 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Reward Functions from Diffusion Models
Jun 01, 2023Diffusion models have achieved remarkable results in image generation, and have similarly been used to learn high-performing policies in sequential decision-making tasks. Decision-making diffusion models can be trained on lower-quality data, and then be steered with a reward function to generate near-optimal trajectories. We consider the problem of extracting a reward function by comparing a decision-making diffusion model that models low-reward behavior and one that models high-reward behavior; a setting related to inverse reinforcement learning. We first define the notion of a relative reward function of two diffusion models and show conditions under which it exists and is unique. We then devise a practical learning algorithm for extracting it by aligning the gradients of a reward function -- parametrized by a neural network -- to the difference in outputs of both diffusion models. Our method finds correct reward functions in navigation environments, and we demonstrate that steering the base model with the learned reward functions results in significantly increased performance in standard locomotion benchmarks. Finally, we demonstrate that our approach generalizes beyond sequential decision-making by learning a reward-like function from two large-scale image generation diffusion models. The extracted reward function successfully assigns lower rewards to harmful images.
Large Language Models are Few-shot Publication Scoopers
Apr 02, 2023Driven by recent advances AI, we passengers are entering a golden age of scientific discovery. But golden for whom? Confronting our insecurity that others may beat us to the most acclaimed breakthroughs of the era, we propose a novel solution to the long-standing personal credit assignment problem to ensure that it is golden for us. At the heart of our approach is a pip-to-the-post algorithm that assures adulatory Wikipedia pages without incurring the substantial capital and career risks of pursuing high impact science with conventional research methodologies. By leveraging the meta trend of leveraging large language models for everything, we demonstrate the unparalleled potential of our algorithm to scoop groundbreaking findings with the insouciance of a seasoned researcher at a dessert buffet.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023



To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Pixels Together Strong: Segmenting Unknown Regions Rejected by All
Nov 25, 2022Semantic segmentation methods typically perform per-pixel classification by assuming a fixed set of semantic categories. While they perform well on the known set, the network fails to learn the concept of objectness, which is necessary for identifying unknown objects. In this paper, we explore the potential of query-based mask classification for unknown object segmentation. We discover that object queries specialize in predicting a certain class and behave like one vs. all classifiers, allowing us to detect unknowns by finding regions that are ignored by all the queries. Based on a detailed analysis of the model's behavior, we propose a novel anomaly scoring function. We demonstrate that mask classification helps to preserve the objectness and the proposed scoring function eliminates irrelevant sources of uncertainty. Our method achieves consistent improvements in multiple benchmarks, even under high domain shift, without retraining or using outlier data. With modest supervision for outliers, we show that further improvements can be achieved without affecting the closed-set performance.
PVT3D: Point Voxel Transformers for Place Recognition from Sparse Lidar Scans
Nov 22, 2022Place recognition based on point cloud (LiDAR) scans is an important module for achieving robust autonomy in robots or self-driving vehicles. Training deep networks to match such scans presents a difficult trade-off: a higher spatial resolution of the network's intermediate representations is needed to perform fine-grained matching of subtle geometric features, but growing it too large makes the memory requirements infeasible. In this work, we propose a Point-Voxel Transformer network (PVT3D) that achieves robust fine-grained matching with low memory requirements. It leverages a sparse voxel branch to extract and aggregate information at a lower resolution and a point-wise branch to obtain fine-grained local information. A novel hierarchical cross-attention transformer (HCAT) uses queries from one branch to try to match structures in the other branch, ensuring that both extract self-contained descriptors of the point cloud (rather than one branch dominating), but using both to inform the output global descriptor of the point cloud. Extensive experiments show that the proposed PVT3D method surpasses the state-of-the-art by a large amount on several datasets (Oxford RobotCar, TUM, USyd). For instance, we achieve AR@1 of 85.6% on the TUM dataset, which surpasses the strongest prior model by ~15%.
