 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Single-Index Models with Shallow Neural Networks
Oct 27, 2022

Single-index models are a class of functions given by an unknown univariate ``link'' function applied to an unknown one-dimensional projection of the input. These models are particularly relevant in high dimension, when the data might present low-dimensional structure that learning algorithms should adapt to. While several statistical aspects of this model, such as the sample complexity of recovering the relevant (one-dimensional) subspace, are well-understood, they rely on tailored algorithms that exploit the specific structure of the target function. In this work, we introduce a natural class of shallow neural networks and study its ability to learn single-index models via gradient flow. More precisely, we consider shallow networks in which biases of the neurons are frozen at random initialization. We show that the corresponding optimization landscape is benign, which in turn leads to generalization guarantees that match the near-optimal sample complexity of dedicated semi-parametric methods.
Towards Antisymmetric Neural Ansatz Separation
Aug 05, 2022


We study separations between two fundamental models (or \emph{Ans\"atze}) of antisymmetric functions, that is, functions $f$ of the form $f(x_{\sigma(1)}, \ldots, x_{\sigma(N)}) = \text{sign}(\sigma)f(x_1, \ldots, x_N)$, where $\sigma$ is any permutation. These arise in the context of quantum chemistry, and are the basic modeling tool for wavefunctions of Fermionic systems. Specifically, we consider two popular antisymmetric Ans\"atze: the Slater representation, which leverages the alternating structure of determinants, and the Jastrow ansatz, which augments Slater determinants with a product by an arbitrary symmetric function. We construct an antisymmetric function that can be more efficiently expressed in Jastrow form, yet provably cannot be approximated by Slater determinants unless there are exponentially (in $N^2$) many terms. This represents the first explicit quantitative separation between these two Ans\"atze.
On Non-Linear operators for Geometric Deep Learning
Jul 06, 2022This work studies operators mapping vector and scalar fields defined over a manifold $\mathcal{M}$, and which commute with its group of diffeomorphisms $\text{Diff}(\mathcal{M})$. We prove that in the case of scalar fields $L^p_\omega(\mathcal{M,\mathbb{R}})$, those operators correspond to point-wise non-linearities, recovering and extending known results on $\mathbb{R}^d$. In the context of Neural Networks defined over $\mathcal{M}$, it indicates that point-wise non-linear operators are the only universal family that commutes with any group of symmetries, and justifies their systematic use in combination with dedicated linear operators commuting with specific symmetries. In the case of vector fields $L^p_\omega(\mathcal{M},T\mathcal{M})$, we show that those operators are solely the scalar multiplication. It indicates that $\text{Diff}(\mathcal{M})$ is too rich and that there is no universal class of non-linear operators to motivate the design of Neural Networks over the symmetries of $\mathcal{M}$.
On Gradient Descent Convergence beyond the Edge of Stability
Jun 08, 2022
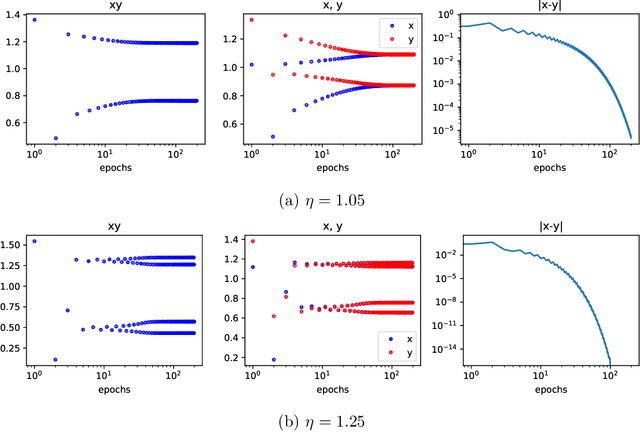
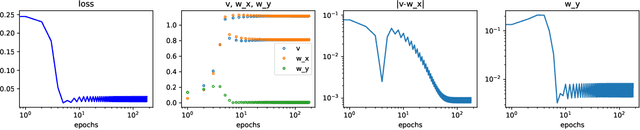
Gradient Descent (GD) is a powerful workhorse of modern machine learning thanks to its scalability and efficiency in high-dimensional spaces. Its ability to find local minimisers is only guaranteed for losses with Lipschitz gradients, where it can be seen as a 'bona-fide' discretisation of an underlying gradient flow. Yet, many ML setups involving overparametrised models do not fall into this problem class, which has motivated research beyond the so-called "Edge of Stability", where the step-size crosses the admissibility threshold inversely proportional to the Lipschitz constant above. Perhaps surprisingly, GD has been empirically observed to still converge regardless of local instability. In this work, we study a local condition for such an unstable convergence around a local minima in a low dimensional setting. We then leverage these insights to establish global convergence of a two-layer single-neuron ReLU student network aligning with the teacher neuron in a large learning rate beyond the Edge of Stability under population loss. Meanwhile, while the difference of norms of the two layers is preserved by gradient flow, we show that GD above the edge of stability induces a balancing effect, leading to the same norms across the layers.
