 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Source Separation with Discriminative Scattering Networks
Apr 28, 2015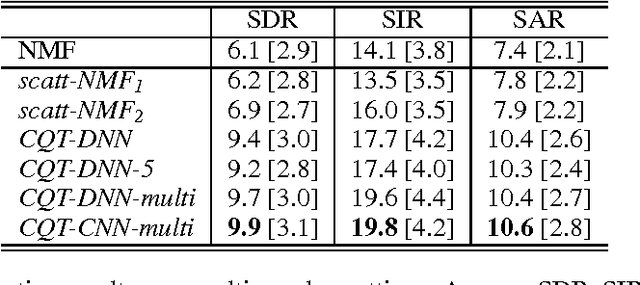
In this report we describe an ongoing line of research for solving single-channel source separation problems. Many monaural signal decomposition techniques proposed in the literature operate on a feature space consisting of a time-frequency representation of the input data. A challenge faced by these approaches is to effectively exploit the temporal dependencies of the signals at scales larger than the duration of a time-frame. In this work we propose to tackle this problem by modeling the signals using a time-frequency representation with multiple temporal resolutions. The proposed representation consists of a pyramid of wavelet scattering operators, which generalizes Constant Q Transforms (CQT) with extra layers of convolution and complex modulus. We first show that learning standard models with this multi-resolution setting improves source separation results over fixed-resolution methods. As study case, we use Non-Negative Matrix Factorizations (NMF) that has been widely considered in many audio application. Then, we investigate the inclusion of the proposed multi-resolution setting into a discriminative training regime. We discuss several alternatives using different deep neural network architectures.
Unsupervised Feature Learning from Temporal Data
Apr 15, 2015

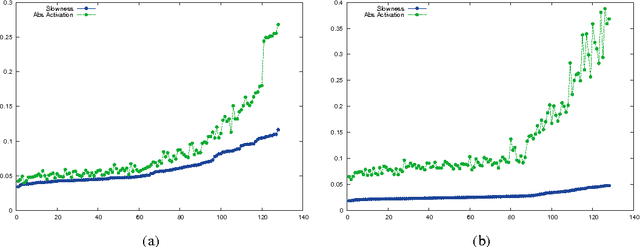

Current state-of-the-art classification and detection algorithms rely on supervised training. In this work we study unsupervised feature learning in the context of temporally coherent video data. We focus on feature learning from unlabeled video data, using the assumption that adjacent video frames contain semantically similar information. This assumption is exploited to train a convolutional pooling auto-encoder regularized by slowness and sparsity. We establish a connection between slow feature learning to metric learning and show that the trained encoder can be used to define a more temporally and semantically coherent metric.
Training Convolutional Networks with Noisy Labels
Apr 10, 2015

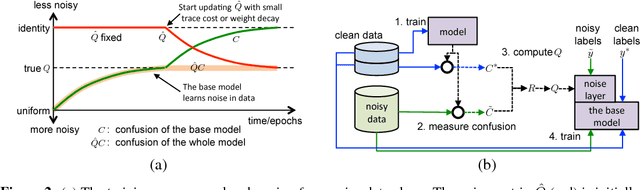
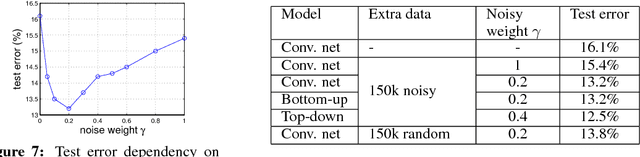
The availability of large labeled datasets has allowed Convolutional Network models to achieve impressive recognition results. However, in many settings manual annotation of the data is impractical; instead our data has noisy labels, i.e. there is some freely available label for each image which may or may not be accurate. In this paper, we explore the performance of discriminatively-trained Convnets when trained on such noisy data. We introduce an extra noise layer into the network which adapts the network outputs to match the noisy label distribution. The parameters of this noise layer can be estimated as part of the training process and involve simple modifications to current training infrastructures for deep networks. We demonstrate the approaches on several datasets, including large scale experiments on the ImageNet classification benchmark.
Blind Deconvolution with Non-local Sparsity Reweighting
Jun 16, 2014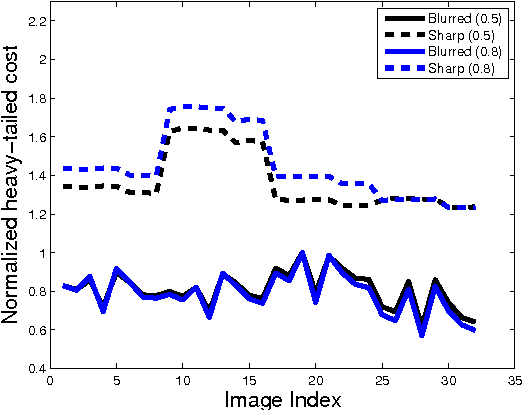
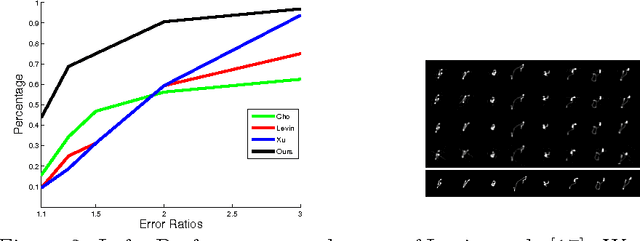