Learn what matters: cross-domain imitation learning with task-relevant embeddings
Sep 24, 2022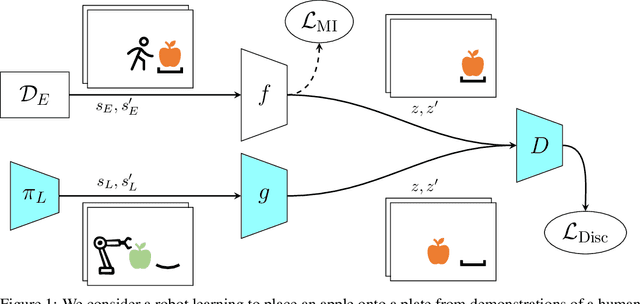

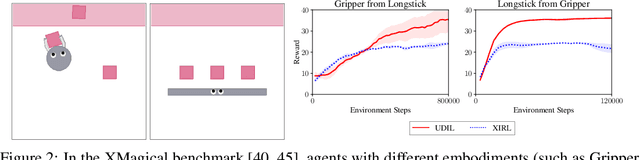
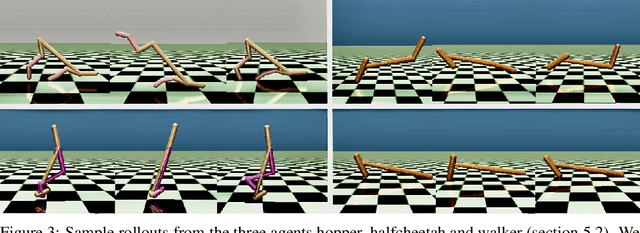
We study how an autonomous agent learns to perform a task from demonstrations in a different domain, such as a different environment or different agent. Such cross-domain imitation learning is required to, for example, train an artificial agent from demonstrations of a human expert. We propose a scalable framework that enables cross-domain imitation learning without access to additional demonstrations or further domain knowledge. We jointly train the learner agent's policy and learn a mapping between the learner and expert domains with adversarial training. We effect this by using a mutual information criterion to find an embedding of the expert's state space that contains task-relevant information and is invariant to domain specifics. This step significantly simplifies estimating the mapping between the learner and expert domains and hence facilitates end-to-end learning. We demonstrate successful transfer of policies between considerably different domains, without extra supervision such as additional demonstrations, and in situations where other methods fail.
Illusionary Attacks on Sequential Decision Makers and Countermeasures
Jul 20, 2022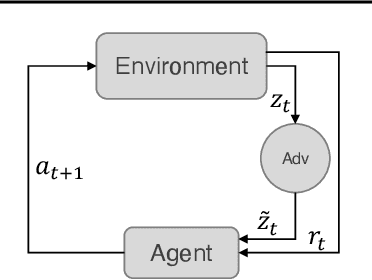
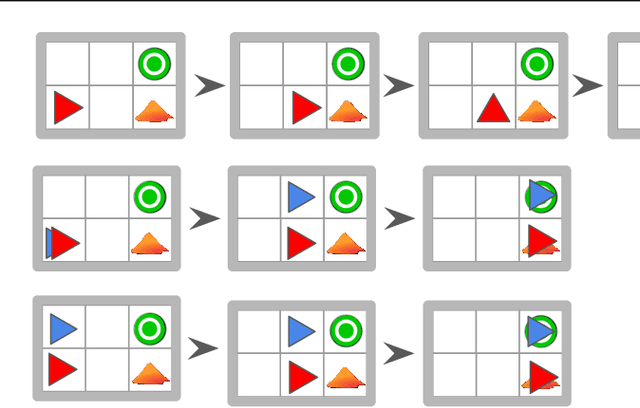
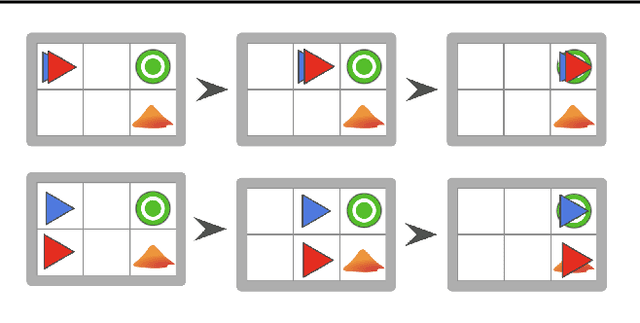
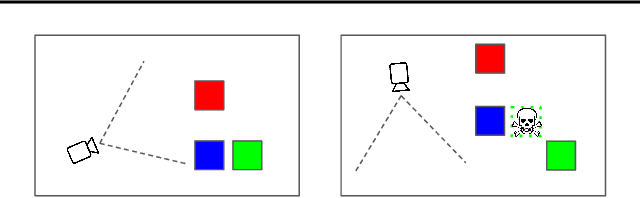
Autonomous intelligent agents deployed to the real-world need to be robust against adversarial attacks on sensory inputs. Existing work in reinforcement learning focuses on minimum-norm perturbation attacks, which were originally introduced to mimic a notion of perceptual invariance in computer vision. In this paper, we note that such minimum-norm perturbation attacks can be trivially detected by victim agents, as these result in observation sequences that are not consistent with the victim agent's actions. Furthermore, many real-world agents, such as physical robots, commonly operate under human supervisors, which are not susceptible to such perturbation attacks. As a result, we propose to instead focus on illusionary attacks, a novel form of attack that is consistent with the world model of the victim agent. We provide a formal definition of this novel attack framework, explore its characteristics under a variety of conditions, and conclude that agents must seek realism feedback to be robust to illusionary attacks.