Exponential Separations in Symmetric Neural Networks
Jun 02, 2022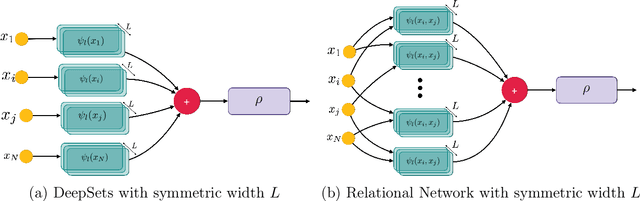
In this work we demonstrate a novel separation between symmetric neural network architectures. Specifically, we consider the Relational Network~\parencite{santoro2017simple} architecture as a natural generalization of the DeepSets~\parencite{zaheer2017deep} architecture, and study their representational gap. Under the restriction to analytic activation functions, we construct a symmetric function acting on sets of size $N$ with elements in dimension $D$, which can be efficiently approximated by the former architecture, but provably requires width exponential in $N$ and $D$ for the latter.
When does return-conditioned supervised learning work for offline reinforcement learning?
Jun 02, 2022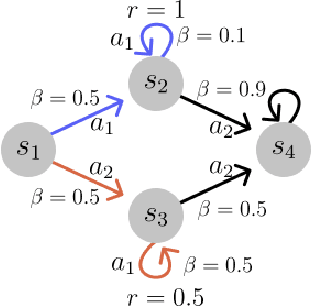
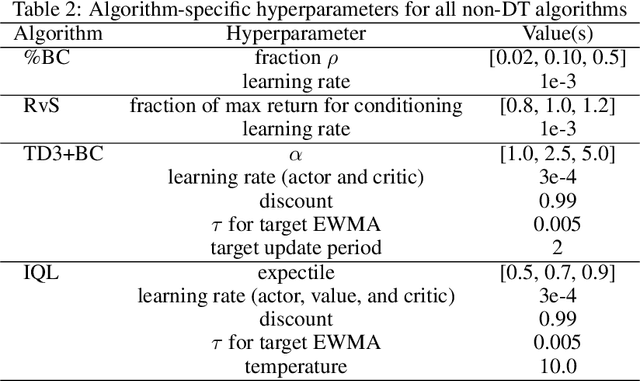
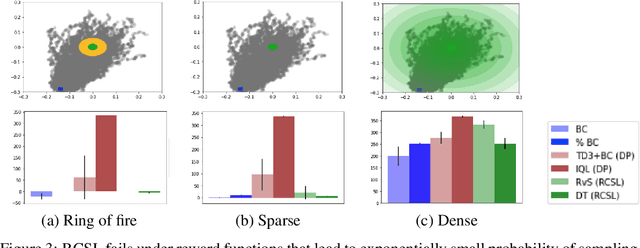
Several recent works have proposed a class of algorithms for the offline reinforcement learning (RL) problem that we will refer to as return-conditioned supervised learning (RCSL). RCSL algorithms learn the distribution of actions conditioned on both the state and the return of the trajectory. Then they define a policy by conditioning on achieving high return. In this paper, we provide a rigorous study of the capabilities and limitations of RCSL, something which is crucially missing in previous work. We find that RCSL returns the optimal policy under a set of assumptions that are stronger than those needed for the more traditional dynamic programming-based algorithms. We provide specific examples of MDPs and datasets that illustrate the necessity of these assumptions and the limits of RCSL. Finally, we present empirical evidence that these limitations will also cause issues in practice by providing illustrative experiments in simple point-mass environments and on datasets from the D4RL benchmark.
