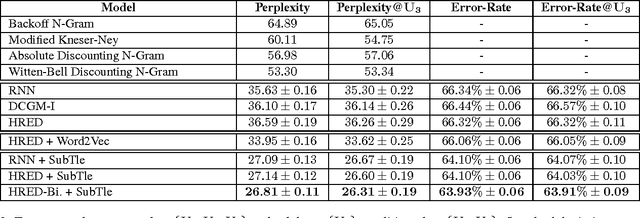

We investigate the task of building open domain, conversational dialogue systems based on large dialogue corpora using generative models. Generative models produce system responses that are autonomously generated word-by-word, opening up the possibility for realistic, flexible interactions. In support of this goal, we extend the recently proposed hierarchical recurrent encoder-decoder neural network to the dialogue domain, and demonstrate that this model is competitive with state-of-the-art neural language models and back-off n-gram models. We investigate the limitations of this and similar approaches, and show how its performance can be improved by bootstrapping the learning from a larger question-answer pair corpus and from pretrained word embeddings.
The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems
Feb 04, 2016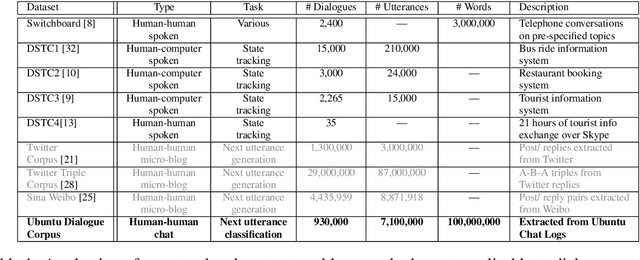
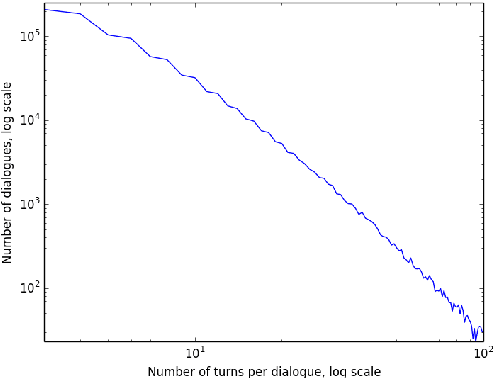
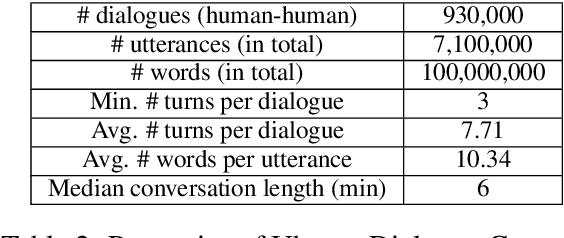
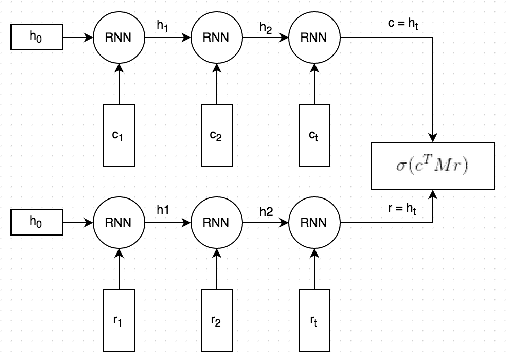
This paper introduces the Ubuntu Dialogue Corpus, a dataset containing almost 1 million multi-turn dialogues, with a total of over 7 million utterances and 100 million words. This provides a unique resource for research into building dialogue managers based on neural language models that can make use of large amounts of unlabeled data. The dataset has both the multi-turn property of conversations in the Dialog State Tracking Challenge datasets, and the unstructured nature of interactions from microblog services such as Twitter. We also describe two neural learning architectures suitable for analyzing this dataset, and provide benchmark performance on the task of selecting the best next response.