SNeS: Learning Probably Symmetric Neural Surfaces from Incomplete Data
Jun 13, 2022
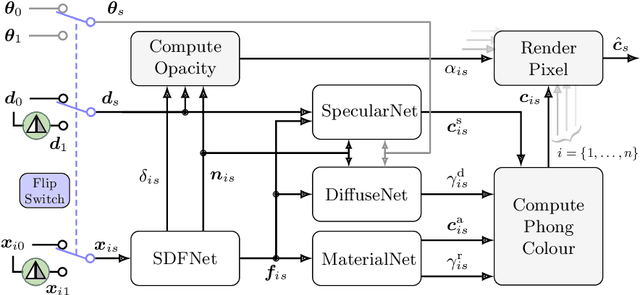
We present a method for the accurate 3D reconstruction of partly-symmetric objects. We build on the strengths of recent advances in neural reconstruction and rendering such as Neural Radiance Fields (NeRF). A major shortcoming of such approaches is that they fail to reconstruct any part of the object which is not clearly visible in the training image, which is often the case for in-the-wild images and videos. When evidence is lacking, structural priors such as symmetry can be used to complete the missing information. However, exploiting such priors in neural rendering is highly non-trivial: while geometry and non-reflective materials may be symmetric, shadows and reflections from the ambient scene are not symmetric in general. To address this, we apply a soft symmetry constraint to the 3D geometry and material properties, having factored appearance into lighting, albedo colour and reflectivity. We evaluate our method on the recently introduced CO3D dataset, focusing on the car category due to the challenge of reconstructing highly-reflective materials. We show that it can reconstruct unobserved regions with high fidelity and render high-quality novel view images.
A 23 MW data centre is all you need
Mar 31, 2022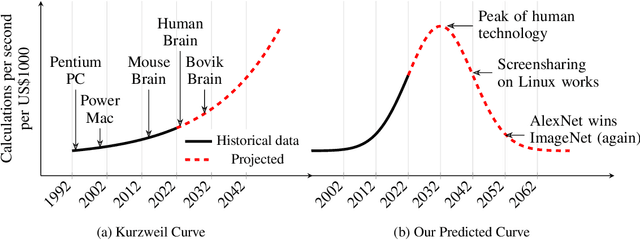
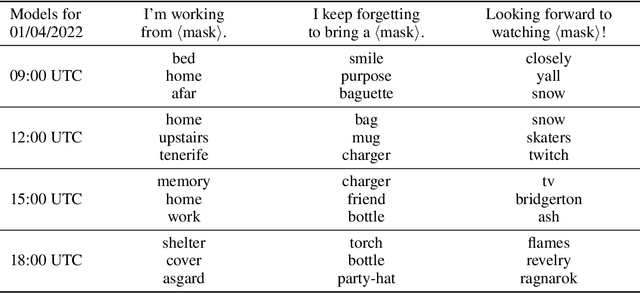
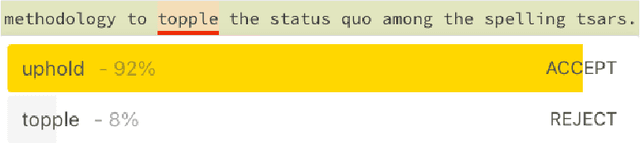
The field of machine learning has achieved striking progress in recent years, witnessing breakthrough results on language modelling, protein folding and nitpickingly fine-grained dog breed classification. Some even succeeded at playing computer games and board games, a feat both of engineering and of setting their employers' expectations. The central contribution of this work is to carefully examine whether this progress, and technology more broadly, can be expected to continue indefinitely. Through a rigorous application of statistical theory and failure to extrapolate beyond the training data, we answer firmly in the negative and provide details: technology will peak at 3:07 am (BST) on 20th July, 2032. We then explore the implications of this finding, discovering that individuals awake at this ungodly hour with access to a sufficiently powerful computer possess an opportunity for myriad forms of long-term linguistic 'lock in'. All we need is a large (>> 1W) data centre to seize this pivotal moment. By setting our analogue alarm clocks, we propose a tractable algorithm to ensure that, for the future of humanity, the British spelling of colour becomes the default spelling across more than 80% of the global word processing software market.