Blind deconvolution has made significant progress in the past decade. Most successful algorithms are classified either as Variational or Maximum a-Posteriori ($MAP$). In spite of the superior theoretical justification of variational techniques, carefully constructed $MAP$ algorithms have proven equally effective in practice. In this paper, we show that all successful $MAP$ and variational algorithms share a common framework, relying on the following key principles: sparsity promotion in the gradient domain, $l_2$ regularization for kernel estimation, and the use of convex (often quadratic) cost functions. Our observations lead to a unified understanding of the principles required for successful blind deconvolution. We incorporate these principles into a novel algorithm that improves significantly upon the state of the art.
Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation
Jun 09, 2014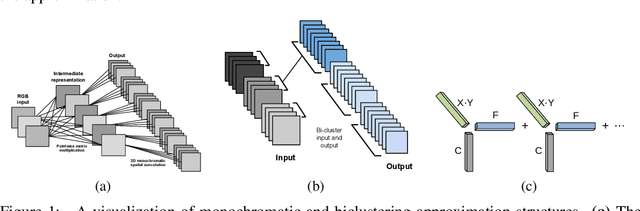

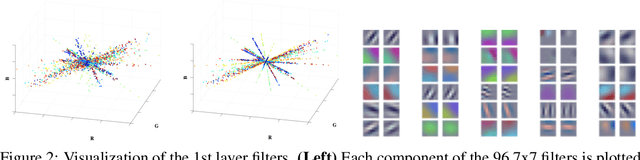
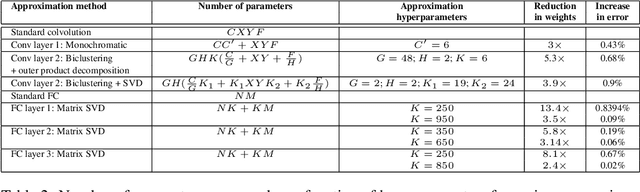
We present techniques for speeding up the test-time evaluation of large convolutional networks, designed for object recognition tasks. These models deliver impressive accuracy but each image evaluation requires millions of floating point operations, making their deployment on smartphones and Internet-scale clusters problematic. The computation is dominated by the convolution operations in the lower layers of the model. We exploit the linear structure present within the convolutional filters to derive approximations that significantly reduce the required computation. Using large state-of-the-art models, we demonstrate we demonstrate speedups of convolutional layers on both CPU and GPU by a factor of 2x, while keeping the accuracy within 1% of the original model.
Spectral Networks and Locally Connected Networks on Graphs
May 21, 2014

Convolutional Neural Networks are extremely efficient architectures in image and audio recognition tasks, thanks to their ability to exploit the local translational invariance of signal classes over their domain. In this paper we consider possible generalizations of CNNs to signals defined on more general domains without the action of a translation group. In particular, we propose two constructions, one based upon a hierarchical clustering of the domain, and another based on the spectrum of the graph Laplacian. We show through experiments that for low-dimensional graphs it is possible to learn convolutional layers with a number of parameters independent of the input size, resulting in efficient deep architectures.
Signal Recovery from Pooling Representations
Feb 27, 2014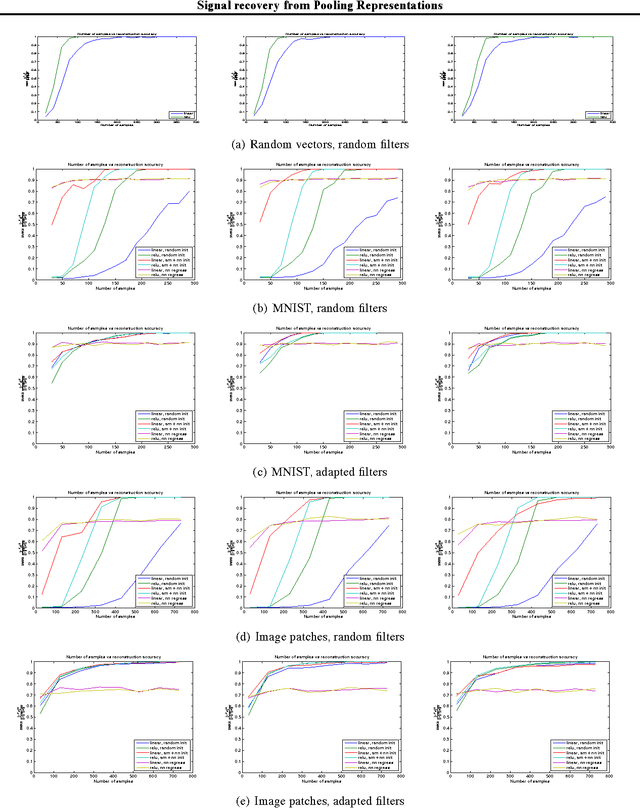
In this work we compute lower Lipschitz bounds of $\ell_p$ pooling operators for $p=1, 2, \infty$ as well as $\ell_p$ pooling operators preceded by half-rectification layers. These give sufficient conditions for the design of invertible neural network layers. Numerical experiments on MNIST and image patches confirm that pooling layers can be inverted with phase recovery algorithms. Moreover, the regularity of the inverse pooling, controlled by the lower Lipschitz constant, is empirically verified with a nearest neighbor regression.
Intriguing properties of neural networks
Feb 19, 2014