On Feature Learning in Neural Networks with Global Convergence Guarantees
Apr 22, 2022
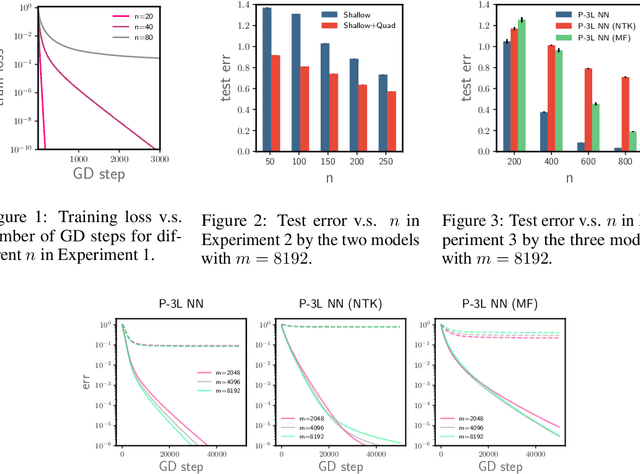
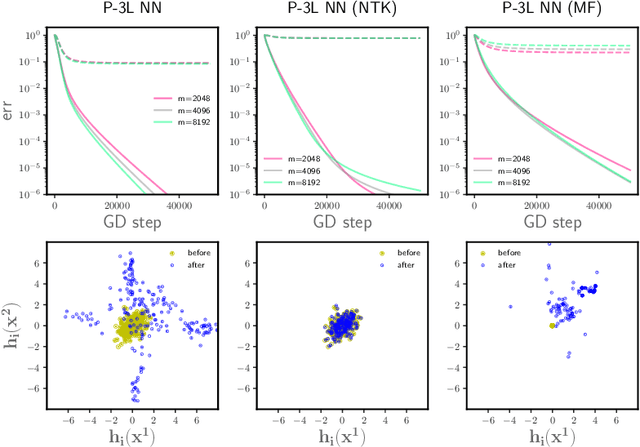
We study the optimization of wide neural networks (NNs) via gradient flow (GF) in setups that allow feature learning while admitting non-asymptotic global convergence guarantees. First, for wide shallow NNs under the mean-field scaling and with a general class of activation functions, we prove that when the input dimension is no less than the size of the training set, the training loss converges to zero at a linear rate under GF. Building upon this analysis, we study a model of wide multi-layer NNs whose second-to-last layer is trained via GF, for which we also prove a linear-rate convergence of the training loss to zero, but regardless of the input dimension. We also show empirically that, unlike in the Neural Tangent Kernel (NTK) regime, our multi-layer model exhibits feature learning and can achieve better generalization performance than its NTK counterpart.
Neural Galerkin Scheme with Active Learning for High-Dimensional Evolution Equations
Mar 02, 2022


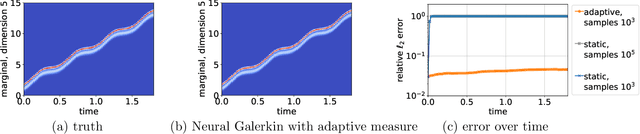
Machine learning methods have been shown to give accurate predictions in high dimensions provided that sufficient training data are available. Yet, many interesting questions in science and engineering involve situations where initially no data are available and the principal aim is to gather insights from a known model. Here we consider this problem in the context of systems whose evolution can be described by partial differential equations (PDEs). We use deep learning to solve these equations by generating data on-the-fly when and where they are needed, without prior information about the solution. The proposed Neural Galerkin schemes derive nonlinear dynamical equations for the network weights by minimization of the residual of the time derivative of the solution, and solve these equations using standard integrators for initial value problems. The sequential learning of the weights over time allows for adaptive collection of new input data for residual estimation. This step uses importance sampling informed by the current state of the solution, in contrast with other machine learning methods for PDEs that optimize the network parameters globally in time. This active form of data acquisition is essential to enable the approximation power of the neural networks and to break the curse of dimensionality faced by non-adaptative learning strategies. The applicability of the method is illustrated on several numerical examples involving high-dimensional PDEs, including advection equations with many variables, as well as Fokker-Planck equations for systems with several interacting particles.
Simultaneous Transport Evolution for Minimax Equilibria on Measures
Feb 21, 2022Min-max optimization problems arise in several key machine learning setups, including adversarial learning and generative modeling. In their general form, in absence of convexity/concavity assumptions, finding pure equilibria of the underlying two-player zero-sum game is computationally hard [Daskalakis et al., 2021]. In this work we focus instead in finding mixed equilibria, and consider the associated lifted problem in the space of probability measures. By adding entropic regularization, our main result establishes global convergence towards the global equilibrium by using simultaneous gradient ascent-descent with respect to the Wasserstein metric -- a dynamics that admits efficient particle discretization in high-dimensions, as opposed to entropic mirror descent. We complement this positive result with a related entropy-regularized loss which is not bilinear but still convex-concave in the Wasserstein geometry, and for which simultaneous dynamics do not converge yet timescale separation does. Taken together, these results showcase the benign geometry of bilinear games in the space of measures, enabling particle dynamics with global qualitative convergence guarantees.
Extended Unconstrained Features Model for Exploring Deep Neural Collapse
Feb 16, 2022



The modern strategy for training deep neural networks for classification tasks includes optimizing the network's weights even after the training error vanishes to further push the training loss toward zero. Recently, a phenomenon termed "neural collapse" (NC) has been empirically observed in this training procedure. Specifically, it has been shown that the learned features (the output of the penultimate layer) of within-class samples converge to their mean, and the means of different classes exhibit a certain tight frame structure, which is also aligned with the last layer's weights. Recent papers have shown that minimizers with this structure emerge when optimizing a simplified "unconstrained features model" (UFM) with a regularized cross-entropy loss. In this paper, we further analyze and extend the UFM. First, we study the UFM for the regularized MSE loss, and show that the minimizers' features can be more structured than in the cross-entropy case. This affects also the structure of the weights. Then, we extend the UFM by adding another layer of weights as well as ReLU nonlinearity to the model and generalize our previous results. Finally, we empirically demonstrate the usefulness of our nonlinear extended UFM in modeling the NC phenomenon that occurs with practical networks.