Audio Retrieval with Natural Language Queries: A Benchmark Study
Dec 17, 2021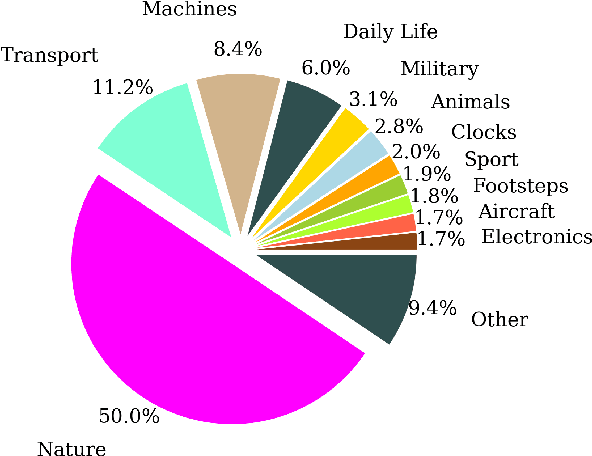
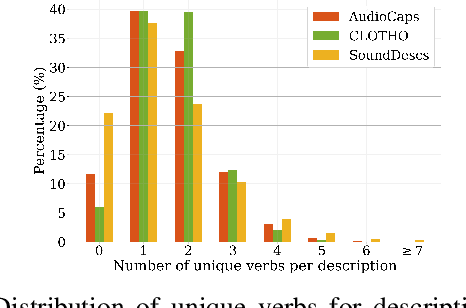
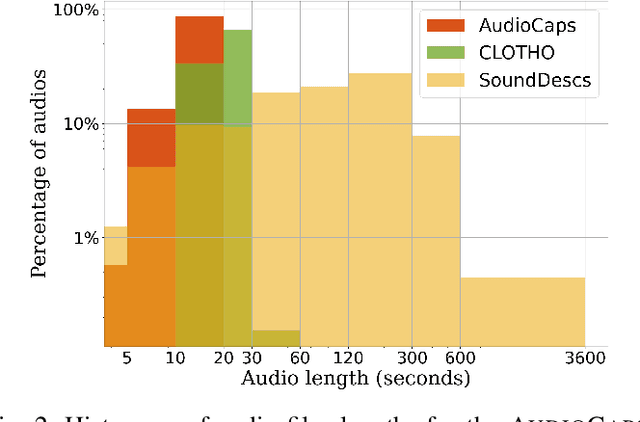
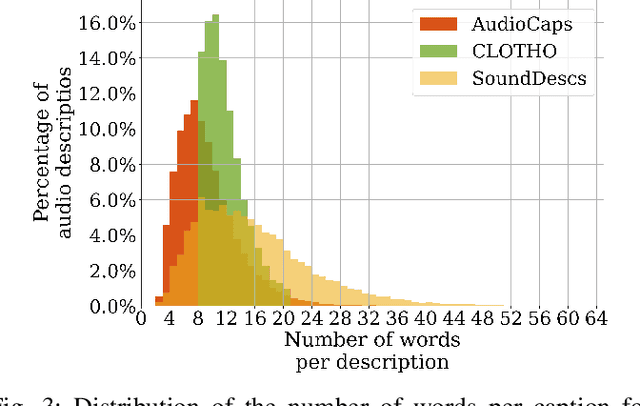
The objectives of this work are cross-modal text-audio and audio-text retrieval, in which the goal is to retrieve the audio content from a pool of candidates that best matches a given written description and vice versa. Text-audio retrieval enables users to search large databases through an intuitive interface: they simply issue free-form natural language descriptions of the sound they would like to hear. To study the tasks of text-audio and audio-text retrieval, which have received limited attention in the existing literature, we introduce three challenging new benchmarks. We first construct text-audio and audio-text retrieval benchmarks from the AudioCaps and Clotho audio captioning datasets. Additionally, we introduce the SoundDescs benchmark, which consists of paired audio and natural language descriptions for a diverse collection of sounds that are complementary to those found in AudioCaps and Clotho. We employ these three benchmarks to establish baselines for cross-modal text-audio and audio-text retrieval, where we demonstrate the benefits of pre-training on diverse audio tasks. We hope that our benchmarks will inspire further research into audio retrieval with free-form text queries. Code, audio features for all datasets used, and the \datasetName dataset will be made publicly available.