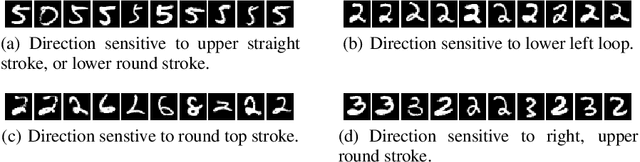
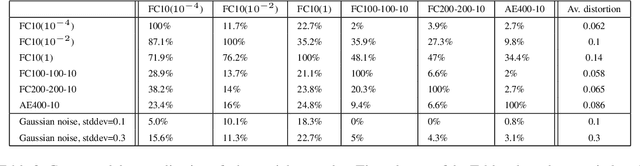
Deep neural networks are highly expressive models that have recently achieved state of the art performance on speech and visual recognition tasks. While their expressiveness is the reason they succeed, it also causes them to learn uninterpretable solutions that could have counter-intuitive properties. In this paper we report two such properties. First, we find that there is no distinction between individual high level units and random linear combinations of high level units, according to various methods of unit analysis. It suggests that it is the space, rather than the individual units, that contains of the semantic information in the high layers of neural networks. Second, we find that deep neural networks learn input-output mappings that are fairly discontinuous to a significant extend. We can cause the network to misclassify an image by applying a certain imperceptible perturbation, which is found by maximizing the network's prediction error. In addition, the specific nature of these perturbations is not a random artifact of learning: the same perturbation can cause a different network, that was trained on a different subset of the dataset, to misclassify the same input.
Classification with Scattering Operators
Nov 20, 2013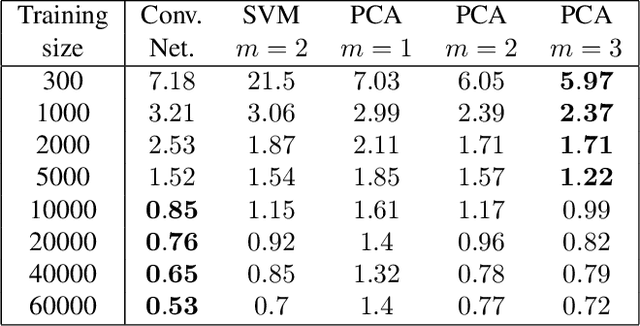
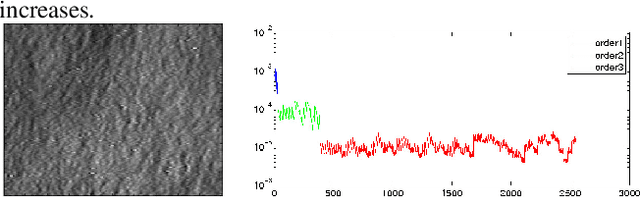


A scattering vector is a local descriptor including multiscale and multi-direction co-occurrence information. It is computed with a cascade of wavelet decompositions and complex modulus. This scattering representation is locally translation invariant and linearizes deformations. A supervised classification algorithm is computed with a PCA model selection on scattering vectors. State of the art results are obtained for handwritten digit recognition and texture classification.
Learning Stable Group Invariant Representations with Convolutional Networks
Jan 16, 2013Transformation groups, such as translations or rotations, effectively express part of the variability observed in many recognition problems. The group structure enables the construction of invariant signal representations with appealing mathematical properties, where convolutions, together with pooling operators, bring stability to additive and geometric perturbations of the input. Whereas physical transformation groups are ubiquitous in image and audio applications, they do not account for all the variability of complex signal classes. We show that the invariance properties built by deep convolutional networks can be cast as a form of stable group invariance. The network wiring architecture determines the invariance group, while the trainable filter coefficients characterize the group action. We give explanatory examples which illustrate how the network architecture controls the resulting invariance group. We also explore the principle by which additional convolutional layers induce a group factorization enabling more abstract, powerful invariant representations.